专升本数据结构复习
每次上线都会收到一些私信,因为学业较忙上线不勤,消息回复不及时,抱歉!
联系方式:
QQ:1947858195
微信:同上
数据结构知识点总汇
主要参考书目:
- 程海英老师的《数据结构(C语言版)》教材
- 严蔚敏,李冬梅,吴伟民.《数据结构(C语言版)》
推荐视频:西北大学 数据结构-耿国华老师
说明:这是本人专升本上岸一年后写的,本篇包含知识点和例题总结。因为是当时自己手码的,所以知识点有冗余和顺序错位。如果发现有错误之处,欢迎评论区留言,看到后及时改正,谢谢!最后祝大家好好学习,积极向上,早日上岸!
① 数据结构(逻辑结构)其4类基本结构:集合、线性结构、树形结构、图状结构 和 网状结构。
② 物理结构(存储结构)其4种存储结构:顺序存储结构、链式存储结构、索引存储结构 和 散列存储结构。
③ 算法5个重要特性:有穷性、确定性、可行性、输入 和 输出。
通常从四个方面评价算法的质量:正确性、易读性、强壮性 和 高效率。
④ 线性表是由n≥0个数据元素组成的 有限序列。其特点为逻辑关系上相邻的两个元素在物理位置上也相邻。
⑤ 在顺序表中实现的基本运算:
插入:平均移动结点次数为 n/2;平均时间复杂度均为O(n)。
删除:平均移动结点次数为 (n-1)/2;平均时间复杂度均为O(n)。
⑥ 存储位置计算:每个元素需占用L个存储单元第一个单元的存储地址作为数据元素的存储位置线性表的第i个数据元素ai的存储位置为LOC(ai)=LOC(a1)+(i-1)*L ,a1的存储位置,通常称做线性表的起始位置或基地址。
⑦ 线性表的链式存储结构:数据元素ai的存储映像称为结点,包括2个域:存数据的 数据域、存后继存储位置的 指针域。
⑧ 线性链表(单链表)特点:每个结点只包含1个指针域。在单链表的第一个结点之前附设的一个结点,称之为 头结点。
⑨ 假设L是LinkList型变量,则L为单链表的头指针,它指向表中第一个结点。
L->next 为第一个结点地址,L->next=NULL为 空表。
回收结点:free(q)。
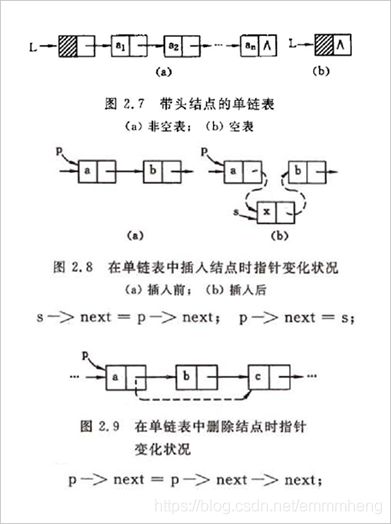
⑩ 栈:是限定仅在 栈顶(表尾)进行插入或删除操作 的线性表。表头端称为栈底,不含有元素的空表称为空栈;栈又称为 后进先出 的线性表。
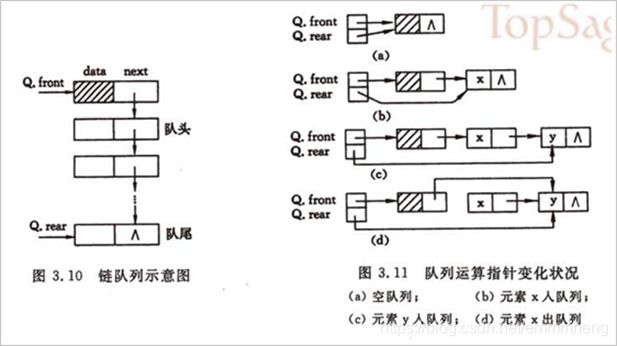
⑪ 队列:是一种 先进先出 的线性表,它只允许在表的一端进行插入,而另一端删除元素。允许插入的一端叫做队尾,允许删除的一端则称为队头。
⑫ 链队列:用链表示的队列。一个队列需要头指针和尾指针才能确定唯一。
⑩ 栈:是限定仅在 栈顶(表尾)进行插入或删除操作 的线性表。表头端称为栈底,不含有元素的空表称为空栈;栈又称为 后进先出 的线性表。
⑪ 队列:是一种 先进先出 的线性表,它只允许在表的一端进行插入,而另一端删除元素。允许插入的一端叫做队尾,允许删除的一端则称为队头。
⑫ 链队列:用链表示的队列。一个队列需要头指针和尾指针才能确定唯一。
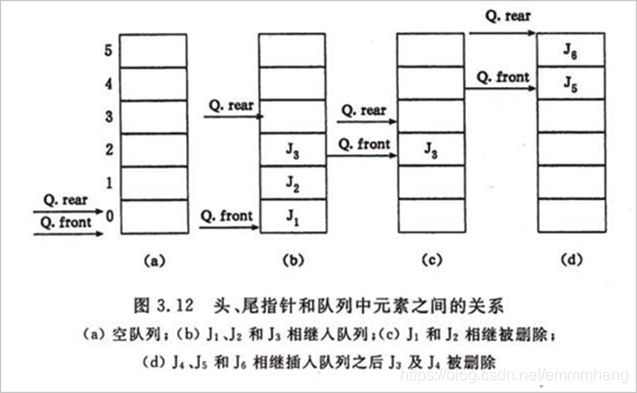
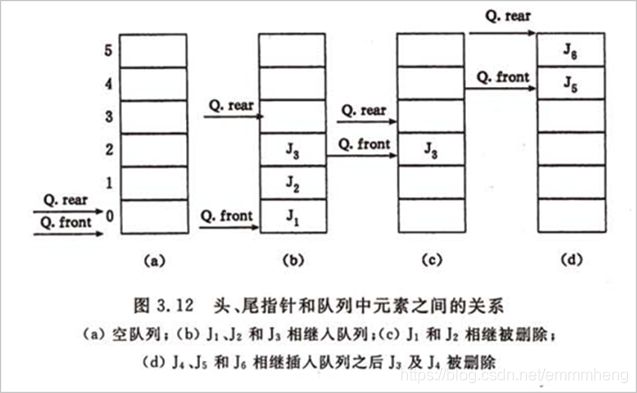
⑬ 循环队列:两个指针front指示队列头元素和rear指示队列尾元素的位置。初始化建空队列时,令front = rear = 0,每当插入新的队列尾元素时,“尾指针增1”;每当删除队列头元素时,“头指针增1”。
⑭ 串:是由零个或多个字符组成的有限序列。
⑮ 数组的存储位置计算:假设每个数据元素需占用L个存储单元,则二维数组A中任一元素A[ij]的存储位置可由下式确定:
以行序为主序的存储结构:LOC(i,j)=LOC(0,0)+(n*i+j)*L;(n为行数)
以列序为主序的存储结构:LOC(i,j)=LOC(0,0)+(n*j+i)*L;(n为列数)
⑯ 广义表:是线性表的推广,在广义表的定义中,ai可以是单个元素,也可以是广义表,分别称为广义表LS的原子和子表。

⑰ 二叉树的性质:
性质1:在二叉树的第K层上至多有 2k-1 个结点(K≥1)。
性质2:深度为k的二叉树至多 2k-1 个结点(k≥1)。
深度为k的二叉树至少有k个结点(k≥1)。
深度为k的完全二叉树至少有 2k-1 个结点(k≥1)。
性质3:对任何一棵二叉树T,如果其终端结点数为N0,度为2的结点数为N2,则 N0=N2+1。总结点个数 N=N0+N1+N2。
性质4:具有n个结点的完全二叉树的深度为 [log2n]+1。
⑱ 满二叉树:一颗深度为k且有 2的k次方减1个结点的二叉树。
⑲ 完全二叉树:深度为k的,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n的结点一一对应。
⑳ 树转换成二叉树:连兄弟,留长子,删孩子。
注意:由于树根没有兄弟结点,固树转换为二叉树后,二叉树根结点的右子树必为空。
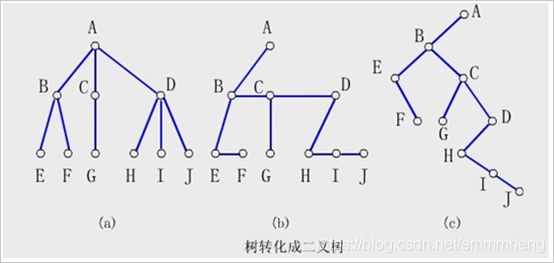
① 森林转换成二叉树:连树根及兄弟,留长子,删孩子。
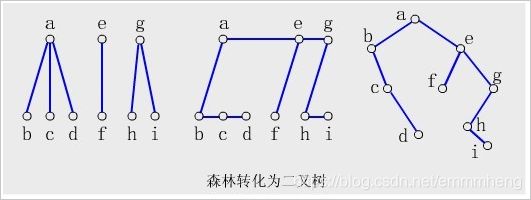
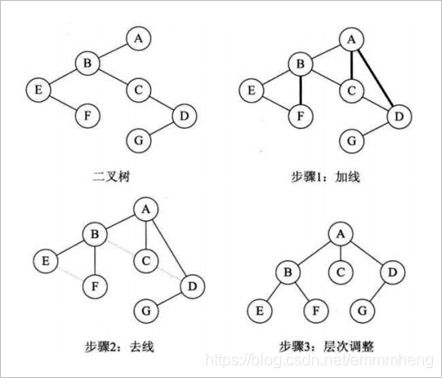
② 二叉树转换成树:连左孩子的右孩子及其右孩子…,删原树右孩子。
③ 赫夫曼树:又称最优树,是一类带权路径长度最短的树。
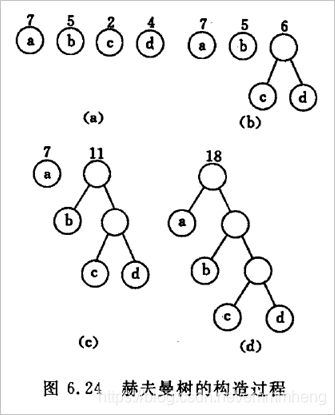 WPL=23+43+52+71=35
WPL=23+43+52+71=35
④ 赫夫曼编码:在赫夫曼树上,左分支代表0,右分支代表1。由根结点到指定结点的路径(从上到下把0、1连起来),就是该结点的赫夫曼编码;如上图(d)中a为0,b为10,c为110,d为111。
⑤无向完全图:有 n(n-1)/2 条边的无向图。
有向完全图:有 n(n-1) 条边的有向图。
⑥邻接矩阵:无向图的邻接矩阵关于主对角线对称,在整个矩阵中非零元素的个数等于边个数的2倍,第i行和第i列中非零元素的个数等于该结点的度。
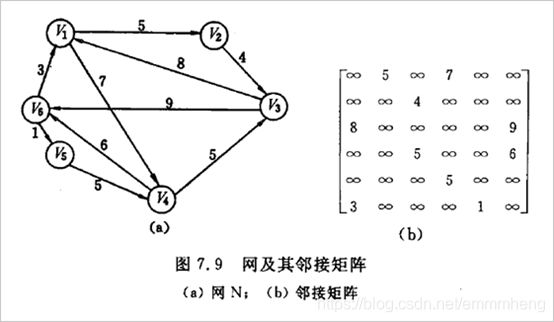
⑦ 邻接表:无向图的邻接矩阵关于主对角线对称,在整个矩阵中非零元素的个数等于边个数的2倍,第i行和第i列中非零元素的个数等于该结点的度。
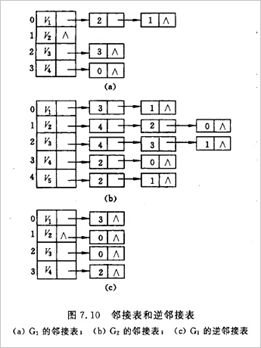
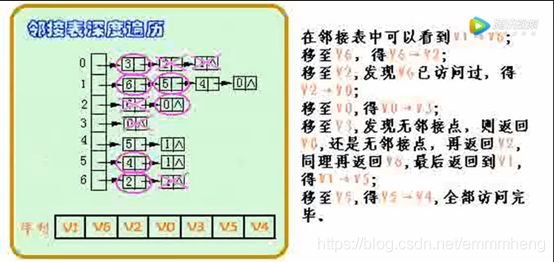
⑧ 深度优先遍历:
⑨ 广度优先遍历:

⑩ 最小生成树:
普里姆算法(Prim):连相邻权值最小的。

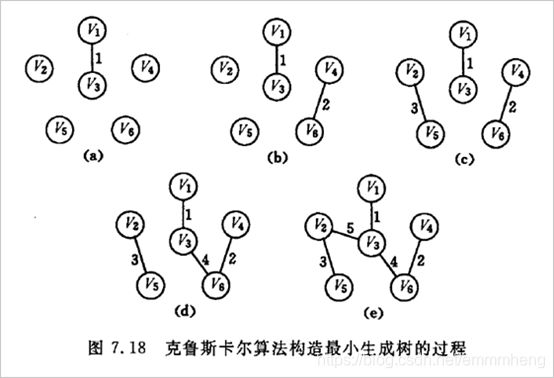
克鲁斯卡尔算法(Kruskal):先连权值最小的,再依次连。
⑪ 拓扑排序:由某个集合上的一个偏序得到该集合上的一个全序的操作。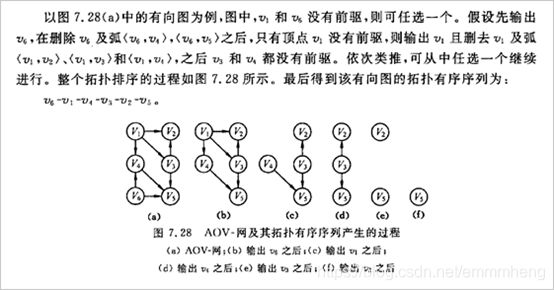
⑫顺序查找法平均查找长度:ASL=(n+1)/2。
折半查找法(二分查找法)平均查找长度:ASL=(n+1)/n*log2(n+1)-1
索引顺序表查找法(分块查找法)平均查找长度:ASL≈log2(n/s+1)+s/2。
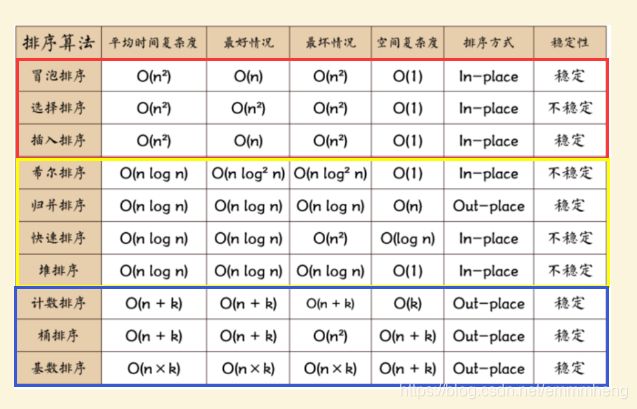
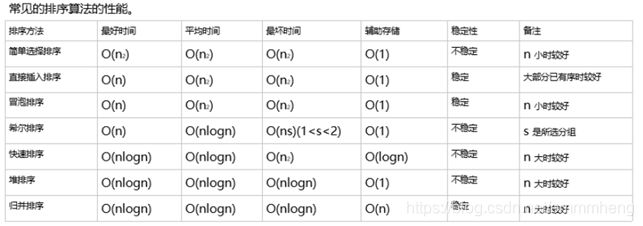
⑬ 直接插入排序:将一个记录插入到已排好序的有序表中,从而得到一个新的、记录数增1的有序表。

⑭ 冒泡排序:首先将一个记录的关键字和第二个记录的关键字进行比较,若为逆序(即L.r[1].key>L.r[2].key),则将两个记录交换之,然后比较第二个记录和第三个记录的关键字。以此类推,直至第n-1个记录和第n个记录的关键字进行过比较为止。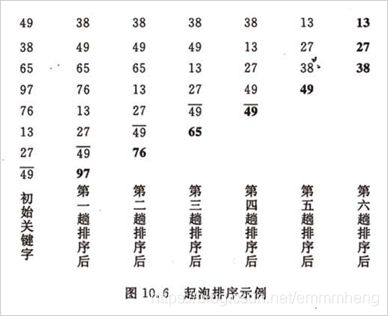
⑮ 快速排序:通过一趟排序将待排记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
① 顺序表是随机存储结构,当线性表的操作 主要是查找时,宜采用以插入和删除操作为主的线性表宜采用 链表 做存储结构。若 插入和删除主要发生在表的首尾两端,则宜采用尾指针表示的单循环链表。
② 在顺序栈中有“上溢”和“下溢”的现象,“上溢”是栈顶指针指出栈的外面是出错状态,“下溢”可以表示栈为空栈,因此用来作为控制转移的条件。
③ 队列 是一种运算受限的线性表,允许删除的一端称为队头(front),允许插入的一端称为队尾(rear) ,队列的操作原则是先进先出的,又称作FIFO表。队列也有顺序存储和链式存储两种存储结构。
④循环队列:判定循环队列是空还是满,方法有三种:
一种是另设一个布尔变量来判断;
第二种是少用一个元素空间,入队时先测试((rear+1)%m = front)? 满:空;
第三种就是用一个计数器记录队列中的元素的总数。
⑤ 队列的链式存储结构称为链队列,为了便于在表尾进行插入(入队)的操作,在表尾增加一个尾指针,一个链队列就由一个头指针和一个尾指针唯一地确定。链队列不存在队满和上溢的问题。
在链队列的出队算法中,要注意当原队中只有一个结点时,出队后要同进修改头尾指针并使队列变空。
⑥ 串是零个或多个字符组成的有限序列。
空串:是指长度为零的串,也就是串中不包含任何字符(结点)
空白串:指串中包含一个或多个空格字符的串。
⑦ 子串在主串中的序号就是指子串在主串中首次出现的位置。空串是任意串的子串,任意串是自身的子串。
⑧ 串的基本运算有:
求串长strlen(char*s) 串复制strcpy(char*to,char*from)
字符定位strchr(char*s,charc) 串联接strcat(char*to,char*from)
串比较charcmp(char*s1,char*s2)
⑨地址的计算方法:
按行优先顺序排列的数组:LOCa(ij)=LOCa(11)+((i-1)*n+(j-1))*d
按列优先顺序排列的数组:LOCa(ij)=LOCa(11)+((j-1)*n+(i-1))*d
⑩图的存储结构:
邻接矩阵表示法:用一个n阶方阵来表示图的结构是唯一的;无向图中邻接矩阵是对称的;有向图中行是出度,列是入度。
邻接表表示法:用顶点表和邻接表构成不是唯一的;顶点表结构 vertex | firstedge,指针域存放邻接表头指针;邻接表是用头指针确定。
⑪图的遍历:
深度优先遍历:借助于邻接矩阵的列。使用栈保存已访问结点。
广度优先遍历:借助于邻接矩阵的行。使用队列保存已访问结点。
⑫ 直接插入排序:

⑬ 直接选择排序:
⑭ 冒泡排序:
⑮ 快速排序:
① n个结点的二叉树共有 2n 个指针域,其中有 n-1 个指针域是存放了地址,有 n+1 个指针是空指针。
② 在一个具有n个顶点的无向完全图中,包含有 e 条边,在一个具有n个顶点的有向完全图中,包含有 2e 条边。
③ 在堆排序的过程中,对任一分支结点进行筛运算的时间复杂度为 O(log2n),整个堆排序过程的时间复杂度为 O(nlog2n)。
④ AOV网是一种 有向无回路 的图。



⑤ 设哈夫曼树中的叶子结点总数为m,若用二叉链表作为存储结构,则该哈夫曼树中总共有 2m 个空指针域。(m个叶子节点的哈夫曼树总共有2m-1个节点)
⑥ 设顺序循环队列Q[0:M-1]的头指针和尾指针分别为F和R,头指针F总是指向队头元素的前一位置,尾指针R总是指向队尾元素的当前位置,则该循环队列中的元素个数为 (R-F+M)%M。
⑦ 快速排序的最坏时间复杂度为 O(n2),平均时间复杂度为 O(nlog2n)。






⑧ 数据的物理结构主要包括 顺序存储结构 和 链式存储结构 两种情况。
⑨ 二分查找的过程可以用一棵二叉树来描述,该二叉树称为二叉判定树。在有序表上进行二分查找时的查找长度 不超过 二叉判定树的高度 1+log2n。


⑩ 设有n个无序的记录关键字,则直接插入排序的时间复杂度为 O(n2),快速排序的平均时间复杂度为 O(nlog2n)。
⑪ 设指针变量p指向双向循环链表中的结点X,则删除结点X需要执行的语句序列为 p>llink->rlink=p->rlink ; p->rlink->llink=p->rlink(设结点中的两个指针域分别为llink和rlink)。
⑫ 设有一个顺序循环队列中有M个存储单元,则该循环队列中最多能够存储 m-1 个队列元素;当前实际存储 (R-F+M)%M 个队列元素(设头指针F指向当前队头元素的前一个位置,尾指针指向当前队尾元素的位置)。
⑬ 设某无向图G中有n个顶点,用邻接矩阵A作为该图的存储结构,则顶点i和顶点j互为邻接点的条件是 A[i][j]=1。

⑭ 数据项是不可分割的构成数据元素的最小单位;数据元素是数据的基本单位。
⑮ 设一个有序的单链表中有n个结点,现要求插入一个新结点后使得单链表仍然保持有序,则该操作的时间复杂度为 O(n)。
两方面:一是插入时间复杂度O(1);二是保持有序时间复杂度O(n)
⑯ 设一棵m叉树中度数为0的结点数为N0,度数为1的结点数为Nl,……,度数为m的结点数为Nm,则N0= l+N2+2N3+3N4+……+(m-1)Nm。
【注解】由2叉树的性质引申出,对于任何一颗树T,如果其终端结点树为n0 度为i的结点数为ni,则n0=1+n2+2n3+···+(i-1)ni
⑰ 设有一个顺序共享栈S[0:n-1],其中第一个栈项指针top1的初值为-1,第二个栈顶指针top2的初值为n,则判断共享栈满的条件是 top1+1=top2。
⑱ 在图的邻接表中用顺序存储结构存储表头结点的优点是 可以随机访问到任一个顶点的简单链表。
⑲设一条单链表的头指针变量为head且该链表没有头结点,则其判空条件是 head==0。
不带头结点是 head==NULL,带头结点是 head->next==NULL
设带有头结点的单向循环链表的头指针变量为head,则其判空条件是 head->next==head。
⑳ 设二叉树的先序遍历序列和后序遍历序列正好相反,则该二叉树满足的条件是 只有一个孩子节点(或 高度等于其结点数)。
① 设指针变量front表示链式队列的队头指针,指针变量rear表示链式队列的队尾指针,指针变量s指向将要入队列的结点X,则入队列的操作序列为 rear->next=s ;rear=s。(注意:入队要从队尾入)
② 设指针变量p指向单链表中结点A,指针变量s指向被插入的新结点X,则进行插入操作的语句序列为 s->next=p->next ; p->next=s(设结点的指针域为next)。
③ 设F和R分别表示顺序循环队列的头指针和尾指针,则判断该循环队列为空的条件为 F==R
④ 设二叉树中结点的两个指针域分别为lchild和rchild,则判断指针变量p所指向的结点为叶子结点的条件是
p->lchild==NULL && p->rchild==NULL。
⑤ 散列表中解决冲突的两种方法是 开放定址法 和 链地址法。


⑥ 设指针变量top指向当前链式栈的栈顶,则删除栈顶元素的操作序列为 top=top->next;
若指针变量top指向当前顺序栈的栈顶,则删除栈顶元素的操作序列为 top=top-1
⑦ 设指针变量p指向双向链表中的结点A,指针变量s指向被插入的结点X,则在结点A的后面插入结点X的操作序列为
s->left=p;s->right=p->right;p->right=s; p->right->left=s;
(设结点中的两个指针域分别为left和right)。
⑧ 解决散列表冲突的两种方法是 开放定址法 和 链地址法。

⑨ 设指针变量p指向单链表中结点A,指针变量s指向被插入的结点X,则在结点A的后面插入结点X需要执行的语句序列:s->next=p->next ; p->next=s 。
⑩ 设指针变量head指向双向链表中的头结点,指针变量p指向双向链表中的第一个结点,则指针变量p和指针变量head之间的关系是p=head->rlink 和head=p->llink(设结点中的两个指针域分别为llink和rlink)。
⑪ 设指针变量p指向双向链表中结点A,指针变量s指向被插入的结点X,则在结点A的后面插入结点X的操作序列为
s->left=p;s->right=p->right;p->right->left=s; p->right=s;。

⑫ 设散列表中有m个存储单元,散列函数H(key)= key % p,则p最好选择 小于等于m的最大素数。
⑬设顺序线性表的长度为30,分成5块,每块6个元素,如果采用分块查找,则其平均查找长度为 6.5。
设分块查找中将长为 n 的表分成均等的 b 个块,每块 s 个元素,则 b = (n / s)上取整。
如果索引表中采用顺序查找,则ASL=(b+1)/2+(s+1)/2;
如果索引表中采用折半查找,则ASL=(s+1)/2+log2(b+1)-1;
⑭ 设指针p指向单链表中结点A,指针s指向被插入的结点X,则在结点A的前面插入结点X时的操作序列为:
- s->next= p->next;2) p->next=s;3) t=p->data;
- p->data= s->data;5) s->data=t;


⑮设某链表中最常用的操作是在链表的尾部插入或删除元素,则选用下列 双向循环链表 存储方式最节省运算时间。
如果只是插入元素,单向循环列表就可以了;
如果还需要删除元素,就要双向循环列表,可以最快的找到尾节点的前一个节点。
⑰ 有N个关键字排序,各排序最大最小情况如下:

⑱ 快速排序算法的平均时间复杂度为 O(nlog2n),直接插入排序算法的平均时间复杂度为 O(n^2)。
⑲ 设一棵m叉树脂的结点数为n,用多重链表表示其存储结构,则该树中有 n(m-1)+1 个空指针域。
【注解】m叉树n个结点,得出总的指针域为m*n,不为空的指针域就等于分枝数,根结点没有分支指向它,推出非空指针域为n-1,总指针域减非空指针域就等于空的指针域即m*n-(n-1)
⑳ 设指针变量p指向单链表中结点A,则删除结点A的语句序列为:
q=p->next;p->data=q->data;p->next= q->next;feee(q);
① 数据结构从逻辑上划分为三种基本类型:线性结构,树型结构 和 图型结构。
② 设无向图G中有n个顶点e条边:则用邻接矩阵作为图的存储结构进行深度优先或广度优先遍历时的时间复杂度为 O(n^2);
用邻接表作为图的存储结构进行深度优先或广度优先遍历的时间复杂度为 O(n+e)。



③ 邻接表是图的一种 链式存储结构。
④ 树最适合用来表示 元素之间具有分支层次关系的数据。
⑤ 在一个单链表中,若要删除由指针q所指向结点的后继结点(若存在),则执行 p=q->next;q->next=p->next 操作。
⑥ 常对数组进行的两种基本操作是 索引 和 修改。
⑦ 在一个单链表中,已知q所指结点是p所指结点的直接前驱,若在q和p之 间插入s所指结点,则执行 q->next=s; s->next=p 操作。

⑧ 设有两个串p和q,求q在p中首次出现的位置的运算称作 模式匹配。
⑨ 一个高度为h的满二叉树共有n个结点,其中有m个叶子结点,则有
n=2m-1 成立。
⑩ 实现图的广度优先搜索遍历算法需要使用 队列,深度优先搜索遍历算法需要使用 栈。
⑪ 顺序表中逻辑上相邻的元素的物理位置必定相邻。单链表中逻辑上相邻的元素的物理位置不一定相邻。
⑫ 树的先序对应二叉树的先序,树的后序对应二叉树的中序。
⑬ 在 n(n>0) 个元素的顺序栈中删除1个元素的时间复杂度为: O(1)。
⑭设 SQ 为循环队列,存储在数组 d[m] 中,则 SQ 出队操作对其队头指针 front 的 修改是 front = (front+1)%m 。
对于一个以顺序实现的循环队列Q[0…m-1],队头、队尾指针分别为f、r,其判空的条件是 r=f,判满的条件是 (r+1)%m=f。
① 设计一个判别表达式中括号是否匹配出现的算法,采用 栈 的数据结构最佳。
② 设广义表L=((a,b,c)),则L的长度为1,深度为2。
③ 衡量查找算法效率的主要标准是 平均查找长度。
④ 栈和队列都是 限制存取点的线性结构。
⑤ 在稀疏矩阵的三元组顺序表中,每个三元组表示 矩阵中非零元素的行号、列号和数据值。
⑥ 顺序结构逻辑上相邻的结点物理上也是相邻的。因此,其存储密度大,存储空间利用串高。
⑦ 含有n个结点的二叉树采用二叉链表存储时,空指针域的个数为 n+1,非空指针个数为 n-1。
⑧ 在数据结构中,从存储结构上可以将之分为 顺序存储和非顺序存储;从逻辑结构上可以将之分为 线性结构和非线性结构。
⑨ 深度优先遍历类似二叉树的 先序遍历;广度优先遍历类似二叉树的 层次遍历。
⑩ n个顶点的有向图最多有 n(n-1)条边;无向图最多有 n(n-1)/2 条边。
⑪ 如果要求用线性表既能较快地查找,又能适应动态变化的要求,则可采用 分块查找。
⑫ 任意一棵二叉树的叶子结点在其先序、中序和后序序列中的相对位置 不发生变化。
⑬ 在单链表指针为p的结点之后插入指针为s的结点,正确的操作是 s->next=p->next;p->next=s。
⑭ 某算法的时间复杂度是O(n^2),表明该算法的 执行时间与n^2成正比。
⑮ 对于一个具有n个顶点和e条边的无向图,若采用邻接表表示,则表头向量的大小为 n,占用的存储空间为 2e。
⑯ 对于顺序表,访问某结点的时间复杂度为 O(1),删除某结点的时间复杂度为 O(n)。
⑰ 以数据集{4,5,6,7,10,12,18}为结点权值,画出构造的哈弗曼树,并计算其带权路径长度。
⑱广义表(a,(b,c),d,e)的表头为 a。
已知广义表L=(a,(b,(c,(d)), e), f ),则:
L1=Tail(L)=((b,(c,(d)), e), f )
L2=Head(L1)= (b,(c,(d)), e)
L3=Tail(L2)=((c,(d)), e)
L4=Head(L3)=(c,(d))
L5=Head(L4)= c
⑲ 树最适合用来表示的结构是 元素间具有分支层次关系的结构。
⑳ 图G是一个非连通无向图,共有28条边,则该图至少有 9 个顶点。
① 栈的特点是 一个线性结构,数据先进后出,且只能在栈顶进行增删操作。
② 与数据元素本身的形式、内容、相对位置、个数无关的是数据的 逻辑结构。
③ 数据结构被形式定义为(D, R),其中D是 数据元素 的有限集合,R是D上的 关系 有限集合。
④ 当利用大小为N的数组顺序存储一个栈时,假定用top= =N表示栈空,则向这个栈插入一个元素时,首先应执行 top-- 语句修改top指针。
⑤ 设有一个字符串S=“abcdefgh”,问该串的最大子串个数为 37。
⑥ 若StrIndex(S,T)表示求T在S中的位置的操作,则对于S=“Beijing and Nanjing”,T=“jing”,StrIndex(S,T)的结果为4。
⑦ 字符串按存储方式可以分为:顺序存储、链接存储和 堆分配存储。
⑧ 在C语言中,以字符 \0表示串值的终结。
⑨ A[N, N]是对称矩阵,将下三角(含对角线)以行序存储到一维数组arr[N(N+1)/2]中,则对任一上三角元素arr[i, j]对应arr[k]的下标k是:解析如下

⑩ 有一个100*90的稀疏矩阵,非零元素有10个,设每个整型数占2个字节,则用三元组表示该矩阵时,所需的字节数是 66。

⑪ 已知广义表LS=((a, b, c),(d, e, f)),对其运用Head和Tail运算,取出其中原子e的运算是 Head(Tail(Head(Tail(LS))))
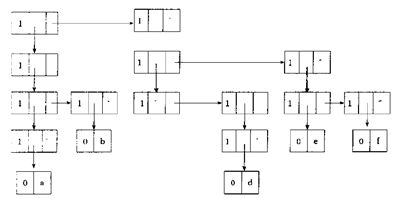
⑫ 画出广义表((((a),b)),(((), d),(e,f)))的链式存储结构图示。
⑬ 引入二叉线索树的目的是 加快查找结点的前驱或后继的速度。
⑭ 利用二叉链表存储一般树,则根结点的右指针是 空;因为左孩子右兄弟,根节点无兄弟。
⑮ 深度优先遍历类似于二叉树的 先序遍历;广度优先遍历类似于二叉树的 层次遍历。
⑯ 用邻接表表示图进行广度优先遍历时,通常借助 队列 来实现算法。
用邻接表表示图进行深度优先遍历时,通常借助 栈 来实现算法。
⑰ 拓扑排序 方法可以判断出一个有向图是否有环。
⑱ 图中的一条路径长度为k,该路径所含的顶点数为 K+1。
⑲ 数据的最小单位是 数据项。
⑳ 设一个有序的单链表中有 n 个结点, 现要求插入一个新结点后使得单链表仍然保持有序, 则该操作的时间复杂度为 O(n)。
① 在图的邻接表中用顺序存储结构存储表头结点的优点是 可以随机访问到任意点的简单链表。
② 设一棵 m叉树中度数为 0 的结点数为 N0,度数为 1 的结点数为 Nl,……,度数为 m的结 点数为 Nm,则 N0= l+N 2+2N3+3N4+…… +(m-1)Nm 。

③ 设有一个 n 阶的下三角矩阵 A,如果按照行的顺序将下三角矩阵中的元素(包括对角线 上元素)存放在 n(n+1) 个连续的存储单元中,则 A[i][j] 与 A[0][0] 之间有 i*(i+1)/2+j -1或i*(i+1)/2+i个数据元素。

④设一条单链表的头指针变量为 head且该链表没有头结点,则其判空条件是 head==0。
head为指向表头结点的指针,分别写出带有头结点的单链表、单项循环链表和双向循环链表判空的条件:
单链表 NULL==head->next
单向循环 head==head->next
双向循环 head==head->next&&head==head->prior
⑤ head为指向表头结点的指针,分别写出不带有头结点的单链表、单项循环链表和双向循环链表判空的条件:
单链表 NULL==head
单向循环 head==head->next
双向循环 head==head->next&&head==head->prior
⑥ 设F和R分别表示顺序循环队列的头指针和尾指针,则判断该循环队列为空的条件为F==R。
⑦ 散列表中解决冲突的两种方法是 开放地址法 和 链接法。
⑧ 设指针变量 top 指向当前链式栈的栈顶,则删除栈顶元素的操作序列为 top=top->next。
⑨ 设关键字序列为 (Kl ,K2,⋯, K n) ,则用筛选法建初始堆必须从第 n/2 个元素开始进行筛选。
⑩ 建立一个长度为 n 的有序单链表的时间复杂度为 O(n^2)。
⑪ 设顺序表的长度为 n,则顺序查找的平均比较次数为 (n+1)/2。
⑫ 设顺序线性表的长度为 30,分成 5 块,每块 6 个元素,如果采用分块查找,则其平均查 找长度为 6.5。

⑬ 在堆排序中,对n个记录建立初始堆需要调用 n/2 次调整算法。
⑭ 已知一棵完全二叉树中共有768结点,则该树中共有 384 个叶子结点。

⑮ 一个一维数组a[10]中存储着有序表(15,26,34,39,45,56,58,63,74,76),根据折半搜索所对应的判定树,写出该判定树中度为1的结点个数,并求出在等概率情况下进行成功搜索时的平均搜索长度。度为1的结点个数:3;平均搜索长度:29/10。
⑯ 一维数组中有n个数组元素,则读取第i个数组元素的平均时间复杂度为 O(1)。
解析:数组是随机访问的数据结构,平均时间复杂度为O(1)
⑰ 含n个顶点的无向连通图中至少含有 n-1 条边。
⑱ 顺序表中,逻辑上相邻的元素,其物理位置也相邻,在链表中,逻辑上相邻的元素,其物理位置不一定相邻。
⑲ 利用三元组表存放稀疏矩阵中的非零元素,则在三元组表中每个三元组元素对应一个非零元素的行号、列号和 值。
⑳ 数据的逻辑结构是从逻辑关系上描述数据,它与数据的 存储(或存储结构) 无关,是独立于计算机的。
① 区分循环队列的满与空,有三种方法,它们是 少用一个存储单元、设置一个标志位 和 设置一个计数器。
② 根据线性表的链式存储结构中每一个结点包含的指针个数,将线性链表分成 单链表和双链表。
③ 数据结构中评价算法的两个重要指标是 时间复杂度 和 空间复杂度。
④ 最大容量为n的循环队列,队尾指针是rear,队头是front,则队空的条件是 rear==front;队满条件是 (rear+1)%n==front;当前队列中的元素个数为 (rear-front+n)%n。
⑤ 一个递归算法必须包括 终止条件和递归部分。
⑥ 循环队列存储在数组A[0…m]中,则入队时的操作为 rear=(rear+1) mod (m+1)。
⑦ 设计一个判别表达式中左,右括号是否配对出现的算法,采用 栈 数据结构最佳。
⑧元素的移动次数与关键字的初始排列次序无关的是:基数排序
元素的比较次数与初始序列无关是:选择排序
算法的时间复杂度与初始序列无关的是:直接选择排序
⑨ 若一个栈以向量V[1…n]存储,初始栈顶指针top为n+1,则下面x进栈的正确操作是:top=top-1; V[top]=x。
⑩ 利用带头结点的二叉链表存储树,则根结点的右指针是 空。二叉链表:左孩子右兄弟,根节点没有兄弟,所以为空 。
⑪ 设二叉排序树的高度为h,则在该树中查找关键字key最多需要比较 h次。
⑫ 入栈操作和入队列操作在链式存储结构上实现时不需要考虑栈溢出的情况。正确,链式存储结构是动态分配空间的。
⑬ 用邻接矩阵作为图的存储结构时,则其所占用的存储空间与图中顶点数有关。图的邻接矩阵存储所占用空间大小只与顶点个数有关,更准确地说,设顶点n个,则与n^2成正比
⑭ 设一维数组中有n个数组元素,则读取第i个数组元素的平均时间复杂度为 O(1)。
⑮ 堆是完全二叉树,完全二叉树不一定是堆。
⑯ 不论线性表采用顺序存储结构还是链式存储结构,删除值为X的结点的时间复杂度均为O(n)。
⑰ 设一组初始记录关键字序列(k1,k2,……,kn)是堆,则对i=1,2,…,n/2而言满足的条件为 ki<=k2i && ki<=k2i+1。
⑱ 设一组初始记录关键字序列为(345,253,674,924,627),则用基数排序需要进行3趟的分配和回收才能使得初始关键字序列变成有序序列。
⑲ 设有序顺序表中有n个数据元素,则利用二分查找法查找数据元素X的最多比较次数不超过 log2n+1。
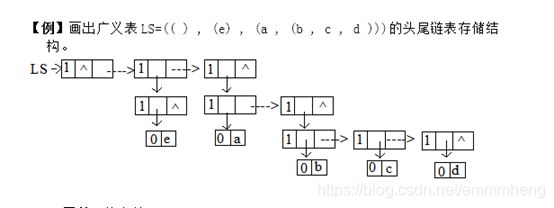
⑳ 画出广义表LS=(( ) , (e) , (a , (b , c , d )))的头尾链表存储结构。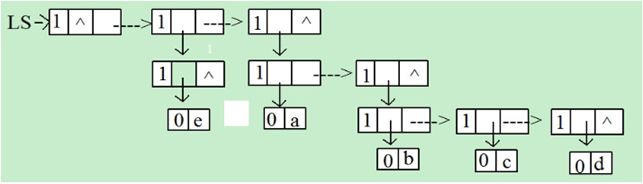
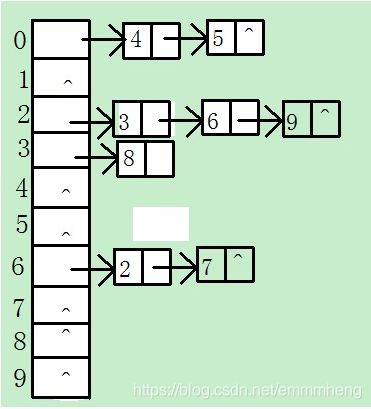
21 设散列表的地址范围是[ 0…9 ],散列函数为H(key)= (key 2 +2)MOD 9,并采用链表处理冲突,请画出元素7、4、5、3、6、2、8、9依次插入散列表的存储结构。
H(4)=H(5)=0,H(3)=H(6)=H(9)=2,H(8)=3,H(2)=H(7)=6
① 二分查找的过程可以用一棵二叉树来描述,该二叉树称为二叉判定树。在有序表上进行二分查找时的查找长度不超过二叉判定树的高度1+log2n。
② 设某链表中最常用的操作是在链表的尾部插入或删除元素,则选用下列 双向循环链表 存储方式最节省运算时间。
③ 将两个各有n个元素的有序表归并成一个有序表,其最少的比较次数是n次,最多2n-1次。
④循环队列存储在数组A[0…m]中,则入队时的操作为 rear=(rear+1)%(m+1)。
入队是:rear=(rear+1)%(m+1) //m+1 代表有m+1个空间 。。它是0到m的数组
出队是: front =(front+1)%(m+1)
⑤ 循环队列放在一维数组A[0…M-1]中,end1指向队头元素,end2指向队尾元素的后一个位置。假设队列两端均可进行入队和出队操作,队列中最多能容纳M-1个元素。初始时为空。则 队空:end1==end2;队满:end1==(end2+1)mod M
⑥ 一个栈的入栈序列为1,2,3,…,n,其出栈序列是p1,p2,p3…,pn。若p2=3,则p3可能取值的个数是 n-1;

⑦ 图的BFS生成树的树高小或相等DFS生成树的树高。
【例题】线性 表( a1, a2,…, an)采用顺序存储结构。试问:
(1) 在等 概率 的 前提下, 平均 每 插入 一个 元素 需要 移动 的 元素 个数 为 多少?
(2) 若 元素 插在 ai 与 ai+ 1 之间( 0 ≤ i ≤ n- 1) 的 概率 为, 则 平均 每 插入 一个 元素 所要 移动 的 元素 个数 又是 多少?




① 线性表的顺序存储结构是一种 随机存取 的存储结构,线性结构的链式存储是一种 顺序存取 的存储结构。
② 数据结构是一门研究非数值计算的 操作对象 以及它们之间的 关系 和运算等的学科。
③ 一个数据结构在计算机 存储器内的表示 称为存储结构。
④ 链栈和顺序栈相比较,有一个较为明显的优点是 通常不会出现栈满的情况。
⑤ 引入循环队列的目的是为了克服 “假溢出”现象。
⑥ 区分循环队列的满与空,只有两种方法,它们是 牺牲一个存储单元 和 设标记。
⑦ 设循环队列存放在向量data[0…M]中,则队头指针front 在循环意义下的出队操作可表示为 front=(front+1)%(M+1),若用牺牲一个单元的办法来区分队满和队空(设队尾指针rear),则队满的条件为 front==(rear+1)%(M+1)。
⑧ 对于长度为n且顺序存储的线性表,在任何位置上操作都是等概率的情况下,插入一个元素需要平均移动表中的元素个数 ;删除一个元素平均需要移动表中元素 。
⑨ 在一个不带头结点的单链表中,在表头插入或删除与在其他位置上插入或删除其操作过程 不相同。
⑩ 在线性表的顺序存储中,元素之间的逻辑关系是通过 存储位置 决定的;在线性表的链式存储中,元素之间的逻辑关系是通过 指针 决定的。
⑪ 单链表表示法的基本思想是用 指针 表示结点的逻辑关系。
⑫ 数据的逻辑结构是指数据元素间的逻辑关系,数据的存储结构是数据在计算机中的表示(又称映像)方法,是数据的逻辑结构在计算机中的存储实现。
⑬ 数据的物理结构包括 数据元素 的表示和数据元素间关系的表示。
⑭ 程序=数据结构+算法。
⑮线性表L=(a1, a2, …, an)用数组表示,假定删除表中任一元素的概率相同,则删除一个元素平均需要移动元素的 (n-1)/2;
线性表L=(a1, a2, …, an)用数组表示,假定删除表中任一元素的概率相同,则插入一个元素平均需要移动元素的 n/2。
⑯ 一个字符串中 任意个连续的字符组成的子序列 称为该串的子串。
⑰ 设T和P是两个给定的串,在T中寻找等于P的子串的过程称为 模式匹配,又称P为 模式串。
⑱ 串是一种特殊的线性表,其特殊性表现在 其数据元素都是字符;
⑲ 串的两种最基本的存储方式是 顺序存储、链式存储;
⑳ 两个串相等的充分必要条件是 两串的长度相等且两串中对应位置的字符也相等。
① 若度为m的哈夫曼树中,其叶结点个数为n,则非叶结点的个数为 [(n-1)/(m-1)](向上取整)
② 树的后根遍历序列等同于该树对应的二叉树的 中序序列。
③ 若二叉树采用二叉链表存储结构,要交换其所有分支结点左、右子树的位置,利用 后序 遍历方法最合适。
④ 一棵非空的二叉树的先序遍历序列与后序遍历序列正好相反,则该二叉树一定满足 只有一个叶子结点。
⑤ 某二叉树的前序序列和后序序列正好相反,则该二叉树一定是 高度等于其结点数 的二叉树。
⑥ 线索二叉树是一种 物理或存储 结构。
⑦ n个结点的线索二叉树上含有的线索数为 n+l(即空指针域个数)。
⑧ 中序线索树 的遍历仍需要栈的支持。
⑨ 设F是一个森林,B是由F变换得的二叉树。若F中有n个非终端结点,则B中右指针域为空的结点有 n+1 个。
⑩ 个有n个结点的图,最少有 1个连通分量,最多有 n个连通分量。
⑪ 用有向无环图描述表达式(A+B)*((A+B)/A),至少需要顶点的数目为 5。
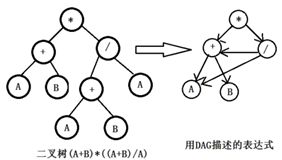
⑫ 如果含n个顶点的图形形成一个环,则它有 n 棵生成树。
⑬ 对稀疏图最好用 克鲁斯卡尔(Kruskal) 算法求最小生成树,对稠密图最好用 普里姆(Prim) 算法求最小生成树。
⑭ 判断一个无向图是一棵树的条件是 n个顶点,n-1条边的无向连通图。
⑮ 有向图G的强连通分量是指 有向图的极大强连通子图。
⑯ N个顶点的无向连通图至少有N-1条边,则邻接矩阵中至少有2(N-1)个非零元素。
⑰ 在AOE网中,从源点到汇点路径上各活动时间总和最长的路径称为 关键路径。
⑱ AOV网中,结点表示 活动,边表示 活动间的优先关系;AOE网中,结点表示 事件,边表示 活动边上的权代表活动持续时间。
⑲ 二叉查找树的查找效率与二叉树的 树型 有关, 在 呈单枝树 时其查找效率最低,
⑳ 堆排序是 选择 类排序,堆排序平均执行的时间复杂度 O(nlog2n) ;需要附加的存储空间复杂度分是O(1)
① 设一维数组中有 n 个数组元素,则读取第 i 个数组元素的平均时间复杂度为 O(1)
② 在二叉排序树中插入一个结点的时间复杂度为 O(n)
③ 设二叉树的先序遍历序列和后序遍历序列正好相反,则该二叉树满足的条件是 高度等于其结点数。