python读取excel中图片,并格式化输出
读取excel中的图片并格式化输出,发现网上并没有python的解决方案,
都是解压遍历图片,并不能满足需求,因此有了下面的方案
该代码支持格式化输出excel图片文本,并可以指定图片输出方式,(图片路径 / 图片base64编码)
步骤
- 复制并修改excel文件后缀为zip 格式
- 解压zip文件
- 遍历/xl/media 下图片,获取路径,base64等信息
- 解析 /xl/drawings/ 下 xml文件,获取图片在表格中的位置
- 处理表格,并格式化输出excel文本及图片等信息
待处理excel表格
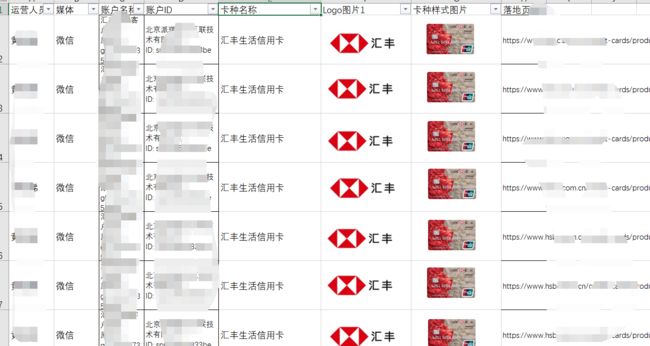
img1.png
处理后结果
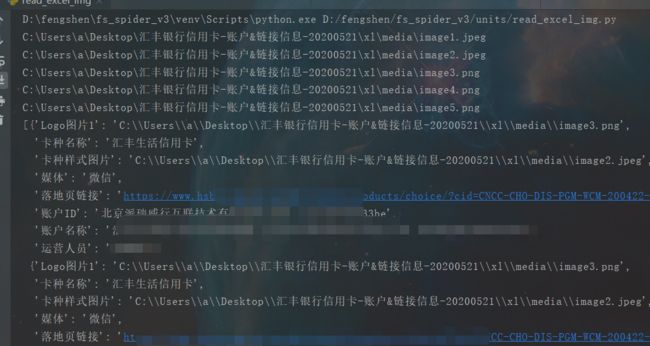
2.png
代码
# -*- coding: utf-8 -*-
"""
Project: spider
Creator: zhangx
Create time: 2020-05-23 15:23
Introduction: 读取含有图片的excel文件, 并按照 字典返回,文本、图片信息
复制excel 并重命名为zip 文件,解压zip 文件,图片在 /xl/media 文件夹下,遍历该文件夹获得图片路径,
图片在excel表格的位置信息保存在,/xl/drawings的文件夹下,根据工作簿的索引保存
解析xml文件,根据 行列获取位置,图片索引根据 rId 属性值,如rId2 == image2
可以更进一步,优化:
1, 可以将重命名解压,等操作在内存中进行, 这样可以免去每次都要生成zip 文件,及解压包
2, 如果不在内存中解压,应当每次运行后删除,zip文件,及解压包
3, 如果多个工作簿中含有图片, 可以/xl/drawings/drawing2.xml 及增加通过sheet索引读取图片位置信息
"""
import base64
import re
import xml.dom.minidom as xmldom
import os
import zipfile
import shutil
import xlrd
# 判断是否是文件和判断文件是否存在
def isfile_exist(file_path):
if not os.path.isfile(file_path):
print("It's not a file or no such file exist ! %s" % file_path)
return False
else:
return True
# 复制并修改指定目录下的文件类型名,将excel后缀名修改为.zip
def copy_change_file_name(file_path, new_type='.zip'):
if not isfile_exist(file_path):
return ''
extend = os.path.splitext(file_path)[1] # 获取文件拓展名
if extend != '.xlsx' and extend != '.xls':
print("It's not a excel file! %s" % file_path)
return False
file_name = os.path.basename(file_path) # 获取文件名
new_name = str(file_name.split('.')[0]) + new_type # 新的文件名,命名为:xxx.zip
dir_path = os.path.dirname(file_path) # 获取文件所在目录
new_path = os.path.join(dir_path, new_name) # 新的文件路径
if os.path.exists(new_path):
os.remove(new_path)
shutil.copyfile(file_path, new_path)
return new_path # 返回新的文件路径,压缩包
# 解压文件
def unzip_file(zipfile_path):
if not isfile_exist(zipfile_path):
return False
if os.path.splitext(zipfile_path)[1] != '.zip':
print("It's not a zip file! %s" % zipfile_path)
return False
file_zip = zipfile.ZipFile(zipfile_path, 'r')
file_name = os.path.basename(zipfile_path) # 获取文件名
zipdir = os.path.join(os.path.dirname(zipfile_path), str(file_name.split('.')[0])) # 获取文件所在目录
for files in file_zip.namelist():
file_zip.extract(files, os.path.join(zipfile_path, zipdir)) # 解压到指定文件目录
file_zip.close()
return True
# 读取解压后的文件夹,打印图片路径
def read_img(zipfile_path):
img_dict = dict()
if not isfile_exist(zipfile_path):
return False
dir_path = os.path.dirname(zipfile_path) # 获取文件所在目录
file_name = os.path.basename(zipfile_path) # 获取文件名
pic_dir = 'xl' + os.sep + 'media' # excel变成压缩包后,再解压,图片在media目录
pic_path = os.path.join(dir_path, str(file_name.split('.')[0]), pic_dir)
file_list = os.listdir(pic_path)
for file in file_list:
filepath = os.path.join(pic_path, file)
print(filepath)
img_index = int(re.findall(r'image(\d+)\.', filepath)[0])
img_base64 = get_img_base64(img_path=filepath)
img_dict[img_index] = dict(img_index=img_index, img_path=filepath, img_base64=img_base64)
return img_dict
# 获取img_base64
def get_img_base64(img_path):
if not isfile_exist(img_path):
return ""
with open(img_path, 'rb') as f:
base64_data = base64.b64encode(f.read())
s = base64_data.decode()
return 'data:image/jpeg;base64,%s' % s
def get_img_pos_info(zip_file_path, img_dict, img_feature):
"""解析xml 文件,获取图片在excel表格中的索引位置信息"""
os.path.dirname(zip_file_path)
dir_path = os.path.dirname(zip_file_path) # 获取文件所在目录
file_name = os.path.basename(zip_file_path) # 获取文件名
xml_dir = 'xl' + os.sep + 'drawings' + os.sep + 'drawing1.xml'
xml_path = os.path.join(dir_path, str(file_name.split('.')[0]), xml_dir)
image_info_dict = parse_xml(xml_path, img_dict, img_feature=img_feature) # 解析xml 文件, 返回图片索引位置信息
return image_info_dict
# 重命名解压获取图片位置,及图片表格索引信息
def get_img_info(excel_file_path, img_feature):
if img_feature not in ["img_index", "img_path", "img_base64"]:
raise Exception('图片返回参数错误, ["img_index", "img_path", "img_base64"]')
zip_file_path = copy_change_file_name(excel_file_path)
if zip_file_path != '':
if unzip_file(zip_file_path):
img_dict = read_img(zip_file_path) # 获取图片,返回字典,图片 img_index, img_index, img_path, img_base64
image_info_dict = get_img_pos_info(zip_file_path, img_dict, img_feature)
return image_info_dict
return dict()
# 解析xml文件并获取对应图片位置
def parse_xml(file_name, img_dict, img_feature='img_path'):
# 得到文档对象
image_info = dict()
dom_obj = xmldom.parse(file_name)
# 得到元素对象
element = dom_obj.documentElement
def _f(subElementObj):
for anchor in subElementObj:
xdr_from = anchor.getElementsByTagName('xdr:from')[0]
col = xdr_from.childNodes[0].firstChild.data # 获取标签间的数据
row = xdr_from.childNodes[2].firstChild.data
embed = \
anchor.getElementsByTagName('xdr:pic')[0].getElementsByTagName('xdr:blipFill')[0].getElementsByTagName(
'a:blip')[0].getAttribute('r:embed') # 获取属性
image_info[(int(row), int(col))] = img_dict.get(int(embed.replace('rId', '')), {}).get(img_feature)
sub_twoCellAnchor = element.getElementsByTagName("xdr:twoCellAnchor")
sub_oneCellAnchor = element.getElementsByTagName("xdr:oneCellAnchor")
_f(sub_twoCellAnchor)
_f(sub_oneCellAnchor)
return image_info
def read_excel_info(file_path, img_col_index, img_feature='img_path'):
"""
读取包含图片的excel数据, 并返回列表
:param file_path:
:param img_col_index: 图片索引列,list
:param img_feature: 指定图片返回形式 img_index", "img_path", "img_base64"
:return:
"""
img_info_dict = get_img_info(file_path, img_feature)
book = xlrd.open_workbook(file_path)
sheet = book.sheet_by_index(0)
head = dict()
for i, v in enumerate(sheet.row(0)):
head[i] = v.value
info_list = []
for row_num in range(sheet.nrows):
d = dict()
for col_num in range(sheet.ncols):
if row_num ==0:
continue
if 'empty:' in sheet.cell(row_num, col_num).__str__():
if col_num in img_col_index:
d[head[col_num]] = img_info_dict.get((row_num, col_num))
else:
d[head[col_num]] = sheet.cell(row_num, col_num).value
else:
d[head[col_num]] = sheet.cell(row_num, col_num).value
if d:
info_list.append(d)
return info_list
if __name__ == '__main__':
i = read_excel_info(r'C:\Users\a\Desktop\汇丰银行信用卡-账户&链接信息-20200521.xlsx', img_col_index=[5, 6])
from pprint import pprint
pprint(i)