java爬取网易云歌单_爬虫爬取网易云歌单
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取网易云音乐歌单
2.主题式网络爬虫爬取的内容与数据特征分析
爬取网易云音乐歌单前十页歌单,轻音乐类型的歌单名称、歌单播放量、歌单链接、用户名称。
分析歌单播放量和歌单标题关键词
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:使用单线程爬取,初始化信息,设置请求头部信息,获取网页资源,使用etree进行网页解析,爬取多页时刷新offset,将爬取数据保存到csv文件中。
难点:使用的翻页形式为URL的limit和offset参数,发送的get请求时froms和url的参数要一至。
二、主题页面的结构特征分析
1.主题页面的结构特
三、网络爬虫程序设计
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集
from urllib import parse
from lxml import etree
from urllib3 import disable_warnings
import requests
import csv
class Wangyiyun(object):
def __init__(self, **kwargs):
# 歌单的歌曲风格
self.types = kwargs['types']
# 歌单的发布类型
self.years = kwargs['years']
# 这是当前爬取的页数
self.pages = pages
# 这是请求的url参数(页数)
self.limit = 35
self.offset = 35 * self.pages - self.limit
# 这是请求的url
self.url = "https://music.163.com/discover/playlist/?"
# 设置请求头部信息(可扩展:不同的User - Agent)
def set_header(self):
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Referer": "https://music.163.com/",
"Upgrade-Insecure-Requests": '1',
}
return self.header
# 设置请求表格信息
def set_froms(self):
self.key = parse.quote(self.types)
self.froms = {
"cat": self.key,
"order": self.years,
"limit": self.limit,
"offset": self.offset,
}
return self.froms
# 解析代码,获取有用的数据
def parsing_codes(self):
page = etree.HTML(self.code)
# 标题
self.title = page.xpath('//div[@class="u-cover u-cover-1"]/a[@title]/@title')
# 作者
self.author = page.xpath('//p/a[@class="nm nm-icn f-thide s-fc3"]/text()')
# 阅读量
self.listen = page.xpath('//span[@class="nb"]/text()')
# 歌单链接
self.link = page.xpath('//div[@class="u-cover u-cover-1"]/a[@href]/@href')
# 将数据保存为csv文件
data=list(zip(self.title,self.author,self.listen,self.link))
with open('yinyue.csv','a',encoding='utf-8',newline='') as f:
writer=csv.writer(f)
#writer.writerow(header)
writer.writerows(data)
# 获取网页源代码
def get_code(self):
disable_warnings()
self.froms['cat']=self.types
disable_warnings()
self.new_url = self.url+parse.urlencode(self.froms)
self.code = requests.get(
url = self.new_url,
headers = self.header,
data = self.froms,
verify = False,
).text
# 爬取多页时刷新offset
def multi(self ,page):
self.offset = self.limit * page - self.limit
if __name__ == '__main__':
# 歌单的歌曲风格
types = "说唱"
# 歌单的发布类型:最热=hot,最新=new
years = "hot"
# 指定爬取的页数
pages = 10
# 通过pages变量爬取指定页面
music = Wangyiyun(
types = types,
years = years,
)
for i in range(pages):
page = i+1 # 因为没有第0页
music.multi(page) # 爬取多页时指定,传入当前页数,刷新offset
music.set_header() # 调用头部方法,构造请求头信息
music.set_froms() # 调用froms方法,构造froms信息
music.get_code() # 获取当前页面的源码
music.parsing_codes() # 处理源码,获取指定数据
对数据进行清洗和处理
import pandas as pd
#读取文件
data=pd.read_csv(r"yinyue.csv",encoding = "utf-8")
data.columns=('title','author','listen_num','link')
data
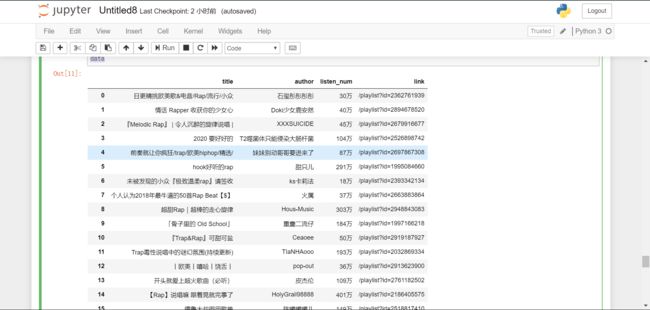
#删除没有万单位的行
data = data[data["listen_num"].str[-1] == "万"]
data
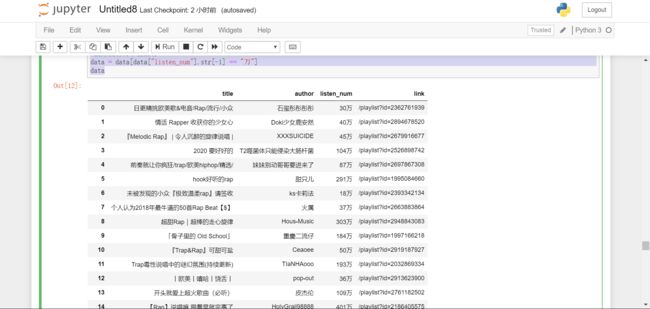
#删除万单位
data['listen_num'] = data['listen_num'].str.strip("万").apply(int)
data
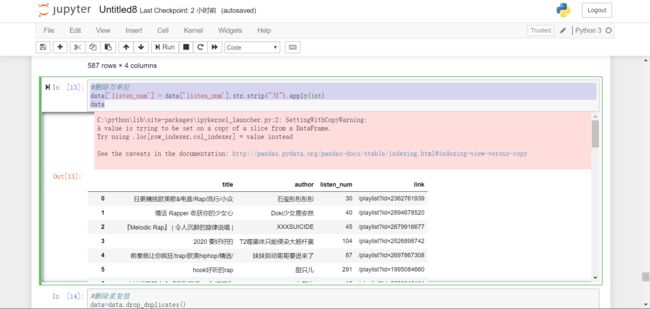
#删除重复值
data=data.drop_duplicates()
data.head()

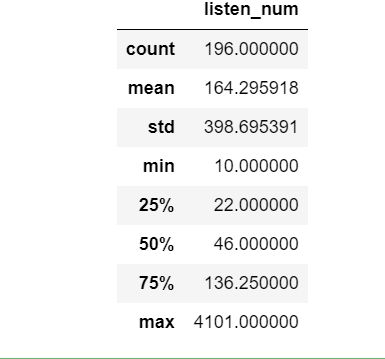
data.describe()
#按播放数量进行降序排序
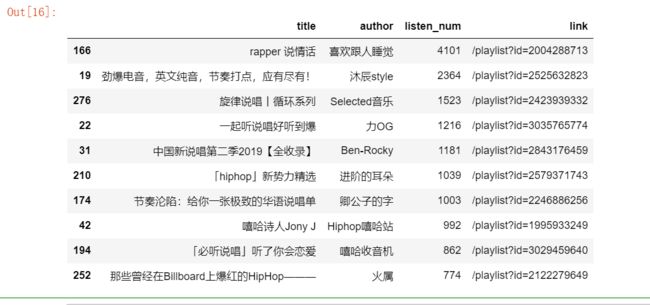
data = data.sort_values('listen_num',ascending = False).head(10)
data
3.文本分析(可选):jieba分词、wordcloud可视化
4.数据分析与可视化:
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
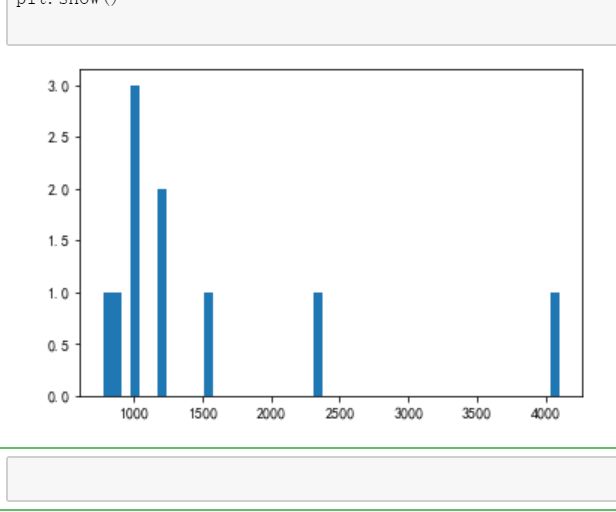
#绘制柱状图查看top50歌单的播放量分布
plt.hist(data['listen_num'],bins=50)
plt.show()
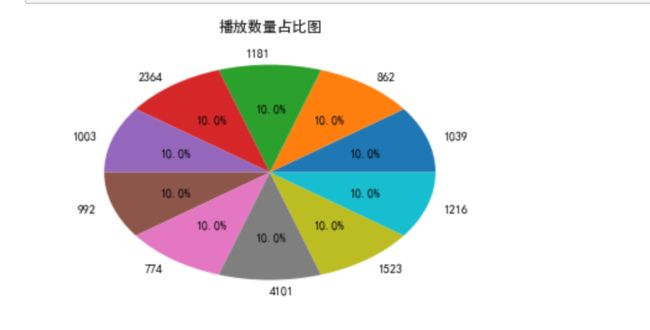
#绘制饼状图
plt.rcParams['font.sans-serif'] = ['SimHei']#解决乱码问题
df_score = data['listen_num'].value_counts() #统计评分情况
plt.title("播放数量占比图") #设置饼图标题
plt.pie(df_score.values,labels = df_score.index,autopct='%1.1f%%') #绘图
#autopct表示圆里面的文本格式,在python里%操作符可用于格式化字符串操作
plt.show()
5.数据持久化
data.to_csv("./wangyiyun.csv")
data
7.全部代码
from urllib import parse
from lxml import etree
from urllib3 import disable_warnings
import requests
import csv
class Wangyiyun(object):
def __init__(self, **kwargs):
# 歌单的歌曲风格
self.types = kwargs['types']
# 歌单的发布类型
self.years = kwargs['years']
# 这是当前爬取的页数
self.pages = pages
# 这是请求的url参数(页数)
self.limit = 35
self.offset = 35 * self.pages - self.limit
# 这是请求的url
self.url = "https://music.163.com/discover/playlist/?"
# 设置请求头部信息(可扩展:不同的User - Agent)
def set_header(self):
self.header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Referer": "https://music.163.com/",
"Upgrade-Insecure-Requests": '1',
}
return self.header
# 设置请求表格信息
def set_froms(self):
self.key = parse.quote(self.types)
self.froms = {
"cat": self.key,
"order": self.years,
"limit": self.limit,
"offset": self.offset,
}
return self.froms
# 解析代码,获取有用的数据
def parsing_codes(self):
page = etree.HTML(self.code)
# 标题
self.title = page.xpath('//div[@class="u-cover u-cover-1"]/a[@title]/@title')
# 作者
self.author = page.xpath('//p/a[@class="nm nm-icn f-thide s-fc3"]/text()')
# 阅读量
self.listen = page.xpath('//span[@class="nb"]/text()')
# 歌单链接
self.link = page.xpath('//div[@class="u-cover u-cover-1"]/a[@href]/@href')
# 将数据保存为csv文件
data=list(zip(self.title,self.author,self.listen,self.link))
with open('yinyue.csv','a',encoding='utf-8',newline='') as f:
writer=csv.writer(f)
#writer.writerow(header)
writer.writerows(data)
# 获取网页源代码
def get_code(self):
disable_warnings()
self.froms['cat']=self.types
disable_warnings()
self.new_url = self.url+parse.urlencode(self.froms)
self.code = requests.get(
url = self.new_url,
headers = self.header,
data = self.froms,
verify = False,
).text
# 爬取多页时刷新offset
def multi(self ,page):
self.offset = self.limit * page - self.limit
if __name__ == '__main__':
# 歌单的歌曲风格
types = "说唱"
# 歌单的发布类型:最热=hot,最新=new
years = "hot"
# 指定爬取的页数
pages = 10
# 通过pages变量爬取指定页面
music = Wangyiyun(
types = types,
years = years,
)
for i in range(pages):
page = i+1 # 因为没有第0页
music.multi(page) # 爬取多页时指定,传入当前页数,刷新offset
music.set_header() # 调用头部方法,构造请求头信息
music.set_froms() # 调用froms方法,构造froms信息
music.get_code() # 获取当前页面的源码
music.parsing_codes() # 处理源码,获取指定数据
import pandas as pd
#读取文件
data=pd.read_csv(r"yinyue.csv",encoding = "utf-8")
data.columns=('title','author','listen_num','link')
data
#删除没有万单位的行
data = data[data["listen_num"].str[-1] == "万"]
data
#删除万单位
data['listen_num'] = data['listen_num'].str.strip("万").apply(int)
data
#删除重复值
data=data.drop_duplicates()
data.head()
data.describe()
#按播放数量进行降序排序
data = data.sort_values('listen_num',ascending = False).head(10)
data
#绘制柱状图
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
#绘制柱状图查看top50歌单的播放量分布
plt.hist(data['listen_num'],bins=50)
plt.show()
#绘制饼状图
plt.rcParams['font.sans-serif'] = ['SimHei']#解决乱码问题
df_score = data['listen_num'].value_counts() #统计评分情况
plt.title("播放数量占比图") #设置饼图标题
plt.pie(df_score.values,labels = df_score.index,autopct='%1.1f%%') #绘图
#autopct表示圆里面的文本格式,在python里%操作符可用于格式化字符串操作
plt.show()
#绘制直方图查看播放数量的分布
sns.distplot(data['listen_num'])
data.to_csv("./wangyiyun.csv")
data
四、结论:
①数据分析时爬取的数据比较乱,要经过一个连套的数据清洗。
②数据清洗对数据可视化提供了很大的方便。
③top50歌单播放量大部分集中在1000万左右。
④歌单前十页的说唱类型播放量在1000万到2000万居多。
2、小结:
在爬取数据过程中,在解析网页代码时,返回的是空列表,经过检查网页源代码,发现原来我们所提取的元素包含在标签内部,这样我们是无法直接定位的,所以必须先切换到iframe中,在爬去过程中小问题很多,到最后爬取到的数据也很“脏”,但是经过数据清洗后,还是可得到一些结论的,经过本次作业中,学习到了必须有耐心和细心,这在往后的码农生涯将会很受用。