虚拟机: VMware ESXi
操作系统:CentOS Linux release 7.5
# 固定静态IP
[root@JMS ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="2a047fc4-4910-4773-8f50-e9211cd158f0"
DEVICE="ens33"
ONBOOT="yes"
IPADDR=192.168.xx.xx
NETMASK=255.255.255.0
GATEWAY=192.168.2.1
DNS1=223.5.5.5
DNS2=8.8.8.8
# 重启network服务
service network restart
hostnamectl set-hostname k8s-master
hostnamectl set-hostname k8s-slave1
hostnamectl set-hostname k8s-slave2
cat >> /etc/hosts << EOF
192.168.2.161 k8s-master
192.168.2.162 k8s-slave1
192.168.2.163 k8s-slave2
EOF
配置master1到node1无密码登陆
在master上操作
ssh-keygen -t rsa
#一直回车就可以
cd /root && ssh-copy-id -i .ssh/id_rsa.pub root@k8s-slave1
cd /root && ssh-copy-id -i .ssh/id_rsa.pub root@k8s-slave2
#上面需要输入yes之后,输入密码,输入node1物理机密码即可
#安装基础软件包,各个节点操作
yum -y install wget net-tools nfs-utils lrzsz gcc gcc-c++make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntplibaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-serversocat ipvsadm conntrack ntpdate
systemctl stop firewalld && systemctl disable firewalld
yum install iptables-services -y
service iptables stop && systemctl disable iptables
# 时间同步
ntpdate cn.pool.ntp.org
1)crontab -e
* */1 * * * /usr/sbin/ntpdate cn.pool.ntp.org
2)重启crond服务:
service crond restart
# 设置永久关闭selinux,各个节点操作
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
# 永久禁用,打开/etc/fstab注释掉swap那一行。
swapoff -a
sed -i 's/.*swap.*/#&/' /etc/fstab
# 修改内核参数,各个节点操作
cat <
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
reboot -f
设置网桥包经IPTables,core文件生成路径,配置永久生效
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
echo 1 >/proc/sys/net/bridge/bridge-nf-call-ip6tables
echo """
vm.swappiness = 0
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
""" > /etc/sysctl.conf
sysctl -p
开启ipvs,不开启ipvs将会使用iptables,但是效率低,所以官网推荐需要开通ipvs内核
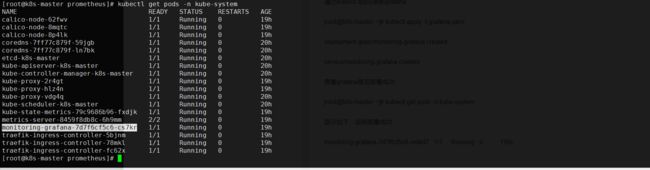
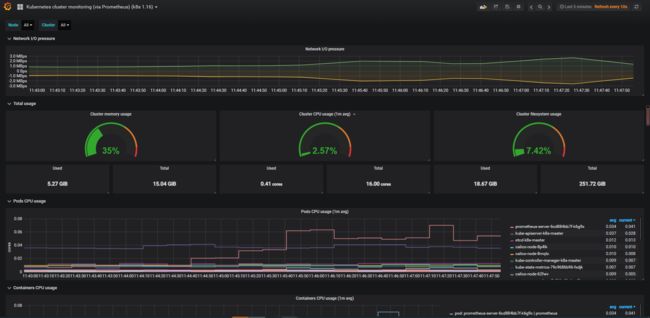
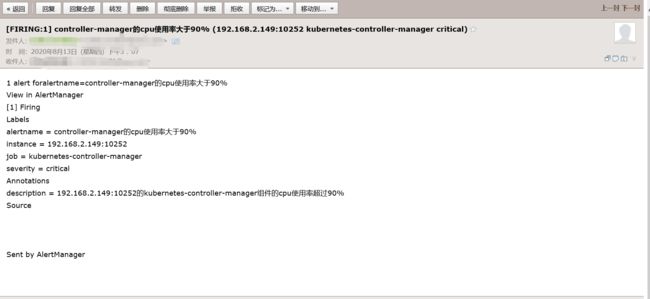
cat > /etc/sysconfig/modules/ipvs.modules < #!/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rrip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sedip_vs_ftp nf_conntrack" for kernel_module in \${ipvs_modules}; do /sbin/modinfo -Ffilename \${kernel_module} > /dev/null 2>&1 if [ $? -eq 0 ];then /sbin/modprobe\${kernel_module} fi done EOF chmod 755 /etc/sysconfig/modules/ipvs.modules &&bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep ip_vs ===========================================安装docker=============================================== sudo yum update 官方脚本安装:curl -sSL https://get.docker.com/ | sh 或者:sudo yum -y install docker-ce-19.03.13 或者 docker run hello-world docker version # 修改成如下内容 vim /usr/lib/systemd/system/docker.service ExecStart=/usr/bin/dockerd --exec-opt native.cgroupdriver=systemd # 新增docker源加速 cat /etc/docker/daemon.json { "storage-driver": "overlay2", "insecure-registries": ["registry.access.redhat.com","quay.io","192.168.2.110:5000"], "registry-mirrors": ["https://registry.docker-cn.com","http://hub-mirror.c.163.com","https://0qswmwvl.mirror.aliyuncs.com"] } systemctl daemon-reload && systemctl restart docker && systemctl status docker =======================================安装kubernetes===================================================== cat > /etc/yum.repos.d/kubernetes.repo << EOF [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum install -y kubelet kubeadm kubectl # 跳过密钥安装如下 yum install kubectl-1.18.2-0.x86_64 --nogpgcheck yum install kubelet-1.18.2-0.x86_64 --nogpgcheck yum install kubeadm-1.18.2-0.x86_64 --nogpgcheck systemctl enable kubelet kubelet --version docker load -i 1-18-kube-apiserver.tar.gz && docker load -i 1-18-kube-scheduler.tar.gz && docker load -i 1-18-kube-controller-manager.tar.gz && docker load -i 1-18-pause.tar.gz && docker load -i 1-18-cordns.tar.gz && docker load -i 1-18-etcd.tar.gz && docker load -i 1-18-kube-proxy.tar.gz && docker load -i cni.tar.gz && docker load -i calico-node.tar.gz && docker load -i traefik_1_7_9.tar.gz && docker load -i dashboard_2_0_0.tar.gz && docker load -i metrics-scrapter-1-0-1.tar.gz && docker load -i metrics-server-amd64_0_3_1.tar.gz && docker load -i addon.tar.gz echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile source ~/.bash_profile 初始化 kubeadm init \ --apiserver-advertise-address=192.168.2.161 \ --image-repository registry.aliyuncs.com/google_containers \ --kubernetes-version v1.18.2 \ --service-cidr=10.1.0.0/16 \ --pod-network-cidr=10.244.0.0/16 mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config ###注释:这个目录可以拷贝到其它节点然后它们也可以使用kubectl命令 kubectl get nodes kubectl apply -f calico.yaml #只需要在master创建一次即可 kubectl get nodes 复制到node1 node2 节点执行: kubeadm join 192.168.2.161:6443 --token 574y6z.9235pj93va9o8ed3 \ --discovery-token-ca-cert-hash sha256:93205aa49e2b587c429f9d11e2b7d546000072abcd943d98e1eff32df505a988 生成traefik证书,在master1上操作 mkdir ~/ikube/tls/ -p echo """ [req] distinguished_name = req_distinguished_name prompt = yes [ req_distinguished_name ] countryName = Country Name (2 letter code) countryName_value = CN stateOrProvinceName = State orProvince Name (full name) stateOrProvinceName_value = Beijing localityName = Locality Name (eg, city) localityName_value =Haidian organizationName =Organization Name (eg, company) organizationName_value = Channelsoft organizationalUnitName = OrganizationalUnit Name (eg, section) organizationalUnitName_value = R & D Department commonName = Common Name (eg, your name or your server\'s hostname) commonName_value =*.multi.io emailAddress = Email Address emailAddress_value [email protected] """ > ~/ikube/tls/openssl.cnf openssl req -newkey rsa:4096 -nodes -config ~/ikube/tls/openssl.cnf -days3650 -x509 -out ~/ikube/tls/tls.crt -keyout ~/ikube/tls/tls.key kubectl create -n kube-system secret tls ssl --cert ~/ikube/tls/tls.crt--key ~/ikube/tls/tls.key kubectl apply -f traefik.yaml #只需要在master创建一次即可 kubectl get pods -n kube-system kubectl apply -f kubernetes-dashboard.yaml #只需要在master创建一次即可 kubectl get pods -n kubernetes-dashboard kubectl get svc -n kubernetes-dashboard 修改service type类型变成NodePort: kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard 把type: ClusterIP变成 type: NodePort,保存退出即可。 # 查看端口 我的是30471 kubectl get svc -n kubernetes-dashboard kubectl get secret -n kubernetes-dashboard # 查看token 值 复制登录 kubectl describe secret kubernetes-dashboard-token-5mwhr -n kubernetes-dashboard # 创建admin管理员权限 kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard kubectl apply -f metrics.yaml # 登录浏览器 https://192.168.2.161:30471/#/overview?namespace=_all =======================================Prometheus+Grafana+Alertmanager========================================== k8s集群中部署prometheus 1.创建namespace、sa账号,在k8s集群的master节点操作 创建一个monitor-sa的名称空间 kubectl create ns monitor-sa 创建一个sa账号 [root@k8s-master ~]# kubectl create serviceaccount monitor -n monitor-sa serviceaccount/monitor created 把sa账号monitor通过clusterrolebing绑定到clusterrole上 [root@k8s-master ~]# kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor clusterrolebinding.rbac.authorization.k8s.io/monitor-clusterrolebinding created 2.创建数据目录 在k8s集群的任何一个node节点操作,这里我选择在k8s-node1上操作如下命令: [root@k8s-node1 ~]# mkdir /data [root@k8s-node1 ~]# chmod 777 /data/ 3.安装prometheus,以下步骤均在在k8s集群的k8s-master1节点操作 1)创建一个configmap存储卷,用来存放prometheus配置信息 cat >prometheus-cfg.yaml < --- kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sa data: prometheus.yml: | global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/s ecrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name EOF 注意:通过上面命令生成的promtheus-cfg.yaml文件会有一些问题,$1和$2这种变量在文件里没有,需要在k8s的k8s-master1节点打开promtheus-cfg.yaml文件,手动把$1和$2这种变量写进文件里,promtheus-cfg.yaml文件需要手动修改部分如下: 22行的replacement: ':9100'变成replacement: '${1}:9100' 42行的replacement: /api/v1/nodes//proxy/metrics/cadvisor变成 replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor 73行的replacement: 变成replacement: $1:$2 通过kubectl apply更新configmap kubectl apply -f prometheus-cfg.yaml 2)通过deployment部署prometheus cat >prometheus-deploy.yaml < --- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: monitor-sa labels: app: prometheus spec: replicas: 1 selector: matchLabels: app: prometheus component: server #matchExpressions: #- {key: app, operator: In, values: [prometheus]} #- {key: component, operator: In, values: [server]} template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: nodeName: k8s-node1 serviceAccountName: monitor containers: - name: prometheus image: prom/prometheus:v2.2.1 imagePullPolicy: IfNotPresent command: - prometheus - --config.file=/etc/prometheus/prometheus.yml - --storage.tsdb.path=/prometheus - --storage.tsdb.retention=720h ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus/prometheus.yml name: prometheus-config subPath: prometheus.yml - mountPath: /prometheus/ name: prometheus-storage-volume volumes: - name: prometheus-config configMap: name: prometheus-config items: - key: prometheus.yml path: prometheus.yml mode: 0644 - name: prometheus-storage-volume hostPath: path: /data type: Directory EOF 注意:在上面的prometheus-deploy.yaml文件有个nodeName字段,这个就是用来指定创建的这个prometheus的pod调度到哪个节点上,根据我们实际的节点名字来修改,我的节点名字为:k8s-node1,所以我们这里让nodeName=k8s-node1,也即是让pod调度到k8s-node1节点上,因为k8s-node1节点我们创建了数据目录/data,所以大家记住:你在k8s集群的哪个节点创建/data,就让pod调度到哪个节点。 通过kubectl apply更新prometheus kubectl apply -f prometheus-deploy.yaml 查看prometheus是否部署成功 kubectl get pods -n monitor-sa 显示如下,可看到pod状态是running,说明prometheus部署成功 kubectl get pods -n monitor-sa 3.给prometheus pod创建一个service cat > prometheus-svc.yaml << EOF --- apiVersion: v1 kind: Service metadata: name: prometheus namespace: monitor-sa labels: app: prometheus spec: type: NodePort ports: - port: 9090 targetPort: 9090 protocol: TCP selector: app: prometheus component: server EOF 通过kubectl apply更新service kubectl apply -f prometheus-svc.yaml 查看service在物理机映射的端口 kubectl get svc -n monitor-sa 显示如下: 通过上面可以看到service在宿主机上映射的端口是32639,这样我们访问k8s集群的k8s-master1节点的ip:32639,就可以访问到prometheus的WebUI界面了 访问Prometheus WebUI界面 浏览器输入如下k8s-master的地址:http://192.168.2.161:31285/ 可看到如下页面: prometheus热更新 为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus 就可以使配置生效,如修改prometheus-cfg.yaml,想要使配置生效可用如下热加载命令: [root@k8s-master ~]# curl -X POST http://10.244.1.70:9090/-/reload Lifecycle APIs are not enabled[ 10.244.1.70是prometheus的pod的IP地址 如何查看prometheus的pod的IP,可用如下命令: kubectl get pods -n monitor-sa -o wide | grep prometheus 显示如下,10.244.1.5就是prometheus的ip 热加载速度比较慢,可以暴力重启prometheus,如修改上面的prometheus-cfg.yaml文件之后,可执行如下强制删除: kubectl delete -f prometheus-cfg.yaml kubectl delete -f prometheus-deploy.yaml 然后再通过apply更新: kubectl apply -f prometheus-cfg.yaml kubectl apply -f prometheus-deploy.yaml 注意:线上最好热加载,暴力删除可能造成监控数据的丢失 Grafana安装和配置 上传包镜像到k8s的各个master节点和k8s的各个node节点 这里采用将包传到k8s-master节点,然后通过脚本传到各节点并导入镜像 vim /root/scp_heapster-grafana_load_image.sh scp heapster-grafana-amd64_v5_0_4.tar.gz k8s-node1:/root scp heapster-grafana-amd64_v5_0_4.tar.gz k8s-node2:/root docker load -i heapster-grafana-amd64_v5_0_4.tar.gz ssh k8s-node1 docker load -i heapster-grafana-amd64_v5_0_4.tar.gz ssh k8s-node2 docker load -i heapster-grafana-amd64_v5_0_4.tar.gz 赋值脚本权限并执行 chmod +x /root/scp_heapster-grafana_load_image.sh && sh /root/scp_heapster-grafana_load_image.sh 在k8s的k8s-master节点创建grafana.yaml cat >grafana.yaml << EOF apiVersion: apps/v1 kind: Deployment metadata: name: monitoring-grafana namespace: kube-system spec: replicas: 1 selector: matchLabels: task: monitoring k8s-app: grafana template: metadata: labels: task: monitoring k8s-app: grafana spec: containers: - name: grafana image: k8s.gcr.io/heapster-grafana-amd64:v5.0.4 ports: - containerPort: 3000 protocol: TCP volumeMounts: - mountPath: /etc/ssl/certs name: ca-certificates readOnly: true - mountPath: /var name: grafana-storage env: - name: INFLUXDB_HOST value: monitoring-influxdb - name: GF_SERVER_HTTP_PORT value: "3000" # The following env variables are required to make Grafana accessible via # the kubernetes api-server proxy. On production clusters, we recommend # removing these env variables, setup auth for grafana, and expose the grafana # service using a LoadBalancer or a public IP. - name: GF_AUTH_BASIC_ENABLED value: "false" - name: GF_AUTH_ANONYMOUS_ENABLED value: "true" - name: GF_AUTH_ANONYMOUS_ORG_ROLE value: Admin - name: GF_SERVER_ROOT_URL # If you're only using the API Server proxy, set this value instead: # value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy value: / volumes: - name: ca-certificates hostPath: path: /etc/ssl/certs - name: grafana-storage emptyDir: {} --- apiVersion: v1 kind: Service metadata: labels: # For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons) # If you are NOT using this as an addon, you should comment out this line. kubernetes.io/cluster-service: 'true' kubernetes.io/name: monitoring-grafana name: monitoring-grafana namespace: kube-system spec: # In a production setup, we recommend accessing Grafana through an external Loadbalancer # or through a public IP. # type: LoadBalancer # You could also use NodePort to expose the service at a randomly-generated port # type: NodePort ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana type: NodePort EOF 通过kubectl apply更新grafana [root@k8s-master ~]# kubectl apply -f grafana.yaml deployment.apps/monitoring-grafana created service/monitoring-grafana created 查看grafana是否部署成功 [root@k8s-master ~]# kubectl get pods -n kube-system 显示如下,说明部署成功 monitoring-grafana-7d7f6cf5c6-nmkd7 1/1 Running 0 110s 查看grafana的service [root@k8s-master ~]# kubectl get svc -n kube-system 显示如下: monitoring-grafana NodePort 10.100.202.134 上面可以看到grafana暴露的宿主机端口是30234 我们访问k8s集群的master节点ip:30234即可访问到grafana的web界面 Grafan界面接入prometheus数据源 1)登录grafana,在浏览器访问 http://IP:30234/ Name: Prometheus Type: Prometheus HTTP处的URL写如下: http://prometheus.monitor-sa.svc:9090 导入监控模板 模板文件导入后 下拉框 选择Name: Prometheus 安装配置kube-state-metrics组件 kube-state-metrics是什么? kube-state-metrics通过监听API Server生成有关资源对象的状态指标,比如Deployment、Node、Pod,需要注意的是kube-state-metrics只是简单的提供一个metrics数据,并不会存储这些指标数据,所以我们可以使用Prometheus来抓取这些数据然后存储,主要关注的是业务相关的一些元数据,比如Deployment、Pod、副本状态等;调度了多少个replicas?现在可用的有几个?多少个Pod是running/stopped/terminated状态?Pod重启了多少次?我有多少job在运行中。 安装kube-state-metrics组件 1)创建sa,并对sa授权 在k8s的k8s-master节点生成一个kube-state-metrics-rbac.yaml文件 cat > kube-state-metrics-rbac.yaml < --- apiVersion: v1 kind: ServiceAccount metadata: name: kube-state-metrics namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: kube-state-metrics rules: - apiGroups: [""] resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"] verbs: ["list", "watch"] - apiGroups: ["extensions"] resources: ["daemonsets", "deployments", "replicasets"] verbs: ["list", "watch"] - apiGroups: ["apps"] resources: ["statefulsets"] verbs: ["list", "watch"] - apiGroups: ["batch"] resources: ["cronjobs", "jobs"] verbs: ["list", "watch"] - apiGroups: ["autoscaling"] resources: ["horizontalpodautoscalers"] verbs: ["list", "watch"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kube-state-metrics roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kube-state-metrics subjects: - kind: ServiceAccount name: kube-state-metrics namespace: kube-system EOF 通过kubectl apply更新yaml文件 kubectl apply -f kube-state-metrics-rbac.yaml 2)安装kube-state-metrics组件 在k8s的k8s-master节点生成一个kube-state-metrics-deploy.yaml文件 cat > kube-state-metrics-deploy.yaml < apiVersion: apps/v1 kind: Deployment metadata: name: kube-state-metrics namespace: kube-system spec: replicas: 1 selector: matchLabels: app: kube-state-metrics template: metadata: labels: app: kube-state-metrics spec: serviceAccountName: kube-state-metrics containers: - name: kube-state-metrics # image: gcr.io/google_containers/kube-state-metrics-amd64:v1.3.1 image: quay.io/coreos/kube-state-metrics:v1.9.0 ports: - containerPort: 8080 EOF 通过kubectl apply更新yaml文件 kubectl apply -f kube-state-metrics-deploy.yaml 查看kube-state-metrics是否部署成功 kubectl get pods -n kube-system 显示如下,看到pod处于running状态,说明部署成功 kube-state-metrics-79c9686b96-lgbfz 1/1 Running 0 3m11s 3)创建service在k8s的k8s-master节点生成一个kube-state-metrics-svc.yaml文件 cat >kube-state-metrics-svc.yaml < apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: 'true' name: kube-state-metrics namespace: kube-system labels: app: kube-state-metrics spec: ports: - name: kube-state-metrics port: 8080 protocol: TCP selector: app: kube-state-metrics EOF 通过kubectl apply更新yaml kubectl apply -f kube-state-metrics-svc.yaml 查看service是否创建成功 kubectl get svc -n kube-system | grep kube-state-metrics 显示如下,说明创建成功 kube-state-metrics ClusterIP 10.109.205.230 安装和配置Alertmanager-发送报警到qq邮箱 在k8s的k8s-master节点创建alertmanager-cm.yaml文件 cat >alertmanager-cm.yaml < kind: ConfigMap apiVersion: v1 metadata: name: alertmanager namespace: monitor-sa data: alertmanager.yml: |- global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' smtp_from: '[email protected]' smtp_auth_username: '123456789' smtp_auth_password: 'XXXXXX' smtp_require_tls: false route: group_by: [alertname] group_wait: 10s group_interval: 10s repeat_interval: 10m receiver: default-receiver receivers: - name: 'default-receiver' email_configs: - to: '[email protected]' send_resolved: true EOF 通过kubectl apply更新文件 kubectl apply -f alertmanager-cm.yaml alertmanager配置文件解释说明: #用于发送邮件的邮箱的SMTP服务器地址+端口 smtp_smarthost: 'smtp.163.com:25' smtp_smarthost: 'smtp.qq.com:465' #这是指定从哪个邮箱发送报警 smtp_from: '[email protected]' #这是发送邮箱的认证用户,不是邮箱名 smtp_auth_username: '1228848273' #这是发送邮箱的授权码而不是登录密码 smtp_auth_password: 'rpxxxxxxxjcib' #to后面指定发送到哪个邮箱,我发送到我的qq邮箱,大家需要写自己的邮箱地址,不应该跟smtp_from的邮箱名字重复 email_configs: - to: '[email protected]' 在k8s的k8s-master节点重新生成一个prometheus-cfg.yaml文件 cat prometheus-cfg.yaml kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: monitor-sa data: prometheus.yml: |- rule_files: - /etc/prometheus/rules.yml alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: kubernetes-pods kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: true source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_scrape - action: replace regex: (.+) source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 source_labels: - __address__ - __meta_kubernetes_pod_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: kubernetes_pod_name - job_name: 'kubernetes-schedule' scrape_interval: 5s static_configs: - targets: ['192.168.2.161:10251'] - job_name: 'kubernetes-controller-manager' scrape_interval: 5s static_configs: - targets: ['192.168.2.161:10252'] - job_name: 'kubernetes-kube-proxy' scrape_interval: 5s static_configs: - targets: ['192.168.2.161:10249','192.168.2.114:10249','192.168.2.115:10249'] - job_name: 'kubernetes-etcd' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key scrape_interval: 5s static_configs: - targets: ['192.168.2.161:2379'] rules.yml: | groups: - name: example rules: - alert: kube-proxy的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: kube-proxy的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-kube-proxy"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: scheduler的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: scheduler的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-schedule"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: controller-manager的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: controller-manager的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-controller-manager"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: apiserver的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: apiserver的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: etcd的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: etcd的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: kube-state-metrics的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: coredns的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: coredns的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: kube-proxy打开句柄数>600 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kube-proxy打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>600 expr: process_open_fds{job=~"kubernetes-schedule"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-schedule"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>600 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>600 expr: process_open_fds{job=~"kubernetes-apiserver"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>600 expr: process_open_fds{job=~"kubernetes-etcd"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-etcd"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 600 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 1000 for: 2s labels: severity: critical annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000" value: "{{ $value }}" - alert: kube-proxy expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: scheduler expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-controller-manager expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-apiserver expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-etcd expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kube-dns expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: HttpRequestsAvg expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000" value: "{{ $value }}" threshold: "1000" - alert: Pod_restarts expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0 for: 2s labels: severity: warnning annotations: description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的" value: "{{ $value }}" threshold: "0" - alert: Pod_waiting expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中" value: "{{ $value }}" threshold: "1" - alert: Pod_terminated expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除" value: "{{ $value }}" threshold: "1" - alert: Etcd_leader expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader" value: "{{ $value }}" threshold: "0" - alert: Etcd_leader_changes expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变" value: "{{ $value }}" threshold: "0" - alert: Etcd_failed expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败" value: "{{ $value }}" threshold: "0" - alert: Etcd_db_total_size expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G" value: "{{ $value }}" threshold: "10G" - alert: Endpoint_ready expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用" value: "{{ $value }}" threshold: "1" - name:物理节点状态-监控告警 rules: - alert:物理节点cpu使用率 expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90 for: 2s labels: severity: ccritical annotations: summary: "{{ $labels.instance }}cpu使用率过高" description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert:物理节点内存使用率 expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}内存使用率过高" description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: InstanceDown expr: up == 0 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}:服务器宕机" description: "{{ $labels.instance }}:服务器延时超过2分钟" - alert:物理节点磁盘的IO性能 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}}流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }}流入磁盘IO大于60%(目前使用:{{$value}})" - alert:入网流量带宽 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}}流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert:出网流量带宽 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}}流出网络带宽过高!" description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)" - alert:磁盘容量 expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}}磁盘分区使用率过高!" description: "{{$labels.mountpoint }}磁盘分区使用大于80%(目前使用:{{$value}}%)" 注意: 通过上面命令生成的promtheus-cfg.yaml文件会有一些问题,$1和$2这种变量在文件里没有,需要在k8s的k8s-master节点打开promtheus-cfg.yaml文件,手动把$1和$2这种变量写进文件里,promtheus-cfg.yaml文件需要手动修改部分如下: 27行的replacement: ':9100'变成replacement: '${1}:9100' 47行的replacement: /api/v1/nodes//proxy/metrics/cadvisor变成 replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor 78行的replacement:变成replacement: $1:$2 102行的replacement:变成replacement: $1:$2 通过kubectl apply更新文件 kubectl apply -f prometheus-cfg.yaml 在k8s的k8s-master节点重新生成一个prometheus-deploy.yaml文件 cat >prometheus-deploy.yaml < --- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: monitor-sa labels: app: prometheus spec: replicas: 1 selector: matchLabels: app: prometheus component: server #matchExpressions: #- {key: app, operator: In, values: [prometheus]} #- {key: component, operator: In, values: [server]} template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: nodeName: k8s-node1 serviceAccountName: monitor containers: - name: prometheus image: prom/prometheus:v2.2.1 imagePullPolicy: IfNotPresent command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-lifecycle" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus name: prometheus-config - mountPath: /prometheus/ name: prometheus-storage-volume - name: k8s-certs mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ - name: alertmanager image: prom/alertmanager:v0.14.0 imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/alertmanager.yml" - "--log.level=debug" ports: - containerPort: 9093 protocol: TCP name: alertmanager volumeMounts: - name: alertmanager-config mountPath: /etc/alertmanager - name: alertmanager-storage mountPath: /alertmanager - name: localtime mountPath: /etc/localtime volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /data type: Directory - name: k8s-certs secret: secretName: etcd-certs - name: alertmanager-config configMap: name: alertmanager - name: alertmanager-storage hostPath: path: /data/alertmanager type: DirectoryOrCreate - name: localtime hostPath: path: /usr/share/zoneinfo/Asia/Shanghai EOF 生成一个etcd-certs,这个在部署prometheus需要 kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt 通过kubectl apply更新yaml文件 kubectl apply -f prometheus-deploy.yaml 查看prometheus是否部署成功 kubectl get pods -n monitor-sa | grep prometheus 显示如下,可看到pod状态是running,说明prometheus部署成功 NAME READY STATUS RESTARTS AGE prometheus-server-5465fb85df-jsqrq 2/2 Running 0 33s 在k8s的k8s-master节点重新生成一个alertmanager-svc.yaml文件 cat >alertmanager-svc.yaml < --- apiVersion: v1 kind: Service metadata: labels: name: prometheus kubernetes.io/cluster-service: 'true' name: alertmanager namespace: monitor-sa spec: ports: - name: alertmanager nodePort: 30066 port: 9093 protocol: TCP targetPort: 9093 selector: app: prometheus sessionAffinity: None type: NodePort EOF 通过kubectl apply更新yaml文件 kubectl apply -f prometheus-svc.yaml 查看service在物理机映射的端口 kubectl get svc -n monitor-sa 显示如下: NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE alertmanager NodePort 10.101.168.161 prometheus NodePort 10.104.39.13 注意:上面可以看到prometheus的service暴漏的端口是31043,alertmanager的service暴露的端口是30066 访问prometheus的web界面 点击status->targets,可看到如下 资源包分享路径: k8s-tools-all.tar.gz 链接:https://pan.baidu.com/s/1w8YPnAksaxKCasa2j0he4g 提取码:xeo6 参考微信公众号如下: https://mp.weixin.qq.com/s/I1-xfxuny_S8DHchkXHSpQ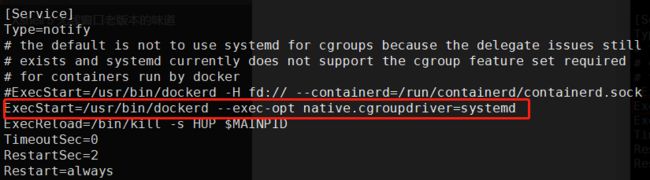
![]()




![]()