Python面试篇(二)
文章目录
-
- 简介
- 算法和数据结构
-
- dict底层结构
- list/tuple
- 实现LRU
- 算法常考点
-
- 单链表反转
- 队列
- 二叉树
- 堆
- 字符串
- Hash扩容
- 二维数组
- 小结
简介
- 上一篇介绍了基础的面试技巧和Python语言考察点,本篇主要从常用算法和数据结构入手
算法和数据结构
- 常用内置数据结构和算法

- 数据结构和算法是不分家的
- 单纯的看数据结构,就是数据存储的格式,这里的线性、链式、KV、集合等等
- 我们更关心基于存储格式的算法,列表、字典、集合属性,内置库算法等
- 常用库
collections:方法 作用 namedtuple() 创建命名元组子类的工厂函数 deque 类似列表(list)的容器,实现了在两端快速添加(append)和弹出(pop) ChainMap 类似字典(dict)的容器类,将多个映射集合到一个视图里面 Counter 字典的子类,提供了可哈希对象的计数功能 OrderedDict 字典的子类,保存了他们被添加的顺序 defaultdict 字典的子类,提供了一个工厂函数,为字典查询提供一个默认值 UserDict 封装了字典对象,简化了字典子类化 UserList 封装了列表对象,简化了列表子类化 UserString 封装了列表对象,简化了字符串子类化 - 看个例子:
import collections # collections.namedtuple(typename, field_names, *, rename=False, defaults=None, module=None) # 返回一个新的元组子类,名为typename ;简而言之,它让tuple更可读 _some = collections.namedtuple('Point', ['x', 'y']) # 这个Point不是关键,重点是让下标从01变为xy,更可读 p = _some(11, y=22) p[0] + p[1] # 33 # 双端队列,两头插 de = collections.deque() de.append(1) de.append(2) de.appendleft(0) de # deque([0, 1, 2]) de.pop() de.popleft() # 计数器 c = collections.Counter('abababaccd') c # Counter({'a': 4, 'b': 3, 'c': 2, 'd': 1}) c.most_common() # [('a', 4), ('b', 3), ('c', 2), ('d', 1)] # OrderedDict order = collections.OrderedDict() # 保存了插入时的顺序 order['a'] = 1 order['b'] = 2 order['c'] = 3 list(order.keys()) # ['a', 'b', 'c'] 方便实现LRU Cache - 看官方文档是个好主意
dict底层结构
- 字典使用哈希表作为底层结构
- 平均查找时间复杂度O(1)
- 二次探查解决哈希冲突问题
- 解决哈希冲突有三种方法:开放定址法、再哈希法、链地址法
- 开放定址法有通用的再散列函数(Hi=(H(key)+di)%m i=1,2,…,n)
- 其中,二次探测再散列:冲突发生时,在表的左右进行跳跃式探测(di=12,-12,22,-22,…,k2,-k2 ( k<=m/2 ),正负代表左右两侧)
- 链地址法:冲突后使用链表保存相同key的元素
- 使用哈希结构的另一个问题是如何扩容
- 类似C++中vector的容量扩张方法
- Hash表中每次发现loadFactor==1(负载因子:used/size)时,就开辟一个原来桶数组的两倍空间(称为新桶数组)
- 把原来的桶数组中元素所有转移过来到新的桶数组中
- 以上是针对链地址法的扩容操作,缺点是要移动所有元素
- 哈希表的底层使用数组(嗯,简单吧,不然怎么O(1),会直接将key按照算法转换成数组下标)
list/tuple
- 都是线性结构,支持下标访问
- list是可变对象,tuple保存的引用不可变
- 不可变指的是不能替换掉里面的对象
- 但如果这个对象本身就是可变的,可以修改
t = ([1],2,3) t[2] = 4 # TypeError: 'tuple' object does not support item assignment t[0].append(2) - list没法作为字典的key,tuple可以(可变对象不可hash)
- list的本质还是数组,但由于能存储不同类型的对象,保存的是指向对象的指针,即这是个指针数组
实现LRU
- 这是一种缓存剔除策略(最近最少使用),学过OS的应该都知道,常见的还有LFU
- 原理呢?使用循环双端队列更新,把最新访问的key放到表头,装不下就踢出表尾
- 怎么实现呢?dict+OrderedDict
- 这种缓存置换策略一般包含三个方法即可实现:
init()、get()、put()
from collections import OrderedDict # OrderedDict的特点是保存了插入时的顺序 class LRUCache: def __init__(self,capacity=128): self.capacity = capacity # 限制容量 self.order = OrderedDict() def get(self, k): if k in self.order: val = self.order[k] self.order.move_to_end(k) # 内置方法,kv移到尾部,改变顺序 # 注意:我们视字典尾部为队列表头,即踢出元素时从字典头部 return val else: return -1 def put(self, k, v): if k in self.order: del self.order[k] self.order[k] = v # 更新kv,move_to_end()也可以的啦,但关键在于v可能不一样, else: if(self.capacity <= len(self.order)): # 满了 del self.order.popitem(last=False) # 踢出字典头部(最先进来的) self.order[k] = v # 插到尾部(表头) - 这种缓存置换策略一般包含三个方法即可实现:
- 使用单元测试看看我们的算法实现对不对吧!
算法常考点
- 重点:排序+查找(可以看我的文章:重学算法C++版)
- 要求:独立手写,分析时间复杂度
- 这里先实现:链表、队列、栈、二叉树、堆
- 使用内置结构实现高级数据结构
- LeetCode刷题/《剑指offer》上的题
- 这里需要你了解常见的数据结构概念,比如什么是单链表、循环链表等
单链表反转
-
打开LeetCode
- 这个题目难度更高一点,指定区间的翻转
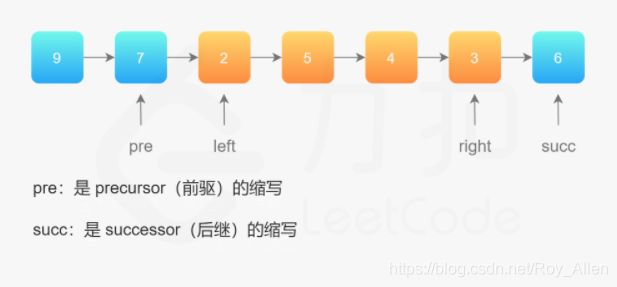
- 链接什么时候切断,什么时候补上去,先后顺序一定要想清楚
- 上面的思路实现比较复杂,可以每遍历到一个节点,让这个新节点来到反转部分的起始位置,遍历一遍即可:

pre始终指向翻转位置的起点(起始指向left-1)cur指向当前节点(起始指向left)next始终指向cur的下一个节点

- 这个题目难度更高一点,指定区间的翻转
-
初始化结点还是会的吧:
# Definition for singly-linked list. class ListNode: def __init__(self, val=0, next=None): self.val = val # 数据 self.next = None # 指针 -
代码实现(官方答案)
class Solution: def reverseBetween(self, head: ListNode, left: int, right: int) -> ListNode: # 设置头结点dummyNode 是这一类问题的一般做法 # 第一个数据节点我们叫首节点 dummy_node = ListNode(-1) dummy_node.next = head pre = dummy_node for _ in range(left - 1): # 用户输入从1开始计数 pre = pre.next # 画个图帮助理解即可,pre指向left前一个 cur = pre.next for _ in range(right - left): # range包左不包右哦! next = cur.next cur.next = next.next next.next = pre.next pre.next = next return dummy_node.next -
再来一个,给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点,打开leetcode
- 思路:双指针
pre和cur
# 力扣题解: # 再强调一遍,链表的题带上头结点好做 class Solution: def deleteNode(self, head: ListNode, val: int) -> ListNode: # 如果删除首节点 if head.val == val: return head.next pre, cur = head, head.next while cur and cur.val != val: pre, cur = cur, cur.next # while完毕,要么找着了,要么走完了 if cur: pre.next = cur.next return head - 思路:双指针
-
再来一个,删除链表指定节点,打开leetcode
- 注意,是指定的node,不是值
- 传统思路:修改之前节点的 next 指针,使其指向之后的节点,但是找到前一个麻烦啊

- 其实很简单,删除固定节点就是把这个值拿走换上next节点的值呗

# 官方答案 class Solution: def deleteNode(self, node): node.val = node.next.val node.next = node.next.next # 没了! -
合并两个有序链表
- 很简单,两个指针分别指向两个链表,相互比较当前节点,小的入表并指针前移
class Solution: def mergeTwoLists(self, l1, l2): prehead = ListNode(-1) # 合并链表 prev = prehead while l1 and l2: if l1.val <= l2.val: prev.next = l1 l1 = l1.next # l1指针前移 else: prev.next = l2 l2 = l2.next prev = prev.next # 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可 prev.next = l1 if l1 is not None else l2 # python简洁之道 return prehead.next -
再来,反转链表,上leetcode
- 思路:链表,有指针相连,直接反转指向就行

- 当然,要注意链表操作的顺序,这是常识
# 官方答案 class Solution: def reverseList(self, head: ListNode) -> ListNode: pre, cur = None, head while cur: nxt = cur.next cur.next = pre pre = cur cur = nxt return pre- leetcode有很多测试用例,如果有遗漏情况不会通过
- 如果没思路别死磕!
- 关于链表的题常考,可以找一些难的锻炼思维
- 思路:链表,有指针相连,直接反转指向就行
队列
- 先进先出结构
- 使用collections.deque
from collections import deque class Queue: def __init__(self): self.queue = deque() # 默认是栈 def append(self, value): self.queue.append(value) def pop(self): return self.queue.popleft() def empty(self) return len(self.queue)==0 def test_queue(): q = Queue() q.append(1) q.append(2) q.append(3) print(q.pop()) print(q.pop()) print(q.pop()) # 同理,可以实现栈 - 可以实现一个最小值栈:即能在常数时间内检索到栈的最小元素
- 上leetcode
- 以空间换时间思想,使用辅助栈是常见的做法
# 声明:以下为官方解法 class MinStack: # 辅助栈和数据栈同步 # 思路简单不容易出错 def __init__(self): # 数据栈 self.data = [] # 辅助栈 self.helper = [] def push(self, x): self.data.append(x) # 辅助栈为空的时候,必须放入新进来的数 # 新来的数小于或者等于辅助栈栈顶元素的时候,才放入 if len(self.helper) == 0 or x <= self.helper[-1]: # [-1]表示最后一个值 self.helper.append(x) # 否则放入辅助找顶元素 else: self.helper.append(self.helper[-1]) # 为了数据同步 def pop(self): if self.data: self.helper.pop() return self.data.pop() # peek def top(self): if self.data: return self.data[-1] def getMin(self): if self.helper: return self.helper[-1]- 你可能会想push中是多此一举,干嘛要数据同步,保存min不就行?
- 直接返回min的问题在于pop之后min如何重新定义,pop出了一个min,里面还有min吗?还是需要空间来存储所有的min值
- 用栈实现队列,上leetcode
# 队列:队尾进队头出 # 常见的思路是使用两个栈,倒换一下顺序 # 注,全程两个栈,再来个指针front指向出队元素 # 借鉴答案: class MyQueue: def __init__(self): """ Initialize your data structure here. """ self.s1 = [] self.s2 = [] # 这里用列表模拟两个栈,先进后出结构即可 self.front = None # 入队 # 只需往S1放即可 def push(self, x: int) -> None: """ Push element x to the back of queue. """ if not self.s1: self.front = x # s1最先放入的元素就是队头!!! self.s1.append(x) # 出队 # 必须从S2出队,但先要把S1的都移过来,一定要移干净 def pop(self) -> int: """ Removes the element from in front of queue and returns that element. """ if not self.s2: while self.s1: self.s2.append(self.s1.pop()) self.front = None return self.s2.pop() # 取队头元素,这里就体现了front的作用,无需把s1都扔过来 def peek(self) -> int: """ Get the front element. """ if self.s2: return self.s2[-1] return self.front def empty(self) -> bool: """ Returns whether the queue is empty. """ if not self.s1 and not self.s2: return True return False
二叉树
- 常考的是树的遍历:先序、中序、后序
- 树就是使用递归定义的,遍历也可以使用递归
- 先定义节点
- 注意定义节点的方式,不是我说,很多人卡死在这一步
# 树节点 class BiTreeNode(object): def __init__(self, data, left=None, right=None): self.data = data self.left = left self.right = right # 树及操作 class BiTree(object): # 初始化树根 def __init__(self, root=None): self.root = root def pre_order(self, treeNode): # 一般传入根节点 if treeNode is not None: print(treeNode.data) self.pre_order(treeNode.left) self.pre_order(treeNode.right) # 中序和后序同理- 层序遍历也不能少
# 思路很简单,遍历每层的值依次放入队列;使用两个数组保存当前节点和子节点,向下传递 class solution: def __init__(self): self.cur_node = [] self.next_node = [] self.res = [] #已遍历到的数组 def level_travel(self, node): # 起始点要把握好! if not node: return [] self.cur_node.append(node) self.res.append([i.val for i in self.cur_node]) # 返回遍历结果是关键 while(self.cur_node or self.next_node): for node in self.cur_node: if node.left: self.next_node.append(node.left) if node.right: self.next_node.append(node.right) if self.next_node: self.res.append([i.val for i in self.next_node]) self.cur_node = self.next_node # 准备遍历子层 self.next_node = [] # 再准备接收子层的子节点 return res- 这里有个常见应用(面试题):树的左视图/右视图;左视图则res提前只保存node.left即可
堆
- 堆是完全二叉树,有最大堆和最小堆
- 最大堆:每个节点值都比他孩子的大,支持每次操作pop最大元素
- 这里有个常考题:获取前10大的元素,这里利用最小堆实现,借助
heapqimport heapq # 直接使用python提供的堆结构,heapq,传参即可,无需初始化 # 维护最小堆是为了取堆顶元素,与新进入的元素比较 class TopK(object): def __init__(self, i:list, capacity:int): self.iterable = i # 待取列表 self.capacity = capacity # 取前几个,这里就是几 self.minheap = [] # 只需要准备一个列表即可,无需heapq() def push(self, val): if(len(self.minheap)>=self.capacity): min_val = self.minheap[0] # 取最小值 if val < min_val: pass # 太小了也,我要取最大的几个 else: heapq.heapreplace(self.minheap, val) # 大的放进去,自动调整 else: # 没存满,直接放入并维护 heapq.heappush(self.minheap, va) def getTopK(self): for val in self.iterable: self.push(val) return self.minheap def test_heap(): import random i = list(range(100000)) random.shuffle(i) # 乱序 _ = TopK(i, 15) print(_.getTopK())- 注:往里放的过程中找最小值
- 关于白板问题(手写代码)
- 竞争激烈,平时刷题,避免手生
- 看一些算法面经,有考试就有押题
- 常见的快排、归并要能手到擒来
- 再来一道:合并k个有序链表,上leetcode
- 还是借助heapq实现
- 思路:遍历所有链表节点加入列表,形成最小堆,构造新链表
from heapq import heapify def mergeKLists(self, lists: List[ListNode]) -> ListNode:: # 传入的是存储链表首节点的列表 # 遍历所有链表节点加入列表 # if not lists: # 空值判断,由于[[]]也会被认为是有值,所以直接判断node_list,这个要注意! # return None node_list = [] for linked in lists: while linked: node_list.append(linked.val) linked = linked.next # 形成最小堆 if not node_list: return None heapify(node_list) # 构造新链表 root = ListNode(heappop(node_list)) # leetcode中直接定义了链表节点,也可自定义 cur = root while node_list: nextnode = ListNode(heappop(node_list)) cur.next = nextnode cur = nextnode return root
字符串
- Python内置了字符串类型
str,并使用Unicode编码 - 其实就是定义了字符串类,封装了操作方法,声明一个字符串就是初始化一个对象;C++中只有string对象,一个道理
- 常见操作:链接
- 反转字符串:上leetcode
- 字符串内置操作
s.reverse(),可以直接实现,但这样就没意思了吧 - 思路:这个题要求原地翻转,即不占用额外空间;想象一下,如果你想把一个木棍翻个个,只需拿住中点,~~~,对吧!
def reverse_string(s:str): begin = 0 end = len(s)-1 # 两个指针,两头开始,交换,靠拢 while begin<end: # 相等即止 s[begin], s[end] = s[end], s[begin] # swap begin += 1 # 没有++ end -= 1+=代表改变了变量,相当于重新生成了一个变量++代表改变了对象本身,而不是变量本身,但Python的数值对象是不可改变的
- 字符串内置操作
- 再来一个:判断是否为回文数,上leetcode
- 啥叫回文数/回文串,和上面的题类似,从前到后或从后到前一样就行(连成一个圈,转呀转)
class Solution(object): def isPalindrome(self, num:int): if num<0: return False s = str(x) # 这样就舒服了 begin = 0 end = len(s)-1 # 两个指针,两头开始,比较,靠拢 while begin<end: # 相等即止 if s[begin] != s[end] return False begin += 1 # 没有++ end -= 1 return True import pytest def test_isP(): # 测试用例 solver = Solution() assert solver.isPalindrome(121) is True assert solver.isPalindrome(12121) is True assert solver.isPalindrome(12341) is False assert solver.isPalindrome(0) is True assert solver.isPalindrome(-1) is False # pytest this.py
Hash扩容
- 回答前面提到的问题:Python中字典用的是hash存储,冲突采用二次探查法,怎么扩容呢?
- 有人说:已使用的大小*4(如果已使用超过50000,那就*2),这个值叫minused.然后从初始大小开始,找一个合适值,要比minused大,如果小于就乘2,这个值就是新的hash表大小!
- 就还是和负载因子有关吧
- 想求证只能看源码了
二维数组
- 前一篇的问题:创建二维数组的坑
- 列表是基于 PyListObject 实现的,PyListObject 是一个变长对象;故可简单理解为:列表是长度可变的数组
- 发现没,数组这个数据结构非常基础,属于线性表中的顺序表
- 然后就是链表了,底层无外乎这两种
- 一般用list创建一维数组,多维呢?
- 我们很容易这样做:
list_1 = [[0] * 3] * 3 # *3这是语言特性 # 但修改值时不行: list_1[1][1] = 2 print(list_1) # [[0, 2, 0], [0, 2, 0], [0, 2, 0]] 都改了! 因为浅拷贝 # 正确做法是:类似生成器: list_2 = [[0 for i in range(3)] for j in range(3)] # 当然,也可以数分三剑客:NumPy和Pandas、Matpotlib 结合一起使用 #但numpy的数组和列表不同,这里是指针数组,np是同类型数组
小结
- 本篇从数据结构和算法的角度,回顾了Python中常见的内置数据结构,也对常考的算法:链表、栈、队列、树、堆等,选择简单的算法题目进行解释
- 这里只是一个提纲,算是提个醒,如果你能从中发现自己薄弱的地方就OK,重在平时,坚持每天刷一道LeetCode中等难度的题,你的编码能力和逻辑思维肯定会长进
- 下一篇从编程范式和操作系统的角度,回顾语言特性和多线程等知识;期待和你交流