
1 Eureka与ZooKeeper的区别?各自优缺点?
-
Zoopkeeper保证CP:
- ZooKeeper是分布式协调服务,核心算法是ZAB,它的职责是保证数据(配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致;所以被设计成CP而不是AP。
- zk的写操作都靠leader节点,leader节点挂了要先leader选举出新的leader才能对外写服务。
- 选举leader的时间可能很长,30~120s,且选举期间整个zk集群是都是不可用的。
-
Eureka保证AP:
- Eureka各个节点都是平等的,只要有一台Eureka还在,就能保证可用性,只不过查到的信息可能不是最新的(不保证一致性)。
- Eureka还有一种自我保护机制,如果在15分钟内超过85%的节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,此时会出现以下几种情况:
- Eureka不再从注册列表中移除因为长时间没有收到心跳而应该过期的服务
- Eureka仍然能够接受新服务的注册和查询请求,但是不会被同步到其它节点上(即保证当前节点依然可用)
- 当前网络稳定时,当前实例新的注册信息会被同步到其它节点中
-
ZooKeeper缺陷
- 保证CP,忽略A,leader选举过程中不能保证高可用
- 其实也是最终一致性
- leader选举速度慢,官方说的200ms内完成leader选举,通常需要30~120s
- ZooKeeper性能有限,典型的ZooKeeper的写操作TPS大概是一万多
- ZooKeeper客户端使用较复杂,没有针对服务发现的模型设计和API封装,需要调用方自己处理。
- 多语言支持不够友好
- 没有比较好用的控制台进行运维管理
-
Eureka缺陷
- 保证AP,舍弃C,节点间同步复制是基于http的,由于网络的不可靠性,可能会出现节点注册信息不同步的情况。
- 不支持事件通知机制
2 使用了springcloud什么组件?
- Eureka:服务治理组件。包含服务注册中心、服务注册与发现机制实现。
- Hystrix:容错管理组件。实现断路器等。
- Ribbon:客户端负载均衡组件。
- Feign:基于Ribbon和Hystrix的声明式服务调用组件。
- Zuul:服务网关组件。提供智能路由、访问过滤等功能。
- Apollo:携程,分布式配置中心
- Skywalking:分布式链路追踪
- Swagger:分布式文档管理
3 springcloud和springboot版本号多少?
- springcloud:Dalston.SR1
- springboot:1.5.9.RELEASE

4 服务注册与发现机制
- ZooKeeper
- 没有内置负载均衡器,需要调用者自己实现
- 写操作TPS一万,存储节点数可达到百万级别
- Eureka
- 负载均衡由Ribbon完成
- 服务注册实例达到5000就会出现服务不可用
- Consul
- 负载均衡由Fabio完成
- Nacos
- 一致性协议
- AP,Distro协议
- CP,Raft协议
- 负载均衡机制
- 基于健康检查和权重的负载均衡
- 基于CMDB的标签负载均衡器
- 健康检查机制
- 客户端上报,TTL机制
- 服务端检测
- Nacos开源版本支持服务实例注册100万,服务的数量10万以上。
- 一致性协议

5 服务治理怎么做?
- 阿里-Dubbo
- 当当-DubboX
- Netflix-Eureka
- Apache-Consul
6 服务网关怎么做?

服务网关功能
- 请求路由转发
- 协议/格式适配
- http、HTTPS
- xml、json
- 公共模块
- 业务隔离
- 安全校验/攻击
- 横切功能:日志、公共校验...
- 限流
- zuul限流由ratelimit实现
服务网关选型
- OpenResty,基于NGINX+lua
- kong,基于OpenResty,2015开源
- zuul,核心功能使用filter实现
- springcloud全家桶一部分,zuul1.x是同步IO
- zuul2.x是基于Netty的异步IO,开源不久,可用性较差
- Spring Cloud Gateway
- springcloud全家桶一部分,zuul1.x的升级版,基于异步IO
- 区分了Router和filter

服务网关性能
- 直连 > kong(直连的70%) > OpenResty(直连的60%) > zuul 约等于Spring Cloud Gateway(直连的40%)
7 链路追踪实现原理
7.1 链路追踪实现方案
- 谷歌的dapper
- 阿里的鹰眼
- 大众点评的CAT
- Twitter的zipkin
- naver(社交软件LINE的母公司)的pinpoint
- skywalking
- Spring Cloud Sleuth
7.2 链路追踪实现原理
- trace架构
- agent代理



8 微服务限流
8.1 合法性验证限流
- 验证码
- IP黑名单
8.2 容器限流
- Tomcat
- maxThreads,在conf/server.xml中设置,默认值为150(tomcat8.5)
- windows每个进程中最大线程数为2000,Linux每个进程中最大线程数为1000
- 每开启一个线程需要好用1MB的JVM内存空间用作线程栈,线程越多GC负担越重。
- Nginx
- 控制速率
- 精确控制:limit_req_zone,限制单位时间内(毫秒级)的请求数
- 模糊控制:limit_req_zone+burst ,限制单位时间内总访问次数
- 控制并发连接数:limit_conn_zone+limit_conn
- limit_conn perip 10,限制单个IP最多持有10个连接
- limit_conn perserver 100,限制服务器最大并发连接数是100
- 控制速率
8.3 服务端限流
-
时间窗口算法/计数器算法
- Redis的zset实现,key存储限流的ID,score存储请求的时间,每次请求来了后先清空之前时间窗口访问量,统计现在计数器是否超过最大允许访问量,超过了则执行限流操作;没超过也允许执行业务逻辑并在zset中添加一条有效的访问记录。
- 临界值问题可以结合滑动时间窗口解决。计数器是滑动窗口的低精度实现,滑动窗口每个格子都需要存储一份数据,如果精度越高,需要的存储空间就越大。
-
漏桶算法(leaky bucket)
- 漏桶算法解决了时间窗口算法限流不均匀的问题,使用队列保存请求。
- Nginx的控制速率就是漏桶算法
- Redis4.0提供了Redis-Cell模块支持分布式限流,提供原子指令限流,cl.throttle
-
令牌桶算法(token bucket)
- 令牌桶算法在漏桶算法基础上还允许一定程度的突发调用。
- 一定速率往桶中放令牌,每次请求调用先要获取令牌,只有拿到令牌才能才能继续执行,否则继续等待或放弃。
- Google的guava实现的令牌算法属于单机限流方案。
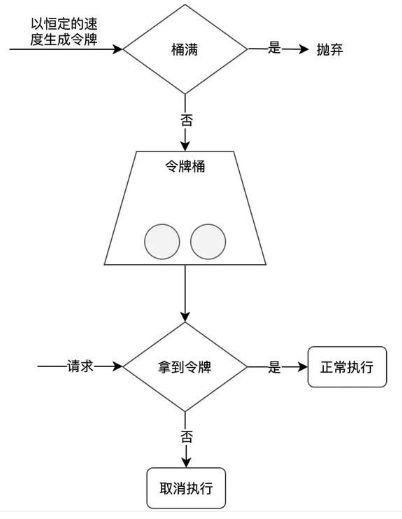
9 zuul网关限流
zuul网关限流实现原理
- zuul网关限流是由spring-cloud-zuul-ratelimit包实现的
zuul网关限流配置



-
zuul.ratelimit.repository 存储方式
- InMemoryRateLimiter - 使用 ConcurrentHashMap作为数据存储
- ConsulRateLimiter - 使用 Consul 作为数据存储
- RedisRateLimiter - 使用 Redis 作为数据存储
- SpringDataRateLimiter - 使用 数据库 作为数据存储
-
zuul.ratelimit.policies 限流策略
- limit:每个周期内请求次数
- quota:单位时间内允许访问的总时间
- refresh-interval:周期时间
- type:限流方式
- USER 根据用户,认证用户(Authenticated User),使用已认证的用户名或匿名
- ORIGIN 原始请求,原始请求(Request Origin),使用用户的原始请求
- URL 请求地址,使用上游请求的地址
- 不设置type,全局限流
zuul网关限流实现步骤
- pom.xml配置
org.springframework.boot
spring-boot-starter-data-redis
org.springframework.cloud
spring-cloud-starter-netflix-eureka-client
org.springframework.cloud
spring-cloud-starter-netflix-zuul
com.marcosbarbero.cloud
spring-cloud-zuul-ratelimit
2.0.0.RELEASE
- application.yml配置
spring:
application:
name: gateway-server #服务名称
cloud:
# 设置偏好网段
inetutils:
preferred-networks: 127.0.0.
loadbalancer:
retry:
enabled: true
jackson:
date-format: yyyy-MM-dd
joda-date-time-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
redis:
host: 127.0.0.1
port: 6379
timeout: 1000ms
database: 0
lettuce:
pool:
max-active: 8
max-wait: -1ms
max-idle: 8
min-idle: 0
zipkin:
enabled: true
base-url: http://zipkin-dashboard/
zuul:
routes:
user-service:
path: /user/**
serviceId: user-service
add-host-header: true
sensitive-headers: Access-Control-Allow-Origin,Access-Control-Allow-Methods
strip-prefix: true
ratelimit:
# 开启限流
enabled: true
# 存储方式
repository: REDIS
# 限流策略
policies:
# 指定限流服务
user-service:
# 每个周期内请求次数
limit: 3
# 单位时间内允许访问的总时间
quota: 30
# 周期时间
refresh-interval: 60
# 限流方式 USER 根据用户;ORIGIN 原始请求;URL 请求地址;
type: ORIGIN
server:
port: 9001 # 端口号
eureka:
client:
serviceUrl:
# 服务器注册/获取服务器的zone
defaultZone: http://127.0.0.1:9000/eureka/
healthcheck:
enabled: true
instance:
prefer-ip-address: true
10 服务熔断机制
10.1 微服务熔断实现方案
- hystrix
- Service Mesh
- lstio
- Linkerd
- Glasnostic
10.2 熔断器实现原理
- 熔断机制是应对微服务雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务不可用或响应时间太长时,会进行服务降级,进而熔断该节点微服务的调用,快速响应。
- springcloud是通过hystrix实现熔断机制,默认5s内20次调用失败就会启用熔断机制,熔断机制的注解是@HystrixCommand
10.3 Spring Cloud熔断机制
- 添加pom.xml依赖
org.springframework.cloud
spring-cloud-starter-netflix-hystrix
org.springframework.cloud
spring-cloud-starter-hystrix-dashboard
- 启动类注解开启熔断器@EnableCircuitBreaker
@EnableDiscoveryClient
@EnableCircuitBreaker
@SpringBootApplication
@EnableFeignClients(basePackageClasses = {PaymentClient.class})
@EnableScheduling
public class Goods {
public static void main(String[] args) {
SpringApplication.run(Goods.class, args);
}
}
- FeignClient开启hystrix
feign:
hystrix:
enabled: true
- 启动类开启hystrix监控@EnableHystrixDashboard
@EnableHystrixDashboard
@EnableDiscoveryClient
@EnableCircuitBreaker
@SpringBootApplication
@EnableFeignClients
public class GoodsApplication {
public static void main(String[] args) {
SpringApplication.run(GoodsApplication.class, args);
}
}
- 服务熔断
- 服务降级
10.4 dubbo熔断机制
- Dubbo的熔断降级需要自己实现,也可以集成hystrix
- @EnableHystrix,@HystrixCommand,fallbackMethod
11 微服务降级
- Feign整合Hystrix的降级
- Hystrix本身的降级
- 隔离(线程池隔离和信号量隔离):限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用。
- 优雅的降级机制:超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。
- 融断:当失败率达到阀值自动触发降级(如因网络故障/超时造成的失败率高),熔断器触发的快速失败会进行快速恢复。
12 springcloud超时设置和重试机制
##timeout config
hystrix:
command:
default:
execution:
timeout:
enabled: true
isolation:
thread:
timeoutInMilliseconds: 60000
ribbon:
ReadTimeout: 60000
ConnectTimeout: 60000
MaxAutoRetries: 0
MaxAutoRetriesNextServer: 1
eureka:
enabled: false
zuul:
max:
host:
connections: 500
host:
socket-timeout-millis: 60000
connect-timeout-millis: 60000
12.1 zuul超时设置
- zuul使用服务发现(serviceId,使用ribbon轮询机制,取ribbon和hystrix配置最小值)
- ribbon.ReadTimeout
- ribbon.SocketTimeout
- zuul指定URL路由(url,基于httpclient发送请求)
- zuul.host.connect-timeout-millis
- zuul.host.socket-timeout-millis
12.2 ribbon超时设置
- ribbon总超时=(1 + MaxAutoRetries + MaxAutoRetriesNextServer) * ReadTimeout
- ribbon.ConnectTimeout,请求连接超时,会自动重试,重试失败zuul异常,默认值2000ms
- ribbon.ReadTimeout,请求处理超时,会自动重试,重试失败zuul异常,默认值5000ms
- MaxAutoRetries:当前实例最大自动重试次数,默认值0
- MaxAutoRetriesNextServer:最大自动重试下一个服务的次数,默认值1
- ribbon设置的超时应该要小于hystrix的超时
12.3 hystrix超时设置

设置隔离方式
execution.isolation.strategy= THREAD|SEMAPHOREzuul.semaphore.max-semaphores
是一个绝对值,无时间窗口,相当于亚毫秒级的。当请求达到或超过该设置值后,其余请求会被拒绝。默认100,这个值最好是根据每个后端服务的访问情况,单独设置。-
execution.isolation.thread.timeoutInMilliseconds
- 用来设置thread和semaphore两种隔离策略的超时时间,默认值1000ms,可以针对service-id单独设置。
- 单独设置时,要根据所对应的业务和服务器所能承受的负载来设置,一般是大于平均响应时间的20%~100%,最好是根据压力测试结果来评估,这个值设置太大,会导致线程不够用而会导致太多的任务被fallback;设置太小,一些特殊的慢业务失败率提升,甚至会造成这个业务一直无法成功,在重试机制存在的情况下,反而会加重后端服务压力。
execution.isolation.semaphore.maxConcurrentRequests
指任意时间点允许的并发数。当请求达到或超过该设置值后,其余就会被拒绝。默认值是100。execution.timeout.enabled
要使用hystrix的超时fallback,必须设置,默认开启execution.isolation.thread.interruptOnTimeout
发生超时是是否中断线程,默认是true。execution.isolation.thread.interruptOnCancel
取消时是否中断线程,默认是false。hystrix.command.default.fallback.isolation.semaphore.maxConcurrentRequests
设置fallback的线程数,默认是10,这个值在大量触发fallback逻辑时要注意调整。
13 springcloud hystrix隔离策略
- hystrix线程有两种隔离策略:
- 线程隔离
- 信号量隔离
- 隔离策略都是控制线程数量的,hystrix默认的隔离策略是thread,zuul中默认的hystrix隔离策略是semaphore,可通过zuul.ribbon-isolation-strategy=THREAD 修改为线程隔离方式。
- thread和semaphore隔离策略默认超时时间都是1000ms
- zuul隔离策略为Semaphore时,max-semaphores默认是100
14 重启zuul后为啥第一次访问经常会超时?怎么解决?
- zuul是懒加载机制,第一次访问才会加载类,而不是启动时候加载,由于默认时间本来很短,加载类也需要时间,就造成了超时。
- zuul依赖hystrix,通过处理hystrix超时来解决zuul首次访问超时问题。

15 Spring Boot 的核心配置文件有哪几个?它们的区别是什么?
Spring Boot 的核心配置文件是 application 和 bootstrap 配置文件。
- application 配置文件这个容易理解,主要用于 Spring Boot 项目的自动化配置。
- bootstrap 配置文件有以下几个应用场景。
- 使用 Spring Cloud Config 配置中心时,这时需要在 bootstrap 配置文件中添加连接到配置中心的配置属性来加载外部配置中心的配置信息;
- 一些固定的不能被覆盖的属性;
- 一些加密/解密的场景;
16 Spring Boot 的配置文件有哪几种格式?它们有什么区别?
- .properties 和 .yml。
- 它们的区别主要是书写格式不同。.yml 格式不支持 @PropertySource 注解导入配置
17 Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
- @SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
- @EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
- @ComponentScan:Spring组件扫描。
18 SpringBoot开启的两种方式?
- 继承spring-boot-starter-parent项目
- 导入spring-boot-dependencies项目依赖
19 Spring Boot 自动配置原理是什么?
注解 @EnableAutoConfiguration, @Configuration, @ConditionalOnClass 就是自动配置的核心,首先它得是一个配置文件,其次根据类路径下是否有这个类去自动配置。META-INF/spring.factories
20 Spring Boot 有哪几种读取配置的方式?
- @PropertySource
- @Value
- @Environment,
- @ConfigurationProperties
21 SpringBoot 实现热部署有哪几种方式?
- Spring Loaded
- Spring-boot-devtools
22 SpringBoot配置加载顺序?
1、开发者工具 `Devtools` 全局配置参数;
2、单元测试上的 `@TestPropertySource` 注解指定的参数;
3、单元测试上的 `@SpringBootTest` 注解指定的参数;
4、命令行指定的参数,如 `java -jar springboot.jar --name="Java技术栈"`;
5、命令行中的 `SPRING_APPLICATION_JSONJSON` 指定参数, 如 `java -Dspring.application.json='{"name":"Java技术栈"}' -jar springboot.jar`
6、`ServletConfig` 初始化参数;
7、`ServletContext` 初始化参数;
8、JNDI参数(如 `java:comp/env/spring.application.json`);
9、Java系统参数(来源:`System.getProperties()`);
10、操作系统环境变量参数;
11、`RandomValuePropertySource` 随机数,仅匹配:`ramdom.*`;
12、JAR包外面的配置文件参数(`application-{profile}.properties(YAML)`)
13、JAR包里面的配置文件参数(`application-{profile}.properties(YAML)`)
14、JAR包外面的配置文件参数(`application.properties(YAML)`)
15、JAR包里面的配置文件参数(`application.properties(YAML)`)
16、`@Configuration`配置文件上 `@PropertySource` 注解加载的参数;
17、默认参数(通过 `SpringApplication.setDefaultProperties` 指定);
23 保护 Spring Boot 应用有哪些方法?
- 在生产中使用HTTPS
- 使用Snyk检查你的依赖关系
- 升级到最新版本
- 启用CSRF保护
- 使用内容安全策略防止XSS攻击
https://mp.weixin.qq.com/s/HG4_StZyNCoWx02mUVCs1g
24 Spring Boot 2.X 有什么新特性?与 1.X 有什么区别?
- 配置变更
- JDK 版本升级
- 第三方类库升级
- 响应式 Spring 编程支持
- HTTP/2 支持
- 配置属性绑定
25 Spring Boot中的监视器是什么?
- Spring boot actuator是spring启动框架中的重要功能之一。Spring boot监视器可帮助您访问生产环境中正在运行的应用程序的当前状态。
- 有几个指标必须在生产环境中进行检查和监控。即使一些外部应用程序可能正在使用这些服务来向相关人员触发警报消息。监视器模块公开了一组可直接作为HTTP URL访问的REST端点来检查状态。
26 springboot常用的starter有哪些?
- spring-boot-starter-web 嵌入tomcat和web开发需要servlet与jsp支持
- spring-boot-starter-data-jpa 数据库支持
- spring-boot-starter-data-redis redis数据库支持
- spring-boot-starter-data-solr solr支持
- mybatis-spring-boot-starter 第三方的mybatis集成starter
27 如何在不使用BasePACKAGE过滤器的情况下排除程序包?
过滤程序包的方法不尽相同。但是弹簧启动提供了一个更复杂的选项,可以在不接触组件扫描的情况下实现这一点。在使用注释@ SpringBootApplication时,可以使用排除属性。请参阅下面的代码片段:
@SpringBootApplication(exclude= {Employee.class})
public class FooAppConfiguration {}
28 如何禁用特定的自动配置类?
- 若发现任何不愿使用的特定自动配置类,可以使用@EnableAutoConfiguration的排除属性。
//By using "exclude"
@EnableAutoConfiguration(exclude={DataSourceAutoConfiguration.class})
- 另一方面,如果类别不在类路径上,则可以使用excludeName类注解,并且指定完全限定名。
//By using "excludeName"
@EnableAutoConfiguration(excludeName={Foo.class})
- 此外,Spring Boot还具有控制排除自动配置类列表的功能,可以通过使用spring.autoconfigure.exclude property来实现。可以将其添加到 propertie应用程序中,并且可以添加逗号分隔的多个类。
//By using property file
spring.autoconfigure.exclude=org.springframework.boot.autoconfigure.jdbc.DataSourceAuto