为什么使用nosql:
关系数据库的缺点:
1.无法处理每秒上万次的qps,优于关系数据库没有大量的io,硬盘io位性能瓶颈
2关系型数据库表字段有限,记录数量有限,最多256列,当表数据到达百万读写速度下降
3无法简单的通过增加硬件,服务节点来提高系统性能
nosql的优点:
1支持高并发,数据存于内存,读写性能高
2无需事先建立字段,随时存储自定义的数据格式,在关系型数据库中必须实现添加好字段
3.高可用,支持实现高可用架构,哨兵/集群cluster 等
4成本低开源基本不收费
nosql的缺点:
1.没有约束没有索引
2.没有标准的sql语句
3.数据之间无联系
redis的安装及下载
linux安装:
下载redis的压缩包(自行百度)并解压,因为redis是c编写的需要c的编译器,安装gcc,yum -y install gcc
到/root/redis/redis-3.2.9/src以下目录执行 make命令 编译c文件,至此安装完成
启动redis:到redis-3.2.9/src 下执行 ./redis-server &
关闭redis:到redis-3.2.9/src 下执行./redis-cli shutdown 可以直接输入也可以在client端直接关掉(处理逻辑是先拒绝请求把当前数据处理完关闭程序)
客户端链接
1.直接启动 ./redis-cli
2.指定所要链接的redis ./redis -cli -h 127.0.0.1 -p 6379
redis的基本命令
ping : 判断网络是否通
dbsize:查看当前数据库的key的数目
redis默认使用16个库,从0-15 对数据库的修改可以在redis-conf中的database 16
切换数据库:select db 选择第6个库 select 5
删除当前的数据库 flushdb
redis的key的操作命令
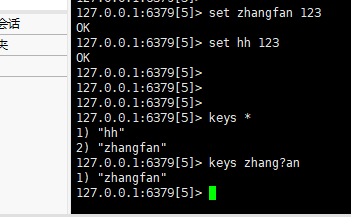
1.keys pattern 查找符合pattern的key值。partten可以使用通配符
如:keys *
如:keys zhang?an
2.exists: exists key【key】判断key是否存在,存在返回1,其他返回0,当使用多个key值时候,返回key的数量
3.expire :expire key seconds 设置key的生存时间秒 ,超过时间key自动删除,设置成功返回1其他情况返回0
4.ttl key:以s为单位查看key的剩余存活时间,
-1表示永不过期
-2表示不存在
其余数字以s为单位表示剩余时间
redis的五种数据类型:
String:存储字符串,包括二进制及序列化后的数据 最大存储512m
语法:set/get/incr(数字类型+1)/decr(数字类型-1)/append 在原来key基础上加value返回value长度,
strlin key:返回key 所存储的字符串的长度
getrange key start end: 截取字符串,返回截取的字符串
setrange key offset value:用value替换key的存储的值从offset开始,不存在的当空字符串处理
mset 同时设置多个key 同理 mget 同时取多个value
(简单语法没有截图,如果需要请留言)
hash:是一个string类型的field和value的映射表
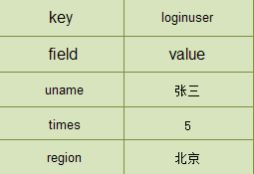
语法:hset/hget /hmset(存多个value)/hmget
hmget key field ... 指定多个field,空field返回null
hgetall key 返回所有的key的filed 及 value
hkeys:看所有的field列表
hvals key:返回hash表中所有域的值
hexists:查看给定的field是否存在,存在返回1不存在返回0
list:简单的字符串列表,按照插入顺序排序,可以从左从右添加

语法:lpush/rpush/lrange key start stop -1表示最后一个数字
lindex key index 获取key中下标为index的元素 lrang zhangfan(key) 0 4
llen key:获取列表key的长度
lrem key count value:根据count删除value的值,count>0从左侧删除counts数量的value,反之从右边,若count =0 删除所有value、
lset key index value,将第几位的值改为value的值
set(无序):是string类型的无序集合,集合成员是唯一的、
语句:sadd/smembers/scard key/srem key member(删除key中的一个或多个value)/
srandmember key {count}随机返回一个数据 有count返回count的数据、
spop key 【count】 删除一个随机元素,有count删除随机的count的值
zset:与set一样也是string的无序集合,且不允许重复的成员,不同点是每一个元素都关联一个分数,redis会根据分树进行排序
语法 zadd:zdd key score member 【。。。。。】
查询zrange -1 表示最后一个,其余的跟之前是一样的
zrevrange key start stop [withscores]:指定区间的score及value返回,按照score从高到底
zrem key member 【。。。。。。。。】:删除一个或者多个成员,不存在即被忽略
zrangebyscore key min max 【withscores】 【limit offset count】:获取有序集中所有的score介于min和满之间的
zount key min max :score值在【min及max】之间成员的数量
redis事务
redis的事务理解:保证事务的多条命令都能正常执行,没有回滚的概念
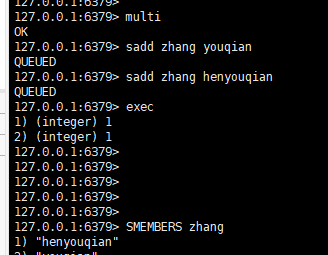
multi:标志一个事物的开始,将多条命令放到队列里进行缓存
exec:执行事务中的每条命令,相当于执行队列中的每条命令,如果事务被打断,返回nil
discard:取消事务的所有的命令
* 事务执行之前如果有命令执行错误(语法有错),无法执行此事务,整个事务被放弃
* 放入事务中的命令,语法没错但是执行时候出现错误,此时事务正常提交的并执行
Redis的watch机制
watch机制:监听一个或者多个key,如果key的value在exec执行之前被修改了,整个事务被取消,watch机制使得事务的exec变成有条件的,事务只有在被watch的key没有被修改的前提下才会执行
语法:watch key。。。。/unwatch key。。。。
redis的持久化
RDB:
在指定的时间间隔内将内存中的数据集以快照的形式存到磁盘中,需要数据恢复时直接将快照文件读取到内存中,存储的是一个二进制文件,默认是dump.rdb
rdb支持多个条件同时生效
AOF
每次接收到一条改变数据的命令时,他将命令写到一个aof文件中,当redis重启的时候,会通过执行aof中每一条命令来回复数据。
如何实现:


redis的主从复制
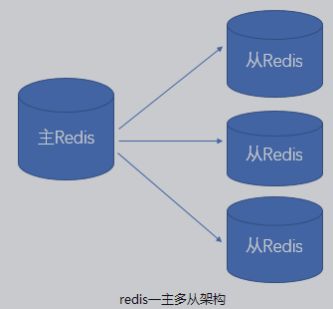
master用于写,slave只负责读,向slave写数据会报错
主从复制的主要流程(全量同步/增量同步):
全量同步:主要发生在slave初始化的阶段:slave会复制master上的所有的数据
1.slave > master 发送sync消息;
2.master收到sync消息执行bgsave生成RDB文件。因为是异步操作,期间收到的请求放入到缓冲区中
3.master执行完bgsave向salve发送快照
4.slave收到快照丢弃所有的旧数据,载入新的数据
5.salve接收完成后,读取缓冲区中的命令
什么是bgsave:bgsave有个兄弟是save,都是master执行生成快照的命令,区别在于,save会阻塞主主进程禁止其他访问,bgsave会fork一个子进程,去生成快照文件,os执行此方法时候会使用写时复制(copy - on - write)策略,即fork执行的时候父子进程是公用同一套内存,当父进程收到写命令的时候会复制一份出来,以保证子进程生成RDB文件不受影响,所有fork的时候是fork某一刻的内存数据。
在一台服务器上,修改配置文件可以模拟主从场景
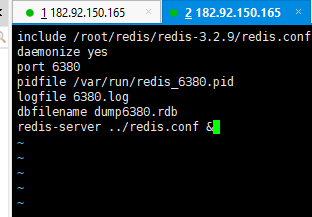
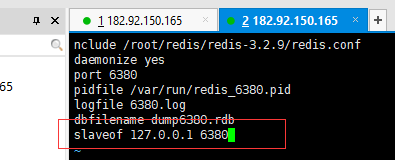
单机场景下的容灾处理
了解(线上不会让你自己去设置太low):如果master挂掉,就不能写入只能读取,选一个slave执行“slaveof no one ”将一个slave变成主服务器,将另一台slave重新挂载到新的master下 :slaveof 127.0.0.1 6381
Sentinel 哨兵模式
sentinel是一个sentine运行在特殊模式下的redis服务器
三个主要作用:
1.监控主从服务器是否正常进行
2.提醒被监控的redis出现问题,sentinel会通知其他程序
3.自动故障转移
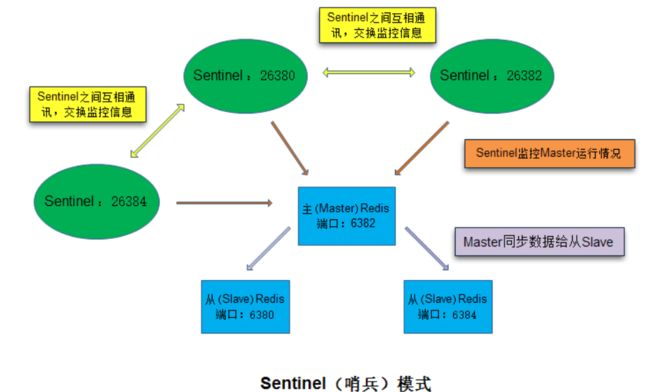
工作机制:
sentinel会检测master和slave是否正常,如果某个sentinel挂了,就无法实现监控所以哨兵一般要3个,当某一个sentinel认为被监控的服务下线以后,会向其他sentinel进行确认,判断是否是真的下线?(主管下线 => 客观下线),对slave重新升为新的master,当原来的master重新上线时候成为slave
Sentinel 集群模式
哨兵模式可以实现高可用,但是要支持高并发,存储海量数据还是不行,所以引入了redis集群
一个redis节点有多个node组成,而多个node之间通过cluster meet命令来实现。
节点间的握手过程:
节点A收到客户端的cluster meet命令。然后A收到ip和端口,向这个地址B节点发送一个消息,B回复一个pang,A收到以后回复一个ping,表名握手成功,最后,A节点通过gossip协议将B节点的信息同步给其他节点C,D,E等
槽slot:
redis通过集群分片的形式保存数据,存储单位是槽slot,一共有16384个,如果有3个节点的集群,那么每个集群都有5500左右的槽slot,添加/删除节点的方式是:如新增一个4节点,1-3会匀出一些分配给4各个节点的槽点基本保持一致
处理数据流程:通过slot = CRC16(key)& 16383 (CRC16算法),计算数据在那个槽solt上,然后进行数据处理
故障转移
A > B 节点会进行通信如果A节点认为B节点离线了(发ping消息在cluster_node_timeout时间内没有返回),会通知其他节点,其余节点如果都认为B节点离线(超过半数以上),则B节点真正的离线。
然后会进行类似于raft算法,该节点上的slave会生成master
重定向
因为client链接redis的时候可以链接任何一个节点。所以在cluster模式的情况下当cliet进行请求的时候主要流程:
1.检查当前的key是否存在当前节点(crc16)key / 16384
2.若不是该节点负责,返回moved重定向
3.该slot是否正在迁入或者迁出(迁入的solt有ASKING标记,直接进行操作,若为正在迁出solt则重定向客户端到迁移的目的服务器)
一些redis常被问道的问题:
https://www.jianshu.com/p/20f902aa35ff