相关性分析用于评估两个或多个变量之间的关联性。
1. 两个变量的相关性分析
参数相关性检验( parametric correlation )
皮尔森相关性分析是一种参数相关性检验,检测的是两个变量间的线性关系;应用皮尔森相关性分析的前提是两个变量都是正态分布的,其相关性可以用线性回归曲线表示。
相关性分析前提
是否为线性相关:geom_smoth()
正态性
如果不满足正态性,最好用非参数检验
cor(){stats} 只给出相关系数
cor(mtcars$wt, mtcars$mpg, method = "pearson")
# cor.test(){stats} 适用于成对变量相关性检验
cor(mtcars$wt, mtcars$mpg, method = "pearson")
结果分析
H0: true correlation is equal to 0
cor.test(){stats} 返回一系列参数,主要关注p.value 和 correlation coefficient(ample estimates: cor );
2. 非参相关性检验
肯德尔等级相关系数( Kendall's tau coefficient, kendall):适用于两个分类变量均为有序变量的情况。对相关的有序变量进行非参数相关检验,取值范围在-1-1之间。Kendall(){ Kendall}, pKendall(){ SuppDists}
斯皮尔曼的等级相关系数(Spearman's coefficient, spearm); pSpearman(){SuppDists}, spearman.test(){pspearman}
可以改变cor.test(){stats}中的method 参数进行非参检验,但stats 的作者都表示用上面提到的包更的支持数据种类更多、估计结果准确性更高。
3. 相关矩阵
实际上就是每一个变量与其他变量间的相关性检验,因此方法也是上面提到的参数相关和非参相关检验。
# 去掉分组变量
data <- mtcars[, c(1,3,4,5,6,7)]
# 相关系数矩阵
cor(data, method = "pearson")
rcorr(){Hmisc}:Matrix of Correlations and P-values
rcorr.cens(){Hmisc}:Rank Correlation for Censored Data
rcorrp.cens(){Hmisc}:Rank Correlation for Paired Predictors with a Possibly Censored Response, and Integrated Discrimination Index
corr.test (){psych} : Find the correlations, sample sizes, and probability values between elements of a matrix or data.frame.
4. 为什么需要p值
比如上面,我们用mtcars的一部分数据算出了disp 与 qsec 具有负相关关系,但由于mtcars 只是只是从总体X中抽出的一部分数据(没人敢说收集了全部数据,应该!),所以计算出的相关系数r并不一定能代表总体数据的相关系数 ρ ; 因此需要显著性检验,计算显著性水平。
H0:总体X中的两个数据的相关系数ρ=0(也就是说假设总体上disp和qsec没有相关关系)
p值校正
多个检验同时进行时,如果对任意单个假设检验问题,p-值小于 α就拒绝原假设,则无法控制总体第一类错误率(family-wise error rate, FWER);FWER随检验个数 mm增大而增大( m→∞m→∞时收敛到1)。
总的来说,当同一个数据集有n次(n>=2)假设检验时,就要做多重假设检验校正
p.adjust(){stats}中的参数:p.adjust.methods = c("holm", "hochberg", "hommel", "bonferroni", "BH", "BY","fdr", "none")
Hochberg's and Hommel's :适用于假设检验是独立或非负相关的检验结果, Hommel的方法比Hochberg的方法更强大,但差异通常很小,而Hochberg 的计算速度更快。
*BH{aka fdr(False Discovery Rate)} : 是控制错误发现率,即将假阳性结果和真阳性的比例控制在一定范围内。 错误发现率是一种不如第一类错误率(family-wise error rate, FWER)严格的条件,因此这些方法比其他方法更有效,也是非常常用的方法。
bonferroni :通过对p值的阈值进行校正来实现消除假阳性结果,是最严格的矫正方法,校正后拒绝的不只是假阳性结果,很多阳性结果也会被它拒绝。bonferroni 通过公式 p*(1/n){其中p为原始阈值,n为总检验次数},拒绝le所有的假阳性结果发生的可能性。
4. 两个矩阵相关关系的检验 - mental test
H0: 两矩阵没有相关关系。
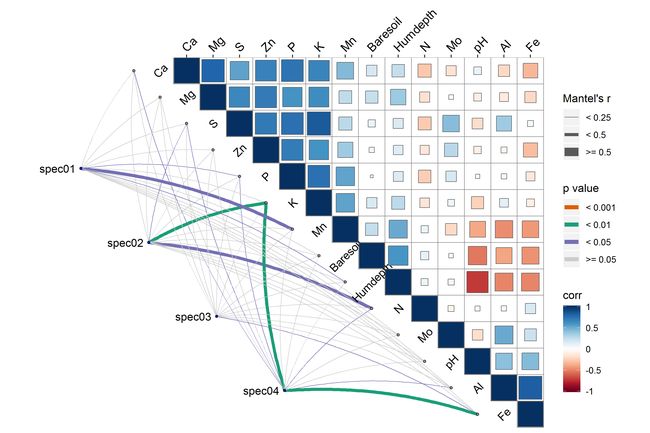
在微生物群落分析中, 免不了分析环境因子与菌落的相关性,此时便需要做CCA 和 Mantel test 分析 。Mantel test 分析是将微生物群落作为一个距离矩阵(如UniFrac distance matrix),环境变量作为另一个距离矩阵(如pH、有机碳、总氮、盐度、温度、地理等),再检验两个矩阵之间的相关性。
mantel.rtest (){ ade4 }
mantel(){ecodist}
mantel(){vegan}
ggcor不仅内置了mental test 函数, 也很好的实现了mental test 可视化。
5. 相关系数可视化
如果是矩阵相关系数计算,结果可能不怎么好解读。通过热图的方式可以有效的将结果分为多个层次,然后再对每个层次进行专注解读就显得方便多了。
专门为相关矩阵可视化写的R包也不少,包括画风比较粗狂、但结果又比较详细的corrgram, GGally, PerformanceAnalytics等,他们可以将原始数据分布,相关系数,线性回归的回归线,显著性P值等展示在一张画布中;而基于base绘图系统写的corrplot 应该是最为精美的了,配色清新,功能齐全。对于已经习惯用了grid 图形系统的ggplot2语法的人来说,ggcorrplot 只实现了小部分的corrplot内容,虽然也很精美但是又有些意犹未尽的感觉;还在紧锣密鼓构建中的 ggcor将满足大部分的相关系数可视化需求。
ggcor
ggcor不同于常规的ggplot2扩展包,它引入了ggcor函数,目的调用ggplot() 来进行图层初始化,因此很多图层参数是通用的;但它需要相关系数矩阵来进行数据处理、绘图类型、背景、坐标轴、颜色映射、图例设置等,因此矩阵需要在这一步就输入。要么调用作者封装的cor(){stats}或 cor.test(){stats},要么处理数据后用 as_cor_tbl() 和 fortify_cor()两个函数导入,应该能满足基本需求。
as_cor_tbl()函数 :
x—相关系数矩阵(或者数据框),矩阵行名和列名是必要的,若没有或者缺失值会自动补全名字,行名以“Y”开头,附上递增的整数序列,列名以“X”开头,附上附上递增的整数序列。
type — 相关系数矩阵图样式,“upper”截断下三角,“lower”截断上三角。
show.diag — 相关系数矩阵图中是否包含对角线,仅对对称矩阵有效。
p —相关系数检验p值矩阵(或者数据框),必须与x一对应。
low 、upp—相关系数置信区间矩阵(或者数据框),必须与x一对应; cluster.type —是否对相关系数矩阵进行重新排序
fortify_cor()函数:
主要用于处理原始数据表,可以调用cor(){stats}求相关系数,默认使用pearson方法,当然spearman和kendall方法也都支持。但stats 包的作者在cor() 下面提到,如果要用spearman和kendall 的方法,最好用其他的包。而且涉及P值矫正什么的,可能cor() 或者 cor.test() 函数并不能达到要求,最好还是自己做统计分析,最后进行数据格式处理。
几个重要图层:
geom_square()、geom_circle2()、geom_ellipse2()、geom_pie2()、geom_colour()、geom_confbox()、geom_num()、geom_mark()、geom_cross()
基本就是形状、色彩、大小等,值得提出来说的只有geom_cross() 这个是根据阈值,在阈值外的位置打上一个X。
可映射参数
-
r — 相关系数值,适用于geom_square()、geom_circle2()、geom_ellipse2()、geom_pie2()、geom_confbox()、geom_mark(),数值会直接显示在图标上。
p — 相关系数检验P值,适用于geom_mark()、geom_cross(),结合
sig.thres等参数来根据显著性水平做一些辅助标记。r、low、upp — 适用于geom_confbox(),三个参数均是必须的,low、r、upp 分别确定置信区间盒子的下端、中间和上端线条位置。
非映射参数
-
r0 —外接圆半径缩放系数,适用于geom_square()、geom_circle2()、geom_ellipse2()、geom_pie2()函数。该参数的主要意义是处理图形覆盖问题,当在每个单元格画半径为0.5的方块、圆等图标时,会相互覆盖掉背景网格线,影响视觉效果。该参数默认值是0.48。
sig.thres — P.value临界值,用于geom_mark()、geom_cross(),规定可以显示的显著性阈值。
sig.level、mark —适用于geom_mark(),前者为统计显著性水平向量,后者为对应的标记符号;如:想规定 c(0.001, 0.01, 0.05)为三个显著性阈值,后者对应为标记符号c("", "", ""),那么相关矩阵的图就会根据阈值,添加标记符号,注意vjust。
6. 示例
- corr.test(){psych} 可以自动对多重比较结果进行P值矫正
- 外部进行统计检验后的数据导入,其他的就是ggplot2 和 ggcor 图形参数。
require(psych)
require(ggcor)
data <- mtcars[, c(1,3,4,5,6,7)]
# 用corr.test(){psych}进行相关性检验
# 对于对称矩阵,corr.test会自动对多重比较进行P值矫正
# 矫正结果是结果矩阵的上三角,下三角为未矫正P值
cor <- corr.test(data)
r <- cor$r
pa <- round(cor$p,3)
dat <- as_cor_tbl(r, type = "upper", p = pa)
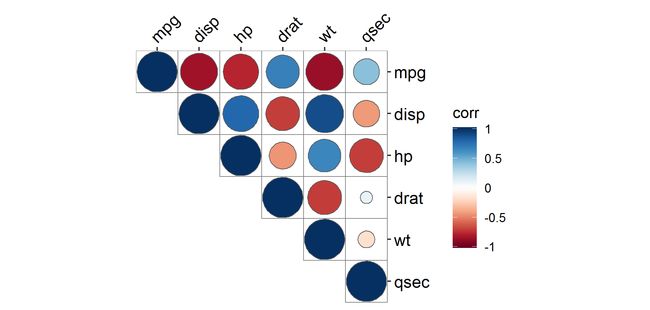
ggcor(dat) + geom_circle2()
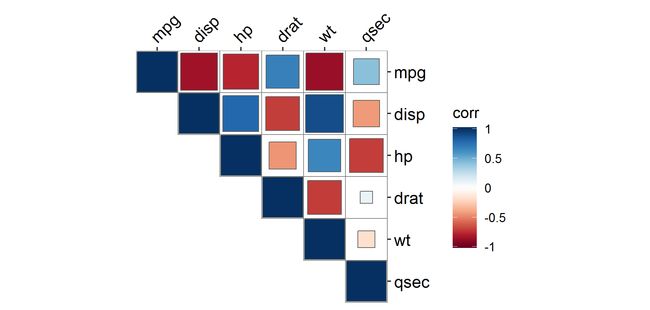
ggcor(dat) + geom_colour() +
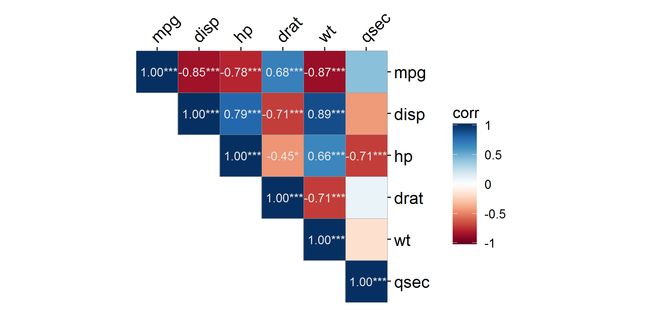
geom_mark(sig.thres = 0.05, size = 3, colour = "grey")