python3 批量定义多个变量_Python成为专业人士笔记-初探 Python 3,万字长文,看完入门!值得细细品读!...

“专业人士笔记”系列目录:
创帆云:Python成为专业人士笔记--强烈建议收藏!每日持续更新!zhuanlan.zhihu.com
Python的历史
Python是由Guido vanRossum创建并于1991年首次发布的,用于通用编程的广泛使用的高级编程语言。Python具有动态类型系统和自动内存管理功能,并支持多种编程范例,包括面向对象,命令式,函数式编程 ,以及面向过程编程。
它具有一个庞大而全面的标准库.Python的两个主要版本目前正在大规模使用:
Python 3.x是当前版本并且正在积极开发中
Python 2.x是旧版本并且在2020年之前将仅接受安全更新,不会再实现任何新功能。
因此,对于大多数开发者,尽快将python环境迁移到3版本是面向未来的最好选择
Python环境版本的确认
要确认是否已正确安装Python,可以通过在常用终端中运行以下命令来验证:
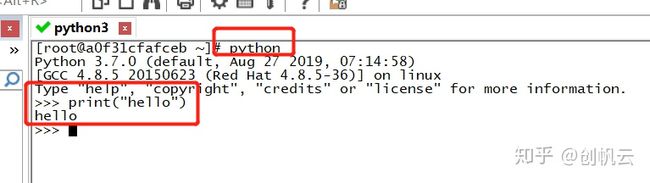
1、如果使用的Python3云环境(见目录中快速升级云环境),验证版本非常简单,只需用SSH工具连接上后,在linux交互命令下运行:
python -v如果结果显示如下图则版本是3.7
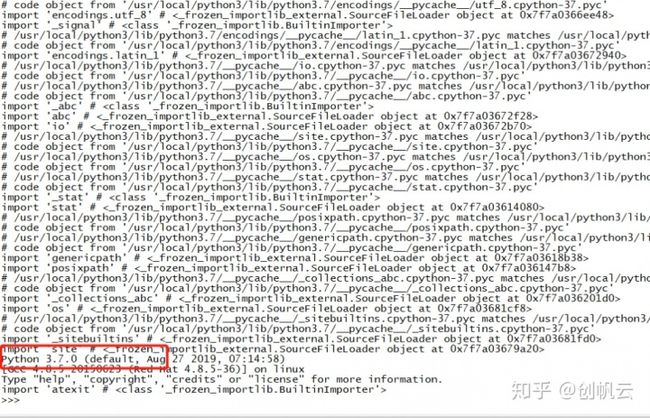
否则即是其他版本
2、如果使用本机Windows OS,则需要在命令提示符中使用python之前将python的路径添加到环境变量中后,使用同样的命令即可:
点击开始菜单—命令提示符—CMD 进入命令模式
python -v
显示如上图,也可确定python的版本
创建第一个hello world程序
1、使用Pycharm创建
打开软件,选择 新建项目–Pure Python
配置好本地代码与云Python3环境同步
步骤详见:
Pycharm本地代码云端同步biblog.bistudio.com.cn接着在新建的项目中,点击鼠标右键—-新建–python file
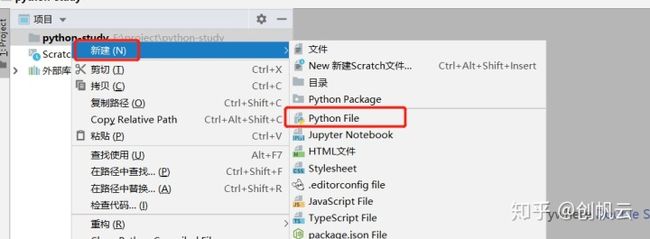
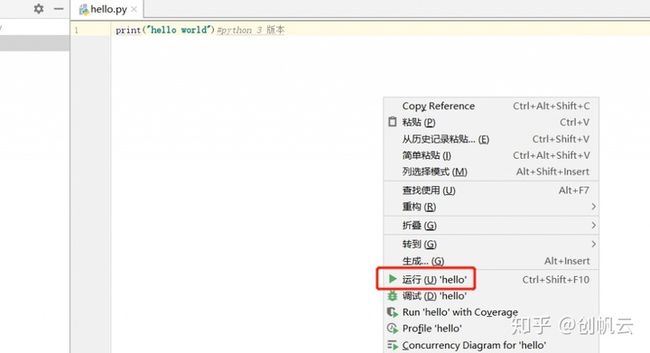
在新建的python文件中,写入
print("hello world") #python 3 版本在空白处鼠标点击右键,选择运行:
控制台成功输出:
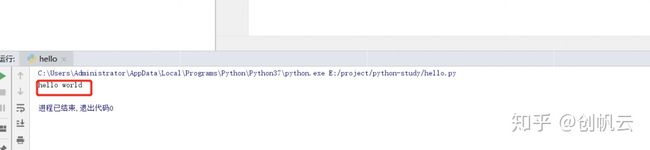
另外还可以使用pycharm直接在下方控制台运行python语句:
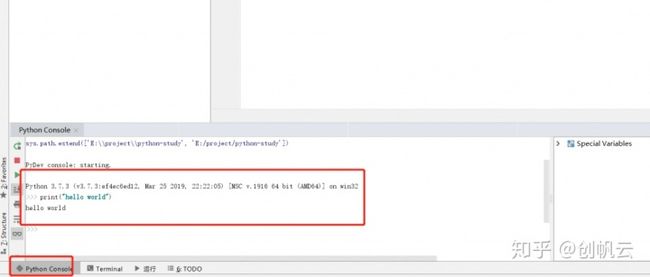
2、直接在python3云环境中新建:
登录创帆云官网
创帆云_python云环境云主机_wordpress网站建设_个人网站_免费上云_数据爬虫_免费bi工具_数据分析www.bistudio.com.cn
python3云环境开通后,进入右上角 控制台—订单管理—云环境,获取链接信息
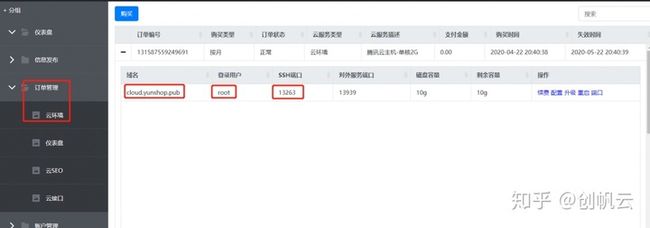
打开SSH连接工具,填入信息连接
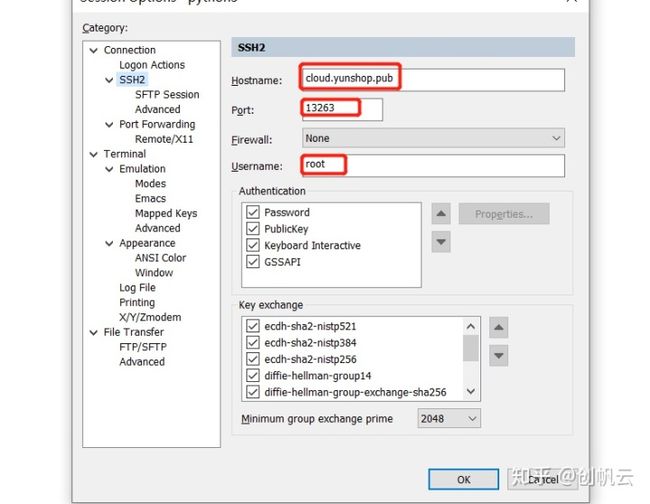
方式一:
直接命令行:
#在SSH控制台上直接输入
$python
#这时启动了交互模式
#再输入:
print("hello world") #python3版本
#完成方式二:
通过新建文件:
在命令行中,输入以下命令新建test.py文件
vi test.py弹出的页面中,按键盘”i”进入编辑模式,接着输入
print("hello world")#python 3 版本再按键盘“Esc”键取消编辑模式
继续输入”:wq”进行保存文件
接着命令运行python文件正常输出,命令如下:
python test.py
当然,也可以直接在交互端运行命令:
在python3云环境中,输入”python”启动交互模式
好的,对于python的初探、版本验证及第一个hello world程序介绍到这里
python创建变量并赋值
要在Python中创建一个变量,您所需要做的就是指定变量名,然后为它赋值
格式如下
= Python使用“=”来为变量赋值,不需要预先声明一个变量(或为其分配一个数据类型),只需为变量本身分配一个值就可以用该值声明并初始化该变量
注意:不能声明一个变量而不给它赋初值,这点和JAVA等编程语言有本质不同
下面在python3云环境上实际操作:
接下来开始讲述python变量相关内容:
python变量赋值
打开pycharm软件,参照上面文章应该已经与云环境同步了,输入代码:
# Integer 整数型
a =2print(a)
# 输出: 2
# Integer 整数型
b =9223372036854775807
print(b)
# 输出: 9223372036854775807
# Floating point 小数型
pi =3.14
print(pi)
# 输出: 3.14
# String 字符串型
c ='A'
print(c)
# 输出: A
# String
name ='John Doe'
print(name)
# 输出: John Doe
# Boolean 布尔值 真或假 True 或False
q =True
print(q)
# Output: True
# 空值或null类型
x =None
print(x)
# Output: None变量赋值从左到右工作,下面会给出一个错误样例
0= x
=> 将会输出: SyntaxError: can't assign to literal 因为赋值方向反了注意:不能使用python的关键字作为有效的变量名,你可以通过如下代码看到内置关键字列表
import keyword
print(keyword.kwlist)运行代码后打印出来的,不能作为变量名的列表
[‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘async’, ‘await’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
变量命名规则:
1、变量名必须以字母或下划线开头
2、变量名的其余部分可能由字母、数字和下划线组成
3、名称区分大小写
尽管在Python中声明变量时不需要指定数据类型,但当为变量在内存中分配必要的区域时,Python解释器会自动为它选择最合适的内置数据类型
现在你已经知道了赋值的基础知识,让我们来看看python中赋值的微妙之处
当使用=号执行赋值操作时,=号左边的名称是右边对象引用的代名词
然后,=所做的是将右边对象的引用分配给左边的名称
因此,从上面的许多赋值示例中,如果我们选择pi =3.14,那么pi就是对象3.14的一个代名词(而一个对象可以有多个名)。如果你不明白下面的内容,回到这一点,再读一遍!同样,你也可以看看这个来更好地理解
变量级联赋值
您可以在一行中为多个变量分配多个值。注意,在=操作符的左右两边必须有相同数量的参数
a, b, c =1,2,3
print(a, b, c)
# 输出: 1 2 3
a, b, c =1,2
#会报错: need more than 2 values to unpacka 因为有3个变量,但只赋了2个值
a,b =1,2,3
#同样会报错,因为只有2个变量,却赋了3个值当然, 你还可以同时将单个值分配给多个变量 ,如下代码:
a = b = c =1
print(a, b, c)
# 输出: 1 1 1在使用这种级联赋值时,需要注意的是,所有三个变量a、b和c都指向内存中的同一个对象,即值为1的int对象。换句话说,a、b和c是给同一int对象的三个不同的名称。正如所期望的那样,之后为其中一个对象分配不同的对象并不会改变其他对象
级联赋值对list对象引用需特别注意
这里有一点要注意的是,当list等可变类型进行级联赋值时,情况会很大的不同,看以下代码:
x = y =[7,8,9] #级联赋值 list列表
x[0]=13 #给列表中索引为0的(即当前值为7的那个),将值改成13
print(y) #输出列表y的值
#输出 [13, 8, 9]看到了吗?很奇怪,我明明改的是列表x的值,可是打印出y的值时候却发现y的值也发生变化了!
这是因为,在内存中,对于list列表类型存储的是引用,其中x和y都是同一个值的代名词,一旦其中一个发生更改,其他所有的都会同步更改!
嵌套list列表赋值
嵌套列表在python中也是有效的。这意味着一个列表可以包含另一个列表作为元素,如下代码
x =[1,2,[3,4,5],6,7]
print x[2]
# 输出: [3, 4, 5]
print x[2][1]
# 输出: 4python数据类型变化
Python中的变量不必保持它们最初定义时的类型——您可以简单地使用=将一个新值赋给一个变量,即使该值是另一种类型的值
如果您对此感到困扰,请考虑这样一个事实:
=左边的只是对象的名称。首先申明一个整数类型变量为a,其值为2
然后改变主意,决定将变量a变为一个string字符串对象,直接用a=‘new value’就可以自动切换数据类型,而不像java那样需要重新申明变量,就这么简单!
python的数据类型详解
内置数据类型:
bool类型值
俗称布尔值,只有真(True)或假(False)两个值, 像and、or、not这样的逻辑操作可以在布尔值上执行
x or y #如果X和y中有一个是True,则整体是True
x and y #只有x和y 都为True的时候,整体才是True
not x # x是False的时候,整体是True在Python中2和python3中,bool类型是int类型的一个子类,True和False是它唯一的实例
如果在算术运算中使用布尔值,它们的整数值(True为1,False为0)将被用来返回整数结果
比如:
True + False==1 # 类似 1 + 0 == 1
True * True==1 # 类似 1 * 1 == 1Numbers 数值类型
1、int 整数型
a =2 #给整数赋值
b =100Python中的整数是任意大小的; 注意: 在旧版本的Python中,long类型是可用的,这与int不同,两者是统一的
2、float 浮点小数型
支持e这样的科学计数法
a =2.0
b =100.e0
c =123456789.e13、 complex 复数
a =2 + 1j
b =100 + 10j注意:当任何操作数是复数时,操作符<、<=、>和>=将引发类型错误异常
4、 Strings 字符串类型
a) str类型: 一个unicode字符串,值为“hello”的类型
b) byte类型:字节字符串,值为b’hello’的类型;注意字串前面有一个字母’b’
序列和集合 数据类型
Python区分有序序列和无序集合(如set和dict):
1、有序序列
a)字符串(str,byte,unicode)是有序序列 ,如用 reversed函数将字符串反转排序后,和之前的值完全不一样
b) tuple元组: 任何类型的n个值的有序集合(n >=0)
如:a =(1,2,3) 和 b=(2,1,3)是两个不一样的元组
c)list列表: n个值的有序列表
如 a=[1,2,3]和b=[1,2,3]是两个不一样的列表
2、无序集合
a) set 集合:无序的值集合(不能有重复值)
如: a ={1,2,’a’} ,和 b={‘a’,2,1}是一样的集合,且集合中不可能有同一个值出现2次
b) dict 字典: 唯一键值对的无序集合
如: g ={‘a’: ‘1’,’b’:’2′} 存储的是键值对,访问方式是: print(g[“a’]),会输出值1
内建常量
与内置的数据类型一起,在内置的命名空间中有少量的内置常量
True:内置类型的布尔值的真值
False:内置类型的布尔值的假值
None:用于表示不存在的单例对象或空值
Ellipsis 或…:在核心Python3 +中不受限制地使用,在Python2.7 +中作为数组表示法的一部分受到限制使用。numpy和相关软件包将其用作数组中的“包括所有内容”引用
NotImplemented: 用于向Python表明某个特殊方法不支持特定参数,如果启用,Python将尝试替代方法
验证变量的类型
在python中,我们可以使用内置的函数类型检查对象的数据类型
a ='123'
print(type(a))
# 输出:
b =123
print(type(b))
# 输出: 可以使用isinstance返回数据类型,通常用在条件if语句判断中:
i =7
if isinstance(i,int):
i +=1
elif isinstance(i,str):
i =int(i)
i +=1
#判断如果是整数int类型则+1,是字符串str类型则先转为int型再+1判断变量是否为None的数据类型,稍微有点特殊,如下:
x =None
if x is None:
print('数据类型是None')变量的类型转化
可以执行显式数据类型转换。例如,’123’是str类型的,它可以使用int函数转换为整数。
a ='123'
b =int(a)可以使用float函数从浮点字符串(如’123.456′)进行转换
a ='123.456'
b =float(a)还可以转换序列或集合类型
a ='hello'
list(a)
# ['h', 'e', 'l', 'l', 'o']
set(a)
# {'o', 'e', 'l', 'h'}
tuple(a)
# ('h', 'e', 'l', 'l', 'o')在定义变量时可显式的指定string字串的子类型
可以 在引号前面加一个字母标签,定义具体是什么类型的字符串
b’foo bar’: 在python3中返回 byte型,在python2中返回 str 型
u’foo bar’ : 在python3中返回 str型,在python2中返回 unicode 型
‘foo bar’ : 都返回 str型
r’foo bar’: 原始字符串,其中无需转义特殊字符,键入时一切都按原样
可变和不可变的数据类型
如果一个对象可以改变值,那么它就叫做可变数据类型。
例如,当你将一个列表传递给某个函数时,该列表可以被函数内的代码改变
def f(m):
m.append(3) # 向列表中添加一个数字。这是一个修改.
x = [1, 2]
f(x)
x == [1, 2] # 现在为False,因为列表中添加了一个项如果对象不能以任何方式更改,则称其为不可变的。例如,整数是不可变的,因为没有办法改变它们
def bar():
x = (1, 2)
g(x)
x == (1, 2) # 总是返回真 True,因为没有函数可以改变对象 (1, 2)注意,变量本身是可变的,所以我们可以重新分配变量x,但这不会改变x之前指向的对象。它只是让x指向了一个新对象。
实例是可变的数据类型称为可变数据类型,对于不可变对象和数据类型也是如此
不可变数据类型的例子
int, long, float, complex
str
bytes
tuple
frozenset
可变数据类型的例子
bytearray
list
set
dict
Python的数据结构
Python中有许多集合类型,像int和str等类型只包含一个值,而集合类型包含多个值
Lists 列表
列表类型可能是Python中最常用的集合类型,除了它的名字,列表更像是其他语言中的数组,尤其是像JavaScript。
在Python中,列表只是有效Python值的有序集合。可以通过在方括号中以逗号分隔的封闭值来创建列表 ,如下:
int_list = [1, 2, 3]
string_list = ['abc', 'defghi']列表可以是空的
empty_list = []列表的元素不局限于单一的数据类型,考虑到Python是一种动态语言这是非常有意义的创新
mixed_list = [1, 'abc', True, 2.34, None]一个列表可以包含另一个列表作为它的元素
nested_list = [['a', 'b', 'c'], [1, 2, 3]]可以通过索引或位置的数字表示访问列表的元素。Python中的列表是零索引的,这意味着列表中的第一个元素在索引0处,第二个元素在索引1处,依此类推
names = ['Alice', 'Bob', 'Craig', 'Diana', 'Eric']
print(names[0]) # Alice
print(names[2]) # Craig索引也可以是负的,这意味着从列表的末尾开始计数(-1是最后一个元素的索引)。因此,使用上面例子中的列表:
print(names[-1]) # Eric
print(names[-4]) # Boblist是可变的,因此你可以更改list中的值 :
names[0] = 'Ann'
print(names)
#输出 ['Ann', 'Bob', 'Craig', 'Diana', 'Eric']此外,可以从列表中添加和/或删除元素,使用append(object)将对象追加到列表末尾
names = ['Alice', 'Bob', 'Craig', 'Diana', 'Eric']
names.append("Sia")
print(names)
输出 ['Alice', 'Bob', 'Craig', 'Diana', 'Eric', 'Sia']添加一个新元素在指定的索引上,用insert(index, object)
names.insert(1, "Nikki")
print(names)
输出 ['Alice', 'Nikki', 'Bob', 'Craig', 'Diana', 'Eric', 'Sia']使用remove(value)删除第一个出现的值
names.remove("Bob")
print(names)
# 输出 ['Alice', 'Nikki', 'Craig', 'Diana', 'Eric', 'Sia']获取第一个值为‘ Alice ’的项的列表中的索引。如果列表中没有这个值,它将显示一个错误
name.index("Alice")
#返回0计算list的长度
len(names)
输出 6统计列表中某个项的出现次数
a = [1, 1, 1, 2, 3, 4]
a.count(1)
#输出3反转列表
a.reverse()
[4, 3, 2, 1, 1, 1]
或者
a[::-1]
[4, 3, 2, 1, 1, 1]使用pop([index]) 删除并返回项目在索引(默认为最后一个项目)处的值,并返回这个值
names.pop() # 输出 ‘Sia’,这是list中最后一个值,现在已经被删除
您可以像下面这样迭代列表元素:
for element in my_list:
print (element)Tuples 元组
元组类似于列表,但它是固定长度和不可变的。因此,既不能更改tuple中的值,也不能在tuple中添加或删除值。元组通常用于不需要更改的值的小集合,如IP地址和端口。元组由圆括号表示,而不是方括号
ip_address = ('10.20.30.40', 8080)列表的索引规则也适用于元组。元组也可以嵌套,值可以是任何有效的Python允许的值,只有一个成员的元组必须这样定义(注意逗号) :
one_member_tuple = ('Only member',)或者
one_member_tuple = 'Only member'或只是使用元组语法 :
one_member_tuple = tuple(['Only member'])Dictionaries 字典
Python中的字典是键值对的集合,字典被花括号包围着;每一对由逗号分隔,键和值由冒号分隔,这是一个例子:
state_capitals = {
'Arkansas': 'Little Rock',
'Colorado': 'Denver',
'California': 'Sacramento',
'Georgia': 'Atlanta'
}要获得一个值,通过它的键来引用它 :
ca_capital = state_capitals['California']您还可以获得字典中的所有键,然后对它们进行迭代
for k in state_capitals.keys():
print('{} is the capital of {}'.format(state_capitals[k], k))字典非常类似JSON语法,Python标准库中的原生json模块可用于在json和字典之间进行转换。
set 集合
集合是一组元素的集合,没有重复,没有顺序,它们只在某些情况下使用,即某些东西组合在一起是很重要的,而不涉及它们的顺序。对于数据比较多的情况,检查元素是否在集合中比检查list列表要快得多。
定义集合与定义字典非常相似:
first_names = {'Adam', 'Beth', 'Charlie'}也可以使用现有列表构建一个集合 :
my_list = [1,2,3]
my_set = set(my_list)使用in检查集合中是否有该成员:
if name in first_names:
print(name)你可以像列表一样遍历一个集合,但是请记住:这些值将以任意的的顺序出现
default dict 默认字典
defaultdict是一个键值为默认值的字典,因此没有显式定义值的键可以在没有错误的情况下访问。defaultdict在字典中的值是集合(列表、dict等)时特别有用,因为它不需要在每次使用新键时都进行初始化。
defaultdict永远不会引发key错误。任何不存在的键都会返回默认值。
例如,考虑下面的字典 :
state_capitals = {
'Arkansas': 'Little Rock',
'Colorado': 'Denver',
'California': 'Sacramento',
'Georgia': 'Atlanta'
}如果我们试图访问一个不存在的key,python会返回一个错误,如下所示
state_capitals['Alabama']
Traceback (most recent call last):
File "", line 1, in
state_capitals['Alabama']
KeyError: 'Alabama'让我们尝试使用defaultdict,它可以在集合模块中找到
from collections import defaultdict
state_capitals = defaultdict(lambda: 'Boston')我们在这里所做的是设置一个默认值(Boston),以防所给的键不存在。现在像以前一样填充dict :
state_capitals['Arkansas'] = 'Little Rock'
state_capitals['California'] = 'Sacramento'
state_capitals['Colorado'] = 'Denver'
state_capitals['Georgia'] = 'Atlanta'如果我们试图使用不存在的键访问dict, python将返回默认值,即Boston
state_capitals['Alabama']
输出'Boston'同时也能像普通字典一样返回之前创建过的值
state_capitals['Arkansas']
输出'Little Rock'Python程序中与用户交互
要从用户获取输入,请使用input函数
name = input("你名什么名字")
#输出: 你叫什么名字? _本例的其余部分都将使用Python 3语法
该函数接受一个字符串参数,该参数将其显示为提示并返回一个字符串;上面的代码提供了一个提示,等待用户输入。
如果用户键入“Bob”并点击回车,变量名name将被分配给字符串“Bob”
name = input(" 你叫什么名字? ")
#输出: 你叫什么名字? 这个时候如果用户在键盘上输入 Bob
print(name)
#打印出: Bob注意,用户输入总是str类型的,如果您希望用户输入数字,这一点尤其要注意;因此,在尝试将str用作数字之前,需要先对用户输入的Str转换至具体数字类型,如:
day_str=input("今天几号?")
day_num=int(day_str)
print(day_num+1)
#程序会把用户输入的今天几号,再+1天,如果不把str转化为整数,程序会报错
(也许大家想python可以隐式转换,但是对于程序设计者时时了解当前数据的类型是必要的)但是,由于用户输入的不可预测性,这里强烈建议使用异常处理程序
在处理用户输入时,使用try / except块来捕获异常。 例如,如果你的代码想要将原始的输入值转换为int,并且用户输入的内容转换过来错误时,这将引发程序抛出ValueError错误
python中的空白tab缩进
Python使用缩进来定义控制和循环结构,这有助于提高Python的可读性,但是,它要求程序员密切注意空格缩进的使用:因为,编辑器错误的校准可能会导致代码出现意想不到的行为。
Python使用冒号(:)和缩进来显示代码块的开始和结束位置(如果你使用过其他另一种语言,请不要将其与三元运算符相混淆)。
也就是说,Python中的块,如函数、循环、if子句和其他结构,没有专门结束标识符,所有块都以冒号开头,然后包含它下面的对应缩进后的子代码行。
例如:
def my_function(): # 这是一个函数定义。注意冒号(:)
a = 2
return a
# 上面2行属于这个函数,因为它是Tab缩进的,返回 return 这一行也属于同一个函数
print(my_function())
#这行代码不属于函数,因为没有用Tab进行缩进或者:
if a > b: # If 语句开始于这里
print(a)
#属于if里一部分
else: # else 语句和if是同一级
print(b)
#属于else里面的子语句只包含一行语句的块可以放在同一行上,尽管这种形式通常被认为是不好的代码习惯:
if a > b: print(a)
else: print(b)尝试使用多个语句来实现这一点是行不通的:
if x > y: y = x
print(y)
# IndentationError: unexpected indent 未知的间隔
if x > y: while y != z: y -= 1
SyntaxError: invalid syntax 语法错误空块会导致IndentationError错误。当您有一个没有内容的块时,使用pass(一个什么都不做的命令) :
def will_be_implemented_later():
passSpaces(空格) 对比. Tabs(制表符)
简而言之:
始终使用4个空格作为缩进,只使用制表符当然也可以,但是Python代码的样式指南PEP 8中声明空格是首选的(但我个人觉得很麻烦,我一般都用Tab)。
Python 3不允许混合使用制表符和空格进行缩进,在这种情况下,会产生编译时错误 : 在缩进中不一致地使用制表符和空格,程序将无法运行。
Python 2允许在缩进中混合制表符和空格,但强烈不建议这样做。制表符完成前面的缩进操作,会变成8个空格的倍数,由于编辑器通常被配置为以4个空格的倍数显示选项卡,这可能会导致一些细微的错误。
许多编辑器都有“制表符到空格”的配置。在配置编辑器时,应该区分制表符(‘t’)和制表键:制表符应该配置为显示8个空格,以匹配语言语义——至少在可能出现(意外)混合缩进的情况下, 编辑器还可以自动将制表符转换为空格 。
然而,往往直接将编辑器中的Tab键配置为自动插入4个空格,而不是插入制表符,这样更符合python程序开发中的简便性要求
用制表符和空格混合编写的Python源代码,或者使用非标准数量的缩进空格,可以使用autopep8(大多数Python安装都提供了一个不太强大的替代方案:reindent.py包来处理这个问题)
综上,我个人建议,对于具体替代方案不用做过多研究,只要在pycharm这样的开发环境中,用tab键缩进代码即可,编译能通过,大部分情况下是没有问题的。
内置模块Modules和函数Functions
模块是一个包含Python定义和语句的文件,而函数是执行逻辑的一段代码 。
要检查python中内置的函数,可以使用dir()。如果调用的时候不带任何参数,则返回当前范围中的名称。否则,返回一个按字母顺序排列的名称列表,其中包含(一些)给定对象的属性,以及从中可以访问的属性。
尝试运行如下命令显示所有函数:
dir(builtins)
输出:
[
'ArithmeticError',
'AssertionError',
'AttributeError',
'BaseException',
'BufferError',
'BytesWarning',
'DeprecationWarning',
'EOFError',
'Ellipsis',
'EnvironmentError',
'Exception',
'False',
'FloatingPointError',
'FutureWarning',
'GeneratorExit',
'IOError',
'ImportError',
'ImportWarning',
'IndentationError',
'IndexError',
'KeyError',
'KeyboardInterrupt',
'LookupError',
'MemoryError',
'NameError',
'None',
'NotImplemented',
'NotImplementedError',
'OSError',
'OverflowError',
'PendingDeprecationWarning',
'ReferenceError',
'RuntimeError',
'RuntimeWarning',
'StandardError',
'StopIteration',
'SyntaxError',
'SyntaxWarning',
'SystemError',
'SystemExit',
'TabError',
'True',
'TypeError',
'UnboundLocalError',
'UnicodeDecodeError',
'UnicodeEncodeError',
'UnicodeError',
'UnicodeTranslateError',
'UnicodeWarning',
'UserWarning',
'ValueError',
'Warning',
'ZeroDivisionError',
'debug',
'doc',
'import',
'name',
'package',
'abs',
'all',
'any',
'apply',
'basestring',
'bin',
'bool',
'buffer',
'bytearray',
'bytes',
'callable',
'chr',
'classmethod',
'cmp',
'coerce',
'compile',
'complex',
'copyright',
'credits',
'delattr',
'dict',
'dir',
'divmod',
'enumerate',
'eval',
'execfile',
'exit',
'file',
'filter',
'float',
'format',
'frozenset',
'getattr',
'globals',
'hasattr',
'hash',
'help',
'hex',
'id',
'input',
'int',
'intern',
'isinstance',
'issubclass',
'iter',
'len',
'license',
'list',
'locals',
'long',
'map',
'max',
'memoryview',
'min',
'next',
'object',
'oct',
'open',
'ord',
'pow',
'print',
'property',
'quit',
'range',
'raw_input',
'reduce',
'reload',
'repr',
'reversed',
'round',
'set',
'setattr',
'slice',
'sorted',
'staticmethod',
'str',
'sum',
'super',
'tuple',
'type',
'unichr',
'unicode',
'vars',
'xrange',
'zip'
]要了解任何函数的功能及属性,我们可以使用内建函数帮助,方法是命令运行:help(函数名)
比如:
help(max)
输出:
Help on built-in function max in module builtin:
max(…)
max(iterable[, key=func]) -> value
max(a, b, c, …[, key=func]) -> value
在单个可迭代参数中,返回其最大的项。使用两个或多个参数,返回最大的参数。而内建模块则包含一些额外的函数。例如,为了得到一个数字的平方根,我们需要包括数学(math)模块
import math
math.sqrt(16) # 输出4.0为了了解模块中的所有函数,我们可以将函数名称分配给一个变量,然后打印该变量。
import math
print(dir(math))
输出:
['doc', 'name', 'package', 'acos', 'acosh',
'asin', 'asinh', 'atan', 'atan2', 'atanh', 'ceil', 'copysign',
'cos', 'cosh', 'degrees', 'e', 'erf', 'erfc', 'exp', 'expm1',
'fabs', 'factorial', 'floor', 'fmod', 'frexp', 'fsum', 'gamma',
'hypot', 'isinf', 'isnan', 'ldexp', 'lgamma', 'log', 'log10',
'log1p', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh', 'sqrt',
'tan', 'tanh', 'trunc']除了函数之外,还可以在模块中提供文档。如果你有一个像这样的名为helloWorld.py的文件
""" 这是模块内函数的定义."""
def sayHello():
"""这是模块内函数的代码"""
return 'Hello World'您可以像这样访问它:
import helloWorld
helloWorld.__doc__
'这是模块的描述'
helloWorld.sayHello.__doc__
'这是函数的描述'对于所有用户定义的类型,都可以使用dir()来检索其属性、类的属性以及递归地检索其类的基类的属性
比如,创建一个class类:
class MyClassObject(object):
pass我们来检索它的定义:
dir(MyClassObject)
输出:
['class', 'delattr', 'dict', 'doc', 'format', 'getattribute', 'hash',
'init', 'module', 'new', 'reduce', 'reduce_ex', 'repr', 'setattr',
'sizeof', 'str', 'subclasshook', 'weakref']任何数据类型都可以使用名为str的内置函数简单地转换为字符串。在将变量传递给print时,默认情况下都会调用该函数 ,比如:
str(123)
#输出 "123",因为默认的print打印都会转成Str字符串打印到屏幕创建用户自定义Module模块
模块是包含定义和语句的可导入文件 ,可以通过创建.py文件来创建一个单独的用户自定义模块。
如下代码:
#hello.py
def say_hello():
print("Hello!")模块中的函数可以通过导入模块来使用
对于创建的用户自定义模块,它们需要与准备导入此模块的其他文件位于相同的目录中(但是,你也可以将它们与Python内置模块一起放到Python lib目录中,但是应该尽可能避免这样做,以区分内置模块和用户自定义模块)
可以这样调用模块:
import hello
print(hello.say_hello())
#输出 'hello'当然,模块也可以由其他模块导入:
#这是另外一个文件,greet.py
import hello
hello.say_hello()也可以只导入模块中的特定函数:
# greet.py
from hello import say_hello
say_hello()导入的模块可以被重命名:
# greet.py
import hello as ai #重命名为ai了
ai.say_hello()模块可以是完全独立的可运行脚本:
#创建一个单独的run_hello.py文件
if __name__ ==__'main__':
from hello import say_hello
say_hello()上面这个模块,可以直接单独运行:
#进入云环境交互模式:
$ python run_hello.py
=> "Hello!"这里解析一下上面语句的写法:
1、__name__ ==__’main__’,这条语句是python固定入口的写法,这样写相当于指定该模块是整个程序的入口函数,如果你学习过Java,那么对于java的入口函数main函数应该很熟悉,两个作用是一样的
2、注意:如果模块位于一个目录中,此时如需要在当前目录中其他文件中引用,那么该目录需要包含一个名为__init__.py的文件,向python解析器表示本目录间有相互引用;而关于__init_.py文件中的内容,你完全可以空着,只是需要新建有这个文件就可以了
返回变量形式函数- str() 和 repr()
有两个函数可用于获取对象的可读表示 ,常用于打印输出及类型转换:
repr(x) : 结合eval函数使用通常会将该变量的结果转换回原始对象,即将对象转化为供编译器(即机器)读取的形式。
str(x) : 返回描述对象的可读字符串(即人类可读),由于会自动类型转换,这可能隐藏了一些技术转换细节。
补充介绍:eval()
函数用来执行一个字符串表达式,并返回表达式的值
如下代码:
>>>x = 7
>>> eval( '3 * x' )
#输出:21注:
repr()
对于许多变量类型,此函数尝试返回一个字符串,它会尽量把原始相同的值作为参数传递给其他函数,比如结合eval()函数使用;同时它会传递一些其它的信息,包括名称、所在内存地址等等对象信息,以保证变量的原始传递,而不丢失机器信息
str()
对于字符串,它返回字符串本身。这与repr(object)的区别在于,str(object)并不总是试图返回一个eval()可以接受的字符串。相反,它的目标是返回一个可打印的或“人类可读的”字符串。如果没有给出参数,则返回空字符串
举例1:
s = """w'o"w"""
repr(s) # 输出: ''w'o"w''
str(s)
#输出: 'w'o"w'
eval(str(s)) == s # 报语法错误
eval(repr(s)) == s # 输出:True举例2:
import datetime
today = datetime.datetime.now()
str(today)
#输出: '2016-09-15 06:58:46.915000'
repr(today)
# 输出: 'datetime.datetime(2016, 9, 15, 6, 58, 46, 915000)'看到没有,人类可读和机器可读其实有本质的区别
在编写类时,你可以覆盖这些方法来做任何你想做的事情 :
class Represent(object):
def __init__(self, x, y):#注:__init_是类class的构造函数
self.x, self.y = x, y
def __repr__(self):
return "Represent(x={},y="{}")".format(self.x, self.y)
def __str__(self):
return "Representing x as {} and y as {}".format(self.x, self.y)使用上面的类,我们可以看到以下结果:
r = Represent(1, "Hopper")
print(r)
#打印默认调用了__str__函数
print(r.__repr__)
# 显式调用了 __repr__方法,打印了: 'Help 帮助功能
Python有几个内置在解释器中的函数,如果您想获得关键字、内置函数、模块或主题的信息,请打开Python云环境命令行并输入 :
>>> help()这个时候会进入帮助的交互模式,如下图:
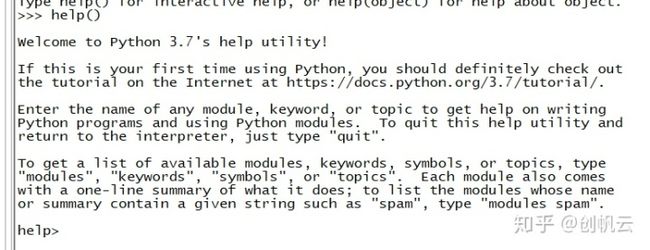
当通过直接输入关键字,就会打印出帮助信息,比如我想看math模块,这个模块到底干什么用的,里面可以用哪些函数等:
注意:此时必须已经通过help()进入交互模式下:
输入:
>>> mathpython云环境中 返回结果如下图:

按“空格”可以不断的向下滚动浏览
好了,今天的分享就到这里,禁止转载,违者必究!