爬虫百战穿山甲(4):帮学弟学妹们看看高考选科走班指南

郑重申明:本文仅为研究学习使用。
文章目录
-
- 网页分析
- 代码实现
- 优化小思路
网页分析
网址:http://wjt.a.101.com/activity/2020/gaokaotool/search-km.shtml

目前是有八个省的数据,但是其他几个省的数据都有Excel直接下载了,所以就选择福建的啦。
能简单就简单嘛。
可以看到页面中有两个下拉框和一个“开始查询”按钮,且让我们点击一下查询按钮看情况。
点击之后发现,依旧是一个动态网页。
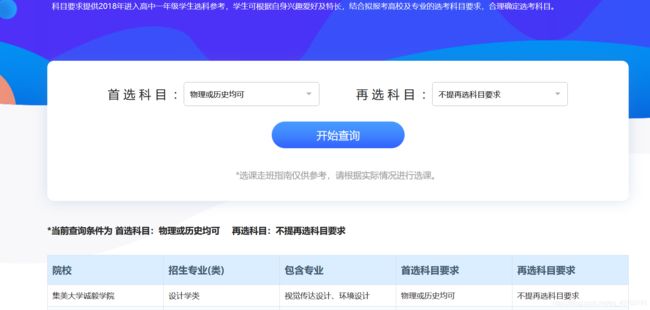
所以我们熟练地点开网络抓包工具:
就一个包,没什么好说的,点开看:
url:
https://wjt-subject-tool-api.sdp.101.com/v1/actions/manage?page_size=30&page=1&f_subject=%E7%89%A9%E7%90%86%E6%88%96%E5%8E%86%E5%8F%B2%E5%9D%87%E5%8F%AF&s_subject=%E4%B8%8D%E6%8F%90%E5%86%8D%E9%80%89%E7%A7%91%E7%9B%AE%E8%A6%81%E6%B1%82
这个url是经过编码的,看起来很乱,但是你放到网址查询框里解析出中文之后你就明白是什么意思了。
page:页面大小
f_subject:首选科目
s_subject:再选科目
接下来,就是一个难点出现了:咱不知道它有多少页,咱也不想去看它有多少页。
但是就算是个空页面,也是可以被爬下来的,只不过爬到的是空数据。
在解析的时候就会卡住。
最后想了个土办法才解决掉,但是感觉不是很好。
但是,今天我又重新审视了一下,发现了网址中的另一个参数:page_size。
只要我给一个足够大的page_size,我管你几页到底啊?反正就都在一页给我到底。
开个玩笑啊,适当调节页面大小就好了,该判断还是判断一下,因为我爬完发现,这些不同的选项搭配,获取的数据量天差地别。
代码实现
# #coding:utf-8
import requests
from lxml import etree
import random
user_agent_list = [
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X 10.5; en-US; rv:1.9.2.15) Gecko/20110303 Firefox/3.6.15",
]
def get_html(url,times):
'''
这是一个用户获取网页源数据的函数
:param url: 目标网址
:param times: 递归执行次数
:return: 如果有,就返回网页数据,如果没有,返回None
'''
try:
res = requests.get(url = url,headers = {
"User-Agent":random.choice(user_agent_list)
}) #带上请求头,获取数据
if res.status_code>=200 and res.status_code<=300: #两百打头的标识符标识网页可以被获取
return res
else:
return None
except Exception as e:
print(e) # 显示报错原因(可以考虑这里写入日志)
if times>0:
get_html(url,times-1) # 递归执行
def get_data(html_data, Xpath_path):
'''
这是一个从网页源数据中抓取所需数据的函数
:param html_data:网页源数据 (单条数据)
:param Xpath_path: Xpath寻址方法
:return: 存储结果的列表
'''
data = html_data.content
data = data.decode().replace("", "") # 删除数据中的注释
tree = etree.HTML(data) # 创建element对象
el_list = tree.xpath(Xpath_path)
return el_list
import json
fsubject_name = ["物理或历史均可","仅物理","仅历史"]
ssubject_name = ['不提再选科目要求','地理必须选考方可报考','化学、地理均须选考方可报考','化学、地理选考其中一门即可报考','化学、生物均须选考方可报考','化学、生物选考其中一门即可报考','化学、思想政治选考其中一门即可报考','化学必须选考方可报考','生物、地理均须选考方可报考','生物、地理选考其中一门即可报考','生物、思想政治选考其中一门即可报考','生物必须选考方可报考','思想政治、地理均须选考方可报考','思想政治、地理选考其中一门即可报考','思想政治必须选考方可报考']
res = get_html('https://wjt-subject-tool-api.sdp.101.com/v1/actions/manage?page_size=30&page=' + str(1) + '&f_subject='+'物理或历史均可'+'&s_subject='+'化学、地理均须选考方可报考',2)
j_data = json.loads(res.content)
import openpyxl
wb = openpyxl.Workbook()
ws = wb.active
with open("新高考选科工具.txt",'w+') as w:
for f in fsubject_name:
for s in ssubject_name:
cs = wb.create_sheet(f+'+'+s, 0)
i = 1
while (1):
res = get_html('https://wjt-subject-tool-api.sdp.101.com/v1/actions/manage?page_size=30&page=' + str(i) + '&f_subject='+f+'&s_subject='+s,2)
j_data = json.loads(res.content)
if (j_data["items"] == []):
print("空界面,跳出")
break
for data in j_data["items"]:
print([data['school_name'],data['subject_name'],data['fsubject'],data['ssubject']])
cs.append([data['school_name'],data['subject_name'],data['fsubject'],data['ssubject']])
#w.write(str([data['school_name'],data['subject_name'],data['fsubject'],data['ssubject']]))
# df = pd.DataFrame([data['school_name'],data['subject_name'],data['fsubject'],data['ssubject']])
# df.to_excel('新高考选科工具.xlsx',sheet_name=f+'+'+s)
i += 1
wb.save('新高考选科工具.xlsx')
wb.close()

优化小思路
我准备将爬取和存储解耦合,放在不同的线程中执行,以提高效率。
这可以作为我《精写15篇,学会Python爬虫》的一个项目来做。