2. Scrapy爬虫实践
文章目录
-
- 简介
- 网站分析
- 下一页
- items
- pipelines
- item loader
- 小结
简介
- 这篇初步学习Scrapy框架,并使用它爬取一个网站
- 这里开发环境使用Windows,需要配置Python虚拟环境
# 安装虚拟环境使用 pip install -i https://pypi.douban.com/simple/ virtualenv # 切换到自定义目录 virtualenv scrapy_article # 进入里面的Scripts文件夹 activate.bat # 激活环境 # 我的Windows中只有Python3,如果你想指定Python2虚拟环境,需要创建时通过 -p 参数指定py2安装位置 # 也有其他创建虚拟环境的方法,还可以建立workon环境变量,方便操作 pip install -i https://pypi.douban.com/simple/ virtualenvwrapper-win workon # wrapper自带命令,列出所有虚拟环境 # 设置WORKON_HOME环境变量,指定创建目录 mkvirtualenv [name] # 创建虚拟环境 workon [name] # 进入指定虚拟环境并激活 deactivate # 退出当前虚拟环境 rmvirtualenv [name] # 删除虚拟环境
网站分析
- 我们爬取科技板块下的文章

- 由于此站已经在链接中指明了文章位置,就无须用深度/广度优先获取URL了(别因为使用算法把问题复杂化)
- 这里只需获取每页的链接并分析,再进入详情:
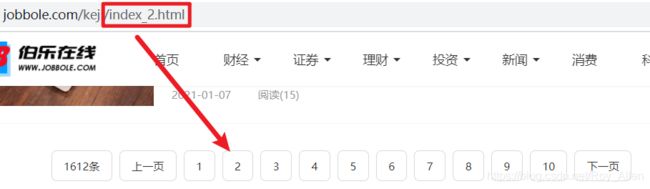
- 为了适应数据的增长,我们针对 “ 下一页 ” 的链接
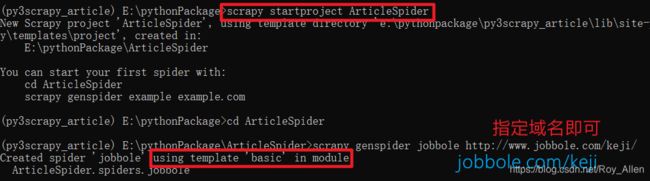
- 创建好虚拟环境
workon py3scrapy_article scrapy startproject ArticleSpider # 命令行创建工程 # 在pycharm打开并导入,更换解释器为虚拟环境 - 根据命令提示,使用默认模板创建一个spiders
- 注:先介绍基本流程,让scrapy跑起来!
- 让scrapy可调试:
# 新建main.py from scrapy.cmdline import execute import sys import os # dirname是获取父目录;file指定当前文件 sys.path.append(os.path.dirname(os.path.abspath(__file__))) # 加入ArticleSpider目录到环境变量,方便运行scrapy命令 # 现在,就相当于我们可在cmd中 E:\pythonPackage\ArticleSpider> 下执行命令 execute(['scrapy','crawl','jobbole']) # 相当于执行:scrapy crawl jobbole- 在
settings.py中关闭robots协议(每个网站都有robots协议,过滤爬虫) - 在爬虫文件parse解析器中打上断点,可以开始debug了(能获取到元素才能调试)
- 你可能需要视情况在settings中添加:
HTTPERROR_ALLOWED_CODES = [404]
- 在
- 现在可以在
parse中使用xpath提取信息了- 在上一篇中我们已经介绍过前端知识,这里主要使用节点(元素)的概念
- 基本的xpath语法:这里的article元素就是我们爬到的一份网页

- 获取具体节点:注意,这里的节点属性就是
id、class、name等等
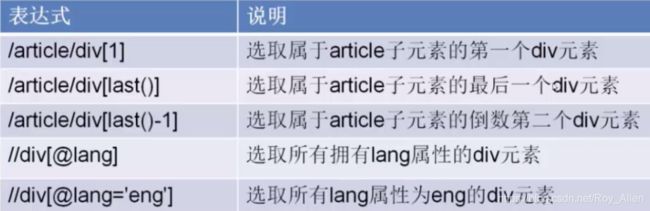
- 还有一些特殊符号:

- 熟能生巧,可以系统学一下Xpath语法,有些内置的方法能省很多事!
- 使劲啃了一波xpath,总结如下:
- 打上断点调试,追踪变量的变化,比print后瞎琢磨强
|符号表示前后两种匹配方式,两种方式不是一回事,别想着用前一种的前缀//代表所有,得看前面是谁,前面没人,就是从整个文档下选取- 一般用于整篇提取,如果基于某个节点那直接
/后不加序号[]即可
- 一般用于整篇提取,如果基于某个节点那直接
- 先通过浏览器的Copy Xpath看看,再自己改进
- 获取的数据格式要符合原本规律,例如:
键:值- 可以键值分开提取再对接,可以一起提取
- 但不要因为键中出现了特殊标签就独立出来想办法提取,反而越搞越麻烦 !
- 当然,是对于一般情况
- 针对取出元素的修饰或者再提取不必执着于现成方法,可以用正则
- 在一个链接下写好了提取语法,要换几个页面测试,泛化方法
- 选取一篇文章,将其URL放在
start_urls中,文章包含的信息如下 :

-
F12查看Elements
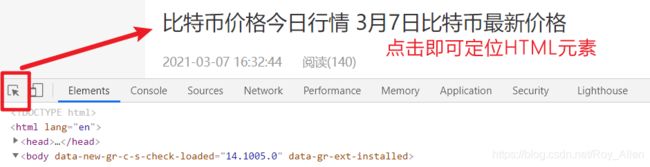
-
观察可知:标题在body下的第三个div下的第一个div下的第三个div下的第一个div…
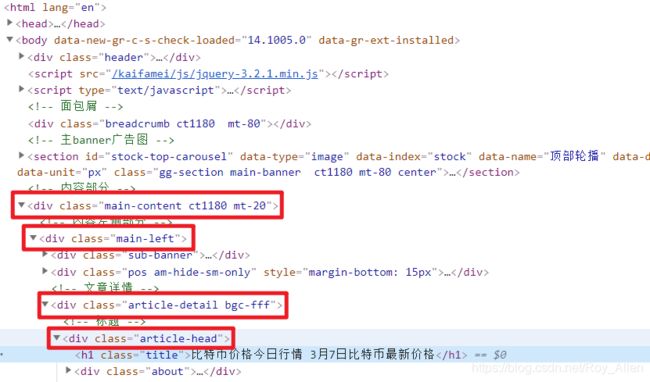
-
浏览器右键
Copy/Copy Xpath即可import scrapy class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['jobbole.com'] start_urls = ['http://www.jobbole.com/keji/qkl/170004.html'] # http://www.jobbole.com/keji def parse(self, response): headline = response.xpath('/ html / body / div[3] / div[1] / div[3] / div[1] / h1') # Chrome pass -
一直显示404:加了User-Agent之类的也不行,反爬?
INFO: Ignoring response <404 http://www.jobbole.com/keji/qkl/170004.html> -
终于,它403了我,还是换一个友好的网站吧!以后必解决它!
-
在cmd里面也提供了工具,激活环境:
scrapy shell 网址,即可开始调试

- 这好像不能对需要UA的网站调试
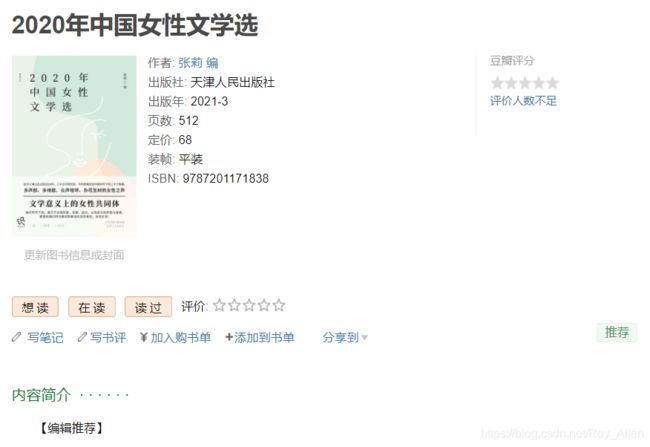
-
提取作者出版社等这一块信息:啃了半天
infos_span = response.xpath('//*[@id="info"]/span[@class="pl"]/text() | //*[@id="info"]/span/span[@class="pl"]/text()').extract() # [' 作者', '出版社:', '出品方:', '副标题:', '原作名:', ' 译者', '出版年:', '页数:', '定价:', '装帧:', 'ISBN:'] 终于成功了! # print(infos_span) infos_text = response.xpath('//*[@id="info"]/text() | //*[@id="info"]/span/a/text() | //*[@id="info"]/a/text()').extract() print(infos_text) # 下面这部分是将数组中只含特殊字符(\n\t\r)的元素去除,如果包含空格之类的可以用strip()或者replace() regex = '.*(\S+).*' # 匹配任何非空白字符 span = [] for i in range(len(infos_span)): match = re.match(regex, infos_span[i]) if match: span.append(infos_span[i]) text = [] for i in range(len(infos_text)): # infos_text[i].replace('\r','').replace('\n','').replace('\t','') # 不能直接extract().strip() match = re.match(regex, infos_text[i]) if match: text.append(infos_text[i]) print(span) print(text) # 可以拼接了 # 内容简介 simple_content = response.xpath('//*[@id="link-report"]/span[2]/div/div/p/text()').extract() # 作者简介 author = response.xpath('//*[@id="content"]/div/div[1]/div[3]/div[2]/span[2]/div/p/text()').extract() # 所有标签 tags = response.xpath('//*[@id="db-tags-section"]/div/span/a/text()').extract()
-
- 以上通过Xpath选择器提取了豆瓣读书网页信息,再看看CSS选择器,主要包括:
- 标签选择器
- 直接针对标签名,例如
div/img/h1/span,范围大
- 直接针对标签名,例如
- id选择器
- 即id属性,特定是不重复,符号
#
- 即id属性,特定是不重复,符号
- 类选择器
- 即class属性,可能重复,符号
.
- 即class属性,可能重复,符号
- 层级选择器
- id选择器、类选择器、标签选择器结合使用
- 如何定位呢?

- 标签配合
. #,注意格式,紧跟着写(大部分定位都用这俩) - 空格就是下级关系(标签),类似
>符号(组) - 使用
+就是下一个 - 如果是多个class确定,不加空格即可
- 标签配合
- 还有:
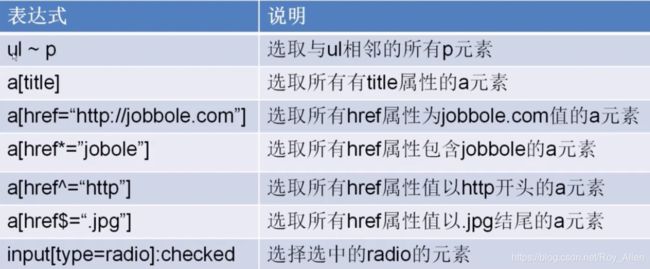
- 相邻所有用
~符号 - 其他属性就要紧跟
[]表示了
- 相邻所有用
- 继续:
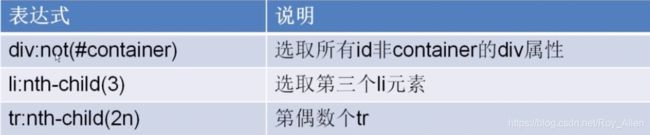
- 这里取值用
::text,即xpath中的/text(),举个例子吧:提取书名header = response.css('span[property="v:itemreviewed"]::text').extract_first("") # 这个提取方法的作用是防止数组为空直接报错!
- 标签选择器
- 为什么还要学习CSS选择器呢?这种看个人情况,都能实现功能,萝卜和青菜的问题!
- 个人感觉还是CSS好理解一些
- 以上是爬取一个页面的代码,图片先不考虑,然后要针对上一级网页,获取所有图书链接,传给scrapy
- 这里选取一个喜欢的作者趴一趴:东野圭吾
下一页
- 这里要先明确一个概念,scrapy是将源代码先下载,返回
response,再进行parse字段的- 下载采用异步形式,提高效率
- 后面会介绍scrapy的整体框架
- 所以我们的解析器主要干两件事:
- 获取当前页和下一页所有文章URL交给scrapy下载
- 回调,解析字段提取数据
- 咱们针对这个页面先分析,获取当前页所有URL,再下一页
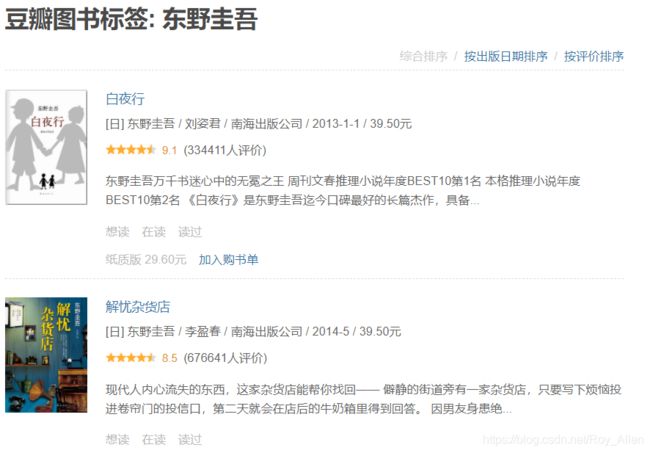
- 发现目标:
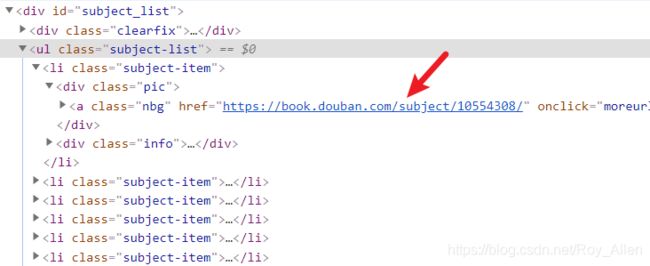
- 获取某一属性,使用
::attr()urls = response.css('#subject_list ul li .pic a::attr(href)').extract() - 获取下一页URL
url_next_page = response.css('.paginator .next a::attr(href)').extract_first() # '/tag/东野圭吾?start=20&type=T' regex = '.*([?]start\S+)' # 写正则的经验不足啊! match = re.match(regex, url_next_page) - 更改start_urls为第一列表页,打上断点,开始调试!
# 完整代码 import scrapy import re from scrapy import Request from urllib import parse class JobboleSpider(scrapy.Spider): name = 'jobbole' allowed_domains = ['book.douban.com'] start_urls = ['https://book.douban.com/tag/%E4%B8%9C%E9%87%8E%E5%9C%AD%E5%90%BE'] # http://www.jobbole.com/keji def parse(self, response, **kwargs): ''' 获取当前页所有URL,交给scrapy下载 ''' urls = response.css('#subject_list ul li .pic a::attr(href)').extract() # 提取某一属性,使用::attr() # print(urls) for url in urls: # # callback是异步调用的,调试可以用run tu cursor 查看article_detail的使用情况 yield Request(url=url, callback=self.article_detail) # 下载完成后回调字段解析函数,注意,不需要加()调用 # 使用生成器(类似子进程中断,可以暂停,然后恢复继续执行) ''' 下一页URL,交给scrapy下载 ''' url_next_page = response.css('.paginator .next a::attr(href)').extract_first() # print(url_next_page) # '/tag/东野圭吾?start=20&type=T' regex = '.*([?]start\S+)' # 写正则的经验不足啊! match = re.match(regex, url_next_page) # print(match.group(1)) if match.group(1): # 如果提供的url不完整,需要拼接主url yield Request(url=parse.urljoin(response.url, match.group(1)), callback=self.parse) # 就形成循环,直到没有下一页!函数执行结束 pass def article_detail(self, response): ''' 文章详情解析函数 :param response: :return: ''' headline = response.xpath('//*[@id="wrapper"]/h1/span/text()').extract()[0] # Chrome # headline2 = response.xpath('/html/body/div[3]/div[1]/div[3]/div[1]/h1') # FireFox # print(headline) infos_span = response.xpath( '//*[@id="info"]/span[@class="pl"]/text() | //*[@id="info"]/span/span[@class="pl"]/text()').extract() # [' 作者', '出版社:', '出品方:', '副标题:', '原作名:', ' 译者', '出版年:', '页数:', '定价:', '装帧:', 'ISBN:'] 终于成功了! # print(infos_span) infos_text = response.xpath( '//*[@id="info"]/text() | //*[@id="info"]/span/a/text() | //*[@id="info"]/a/text()').extract() # print(infos_text) # 下面这部分是将数组中只含特殊字符(\n\t\r)的元素去除,如果包含空格之类的可以用strip()或者replace() regex = '.*(\S+).*' # 匹配任何非空白字符 span = [] for i in range(len(infos_span)): match = re.match(regex, infos_span[i]) if match: span.append(infos_span[i]) text = [] for i in range(len(infos_text)): # infos_text[i].replace('\r','').replace('\n','').replace('\t','') # 不能直接extract().strip() match = re.match(regex, infos_text[i]) if match: text.append(infos_text[i]) # print(span) # print(text) simple_content = response.xpath('//*[@id="link-report"]/span[2]/div/div/p/text()').extract() # 内容简介 author = response.xpath('//*[@id="content"]/div/div[1]/div[3]/div[2]/div/div/p/text()').extract() # 作者简介 # print(simple_content) # print(author) tags = response.xpath('//*[@id="db-tags-section"]/div/span/a/text()').extract() # 所有标签 # print(tags) - 注意callback是异步调用的,打上断点直接进不去,可以取消循环的断点,
run to cursor - 调试有技巧,铁头需谨慎(F8单步执行,F9打断点跳过去)

- 上面就是我们给异步函数传的参数meta,在response中,并不用修改函数
- 发现目标:
items
- 由于解析字段形成结构化数据的过程中,有可能出现变量名错误等问题,scrapy采用items将各字段实例化,然后送到pipeline中统一清洗存储
# items.py class DoubanArticleItem(scrapy.Item): front_img_url = scrapy.Field() front_img_path = scrapy.Field() title = scrapy.Field() infos_span = scrapy.Field() infos_text = scrapy.Field() simple_content = scrapy.Field() simple_author = scrapy.Field() tags = scrapy.Field() - 实例化的字段类型只有一种
scrapy,Field,不像Django中对应数据库各种类型的数据# 解析函数中定义: article_item = DoubanArticleItem() article_item['front_img'] = [front_img] article_item['title'] = title article_item['infos_span'] = infos_span article_item['infos_text'] = infos_text article_item['simple_content'] = simple_content article_item['tags'] = tags # 在settings中打开ITEM_PIPELINES,会执行到pipelines中的process_item # 中间件原理,底层中断监听实现- github上有个项目叫
scrapy-djangoitem,可以将Django的ORM集成到scrapy - 操作数据库能直接用
model的方法,这个扩展可以安装试试(如果你学过Django的话)
- github上有个项目叫
pipelines
- 因为图片只能从源码中获取链接,得下载,需要用到pipelines定义好的类:
site-packages\scrapy\pipelines\images.py中可以看到# settings.py ITEM_PIPELINES = { 'ArticleSpider.pipelines.ArticlespiderPipeline': 300, 'scrapy.pipelines.images.ImagesPipeline':1, # 数值越小越先处理 } # 类会从这里取值,类似config文件 IMAGES_URLS_FIELD = 'front_img' # ImagesPipeline类会找item中的这个字段 # 图片的存放路径我们搞成相对定位 import os projecct_path = os.path.abspath(os.path.dirname(__file__)) # ArticleSpider路径 IMAGES_STORE = os.path.join(projecct_path, 'images') # 还要安装pillow库 pip install -i https://pypi.douban.com/simple pillow- 它起到的作用就是拦截item,然后对指定字段进行处理
- 当然,还可以自定义pipeline处理图片,详见代码
class ArticleImagePipeline(ImagesPipeline): def item_completed(self, results, item, info): ''' 重载 :param results: list,每个元素是字典 [{0:True/False},{1:{path:full/xxx.jpg}}] :param item: 在parse中初始化的字段item :param info: :return: ''' # print('result:',results) if "front_img_url" in item: for ok, value in results: image_file_path = value["path"] item["front_img_path"] = image_file_path print(image_file_path) # 获取的是图片保存路径,应该就是:图片已经下载好(item_completed),让item中的这个属性记录保存路径! return item # settings中的下一个pipeline还要处理- 唯一的问题是:更新了
front_img_path字段啥时候存?别急!
- 唯一的问题是:更新了
- 接着,用pipeline处理其他字段,因为信息已经提取到字段,重点是保存到文件或数据库
# pipeline.py import codecs import json class JsonWithEncodingPipeline(object): ''' 处理item的各个字段,变为json格式并写入 主要逻辑写在process_item 别忘了返回item 在settings中注册 ''' def __init__(self): self.file = codecs.open('article.json', 'w', encoding='utf-8') def process_item(self, item, spider): lines = json.dump(dict(item), ensure_ascii=False)+'\n' # 变成json格式的文件 self.file.write(lines) return item def spider_closed(self,spider): # 信号量(中间件) self.file.close()- 这里自定义了一首,保存到article.json文件,也可使用scrapy提供的Exporter
- 注意:文件保存时都要变成utf8可变长编码,Python3中变量都是用Unicode编码
- 保存到数据库中需要设计数据表,这很简单,直接用Navicat完成
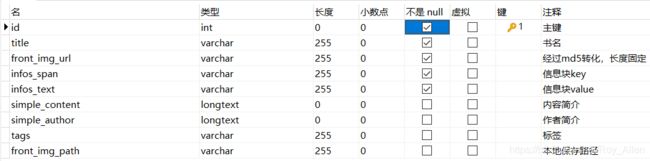
- 定义pipeline保存数据到MySQL:
class MySQLPipeline(object): ''' 保存字段数据到数据库 ''' def __init__(self): # 链接数据库 # 'host','user','password','dbname' self.conn = MySQLdb.connect('127.0.0.1','root','123456', 'article',charset='utf8', use_unicode=True) self.cursor = self.conn.cursor() def process_item(self, item, spider): sql = """ insert into article_douban(title, front_img_url, infos_span, infos_text, simple_content, simple_author, tags) VALUES(%s, %s, %s, %s, %s, %s, %s) """ # 这里都用str()处理一下 self.cursor.execute(sql, (str(item['title']), str(item['front_img_url']), str(item['infos_span']), str(item['infos_text']), str(item['simple_content']), str(item['simple_author']), str(item['tags']))) self.conn.commit() return item # 在settings中注册 - 这里有个关键问题:execute()是同步操作,这里搞不完后面走不了,如果爬虫速度很快就会出问题
- scrapy基于twisted提供了一个API,实现数据库异步操作:
# 异步IO:下载、上传、保存到数据库等,都可以考虑twisted class MySQLTwistedPipeline(object): def __init__(self, dbpool): self.dbpool = dbpool # 这是个类方法,scrapy初始化的时候就会调用,返回dbpool,当前定义的pipeline工作时,实例化后就会接收此返回值 @classmethod def from_settings(cls, settings): # 会将当前spider的settings传过来,名称固定 dbparams = dict( host = settings['MYSQL_HOST'], user = settings['MYSQL_USER'], passwd = settings['MYSQL_PASSWORD'], db = settings['MYSQL_DBNAME'], charset = 'utf8', cursorclass = MySQLdb.cursors.DictCursor, use_unicode = True ) # 连接池,指明用哪个数据库,然后传参 dbpool = adbapi.ConnectionPool('MySQLdb', **dbparams) # 容器的思想 return cls(dbpool) def process_item(self, item, spider): # 异步执行数据库操作 query = self.dbpool.runInteraction(self.do_insert, item) # 异步的错误处理 query.addErrback(self.handle_error) def handle_error(self, failure, item, spider): print(failure) def do_insert(self, cursor, item): sql = """ insert into article_douban(title, front_img_url, infos_span, infos_text, simple_content, simple_author, tags) VALUES(%s, %s, %s, %s, %s, %s, %s) """ cursor.execute(sql, (str(item['title']), str(item['front_img_url']), str(item['infos_span']), str(item['infos_text']),\ str(item['simple_content']), str(item['simple_author']), str(item['tags']))) - 运行main.py文件我们发现图片下载了、article_exporter.json生成了、数据库更新了
- 主要就三点:
- 理清parse函数的处理逻辑,下载源代码并提取数据
- 设置好Item,在parse中实例化
- 图片下载、数据导出、保存到数据库,都是准备好Item后借助pipeline进行;类似于面向切面编程,针对Item的不同处理进程,这里注意settings的设置(也可以起到开关的作用)
- 基于twisted(异步IO网络框架)和单独定义Item(全局流通)值得品味
- Python Twisted介绍
- 重点关注一下回调链,回调是事件驱动编程模型中的基础
- 目前,基本走通了scrapy的处理逻辑,将代码保存一份,继续学习
- 这里在pycharm中使用gitee(先安装,在VCS)
item loader
- 到这,你会发现你的spider代码很杂乱,今天能看懂,下周就让你放弃爬虫了
- 于是,scrapy提供了
ItemLoader,整理代码# 修改spider from scrapy.loader import ItemLoader # 使用itemloader加载item item_loader = ItemLoader(item=DoubanArticleItem(), response=response) item_loader.add_value("front_img_url", front_img) # 直接添加值即可,无需提取 # item名称,提取规则 item_loader.add_xpath('title', '//*[@id="wrapper"]/h1/span/text()') item_loader.add_xpath('infos_span', '//*[@id="info"]/span[@class="pl"]/text() | //*[@id="info"]/span/span[@class="pl"]/text()') item_loader.add_xpath('infos_text', '//*[@id="info"]/text() | //*[@id="info"]/span/a/text() | //*[@id="info"]/a/text()') item_loader.add_xpath('simple_content', '//*[@id="link-report"]/div[1]/div/p/text()') item_loader.add_xpath('simple_author', '//*[@id="content"]/div/div[1]/div[3]/div[2]/span[2]/div/p/text()') item_loader.add_xpath('tags', '//*[@id="db-tags-section"]/div/span/a/text()') article_item = item_loader.load_item() yield article_item # 代码是不是看着清爽多了? - 但是,我们提取出字段后进行的正则或者其他处理能否集成进去呢?当然!
# items.py from scrapy.loader.processors import MapCompose, TakeFirst def regex_infos(value): ''' 处理item提取出的内容 这里是每次将list中的一个元素传过来 :param value: :return: ''' regex = '.*(\S+).*' # 匹配任何非空白字符 match = re.match(regex, value) if match: return value return None class ArticleItemLoader(ItemLoader): ''' 如果我们都是取第一个元素,不用在Field()都写一遍 ''' # 自定义default # default_output_processor = MapCompose(empty) # 会在前面报错! class DoubanArticleItem(scrapy.Item): front_img_url = scrapy.Field() front_img_path = scrapy.Field() title = scrapy.Field( # 只取list第一个 # output_processor = TakeFirst() ) infos_span = scrapy.Field( # 这里也可以传递匿名函数 input_processor=MapCompose(regex_infos) ) infos_text = scrapy.Field( input_processor=MapCompose(regex_infos) ) simple_content = scrapy.Field( ) simple_author = scrapy.Field( ) tags = scrapy.Field()- 这里有个坑,如果你的xpath没有取到值,这个字段直接不存在了(卧槽),后面就会KeyError,一开始没调试,想当然的正MapCompose呢,解决方案
- 配合使用
add_xpath和add_value即可:

- 这里还有个问题要重视,如果我们设置了
default_output_processor为TakeFirst,他会提取第一个值并转换为str;如果我们想返回的是list呢?可以定义一个函数直接返回value,覆盖掉default操作! - 当然,默认操作和输入输出操作都要根据爬取的内容灵活定义,代码精简少重复最好
- push你的代码
小结
- 到此,scrapy从数据爬取到存储,及代码的简单优化已经完成
- 每一次优化都要按spider、item、pipeline、settings顺序检查一下
- 调试是关键;逻辑上没问题你就看数据流,动态语言在这方面确实有些麻烦
- 明天爬啥呢?看见啥爬啥,是不可能的,很多网站都反爬,继续学习!