Foreword
大数据领域SQL化的风潮方兴未艾(所谓"Everybody knows SQL"),Flink自然也不能“免俗”。Flink SQL是Flink系统内部最高级别的API,也是流批一体思想的集大成者。用户可以通过简单明了的SQL语句像查表一样执行流任务或批任务,屏蔽了底层DataStream/DataSet API的复杂细节,降低了使用门槛。
那么,一条Flink SQL语句是如何转化成可执行的任务的呢?本文以最新的Flink 1.11版本为蓝本,分上下两篇详细梳理流程。在此之前,先简要介绍Apache Calcite与Blink Planner。
Prerequisite: Apache Calcite & Workflow
不同于Spark专门打造Catalyst作为其SQL层核心的骚操作,Flink没有重复造轮子,而是务实地直接利用了通用的SQL解析与优化引擎——Apache Calcite。Calcite在Hive、Drill、Pheonix、Kylin诸框架中都已经有了非常成熟的应用,Flink选择它也是情理之中。
下图示出Calcite在整个Flink Table & SQL体系中的作用。
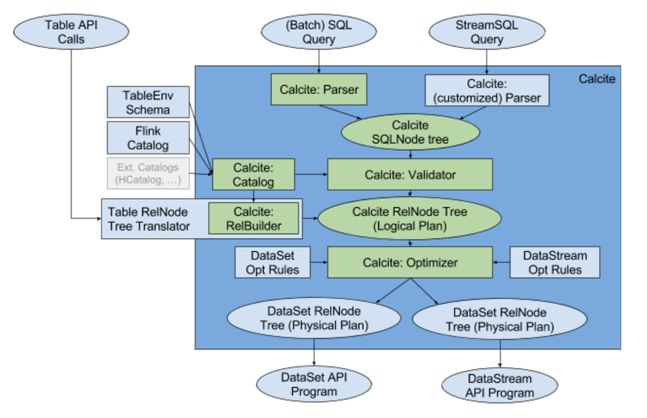
可见,Calcite在此体系内需要负责以下任务:
- 解析(parsing)——将SQL语句转化为抽象语法树(AST),即SqlNode树。
- 验证(validation)——根据Catalog中的元数据进行语法检查。
- 逻辑计划(logical planning)——根据AST和元数据构造出逻辑计划,即RelNode树。
- 逻辑计划优化(logical plan optimization)——按照预定义的优化规则RelOptRule优化逻辑计划。Calcite中的优化器RelOptPlanner有两种,一是基于规则优化(RBO)的HepPlanner,二是基于代价优化(CBO)的VolcanoPlanner。
- 物理计划(physical planning)——将优化的逻辑计划翻译成对应执行逻辑的物理计划。
前4个阶段其实就是Calcite的标准工作流,同时这5个阶段也基本上涵盖了Flink SQL执行流程的主体部分。Table API相对于SQL只是在解析、验证方面有些不同(解析的不是SQL语句而是算子树,再用Calcite RelBuilder生成逻辑计划)。而在物理计划之后,还需要通过代码生成(code generation)最终转化为能够直接执行的DataStream/DataSet API程序。下面分析Flink SQL的执行步骤时,就以上面的5 + 1 = 6个阶段为准。
本文作为上篇,先讲解比较简单的解析、验证和逻辑计划,下篇再讲解比较复杂的逻辑计划优化、物理计划和代码生成。
关于Calcite细节的讲解有珠玉在前,看官可直接参考以下几篇文章,本文不再班门弄斧了。
- 《Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources》 from SIGMOD 2018 by E.Begoli et al.
- 《Apache Calcite处理流程详解(一)》 from matt33.com
- 《Apache Calcite优化器详解(二)》 from matt33.com
Prerequisite: Blink Planner
Flink Table/SQL体系中的Planner(即查询处理器)是沟通Flink与Calcite的桥梁,为Table/SQL API提供完整的解析、优化和执行环境。Blink Planner从1.9版本开始合并到Flink主干,并从1.11版本开始成为默认Planner,而原有的Old Planner将会逐渐退役。
Blink Planner真正地践行了流批一体的处理方式。它根据流处理作业和批处理作业的不同,分别提供了StreamPlanner和BatchPlanner两种实现。这两种Planner的底层共享了基类PlannerBase的很多源码,且作业最终都会翻译成基于DataStream Transformation API的执行逻辑(即将批处理视为流处理的特殊情况)。通过如下类图即可看出一二。
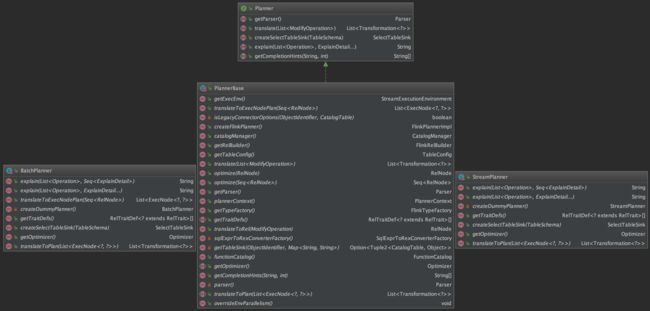
Blink Planner正式发布时社区的介绍见这里,不多废话了。
Example Preparation
为了方便讲解,使用一个简单的基于官方StreamSQLExample改造而来的示例,完整代码如下。
object StreamSQLExample {
def main(args: Array[String]): Unit = {
val settings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build()
// set up execution environment
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val tEnv = StreamTableEnvironment.create(env, settings)
val orders: DataStream[Order] = env.fromCollection(Seq(
Order(20200819177L, 1L, "beer", 3),
Order(20200819234L, 2L, "diaper", 4),
Order(20200819239L, 2L, "beef", 6),
Order(20200820066L, 3L, "rubber", 2),
Order(20200820100L, 3L, "beer", 5)))
val users: DataStream[User] = env.fromCollection(Seq(
User(1L, "Alice", 27),
User(2L, "Bob", 26),
User(3L, "Charlie", 25)))
// register DataStream as Table
val tableA = tEnv.createTemporaryView("orders", orders, 'id, 'uid, 'product, 'amount)
val tableB = tEnv.createTemporaryView("users", users, 'id, 'name, 'age)
// join the two tables
val sql =
s"""
|SELECT u.name,sum(o.amount) AS total
|FROM orders o
|INNER JOIN users u ON o.uid = u.id
|WHERE u.age < 27
|GROUP BY u.name
""".stripMargin
print(tEnv.explainSql(sql))
val result = tEnv.sqlQuery(sql)
result.toRetractStream[Row].print()
env.execute()
}
case class Order(id: Long, uid: Long, product: String, amount: Int)
case class User(id: Long, name: String, age: Int)
}
通过TableEnvironment.explainSql()方法可以直接以文本形式获取到上述SQL语句的查询计划,包括抽象语法树、优化的逻辑计划和物理执行计划三部分,在接下来的行文中会逐渐将查询计划贴出来。
好了,Let's get our hands dirty.
Stage 1: Parsing
首先来到执行SQL语句的入口TableEnvironmentImpl.sqlQuery()方法,第一句就是调用Parser.parse()方法解析SQL。
// TableEnvironmentImpl.sqlQuery()
@Override
public Table sqlQuery(String query) {
List operations = parser.parse(query);
// ......
}
继续来到ParserImpl.parse()以及它调用的CalciteParser.parse()方法。
// ParserImpl.parse()
@Override
public List parse(String statement) {
CalciteParser parser = calciteParserSupplier.get();
FlinkPlannerImpl planner = validatorSupplier.get();
// parse the sql query
SqlNode parsed = parser.parse(statement);
Operation operation = SqlToOperationConverter.convert(planner, catalogManager, parsed)
.orElseThrow(() -> new TableException("Unsupported query: " + statement));
return Collections.singletonList(operation);
}
// CalciteParser.parse()
public SqlNode parse(String sql) {
try {
SqlParser parser = SqlParser.create(sql, config);
return parser.parseStmt();
} catch (SqlParseException e) {
throw new SqlParserException("SQL parse failed. " + e.getMessage(), e);
}
}
可见是直接调用Calcite的SQL解析器SqlParser进行解析的。限于篇幅原因,本文就不继续向下追踪了,看官可在上文提到的参考文档中找到详细的Calcite源码分析。来观察一下解析出的SqlNode数据吧。
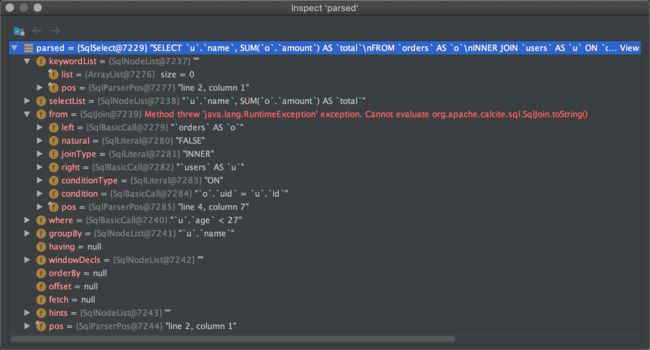
我们知道,Flink的SQL方言与标准SQL相比有很大差别,那么如何实现Flink SQL专用的解析器呢?注意到构造SqlParser的配置类SqlParser.Config时,需要传入解析器工厂SqlParserImplFactory,对应代码如下。
// PlanningConfigurationBuilder.getSqlParserConfig()
public SqlParser.Config getSqlParserConfig() {
return JavaScalaConversionUtil.toJava(calciteConfig(tableConfig).sqlParserConfig()).orElseGet(() ->
// we use Java lex because back ticks are easier than double quotes in programming
// and cases are preserved
SqlParser
.configBuilder()
.setParserFactory(FlinkSqlParserImpl.FACTORY)
.setConformance(getSqlConformance())
.setLex(Lex.JAVA)
.build());
}
但是flink-sql-parser模块中默认并没有FlinkSqlParserImpl这个类。我们只需要将该模块build一下,就会发现JavaCC开始编译Flink SQL的语法描述文件(包含Calcite内置的Parser.jj与Flink定制好的Freemarker模板),输出如下信息:
[INFO] --- javacc-maven-plugin:2.4:javacc (javacc) @ flink-sql-parser ---
Java Compiler Compiler Version 4.0 (Parser Generator)
(type "javacc" with no arguments for help)
Reading from file /Users/lmagic/workspace-new/gitee/flink/flink-table/flink-sql-parser/target/generated-sources/javacc/Parser.jj . . .
Note: UNICODE_INPUT option is specified. Please make sure you create the parser/lexer using a Reader with the correct character encoding.
File "TokenMgrError.java" does not exist. Will create one.
File "ParseException.java" does not exist. Will create one.
File "Token.java" does not exist. Will create one.
File "SimpleCharStream.java" does not exist. Will create one.
Parser generated successfully.
[INFO] Processed 1 grammar
最终在generated-sources目录下生成了FlinkSqlParserImpl及其附属的类,Calcite会利用它们进行Flink SQL的解析。codegen目录下则是语法描述文件的本体。

// FlinkSqlParserImpl
/**
* SQL parser, generated from Parser.jj by JavaCC.
*
* The public wrapper for this parser is {@link SqlParser}.
*/
public class FlinkSqlParserImpl extends SqlAbstractParserImpl implements FlinkSqlParserImplConstants
Stage 2: Validation
SQL解析完成后,上文所述ParserImpl.parse()方法紧接着就会调用验证相关的逻辑。查看SqlToOperationConverter.convert()方法的代码。
// SqlToOperationConverter.convert()
public static Optional convert(
FlinkPlannerImpl flinkPlanner,
CatalogManager catalogManager,
SqlNode sqlNode) {
// validate the query
final SqlNode validated = flinkPlanner.validate(sqlNode);
// ......
}
FlinkPlannerImpl.validate()方法与其调用的validateInternal()方法如下所示。
def validate(sqlNode: SqlNode): SqlNode = {
val validator = getOrCreateSqlValidator()
validateInternal(sqlNode, validator)
}
private def validateInternal(sqlNode: SqlNode, validator: FlinkCalciteSqlValidator): SqlNode = {
try {
sqlNode.accept(new PreValidateReWriter(
validator.getCatalogReader.unwrap(classOf[CatalogReader]), typeFactory))
// do extended validation.
sqlNode match {
case node: ExtendedSqlNode =>
node.validate()
case _ =>
}
// no need to validate row type for DDL and insert nodes.
if (sqlNode.getKind.belongsTo(SqlKind.DDL)
|| sqlNode.getKind == SqlKind.INSERT
|| sqlNode.getKind == SqlKind.CREATE_FUNCTION
|| sqlNode.getKind == SqlKind.DROP_FUNCTION
|| sqlNode.getKind == SqlKind.OTHER_DDL
|| sqlNode.isInstanceOf[SqlShowCatalogs]
|| sqlNode.isInstanceOf[SqlShowDatabases]
|| sqlNode.isInstanceOf[SqlShowTables]
|| sqlNode.isInstanceOf[SqlShowFunctions]
|| sqlNode.isInstanceOf[SqlShowViews]
|| sqlNode.isInstanceOf[SqlRichDescribeTable]) {
return sqlNode
}
sqlNode match {
case explain: SqlExplain =>
val validated = validator.validate(explain.getExplicandum)
explain.setOperand(0, validated)
explain
case _ =>
validator.validate(sqlNode)
}
}
catch {
case e: RuntimeException =>
throw new ValidationException(s"SQL validation failed. ${e.getMessage}", e)
}
}
可见,对于某些SqlNode类型是不需要验证的,直接返回。FlinkCalciteSqlValidator继承了Calcite的默认验证器SqlValidatorImpl,并额外规定了对字面量和join的验证逻辑,代码就不再贴出来了。
观察验证过后的SqlNode数据,可以发现多出了catalog和database的名称,说明确实根据元数据校验了各个元素(表名、列名及类型、函数名等)。
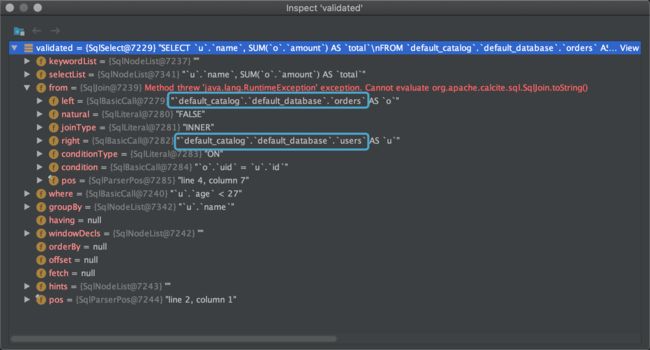
经历了解析和验证阶段之后,我们的查询计划仍然停留在SqlNode树的形态。如果用AST的方式表达,如下所示。
== Abstract Syntax Tree ==
LogicalAggregate(group=[{0}], total=[SUM($1)])
+- LogicalProject(name=[$5], amount=[$3])
+- LogicalFilter(condition=[<($6, 27)])
+- LogicalJoin(condition=[=($1, $4)], joinType=[inner])
:- LogicalTableScan(table=[[default_catalog, default_database, orders]])
+- LogicalTableScan(table=[[default_catalog, default_database, users]])
Stage 3: Logical Planning
在逻辑计划阶段,SqlNode将被转化成RelNode,从单纯的语句转化为对数据的处理逻辑,即关系代数的具体操作,如Scan、Project、Filter、Join等。接着上一节SqlToOperationConverter.convert()方法来看。
// SqlToOperationConverter.convert()
public static Optional convert(
FlinkPlannerImpl flinkPlanner,
CatalogManager catalogManager,
SqlNode sqlNode) {
// validate the query
final SqlNode validated = flinkPlanner.validate(sqlNode);
SqlToOperationConverter converter = new SqlToOperationConverter(flinkPlanner, catalogManager);
if (validated instanceof SqlCreateTable) {
return Optional.of(converter.createTableConverter.convertCreateTable((SqlCreateTable) validated));
} else if (validated instanceof SqlDropTable) {
return Optional.of(converter.convertDropTable((SqlDropTable) validated));
} else if (validated instanceof SqlAlterTable) {
return Optional.of(converter.convertAlterTable((SqlAlterTable) validated));
} else if (validated instanceof SqlAlterView) {
return Optional.of(converter.convertAlterView((SqlAlterView) validated));
} else if (validated instanceof SqlCreateFunction) {
return Optional.of(converter.convertCreateFunction((SqlCreateFunction) validated));
} else if (/*...*/) {
// ......
} else if (validated instanceof SqlRichDescribeTable) {
return Optional.of(converter.convertDescribeTable((SqlRichDescribeTable) validated));
} else if (validated.getKind().belongsTo(SqlKind.QUERY)) {
return Optional.of(converter.convertSqlQuery(validated));
} else {
return Optional.empty();
}
}
这个方法会用很多重if-else判断验证之后的SqlNode属于何种类型,再分别调用不同的方法触发转换为RelNode的操作。由于示例中执行的是一个SELECT语句,所以从convertSqlQuery()方法继续。
// SqlToOperationConverter.convertSqlQuery()
private Operation convertSqlQuery(SqlNode node) {
return toQueryOperation(flinkPlanner, node);
}
// SqlToOperationConverter.toQueryOperation()
private PlannerQueryOperation toQueryOperation(FlinkPlannerImpl planner, SqlNode validated) {
// transform to a relational tree
RelRoot relational = planner.rel(validated);
return new PlannerQueryOperation(relational.project());
}
注释已经写得很明白了,FlinkPlannerImpl.rel()方法将SqlNode树转化为RelNode树,并返回其根RelRoot。而rel()方法直接利用Calcite内置的SqlToRelConverter组件来递归地转换,其具体逻辑仍然可见参考文档。
// FlinkPlannerImpl.rel()
private def rel(validatedSqlNode: SqlNode, sqlValidator: FlinkCalciteSqlValidator) = {
try {
assert(validatedSqlNode != null)
val sqlToRelConverter: SqlToRelConverter = new SqlToRelConverter(
createToRelContext(),
sqlValidator,
sqlValidator.getCatalogReader.unwrap(classOf[CalciteCatalogReader]),
cluster,
convertletTable,
sqlToRelConverterConfig)
sqlToRelConverter.convertQuery(validatedSqlNode, false, true)
// ......
} catch {
case e: RelConversionException => throw new TableException(e.getMessage)
}
}
下图示出RelRoot所表示的RelNode树形结构,注意LogicalAggregate、LogicalProject等都是Calcite中AbstractRelNode的实现类。
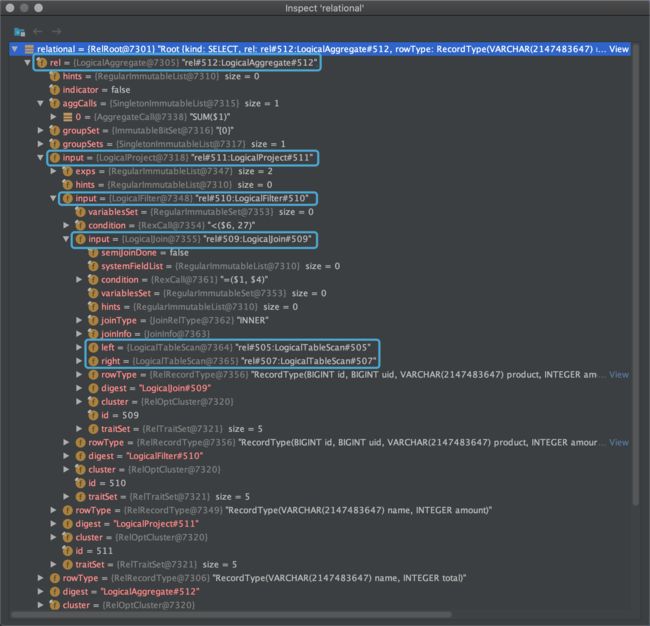
To Be Continued...
民那晚安晚安。