1 测试基础知识储备
按照项目开发阶段来分:单元测试、集成测试、系统测试、验收测试
按照测试执行的类型划分:功能测试、自动化测试、性能测试
按照测试技术的不同来分:黑盒测试、白盒测试、灰盒测试
测试人员需要具备一定程度的计算机技术储备,只累积测试经验远远不够,要不断的学习其他领域的知识,大致包括以下:js/css前端技术、网络架构、网络协议、DNS解析、负载均衡策略、Linux系统基本操作、数据库知识等。
2 Python测试基础
变量赋值:Python在给变量赋值时,不需要类型声明,而且变量可以存储任何值。每个变量在使用之前都必须赋值,变量赋值以后该变量才会被创建。每个变量在内存中创建,都包括变量的标识、名称和数据这些信息。变量不仅可以赋值给各种类型,还可以随意改变类型。
全局变量的引用:全局变量的调用需要通过global+变量的方式引用。
算数运算:出现复杂的运算时遵循两个原则,1)括号内的运算优先运算;2)先乘除后加减,从左往右依次运算。
关系运算:大于>、大于等于>=、小于<、小于等于<=、等于==、不等于!=;关系运算符的优先级低于算数运算。
逻辑运算:逻辑与x and y,逻辑或x or y,逻辑非x not;在理解这3种逻辑运算之前先要明白true和false的判断,值不为0或者不为空,程序均判断为true。对于逻辑与,只有当x为true的时候,才会计算y的值;对于逻辑或,只有当x为false的时候,才会计算y的值;对于逻辑非,当x为true的时候返回false,反之返回true。逻辑运算的优先级低于关系运算。
数据结构:python内置了几种数据结构、元组、列表、字典。
元组:元组可以由不同的元素组成,每个元素可以是不同的数据类型,字符串、数组或者元组,创建元组的语法格式如下,变量名=(元素1,元素2,...),初始化示例,a=(1,2,“d”,(1,“d”)),元组一旦被创建就不能被修改,即元组为只读。元组的读取按照编号排序,每一个元素会有一个编号,不仅可以正序读取,还可以倒序读取,两者的区别在于正序从0开始依次往后加,而倒序从-1依次往前减。要读取元组的多个元素时,采用“元组[m:n]”的方式,m和n就是索引的序号,代表读取元素从m到n的元素,但不包括n这个元素本身。元组的索引如下所示:

列表:列表和元素类似,都是一组元素的集合,区别在于列表可以增删改。创建列表的语法格式,变量名=[元素1,元素2,...]。列表的相关语法,1)list.append(元素)调用列表的添加方法加入元素,并将元素添加到列表最后;2)list.insert(索引位置,元素)调用列表的插入方法加入元素到指定的位置,之后的元素索引位置依次向后顺移;3)list.remove(元素)调用列表的移除方法删除元素,之后的元素索引位置依次向前顺移;4) list[n]=元素(新)读取列表中的某一个元素并重新赋值便完成了修改,索引位置不变,只是元素被替代了。
列表之间的合并:1)list1.extend(list2)调用列表1的扩展方法加入列表2,并将列表2的元素放到列表1元素的后面;2)list1=list1+list2直接通过列表相加的方法并重新赋值到列表1之中。
字典:字典由一系列“键-值”成对组成,每一组可以理解为元组和列表的一个元素,并通过{}包含起来,创建字典语法格式如下,dictionary={键1:值1,键2:值2,...},字典的读取也是通过索引,不过字典的索引不是通过数字而是通过键作为索引的,所以字典没有位置先后的概念。如下的实例代码中运行的结果为:1 ok。

字典的增加和修改:通过给某个键进行对应的赋值,当键对应的值存在时将原来的值替换为新的值,当键不存在时创建一个新的“键-值”,dictionary[键]=值。
字典的删除:直接用内置del()函数,删除字典中的键就等于删除了对应的值,Del(dictionary[键])。

字典之间的合并:使用字典的update方法,dict1.update(dict2)。与列表合并的区别在于,列表可以合并重复的数据并且不会被替代,而字典中如果有重复的键,会被新的键的对应的值所替代。
函数:函数就是一段代码的集合,并且可以重复被调用,也就是处理事务的方法。python中内置了很多函数,可以直接调用。自定义函数的语法如下,def 函数名(): ... 函数名可以由数字、字母或者下划线组合而成,但不能以数字开头,冒号以下的代码是函数的主体,换行的缩进表示代码属于该函数。
函数的参数:自定义函数的时候可以加上参数,参数放在括号之中,参数可以是一个或者是多个。给形参赋值的实例代码说明:1)调用add()函数,由于创建参数时已经赋予了默认值,所以可以不用再填入实际参数,会以默认值作为实参运行;2)调用执行add(2,3)函数,给形参分别赋值2和3,此时a和b的值将被改变;3)调用执行add()函数,虽然第5行调用时改变量a和b的值,但对于函数本身默认值是不会变的,调用时改变的值只对调用时生效,不会影响函数本身的默认值。


函数的返回值:Python区别于其他语言的地方在于不会报错,当没有返回值时会返回一个none。若需要保存某个变量的值,需要在函数中加return+返回值。有多个返回值时,多个返回值之间用逗号隔开,数据以元组的形式返回,同样可以将返回值按照顺序赋值给多个变量。


函数的嵌套:在某个函数的代码中调用其他函数即为函数的嵌套。

字符串的转换:Python内置了str()函数可以将任何类型的数据转换成字符串,语法格式如下,s=str(任意数据类型),将需要转换类型的数据当做str的参数放入执行,运行的结果就是转换成的字符串。其他类型的数据,包括元组、列表、字典等都可以通过str()转换成字符串。

字符串的合并:字符串的合并只需要通过“+”连接即完成了合并,Python会根据“+”两侧的数据类型决定是连接操作还是运算,但是不同类型的数据是无法进行合并的。
字符串的截取:可以用索引的方式,可以用split()函数,或者是使用正则表达式。1)字符串的索引和元组、列表、字典相似,不同之处在于字符串是给每一个字符一个位置,而不是以元素为单位的,但是这种方式效率不高;2)使用字符串自带的split()函数将数据分割成段,并以元素的形式放入列表之中,然后通过索引截取相应的字符串,split中的参数就是分隔符,并且分隔符会被去掉,语法格式如下,split(字符/字符串,分割次数)。分割次数可以省略,默认情况下会根据字符串出现的次数进行分割。split()分割实例中,字符串以逗号为界限分割字符,由于逗号出现了3次,没有指定分隔符,所以默认将数据分割成了4段。语句3打印分割后的数据类型,语句4打印分割后列表的第三个字符串。此外,split()函数可以多次使用。


字符串的替换:使用字符串自带的replace()函数,语法格式如下,replace(原字符串,替换的字符串,替换次数),替换的次数默认是全部,如果指定替换次数就按照顺序替换,达到替换次数之后就不再进行替换了。注意,replace()函数只替换副本,不会改变原来的值,如果需要的话需要将替换后的副本重新赋值给新的变量。
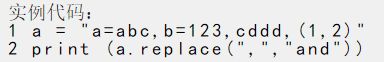


3 接口测试基础
一 、网络传输知识
协议:在接口测试中,从客户端发送request至服务器反馈response,网络传输的数据就是接口测试中的主要部分,而数据传输的本质就是基于网络传输协议。
缓存cache:浏览器缓存、代理缓存、网关缓存
cookie:cookie的内容是保存的一小段文本信息,这些文本信息组成一份通行证。它是客户端对于无状态协议的一种解决方案。
获取cookie的途径:1)使用浏览器的开发者工具或者专业的抓包工具获取;2)从本地文件中获取;3)通过前端技术获取。

cookie的生命周期:cookie的生命周期是可以设置的,在创建测试场景时可以根据需求进行相应的设置。cookie的生存周期是整个会话期间:浏览器会将cookie保存在内存中,浏览器关闭时就会自动清除这个cookie。cookie的生存周期是长期有效:cookie保存在客户端的硬盘中,浏览器关闭的话该coolie也不会被清除,下次打开浏览器访问对应网站时,这个cookie就会自动再次发送到对应的服务器端。
cookie不可跨域名或者浏览器使用:一般cookie是不可以跨域名的,这是由cookie的隐私安全机制决定的。隐私安全机制能够禁止网站非法获取其他网站的cookie。
session:session是另外一种记录用户状态的机制,不同的是cookie保存在客户端浏览器中,而session保存在服务器上。session是服务器端对于无状态协议的一种解决方案。客户端访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上,这就是session。客户端再次访问时,只需要从该session中查找该用户的状态即可。
session的传输媒介:
1)通过cookie传输,session的信息是保存在服务器端的。测试人员只需要运用抓包工具从cookie中获取session ID的值用于模拟用户的请求。虽然session保存在服务器上,对客户端是透明的,但他的正常运行仍然需要客户端浏览器的支持,这是因为session需要使用cookie作为识别标志。因此,服务器向客户端浏览器发送一个名为JSESSIONID的cookie,它的值为该session的ID,测试人员获取JSESSIONID的值即可。session的有效期与会话有关,存储JSESSIONID的cookie是服务器自动生成的,它的maxAge属性一般为-1,表示仅当前浏览器内有效。
2)URL地址重写,URL地址重写是对客户端不支持cookie的解决方案。它的原理是将该用户session的ID信息重写到URL地址中,服务器能够解析重写后的URL地址,获取session的ID。这样即使客户端不支持cookie,也可以使用session来记录用户状态。
session的生命周期:对于session来说,除非程序通知服务器删除一个session,否则服务器会一直保留,程序一般都是在用户做log off的时候发出指令去删除session。关闭浏览器不会导致session被删除,会迫使服务器为session设置一个失效时间,当距离客户端上一次使用session的时间超过这个失效时间时,服务器就可以认为客户端已经停止了活动,才会把session删除,以节省存储空间。
cookie与session的区别:
1)存储位置不同,通常情况下cookie的数据存放在客户端浏览器上,而session的数据存放在服务器上。
2)存储容量不同,通常情况下单个cookie保存的数据<=4kb,一个站点最多保存20个cookie;对于session并没有上限,不过出于服务器端的性能考虑,session内不要放过多的东西,并且设置session删除机制。
3)存取方式的不同,cookie中只能保管ASCII字符串,需要通过编码的方式存取Unicode字符或者二进制数据,运用cookie难以实现存储略微复杂的信息;session中能够存储任何类型的数据,包括且不限于string、interger、list、map等。
4)隐私策略的不同,cookie对于客户端是可见的,别有用心的人可以分析存放在本地的cookie并进行cookie欺骗,所以cookie是不安全的;session存储在服务器上,对客户端是透明的,不存在敏感信息泄露的风险。
5)有效期上的不同,开发者可以通过设置cookie的属性,达到使cookie长期有效的效果;由于session依赖于名为JSESSIONID的cookie,而cookie JSESSIONID的过期时间默认为-1,只需关闭窗口该session就会失效,所以session不能达到长期有效的效果。就算不依赖于cookie,运用URL地址重写也不能完成,假设设置的session的超时时间过长,服务器累积的session就会越多,越容易导致session溢出。
6)服务器压力的不同,session是保存在服务器端的,每个用户都会产生一个session。假如并发访问的用户很多,则会产生很多的session,耗费大量的内存;cookie保存在客户端,不占用服务器资源,对于并发用户多的网站,cookie是很好的选择。
7)浏览器支持的不同,1、假如客户端浏览器不支持cookie:cookie是需要客户端浏览器的支持的,假如客户端禁用了cookie,或者不支持cookie,则回话跟踪会失败。关于WAP上的应用,常规的cookie就派不上用场了;运用session需要使用URL地址重写的方式,一切用到session程序的URL都要进行URL地址重写,否则session回话跟踪还会失效。关于WAP应用来说,session+URL地址重写或许是它唯一的选择。2、假如客户端支持cookie:cookie既能够设为本浏览器窗口及子窗口内有效(把过期时间设为-1),也能够设为一切窗口内有效(把过期时间设为某个大于0的整数);session只能在本窗口及子窗口内有效,假如两个浏览器窗口互不相干,它们将运用两个不同的session。
8)跨域支持上的不同,cookie支持跨域名访问,例如将domain属性设置为“.biaodianfu.com”,则以“.biaodianfu.com”为后缀的一切域名均能够访问该cookie。跨域名cookie如今被普遍用在网络中,例如Google、baidu、sina等;session则不会支持跨域名访问,session仅在自己所在的域名内有效。
token:以时间换取空间的方式。
1)当客户端第一次请求时,发送用户信息至服务器。服务器对用户信息使用hs256算法及秘钥进行签名,再将这个签名和数据一起作为token,返回给客户端;
2)服务器端不保存token,客户端保存token;
3)当客户再次发送请求时,在请求信息中将token一起发给服务器;
4)服务器用同样的hs256算法和同样的秘钥,对数据再计算一次签名,和token中的签名比较。如果相同,服务器就知道客户端已经登录过了,并且可以直接提取到客户端的user ID。如果不相同,数据部分肯定被人篡改过,服务器就返回客户端,认证不通过。
运用token服务器就不需要保存session ID,只负责生成token,然后验证token。这就是服务器用CPU计算时间换取session存储空间的方式。token的传递通常放在cookie中,如果客户端不支持cookie,token也可以放置在请求头中。和cookie一样,为了数据安全性token中不应该放密码等敏感信息。可以土狗抓包工具获取token值。token通常被用于一种轻巧的规范下,这种规范叫做JSON Web Token(JWT)。

JSON Web Token:JWT是一种开放标准(RFC 7519),定义了一种紧凑且安全的标准,用于将各方之间的信息传输为JSON对象。该对象通过数字签名进行验证。使用HMAC算法或使用RSA的公钥/私钥对JWT进行签名,它是rest接口的一种安全策略。
JWT的组成:头部、载荷、签名。
1)头部 (Header),头部用于描述JWT最基本的信息,例如类型和签名所用的算法等。它被表示成一个JSON对象,如下的示例,说明了这是一个JWT,使用的签名算法是hs256算法,对他进行base64编码后形成的字符串就成了JWT的header。
{
"type::"JWT",
"alg":"hs256"
}
2)载荷(Payload),以下示例中的5个字段是由JWT的标准所定义的,将下面示例的JSON对象进行base64编码可以得到一串字符串,将这个字符型称作为JWT的载荷。
iss:该JWT的签发者;
iat(issued at):在什么时候签发的;
exp(expires):什么时候过期,这里是一个Unix时间戳;
aud:接收该JWT的一方;
sub:该JWT所面向的用户;

3)签名(Signature),将上面的两个编码后的字符串用“.”连接在一起(头部在一起),就形成了一串新的字符串。最后,将拼接完的字符串用hs256算法进行加密。在加密的时候,需要提供一个秘钥(secret)。通过秘钥和加密算法加密后的部分就叫做签名。
最后将这一部分签名也拼接在被签名的字符串的后面,就得到了完整的JWT。
二、HTTP协议
国际标准化组织(ISO)将计算机网络T恤结构的通信协议划分为7层,自上而下依次为:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层。每层的网络协议如下:
1)物理层:以太网、调制解调器、电力线通信(PLC)、SONET/SDH、光导纤维、同轴电缆、双绞线等。
2)数据链路层:Wi-Fi(IEEE 802.11)、WiMAX((IEEE 802.16)、ATM、令牌环、PPP、L2TP、PPTP等。
3)网络层协议:IP(IPv4,IPv6)、ICMP、ICMPv6、IGMP、IS-IS、IPsec、ARP、RARP等。
4)传输层协议:TCP、UDP、TLS、DCCP、SATP、RSVP、OSPF等。
5)应用层协议:NDS、FTP、Gopher、HTTP、IMAP4、POP3、SIP、SSH、TELNET、RPC、SDP、SOAP、GTP等。
HTTP协议介绍:
1)HTTP是建立在TCP/IP协议之上的,面向应用层的超文本传输协议。
2)HTTP由请求和响应组成,完全符合标准的客户端服务器的请求响应模型。
3)HTTP协议很轻便简单,并且请求与请求间没有关联,是无状态性的协议。
4)为了弥补这种无状态性就需要使用HTTP协议的扩展cookie等方式建立关联。
HTTP协议的原理:
HTTP协议工作于客户端-服务端的架构上,客户端通过URL向服务端发送所有请求,服务器根据接收到的请求,向客户端发送响应信息。HTTP协议采用了请求/响应模型。如下图所示:
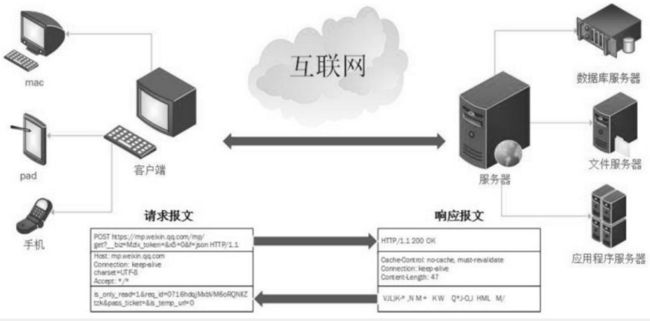
客户端,客户端的主要职能:1、向服务器发送请求;2、接收服务器返回的报文并解释成友善的信息供我们阅读。客户端大概有以下几类:浏览器、应用程序(桌面应用和app应用)等。
以Chrome浏览器为例,在地址栏输入网址并回车,浏览器做的处理如下:
1)解析出协议(HTTP)、域名(www.qq.com)。
2)使用HTTP协议并创建请求报文向服务器发送请求。
3)接收到服务器返回的内容并经过渲染之后展示给客户。
服务器,服务器的处理过程:
1、建立连接,如果客户端已经打开一条道服务器的持久连接,则可以直接使用,否则,客户端需要在服务器打开一条新的连接。
2、接收请求报文,连接上有数据时,Web服务器会从网络连接中读取数据,并将请求报文中的数据解析出来。
3、接收后表示成相应的形式。
4、处理请求,当请求被接收和表示之后,服务器便可根据请求报文进行处理。例如,post方法中提出报文主体的数据并插入到数据之中。
5、访问资源,请求处理完成之后,比如web会根据数据生成一系列的HTML页面或者图片信息,此步骤将访问这些存储在服务器上的物理文件。
6、构建响应,web服务器在识别资源之后,构造响应报文。响应报文中包含状态码、响应头、主体等内容。
7、发送响应,服务器将响应的数据发送给客户端机器。
8、记录日志,请求结束,web服务器会在日志文件中添加一条请求记录。
报文,客户端与服务器端之间的信息传递使用的载体就叫做报文,报文分为请求和响应两部分。
1、客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。
2、服务器反馈给客户端一个响应报文,响应报文包括协议的版本、成功或错误的响应码、服务器信息、响应头部和响应数据。
Uniform Resource Locator(URL):是互联网上用来标识某一处资源的地址。假设请求发送地址为:www.eaxmple.com/index.html。浏览器会将地址解析为,Host: www.example.com , Name: Uri Value: index.html ,其中的URI是HTTP中的统一资源标识符(Uniform Resource Idetifiers),用来传输数据和建立连接。日常使用的URL是一种特殊类型的URI,包含了用于查找某个资源的足够信息。
URL的主要作用:
1)HTTP是URL的方案,方案告诉客户端使用什么样的协议去访问服务器。
2)Host:www.eaxmple.com,指服务器的位置。
3)/index.html是资源路径,说明了请求的是服务器上哪个特定的本地资源。
URL的组成:
1)协议部分,
2)域名部分,
3)端口部分,
4)虚拟目录部分,
5)文件名部分,
6)锚部分,
7)参数部分,
请求报文
报文格式:request报文分为3部分,请求行(request line),请求头部(header),主体(body)。header和body之间有个空行。HTTP的请求报文格式如下:

请求报文的headers属性:
1)cache头域,cache-control用来指定response-request遵循的缓存机制;if-modified-since把浏览器端 韩村页面的最后修改时间发送到服务器;if-none-match和etag一起工作;pragma防止页面被缓存。
2)client头域,accept浏览器端可以接收的媒体类型;user-agent告诉HTTP服务器客户端使用的操作系统和浏览器的名称和版本;accept-charset浏览器声明自己接收的字符集。
3)cookie头域,最重要的header,将cookie的值发送给HTTP服务器。
4)miscellaneous头域,提供了request的上下文信息的服务器。
5)entity头域,content-length发送 给HTTP服务器数据的长度;content-type表示具体请求中的媒体类型信息。
6)transport头域,connection和host。
请求报文的方法:
1)get方式:是以实体的方式得到请求URI所指定的资源信息,如果请求URI只是一个数据产生的过程,那么最终要在响应实体中返回的是处理过程的结果所指向的资源,而不是处理过程的描述。
2)post方式:用来向目的服务器发出请求,要求它接收被附在请求后的实体,并把它当作请求队列中请求URI所指定资源的附加新子项,所以post请求可能会导致新的资源的建立或已有资源的修改。
响应报文
报文格式:分为三部分响应状态(response code)、响应头(response header)、响应主体(response body),header和主体之间也有个空行。结构如下所示:

响应报文的headers属性:
1)cache头域,cache-control用来设置缓存的属性;date生成消息的具体时间和日期;expires浏览器会在指定过期时间内使用本地缓存;pragma防止页面被缓存。
2)cookie/login头域,P3P用于跨域设置cookie;set-cookie用于把cookie发送到客户端浏览器。
3)entity头域,etag和if-none-match配合使用;last-modified用于指示资源的最后修改日期和时间;content-typeweb服务器告诉浏览器自己响应的对象的类型和字符集。。。
4)miscellaneous头域,server指明HTTP服务器的软件信息。。。
5)transport头域,connection和host。
6)location头域,用于重定向一个新的位置,包含新的URL地址。
响应报文的状态码:当客户端发起一次HTTP请求后,服务器会返回一个包含HTTP状态码的信息头(server header)用于响应客户端的请求。response消息中的第一行叫做状态行,由HTTP协议版本号、状态码、状态消息三部分组成。
三、HTTPS协议
HTTPS(hyper transfer protocol over secure socket layer),是以安全为目标的HTTP通道。
传输原理:
1)客户端发起HTTPS请求,用户在浏览器里输入一个HTTPS网址链接到服务器端口。
2)服务器端初步响应,采用HTTPS协议的服务器必须有一套数字证书,这套证书就是一对公钥和私钥。将证书发回给客户端,证书包含证书的颁发机构、过期时间等。
3)客户端解析证书,客户端首选会验证证书是否有效,若出现异常则提示证书有问题,若没有问题,客户端就随机生成一个值,然后用证书对该随机值进行加密。
4)客户端发送加密信息客户端发送的是用证书加密之后的公钥。
5)服务器解密信息,服务器端用公钥解密之后,得到了客户端传来的公钥,然后把内容通过该值进行对称加密。
6)服务器发送加密后的信息,服务器发送用公钥进行加密后的信息。
7)客户端解密信息,客户端用之前生成的私钥解密服务器端传过来的信息,客户端就获取了解密后的内容。

很多情况下,测试人员过多的依赖于工具去完成测试工作。工具虽然能够简化我们的工作,但是却不利于测试人员的成长。测试人员应该摆脱对工具的依赖,从原理上去理解技术的本质,才能真正的懂得测试,提升自己的测试能力。