
什么是语义分割?
语义分割是逐像素分类问题陈述。如果到目前为止,您已将图像中的一组像素分类为Cat,Dog,Zebra,Humans等,那么现在是时候学习如何为图像中的每个像素分配类。这可以通过语义分割,Mask-R-CNN等许多算法实现。
在本文中,我们将学习使用深度学习模型实现语义分割,该模型在称为U-Net的生物医学图像分割领域中表现得非常好。
网络可以用很少的图像端到端地进行训练,并且优于先前的最佳分割方法。
几年前,我使用OpenCV的GrabCut构建了一个应用程序,在图像上执行半自动分割(人在循环中),我的目标是在图像中分割前景和背景,它是可行的,但不是可扩展的解决方案。
然后我的问题陈述改为分段图像,这样我就需要分割图像中存在的多个对象,如果它们属于同一个类,我们会给出相同的标签。
使用GrabCut解决上述问题陈述是不可行的。
在本文中,我们将训练U-Net模型来构建一个可以自动注释2D卫星图像上的建筑物的应用程序。我将仅训练两个班级。一栋建筑和另一栋背景。
您可以为多个班级培训它。您可以在数据集上训练模型。您只需要按照我要在包含2D卫星图像的数据集上训练的类似步骤。
项目结构
|------U-Net
| |------data
| | |------train
| | | |-----|Folder_1
| | | | |------|images
| | | | |------|------|Folder_1.png
| | | | |------|masks
| | | | |------|------|Folder_1_mask_1.png
| | | | |------|------|Folder_1_mask_2.png
| | | | |------|------|Folder_1_mask_3.png
| | | | |------|------|Folder_1_mask_4.png
| | | | |------|------|Folder_1_mask_......png
| | | | |------|------|Folder_1_mask_n.png
| | | |-----|Folder_n
| | | | |------|images
| | | | |------|------|Folder_npng
| | | | |------|masks
| | | | |------|------|Folder_n_mask_1.png
| | | | |------|------|Folder_n_mask_2.png
| | | | |------|------|Folder_n_mask_3.png
| | | | |------|------|Folder_n_mask_4.png
| | | | |------|------|Folder_n_mask_......png
| | | | |------|------|Folder_n_mask_n.png| | |------test
| | | |-----|Folder_2
| | | | |------|images
| | | | |------|------|Folder_2.png
| |------code
| | |------train
| | | |------|train_unet.py
| | | |------|train.ipynb
| | |------test
| | | |------|test.py
| | |------util
| | | |------|resize.py
您可以通过单击此文本下载整个项目(需翻强)。
https://drive.google.com/open?id=16-wHZg0nQH7sb8gWH4v_yVJetW6NM8Wd
记得按照Keras的7个步骤来构建深度学习模型。
1. Analyze the dataset
2. Prepare the dataset
3. Create the model
4. Compile the model
5. Fit the model
6. Evaluate the model
7. Summary
创建数据集
分析并准备数据集
当您尝试训练任何深度学习模型时,这是我要说的最重要的一步。良好的分析和理解您将用于训练深度学习模型的数据将帮助您以一种有意识的方式选择超参数,矩阵,损失函数和优化器。它将使您免于过度拟合,不合适,节省您的时间和资源。
只有当您准备好花费大量时间仔细交叉检查增强数据的质量时,我才会建议数据增强。但是,如果你无法承受时间,仍然想要使用增强数据,我最不推荐的是外包图像预处理步骤。说实话,我不相信外包过程。它会产生大量的时间,当你没有看到预期的结果时,你就会感到恐慌,而且更多的是返工。
我注释所有训练图像,建立我的模型,训练和测试它们。
最近,一位深度学习爱好者(Leader)问了我一些我想做的事情。我的答案之一是“希望在标签团队的支持下工作”。听到这个,如果我愿意,他给了我一些时间来修改我的陈述。经过深思熟虑之后,我回答说:“希望与标签团队一起工作,并在他们中间工作”。他对我的“深思”很满意。是的,亲爱的朋友,当你必须标记/注释大量数据时,你需要一个团队来帮助你做到这一点。然后,我建议您与标签团队坐在一起,并注意您的数据是否正确注释。不要让人们说话,睡觉,吃饭,看他们的手机,做白日梦并注释你的数据。不,不,不允许这样做。数据就是数据。
在创建数据集之前,几个主要步骤应该是理解
数据要求
可用数据的类别,质量和数量与所需数据的数量。
数据采集
数据来自各种来源。数据也可以从环境中的传感器收集,例如交通摄像机,卫星,记录设备等。它还可以通过访谈,从在线资源下载或阅读文档来获得。
数据处理
必须处理或组织最初获得的数据以进行分析。例如,这些可能涉及将数据放入表格格式的行和列中以供进一步分析,例如在电子表格或统计软件中,或将图像及其注释放置在文本JSON文件中。
数据清理或后处理
处理和组织数据后,数据可能不完整,包含噪声,包含重复,损坏或可能已损坏。特别是对于图像处理数据清理涉及查找极值,图像归一化,去噪,歪斜校正,调整图像大小,增强或平滑边缘,照明校正,色彩空间转换,区域处理,阈值处理,构建聚类,找到相关性。验证注释和标签。
我正在训练2D卫星图像,我的图像要求是建立一个2D卫星图像的数据集,其中有建筑物,因为我试图从背景中分类建筑物。数据集应该是无偏的,应该具有良好的像素密度,高清晰度图像,大量数据,与每个图像相对应的掩模,其中建筑物被准确地注释。这里所需的数据处理和组织是在我接收到文本文件时生成掩模图像,其中提到了作为x和y坐标点的注释信息。举个例子,我在文本文件中的注释看起来像这样:
[[441, 562], [441, 529], [458, 529], [458, 520], [472, 520], [472, 528], [475, 528], [475, 561], [441, 562], [545, 541], [545, 520], [573, 520], [573, 541], [545, 541], [545, 541]]

最左边的图像是输入图像,中心图像是使用上述x和y坐标值(polyfill)创建的中间掩模,并且最左边的图像是在绘制所有注释点之后输入图像的完整掩模。
在创建数据集时,您可能会在文本,JSON,电子表格中找到注释,如果幸运的话,您可能会收到完整的掩码。
有了掩模后,需要将图像和掩模放在上面显示的结构中。我使用OpenCV来创建蒙版。您可以在util文件夹中找到此代码。您可能想要引用我的代码。现在将可用数据分为两部分训练和测试。保留70%的图像用于培训,30%的图像用于测试。切勿使用训练图像进行测试。
创建U-Net模型
导入依赖项
import os
import sys
import random
import warnings
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('agg')
import matplotlib.pyplot as plt
from tqdm import tqdm
from itertools import chain
from skimage.io import imread, imshow, imread_collection, concatenate_images
from skimage.transform import resize
from skimage.morphology import label
from keras.models import Model, load_model
from keras.layers import Input
from keras.layers.core import Dropout, Lambda
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.layers.pooling import MaxPooling2D
from keras.layers.merge import concatenate
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras import backend as K
import tensorflow as tf
import cv2
我已经与项目共享了依赖项要求文件。您可以在代码文件夹中找到需求文件。您可以使用以下命令创建新的虚拟环境来安装所有库。这些库是numpy,pandas,matplotlib,tqdm,sci-kit图像学习,Keras,tensorflow,OpenCV。
sudo apt update
sudo apt install python3-pip
pip3 --version
pip3 install virtualenv
virtualenv venv
source venv/bin/activate
pip3 install -r requirement.txt
# Set some parameters
IMG_WIDTH = 128
IMG_HEIGHT = 128
IMG_CHANNELS = 3
TRAIN_PATH = '/U-Net/data/train/'#enter path to training data
TEST_PATH = '/U-Net/data/test/'#enter path to testing data
warnings.filterwarnings('ignore', category=UserWarning, module='skimage')
seed = 42
random.seed = seed
np.random.seed = seed
print("Imported all the dependencies")
# Get train and test IDs
train_ids = next(os.walk(TRAIN_PATH))[1]
test_ids = next(os.walk(TEST_PATH))[1]
# Get and resize train images and masks
X_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
Y_train = np.zeros((len(train_ids), IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)
print("X_train",X_train.shape)
print("Y_train",Y_train.shape)
print('Getting and resizing train images and masks ... ')
sys.stdout.flush()
for n, id_ in tqdm(enumerate(train_ids), total=len(train_ids)):
path = TRAIN_PATH + id_
img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS]
img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True)
X_train[n] = img
mask = np.zeros((IMG_HEIGHT, IMG_WIDTH, 1), dtype=np.bool)
for mask_file in next(os.walk(path + '/masks/'))[2]:
mask_ = imread(path + '/masks/' + mask_file)
mask_ = np.expand_dims(resize(mask_, (IMG_HEIGHT, IMG_WIDTH), mode='constant',preserve_range=True), axis=-1)
mask = np.maximum(mask, mask_)
Y_train[n] = mask
# Get and resize test images
X_test = np.zeros((len(test_ids), IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS), dtype=np.uint8)
sizes_test = []
print('Getting and resizing test images ... ')
sys.stdout.flush()
for n, id_ in tqdm(enumerate(test_ids), total=len(test_ids)):
path = TEST_PATH + id_
img = imread(path + '/images/' + id_ + '.png')[:,:,:IMG_CHANNELS]
sizes_test.append([img.shape[0], img.shape[1]])
img = resize(img, (IMG_HEIGHT, IMG_WIDTH), mode='constant', preserve_range=True)
X_test[n] = img
print('Done!')
第1行到第7行 - 我已经定义了输入图像尺寸。它是128x128x3,掩模是128x128。列车和测试文件夹的路径在第6和第7行定义。
第9到18行 - 它用于取消python和随机库的所有随机性。第17行和第18行,它列出了培训和测试文件夹中使用的所有图像文件夹。
第21,22行 - 我们创建张量来加载输入图像及其蒙版。在第24行和第25行中,您可以看到数据集的形状。您可以使用您拥有的训练样本数量手动交叉检查号码。
第28行到第38行 - 这是代码块,其中图像和掩码文件从文件夹中读取,调整大小并分别加载到张量X_train和Y_train中。如果图像的大小很大,那么加载数据将会很愉快。加载720张图片一次在8核CPU上花了2个小时。
第40到49行 - 因为我已经加载了输入图像及其掩码。现在是加载测试图像的时候了。测试图像加载到张量X_test中。在这段代码中,读取,调整大小,加载测试图像。
训练U-Net模型
# Build U-Net model
inputs = Input((IMG_HEIGHT, IMG_WIDTH, IMG_CHANNELS))
s = Lambda(lambda x: x / 255) (inputs)
c1 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (s)
c1 = Dropout(0.1) (c1)
c1 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c1)
p1 = MaxPooling2D((2, 2)) (c1)
c2 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p1)
c2 = Dropout(0.1) (c2)
c2 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c2)
p2 = MaxPooling2D((2, 2)) (c2)
c3 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p2)
c3 = Dropout(0.2) (c3)
c3 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c3)
p3 = MaxPooling2D((2, 2)) (c3)
c4 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p3)
c4 = Dropout(0.2) (c4)
c4 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c4)
p4 = MaxPooling2D(pool_size=(2, 2)) (c4)
c5 = Conv2D(256, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p4)
c5 = Dropout(0.3) (c5)
c5 = Conv2D(256, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c5)
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same') (c5)
u6 = concatenate([u6, c4])
c6 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u6)
c6 = Dropout(0.2) (c6)
c6 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c6)
u7 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same') (c6)
u7 = concatenate([u7, c3])
c7 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u7)
c7 = Dropout(0.2) (c7)
c7 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c7)
u8 = Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same') (c7)
u8 = concatenate([u8, c2])
c8 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u8)
c8 = Dropout(0.1) (c8)
c8 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c8)
u9 = Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same') (c8)
u9 = concatenate([u9, c1], axis=3)
c9 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u9)
c9 = Dropout(0.1) (c9)
c9 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c9)
outputs = Conv2D(1, (1, 1), activation='sigmoid') (c9)
model = Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=[mean_iou])
model.summary()
该模型包含23个卷积层。卷积层的数量是19,转置的卷积层是4。
第2行到第3行输入图像的大小为128X128X3,其掩码大小为128X128。接下来是两个连续的卷积层。每层使用64个大小为3X3的过滤器。我通过将图像中的所有像素除以255来将图像像素归一化到0和1之间,因为我使用的是8位图像。
第5行到第8行 - 在第5行,层c1是第一个卷积层,在这个卷积层中,我使用了16个过滤器,每个过滤器大小为3x3。使用的激活函数是指数线性单位(ELU),“he_normal”是权重初始化方法。要了解有关使用ELU和“he_normal”背后原因的更多信息,请参阅本系列的第1部分。
第6行层c1的输出进入丢失层,在前向和后向通过期间丢弃0.1个节点。这用于正则化并使您的模型免于过度拟合。这层没有学习。
第7行 - 丢失后的层c1再次与每个大小为3x3的16个滤波器卷积。激活和重量初始化器保持不变。
我只是喜欢这些婴儿过滤器从图像处理到深度学习的成长过程。是的,我愿意。我记得使用过一次,两次,三次和多次过滤器,这些过滤器是经过多年对大型数据集的分析而设计的,现在事情已经成长起来。过滤器正在设计自己。
第8行 - 卷积层c1的输出现在进入最大池层。最大池化层m1的窗口大小是2×2。
我想再分享一下我的经历。最近我被问到一个问题“当我们使用过滤器对图像进行卷积时,图像的尺寸会减小,并且您必须意识到最大池化也是如此,它会减小尺寸。那么为什么我们分别使用卷积或最大池?我们可以使用卷积或最大池化“。这是一个很好的问题,这让我反思,我的回答是“卷积层负责提取图像特征,构建滤镜,在这个过程中,图像的尺寸减小,在这一层学习了很多参数。但是在max-pooling层中,没有学习参数。最大池化层通过仅考虑可用数据/特征的最佳表示,帮助我们以最有效的方式处理数据。这就是我们分别使用卷积层和最大池层的原因“
第10行到第13行 - 在这段代码中你可以找到与代码块类似的结构,如第5行到第8行所示。卷积层跟随一个丢失,然后再次进行卷积和最大池化。我在这个块中将过滤器的数量从16增加到32。辍学率仍为0.1。您可以自由使用这些超参数。我不想丢弃大量的节点,因为我将使用这些层信息来保留即将到来的层中的上下文信息。我还建议你保持辍学率很小。
第20行到第27行 - 您可以看到有两个类似于上面的代码块。您应该注意到所用过滤器数量的变化。过滤器的数量增加了一倍。
第29至51行 - 要注意这些重要的路线。
u6 = Conv2DTranspose(128, (2, 2),strides=(2, 2),padding='same') (c5)
u6 = concatenate([u6, c4])
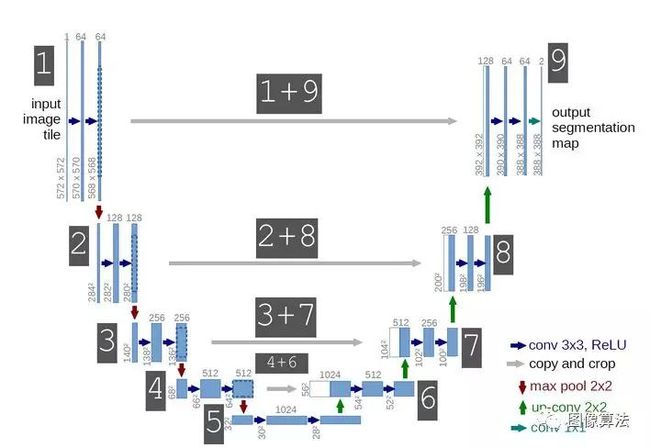
在这里,您可以看到两个名为Conv2DTranspose和连接的新层。首先,让我们了解Conv2DTranspose的功能。对转置卷积的需求通常源于希望使用在正常卷积的相反方向上进行的变换,即,从具有某种卷积输出形状的某种东西到具有其输入形状的某种东西,同时保持与所述卷积兼容的连接模式。我们的目标也是再现类似于输入掩模尺寸的掩模,我们使用Transpose卷积。
在上面的代码块中,您可以看到我们使用128个过滤器,每个过滤器大小为2x2,并在后面的c5输出上跨步2。一旦我们对其进行了上采样,输出就是u6。关于这个模型的最好和最重要的部分是连接层,它连接来自两个层的输出,一个来自其U形网络的左侧部分,另一个来自其U形网络的右侧部分。
在上面的代码块中,您可以看到最大池之前卷积层4的输出与层U6的输出连接。这样做是为了将一个像素的上下文信息保持到其相邻像素(左像素,右像素,对角像素等)。我们都知道修道院的早期层学习次要特征,并且它们有更多关于边缘,曲线等的信息。使用它们或将它们与后面的层连接将有利于在携带上下文信息时产生更准确的分割。
同样,U-Net架构右侧有四个块。每个块都有一个Transpose卷积层,一个连接层,两个卷积层,一个dropout层。

该图显示了如何使用Transpose卷积对来自编码器的特征映射进行上采样
第53行 - 这是一个完全卷积的深度学习模型,因此没有密集的层。最后一层是卷积层。使用的激活函数是sigmoid,因为我只有2个类。2D卫星地图图像上的建筑物和背景。如果您希望训练模型超过2个班级,则必须使用softmax。
第55行到第57行 - 我在这里使用的损失函数是二进制交叉熵,因为我正在使用二进制类。如果您使用两个以上的类,则必须用分类交叉熵替换它。我使用Adam作为优化器。在Adam中,为每个网络权重(参数)保持学习速率,并随着学习展开而单独调整。这里使用的指标是指IOU。度量标准在学习中没有任何作用,只是在那里你可以直观地将训练与损失函数之外的东西进行比较。您可以使用Keras summary()命令在控制台上打印模型摘要。
# Fit model
earlystopper = EarlyStopping(patience=5, verbose=1)
checkpointer = ModelCheckpoint('model-dsbowl2018-1.h5', verbose=1, save_best_only=True)
results = model.fit(X_train, Y_train, validation_split=0.1, batch_size=16, epochs=5,
callbacks=[earlystopper, checkpointer])
第2行 - 如果某些连续时期的验证损失没有减少,则早期停止可帮助您停止并保存模型。在代码中,你可以看到我已经提到耐心= 5,这意味着在训练期间如果验证损失没有增加连续5个时期,训练应该停止并保存模型。该模型将包含网络及其学习的权重,您可以使用它来预测新图像的结果。
测试U-Net模型
import os
import sys
import random
import warnings
import numpy as np
import pandas as pd
import matplotlib
matplotlib.use('agg')
import matplotlib.pyplot as plt
from tqdm import tqdm
from itertools import chain
from skimage.io import imread, imshow, imread_collection, concatenate_images
from skimage.transform import resize
from skimage.morphology import label
from keras.models import Model, load_model
from keras.layers import Input
from keras.layers.core import Dropout, Lambda
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.layers.pooling import MaxPooling2D
from keras.layers.merge import concatenate
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras import backend as K
import tensorflow as tf
import cv2
class automaticmaplabelling():
def __init__(self,modelPath,full_chq,imagePath,width,height,channels):
print (modelPath)
print(imagePath)
print(width)
print(height)
print(channels)
self.modelPath=modelPath
self.full_chq=full_chq
self.imagePath=imagePath
self.IMG_WIDTH=width
self.IMG_HEIGHT=height
self.IMG_CHANNELS=channels
self.model = self.U_net()
def mean_iou(self,y_true, y_pred):
prec = []
for t in np.arange(0.5, 1.0, 0.05):
y_pred_ = tf.to_int32(y_pred > t)
score, up_opt = tf.metrics.mean_iou(y_true, y_pred_, 2)
K.get_session().run(tf.local_variables_initializer())
with tf.control_dependencies([up_opt]):
score = tf.identity(score)
prec.append(score)
return K.mean(K.stack(prec), axis=0)
def U_net(self):
# Build U-Net model
inputs = Input((self.IMG_HEIGHT, self.IMG_WIDTH, self.IMG_CHANNELS))
s = Lambda(lambda x: x / 255) (inputs)
c1 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (s)
c1 = Dropout(0.1) (c1)
c1 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c1)
p1 = MaxPooling2D((2, 2)) (c1)
c2 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p1)
c2 = Dropout(0.1) (c2)
c2 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c2)
p2 = MaxPooling2D((2, 2)) (c2)
c3 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p2)
c3 = Dropout(0.2) (c3)
c3 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c3)
p3 = MaxPooling2D((2, 2)) (c3)
c4 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p3)
c4 = Dropout(0.2) (c4)
c4 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c4)
p4 = MaxPooling2D(pool_size=(2, 2)) (c4)
c5 = Conv2D(256, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (p4)
c5 = Dropout(0.3) (c5)
c5 = Conv2D(256, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c5)
u6 = Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same') (c5)
u6 = concatenate([u6, c4])
c6 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u6)
c6 = Dropout(0.2) (c6)
c6 = Conv2D(128, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c6)
u7 = Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same') (c6)
u7 = concatenate([u7, c3])
c7 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u7)
c7 = Dropout(0.2) (c7)
c7 = Conv2D(64, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c7)
u8 = Conv2DTranspose(32, (2, 2), strides=(2, 2), padding='same') (c7)
u8 = concatenate([u8, c2])
c8 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u8)
c8 = Dropout(0.1) (c8)
c8 = Conv2D(32, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c8)
u9 = Conv2DTranspose(16, (2, 2), strides=(2, 2), padding='same') (c8)
u9 = concatenate([u9, c1], axis=3)
c9 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (u9)
c9 = Dropout(0.1) (c9)
c9 = Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_normal', padding='same') (c9)
outputs = Conv2D(1, (1, 1), activation='sigmoid') (c9)
model = Model(inputs=[inputs], outputs=[outputs])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=[self.mean_iou])
model.load_weights(self.modelPath)
model.summary()
return model
def prediction(self):
img=cv2.imread(self.imagePath,0)
img=np.expand_dims(img,axis=-1)
x_test= np.zeros((1, self.IMG_HEIGHT, self.IMG_WIDTH, self.IMG_CHANNELS), dtype=np.uint8)
#testimg=resize(img,(self.IMG_HEIGHT,self.IMG_WIDTH),mode='constant',preserve_range=True)
x_test[0]=img
preds_test= self.model.predict(x_test, verbose=1)
preds_test = (preds_test > 0.5).astype(np.uint8)
mask=preds_test[0]
for i in range(mask.shape[0]):
for j in range(mask.shape[1]):
if mask[i][j] == 1:
mask[i][j] = 255
else:
mask[i][j] = 0
merged_image = cv2.merge((mask,mask,mask))
contours, hierarchy = cv2.findContours(mask,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
for each_contour in contours:
x,y,w,h = cv2.boundingRect(each_contour)
cv2.rectangle(merged_image,(x,y),(x+w,y+h),(0,0,255),4)
print (x,y,w,h)
cv2.imshow("merged_image",merged_image)
cv2.waitKey(0)
cv2.imwrite("mask.png",mask)
return x_test[0],mask
def main():
test_image_name = "test_image.png"
automaticmaplabellingobj= automaticmaplabelling('model-dsbowl2018-1.h5',True,test_image_name,128,128,3)
testimg,mask = automaticmaplabellingobj.prediction()
print('Showing images..')
cv2.imshow('img',testimg)
dim = (1280, 1280)
resized = cv2.resize(mask, dim, interpolation = cv2.INTER_AREA)
cv2.imshow('mask',mask)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.imwrite("resized_mask.png",resized)
if __name__ == "__main__":
main()
上面的代码用于测试我们加载训练模型的位置(你可以在测试文件夹中找到训练好的模型)并在测试图像上测试结果(测试图像的大小必须是128x128x3,你可以找到一些样本 在测试文件夹内的test_128文件夹中测试图像)。由于我们得到二值化输出,因此如果输出像素为0,则为其指定强度0,如果输出像素强度为1,则为其指定强度255.预测精度阈值为0.5。此外,我用于训练模型的数据存在隐私问题。尊重这一点,我已经分享了类似的测试图像。同样在数据文件夹中,我放置了一个不同的数据集,以便它可以帮助您了解如何构建自定义数据集。
结果分析

我用720张图像进行训练,用180张图像测试U-Net模型。当在720个图像上训练30个时期时,我已经实现了0.31558的验证损失和IOU准确度0.6293。当我在128张图像上训练模型时,验证损失为0.8973。损失和IOU值的增加和减少有多种因素,它不仅仅是图像的数量。
我建议根据我在下一节中观察到的数据和模型进行一些改进。
改进建议
使用编码器部分中的剩余网络。如果使用大跳过连接可以帮助增强结果,可以尝试使用编码器部分中的剩余网络。
如果您的硬件允许您训练大图像。如果你有很好的内存带宽,我总是建议你使用尺寸为512X512X3,572x572x3的图像。
我的数据也缺乏质量。图像的对比度非常低。但这就是自然场景的方式。我没有对图像进行任何预处理,但在预处理图像后看到改善或减少结果会非常有趣。
我建议在激活功能后使用批量标准化,这将有助于您的模型更快地规范和学习。
我还想看看使用relu如何帮助模型以及我们在收敛速度中可以看到什么效果。
填充很重要,因为我们缺少来自边境地区的大量信息。我没有填充我的图像。因此,如果您的目标也是从图像边界预测准确信息,则必须在训练时考虑填充图像。
更多论文源码关注微信公众号:“图像算法”或者微信搜索账号imalg_cn关注公众号