思维导图

什么是链表:
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
在计算机科学中,链表作为一种基础的数据结构可以用来生成其它类型的数据结构。链表通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向上一个/或下一个节点的位置的链接("links")。链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的访问往往要在不同的排列顺序中转换。而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。链表允许插入和移除表上任意位置上的节点,但是不允许随机存取。链表有很多种不同的类型:单向链表,双向链表以及循环链表。
链表可以在多种编程语言中实现。像Lisp和Scheme这样的语言的内建数据类型中就包含了链表的访问和操作。程序语言或面向对象语言,如C/C++和Java依靠易变工具来生成链表。
特点:
•最简单的动态数据结构
•可以辅助组成其他数据结构
•数据存储在“节点”(Node)中
•不一定按顺序存储
•真正的动态,不需要处理固定容量的问题
•没有随机访问的能力
图解:

数组和链表的对比:
前面我们学过动态数组,栈,队列,它们底层都依托于静态数组,靠resize解决固定容量问题,而链表却是真正的动态数据结构。
•数组最好用于索引有语义的情况
•数组优点:支持快速查询
•链表不适合用于索引有语义的情况
•链表优点:动态
代码实现步骤:

节点代码实现:
我们先定义一个叫做节点的内部类:
//节点
class Node{
private E data;//数据域
private Node next;//结点指针
//部分代码可不写,仅作理解之用
//无参时数据域和节点域都为空
public Node(){
this.data = null;
this.next = null;
}
//数据域为data,节点域为空
public Node(E data){
this.data = data;
this.next = null;
}
//数据域为data,节点域为next
public Node(E data,Node next){
this.data = data;
this.next = next;
}
}
初看代码好像挺难理解,为什么Node(结点)里面又有Node?
其实细细想想挺好理解,JAVA的对象都是引用型的,比如:
① Node node ;
② Node node1 = new Node();
③ Node node2= new Node(data,next);
①里的代码只声明了一个node引用型变量,而没有new一个Node对象,我们可以把node这个引用理解为"指针"(其实不是,为什么可以去查查资料),此时node并没有指向任何一个对象,可以理解为一个空指针(我存在,但我不指向其他对象);
②里的代码new了一个Node对象,node1这个指针就指向了这个对象,此时是空的构造方法,
data为null,next也为null,next也是Node类型的,next此时和①一样;
③ 里的代码也new了一个Node对象,node2指针指向这个对象,因为此时是有参数的构造方法,data这个数据域也就有了值(传进来的data),next这个指针此时指向传进来的next。
就和老式的火车厢一样,一个火车厢包括车厢和挂钩,挂钩又可以连着下一节火车厢
即火车厢 = 车厢+挂钩,而挂钩又可以连着下一个火车厢。
①②③通俗化:
①知道有个火车厢,但是它即没有车厢也没有挂钩(???),即它只是一个概念,没有实体
②知道有个火车厢,有车厢也有挂钩(车厢里没东西,挂钩也没有连着下一节火车厢)
③知道有个火车厢,有车厢也有挂钩(车厢里放着东西,挂钩也连着下一节火车厢)
好,现在我们开始正式的代码:
代码部分(虚拟头结点):
public class LinkedList {
//结点
class Node {
private E data;//数据域
private Node next;//结点指针
//无参时数据域和节点域都为空
public Node() {
this.data = null;
this.next = null;
}
//数据域为data,节点域为空
public Node(E data) {
this.data = data;
this.next = null;
}
//数据域为data,节点域为next
public Node(E data, Node next) {
this.data = data;
this.next = next;
}
}
private Node dummyhead; //虚拟头结点,此结点不存储数据(dummyhead可以理解为指针)
private int size;//链表数据个数
public LinkedList() {
dummyhead = new Node(null, null);
size = 0;
}
//当前元素个数
public int size() {
return size;
}
//链表是否为空
public boolean isEmpty() {
return size == 0;
}
//在链表的index位置添加新数据,在链表中不是一个常用的操作
public void add(int index, E data) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("Index is illegal");
}
Node pre = dummyhead;
for (int i = 0; i < index; i++) {
pre = pre.next;
}
pre.next = new Node(data, pre.next);
size++;
}
//在链表首(虚拟头结点后)位置添加数据
public void addFirst(E data) {
add(0, data);
}
//在链表尾添加数据
public void addLast(E data) {
add(size, data);
}
//获取链表指定索引处的数据
public E get(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Index is illegal");
}
Node current = dummyhead.next;
for (int i = 0; i < index; i++) {
current = current.next;
}
return current.data;
}
//获取链表0索引处的数据
public E getFirst() {
return get(0);
}
//获取链表表尾处的数据
public E getLast() {
return get(size - 1);
}
//修改链表指定索引处的数据
public void set(int index, E data) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("Index is illegal");
}
Node current = dummyhead.next;
for (int i = 0; i < index; i++) {
current = current.next;
}
current.data = data;
}
//查看链表是否包含某数据
public boolean contains(E data) {
Node current = dummyhead.next;
while (current != null) {
if (current.data == data) {
return true;
}
current = current.next;
}
return false;
}
//删除链表指定索引的数据
public E remove(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Index is illegal");
}
Node pre = dummyhead;
for (int i = 0; i < index; i++) {
pre = pre.next;
}
Node ret = pre.next;
pre.next = ret.next;
ret.next = null;
size--;
return ret.data;
}
//删除0索引的数据
public E removeFirst() {
return remove(0);
}
//删除最后一个数据
public E removeLast() {
return remove(size - 1);
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("LinkedList:");
for (Node current = dummyhead.next; current != null; current = current.next) {
res.append(current.data + "-->");
}
res.append("NULL");
return res.toString();
}
}
这里的代码用到了虚拟头结点,什么是虚拟头结点,不用它有什么坏处?
我们先说不用虚拟头结点的坏处,如果我们想在链表头添加一个结点,我们需要这么写:
//结点代码与上文相同,省略
private Node head;
private int size;
public LinkedList() {
head = null;
size = 0;
}
// 在表头插入数据
public void addFirst(E data) {
head = new Node(data, head);
// 上一行代码相当于下面代码的缩写
// Node prev = new Node(data);
// prev.next = head;
// head = prev;
size++;
}
public void add(int index, E data) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("Index is illegal");
}
if (index == 0) {
addFirst(data);
} else {
Node prev = head;
for (int i = 0; i < index - 1; i++) {
prev = prev.next;
}
//缩写和前一个方法类似
prev.next = new Node(data, prev.next);
size++;
}
}
}
//后续代码省略
在表头插入数据需要这样:
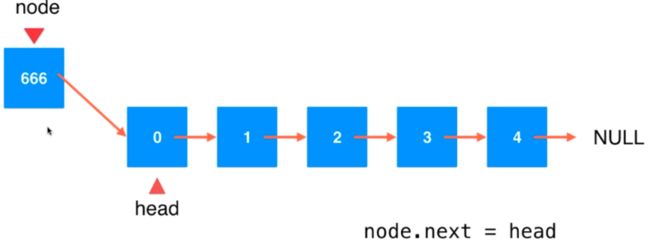

在其他结点插入数据需要这样:


都是插入操作其代码却不能统一,在头结点插入数据能不能和其他结点插入操作一样呢,这时候我们就需要虚拟头结点了。
虚拟头结点的概念:
虚拟头结点:链表的增加和删除操作,一定要通过待处理节点的前一个节点来实现,为了解决头结点没有前继节点的特殊性,需要给链表添加一个虚拟头结点。新建指针一个用于索引的指针dummyHead, 指向待处理节点的前继节点,则待处理节点为dummyHead.next. 初始化dummyHead则指向链表的虚拟头结点。
注意:虚拟头结点不存储任何数据,和循环队列差不多
其中,虚拟头结点的图示:

添加操作:
先新建一个结点指针prev,令其指向dummyHead结点,prev指针经循环操作后到要添加的结点的前一个位置,然后进行如下操作:

删除操作:
先新建一个结点指针prev,令其指向dummyHead结点,prev指针经循环操作后到要删除的结点的前一个位置,然后进行如下操作:

为什么在链表表尾添加数据和删除数据传入的参数不同?
因为添加和删除操作均要操作待处理结点的前一个结点来实现,在表尾添加数据时依托于链表中存在的最后一个结点(将其作为前继结点),而表尾删除数据时删除的是最后一个结点,此时依托倒数于第二个结点(将其作为前继结点)。
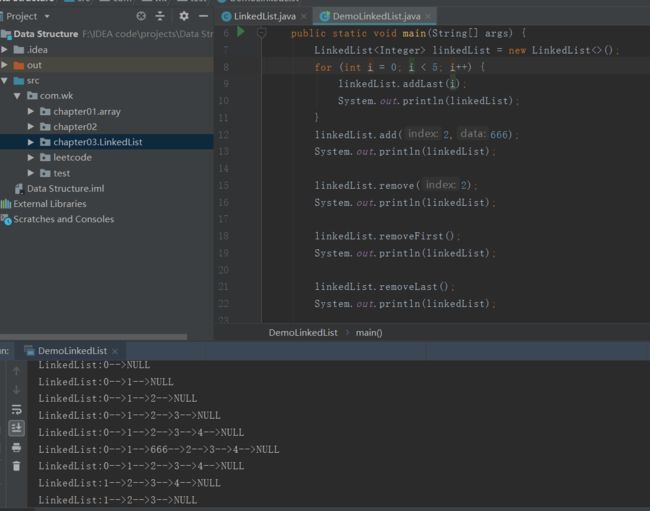
测试结果:
时间复杂度:
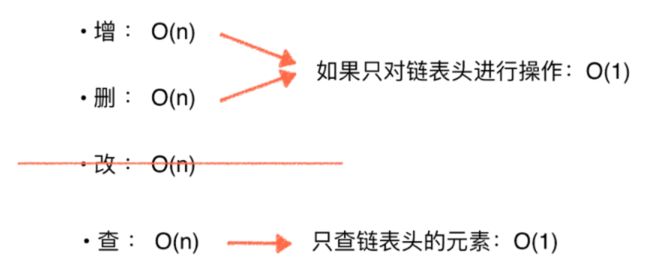
•添加操作:O(n)

•删除操作:O(n)

•修改操作:
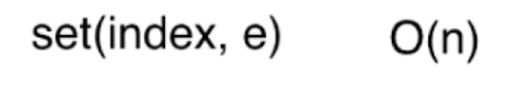
•查询操作:

总结: