一:爬虫认知
爬虫名称由来于蜘蛛结网,蜘蛛在一个一个的蛛网节点中等待猎物的到来。而我们的爬虫也是从网页页面的HTML资源中取出我们要的节点资源。二者过程相似,因此爬虫称之为Spider。
1.1 爬虫的前置知识
知道双标签的HTML结构,知道网页或者抓包工具如何查看资源,了解css和js更佳。如果零基础也没有关系,接下来的案例讲解中会穿插到有相关的知识。
1.2 准备工具
安装有python3,以及requests、lxml、beautifulsoup4、selenium、scripy三方包。
二:爬虫基础
2.1 基本套路
- 基本流程
- 目标数据是什么,你要爬取什么数据?
- 来源地址在哪,你从什么地方爬取数据?
- 你要的数据放在那些HTML结构里面?
- 你采用那种方式进行数据提取?xpath、css选择、beautifulsoup提取、re正则提取?
- 基本手段
- 破解请求限制
- 请求头设置,模拟设置请求头
- 控制请求频率(根据实际情景),控制爬虫休眠(防止DNS攻击目标网站)
- IP代理(防止反爬手段封你的IP)
- 签名/加密参数从html/cookie/js分析(网站要求验证信息)
- 破解登录授权
- 请求带上用户cookie信息
- 破解验证码
- 简单的验证码可以使用识图读验证码第三方库(自己训练验证码算法或者付费实现)
- 破解请求限制
- 解析数据
- xpath、css选择、beautifulsoup提取、re正则提取?
2.2 一个简单爬虫
import requests # 导入三方包 requests
url = 'http://www.baidu.com' # 给出访问地址
response = requests.get(url=url) # 利用requests包进行请求访问
print(response.status_code) # 返回请求状态码,200代表访问成功,可以直接答应response查看一下整体效果
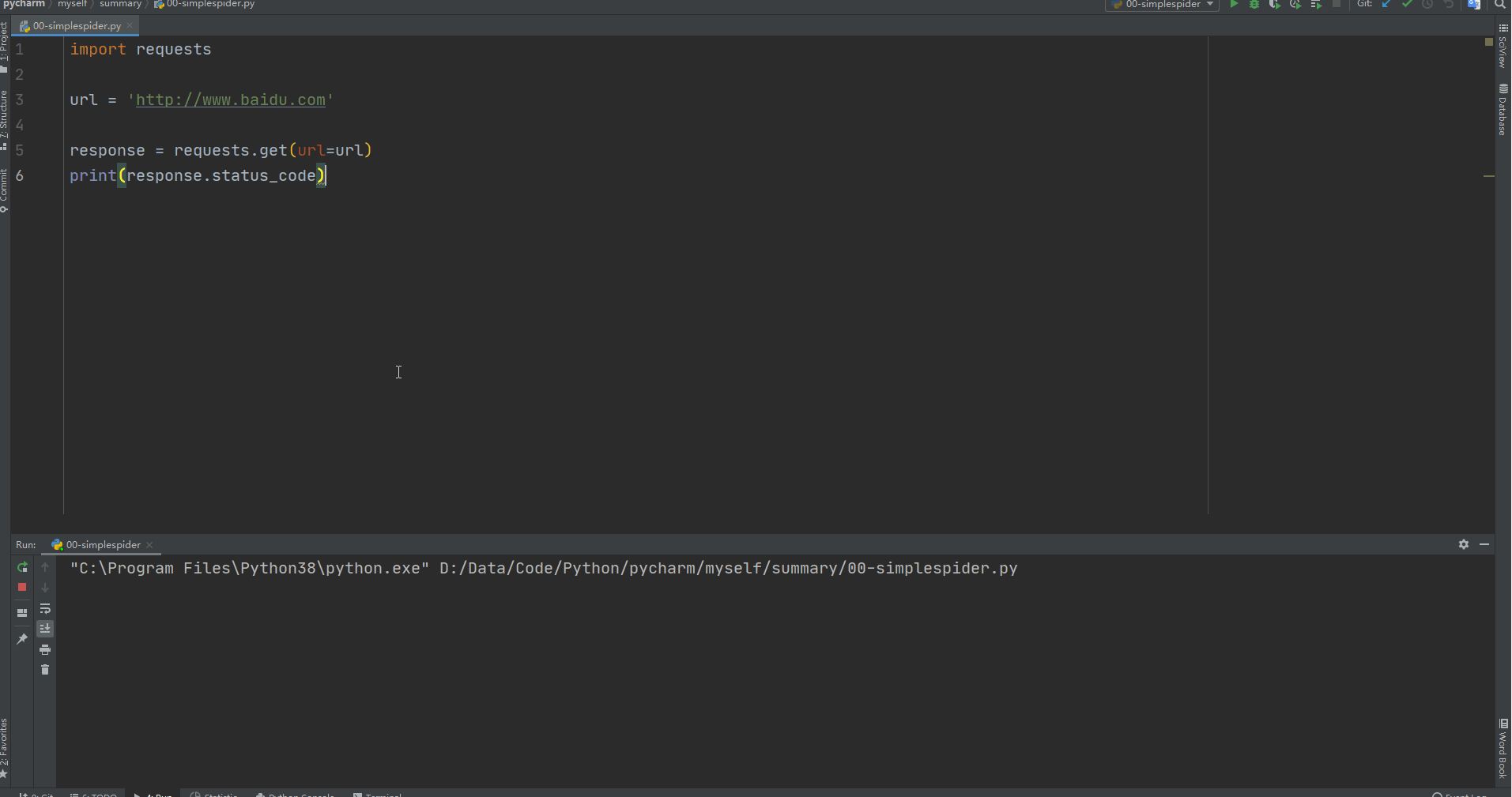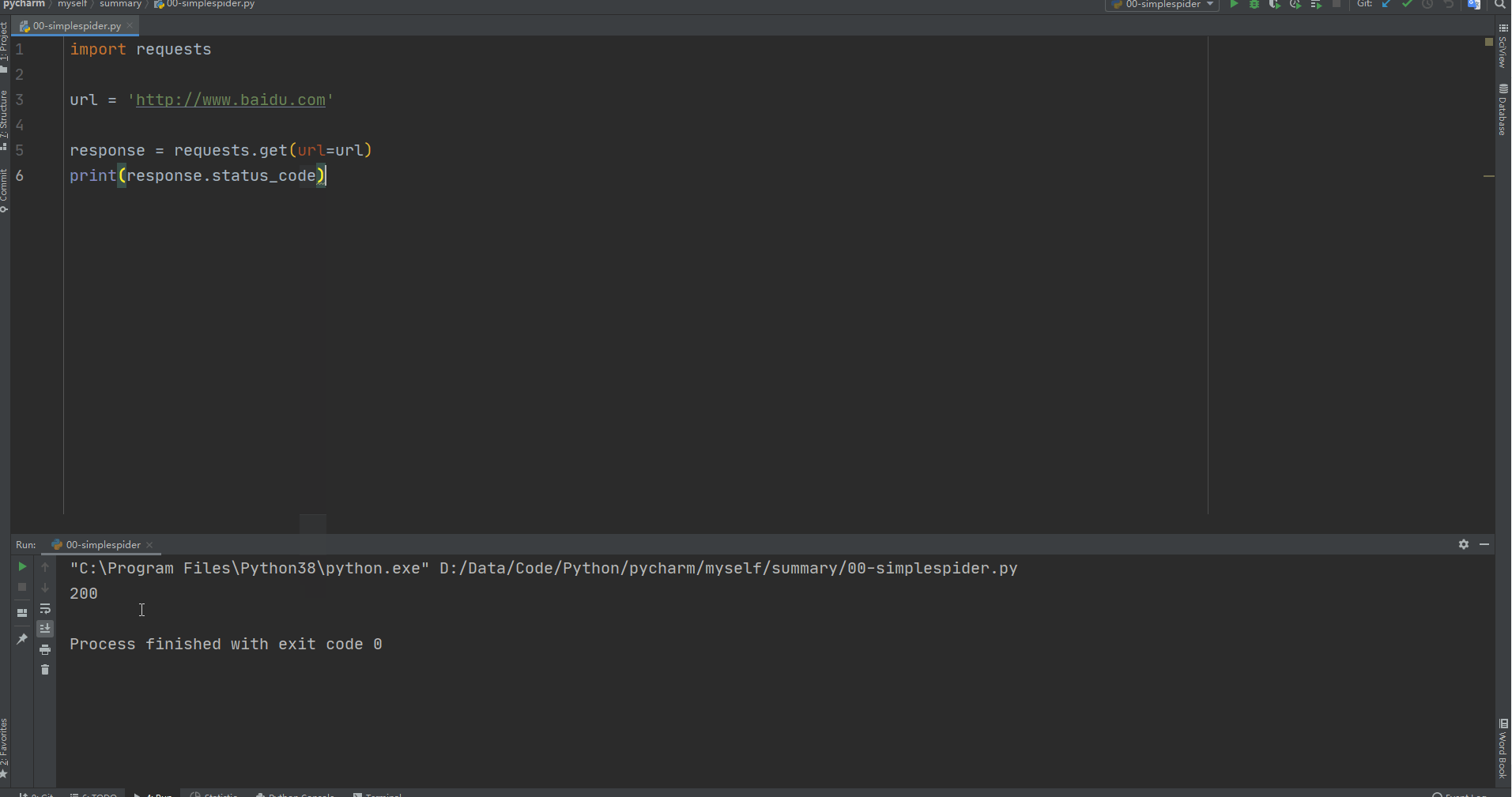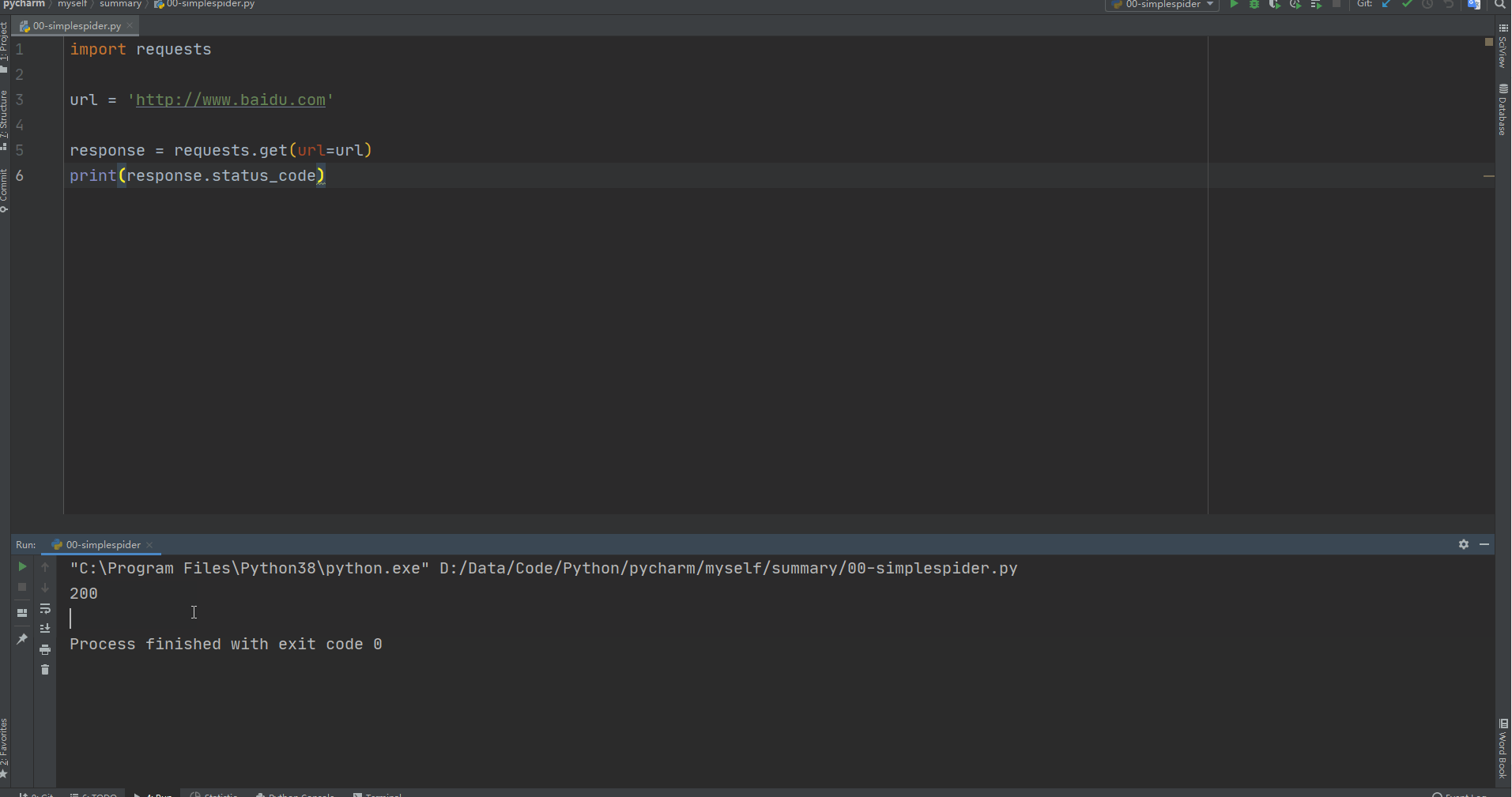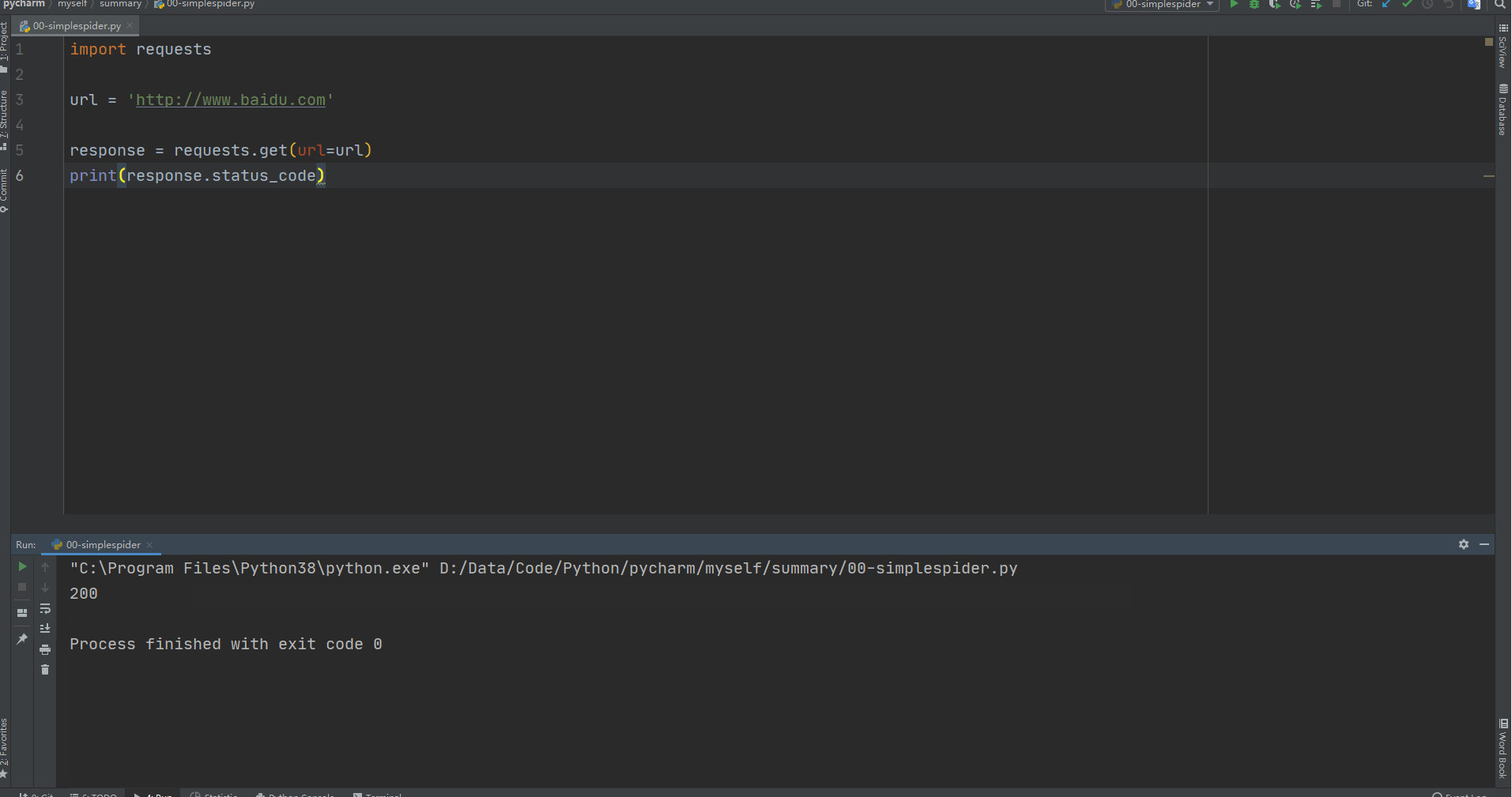
对比之后我们发现,两者的网页并不一样,莫着急,上面的简单爬虫只是想要说明在python中爬虫代码有多么容易,短短三行代码就可以构建一个爬虫。真正运用的爬虫可以参考上诉构造方式添加参数构建。
2.3 一些简单参数的添加
2.3.1 爬虫响应信息
| 代码 | 含义 |
|---|---|
| response.json() | 获取响应内容(以json字符串) |
| response.text | 获取响应内容 (以字符串) |
| response.content | 获取响应内容(以字节的方式) |
| response.headers | 获取响应头内容 |
| response.url | 获取访问地址 |
| response.encoding | 获取网页编码 |
| response.request.headers | 请求头内容 |
| response.cookie | 获取cookie |
2.3.2 构造header
现如今网站的反爬手段非常多,除了一部分网站不做反爬措施以外,大部分都做了反爬。因此,我们就需要为我们的爬虫来添加各种参数,使得网站认为这是一个用户在浏览内容,而不是一个爬虫在进行内容爬取。当然,现如今随着法律的健全,爬虫也需要注意不要去爬取违法资源。可以参考网站的/robots.txt,看有哪些内容是不允许爬取的。这个还是要看一下的,否则牢狱之灾也不是说着玩的。
网页地址/robots.txt
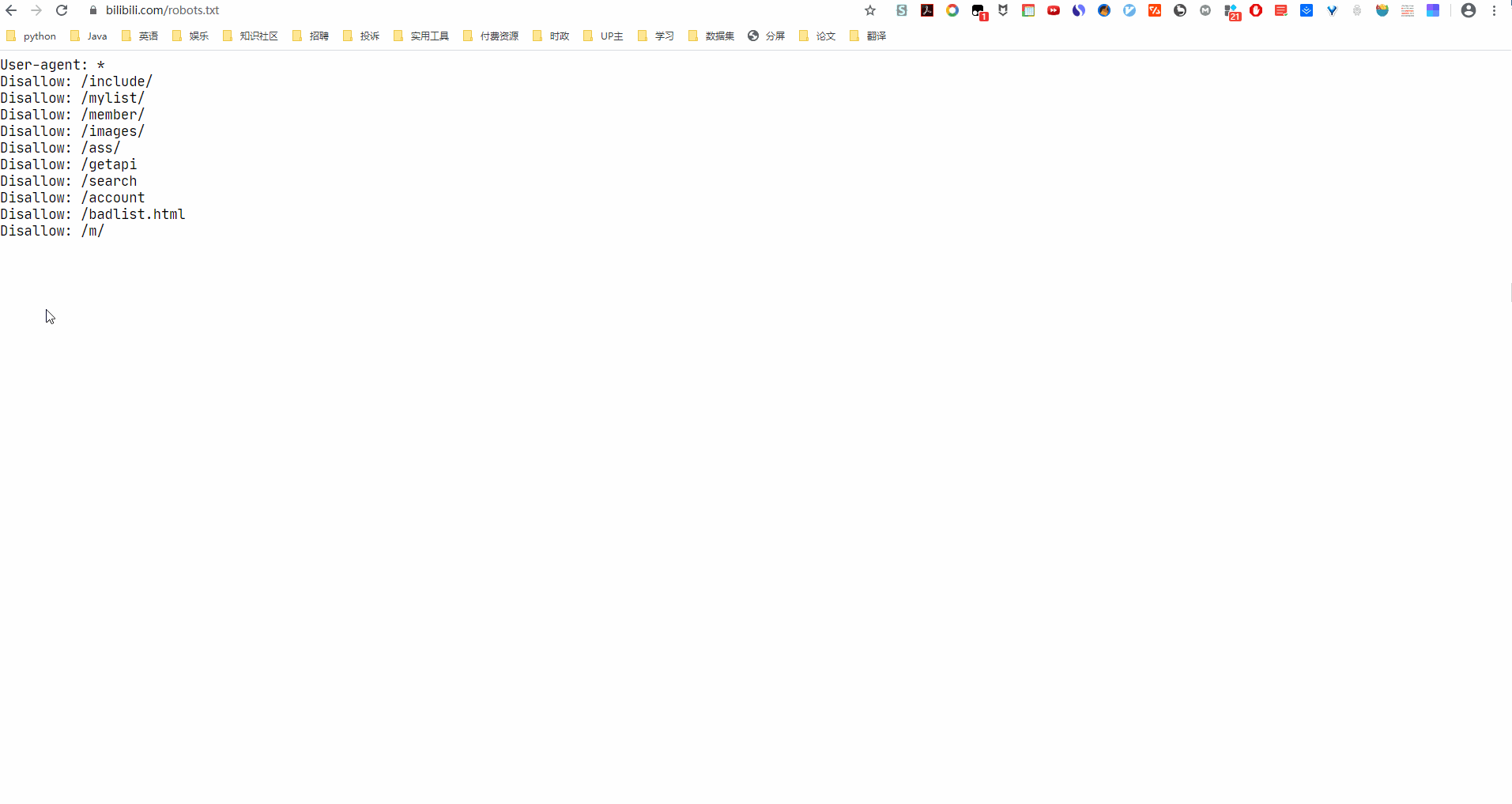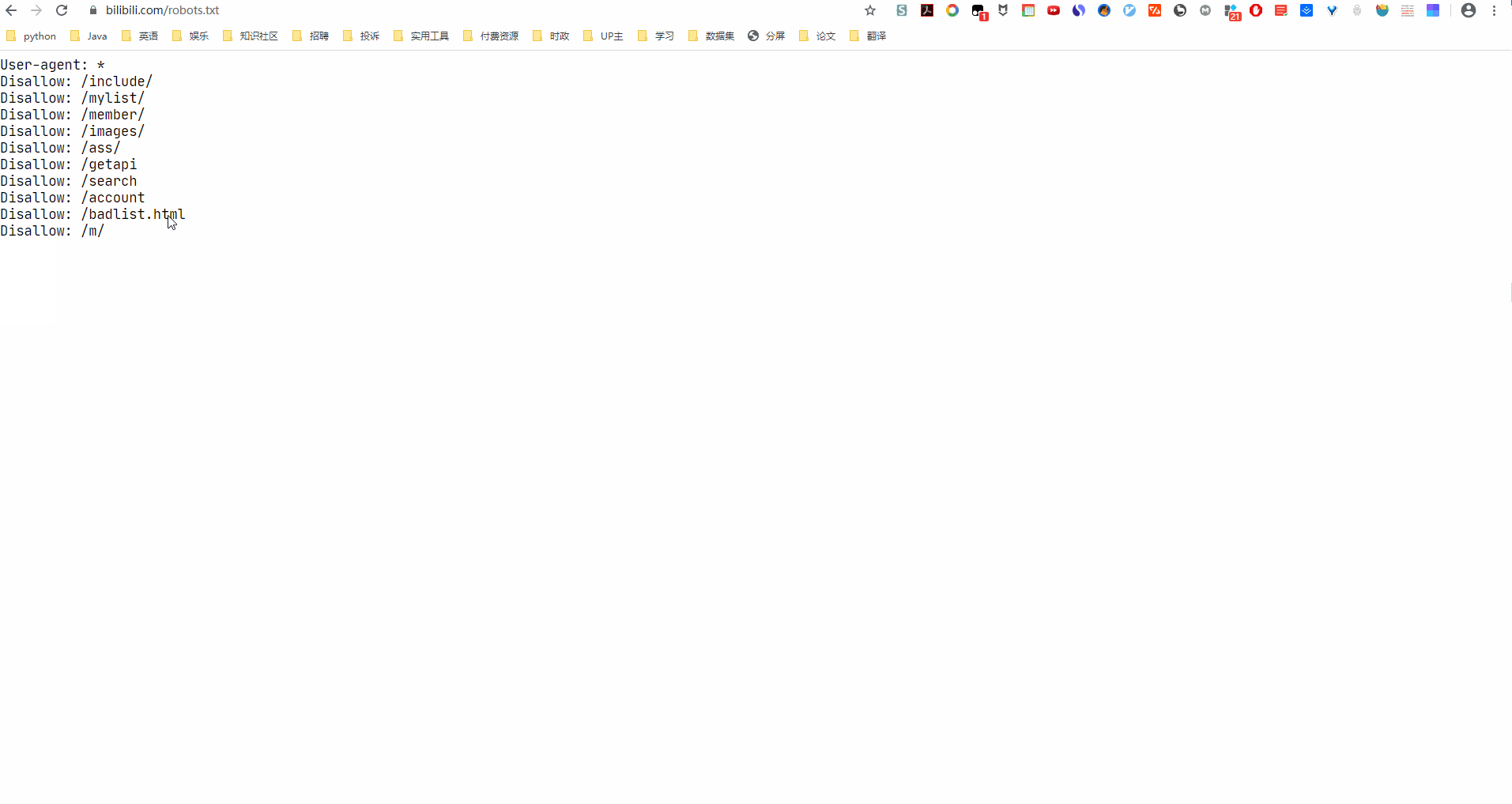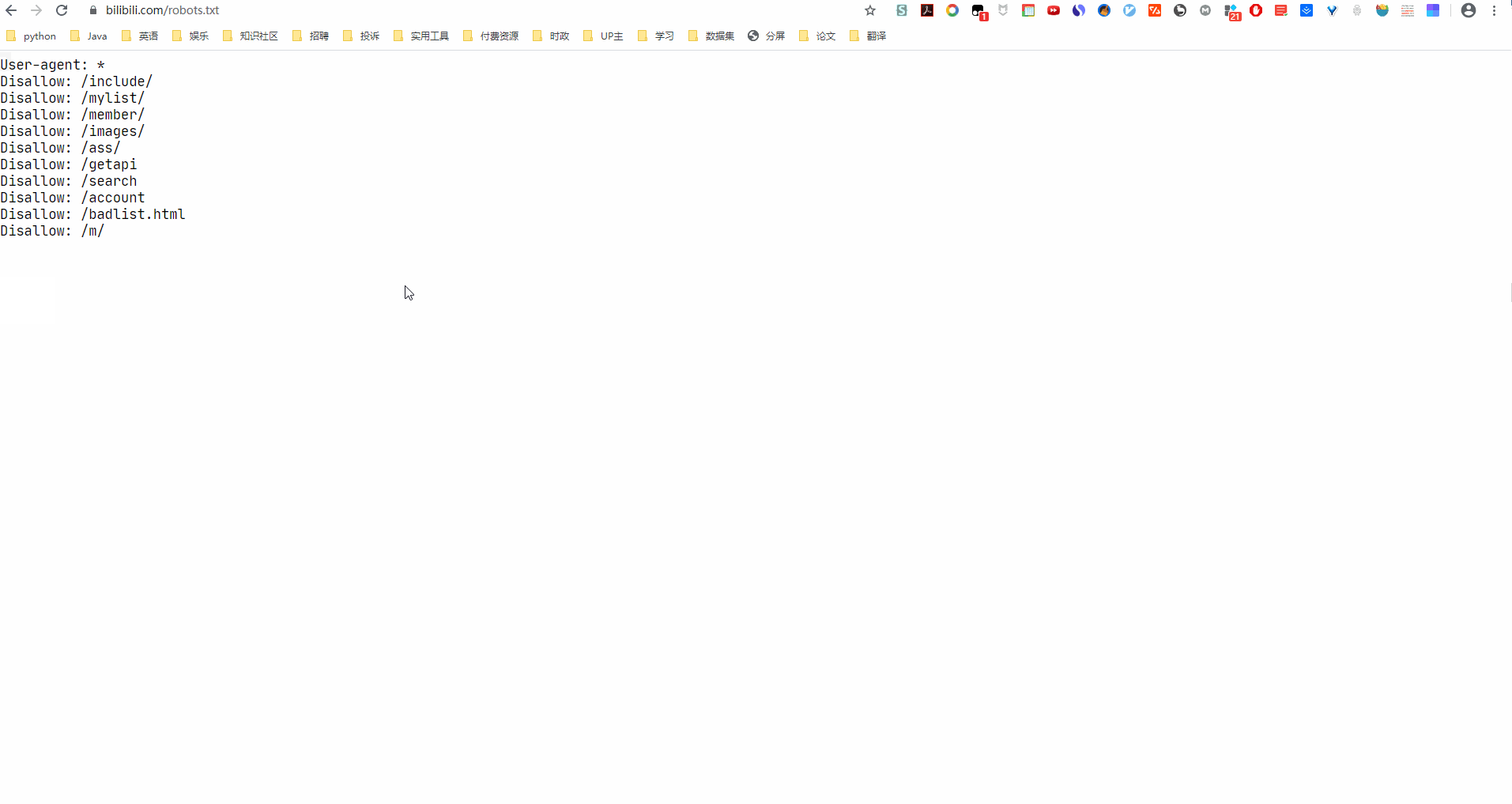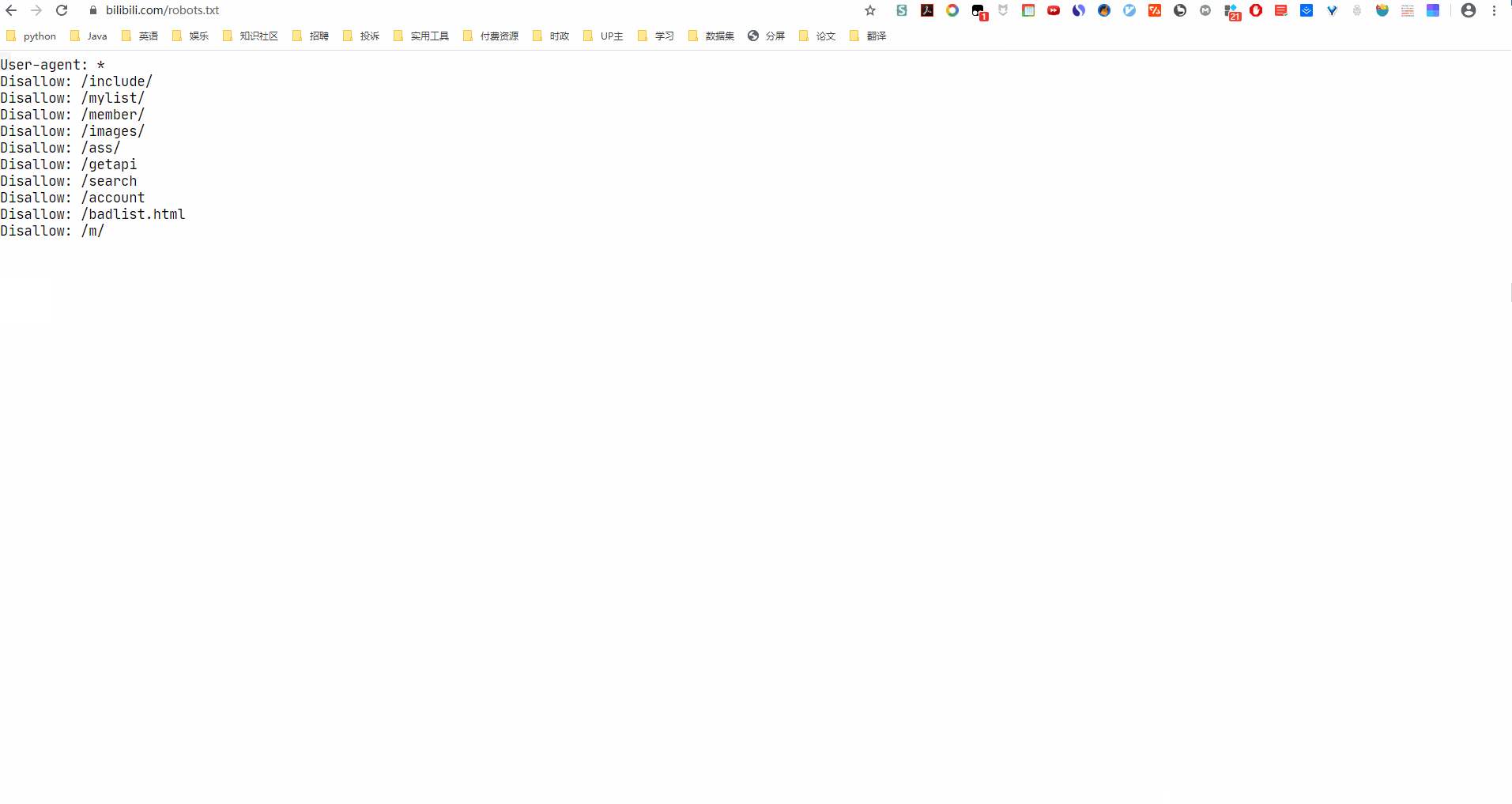
好了,那么我们接下来 构造我们的第一个参数,header。
我们为什么要设置header这个参数呢?header是我们的浏览器在浏览时提交给网站服务器关于自身浏览器的信息,而我们使用python作为爬虫的时候,给出的header是python,而这样会导致网站服务器直接认出我们是一个爬虫。直接不返回数据,或者返回错误数据。因此,header是我们爬虫要设置的第一个参数。
header的数据可以通过在浏览器查看自己的header。我们一般添加User-Agent信息。
另外,也可以通过三方包fake-useragent进行实例化User-Agent,不过国内可能无法得到fake-useragent的实例化对象,可以在网上找找。或者参考以下文章:https://blog.csdn.net/jiduochou963/article/details/90383692
ok,我们设置了第一个参数headers之后,可以尝试着爬取一小部分的信息了,我们使用如下网站:开心一刻笑话:http://xiaodiaodaya.cn/article/view.aspx?id=7436
import requests
from fake_useragent import UserAgent
url = 'http://xiaodiaodaya.cn/article/view.aspx?id=7436' # 请求网址
headers = {'User-Agent': UserAgent().random} # 设置header参数
response = requests.get(url, headers=headers) # 发送请求并将接收到的数据作为response
response.encoding = 'utf-8' # 设置返回数据的编码为utf-8可以查看中文
print(response.text) # 打印输出text内容
import requests
from fake_useragent import UserAgent
url = 'http://xiaohua.zol.com.cn'
headers = {'User-Agent': UserAgent().random}
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
print(response.text)
2.3.3 设置爬取时间间隔
当我们使用爬虫爬取网站时,如果不设置爬虫间隔时间,可能会导致短时间内大量访问网站,导致网站服务器崩溃,或者被网站服务器检测到异常直接封掉IP。因此,为了减少爬取的次数,我们可以设置一次爬虫的间隔时间,可以使用time这个自带的包,设置sleep()休眠时间。如此,就可以杜绝短时的大量访问情况了。
import requests
from fake_useragent import UserAgent
from time import sleep
url = 'http://xiaohua.zol.com.cn'
headers = {'User-Agent': UserAgent().random}
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
print(response.text)
sleep(2)
一般而言,需要时间间隔的爬虫,都有较大数目的循环爬取,而我们上方的代码实际上只爬取了一次,因此可以不用时间间隔。我目前也没有什么要大量爬取的数据,所以就写了一下如何进行设置,而不是完全的演示。
2.3.4 代理IP
我们注意到了构建一个健康的爬虫,并且也设置了header和时间间隔。然而,有可能网站的服务器反爬算法还是监测到了我们的爬虫程序。虽然一般来说不会出现封IP的现象,但是不可否认的是可能会出现封IP的情况。所以,我们可以通过设置代理IP的方式进行访问。
import requests
from fake_useragent import UserAgent
url = 'http://httpbin.org/get'
headers = {'User-Agent': UserAgent().random}
proxies = {
"http": "http://140.246.30.24:3828"
}
response = requests.get(url, headers=headers, proxies=proxies, stream=True)
response.encoding = 'utf-8'
print(response.raw._connection.sock.getpeername()[0])
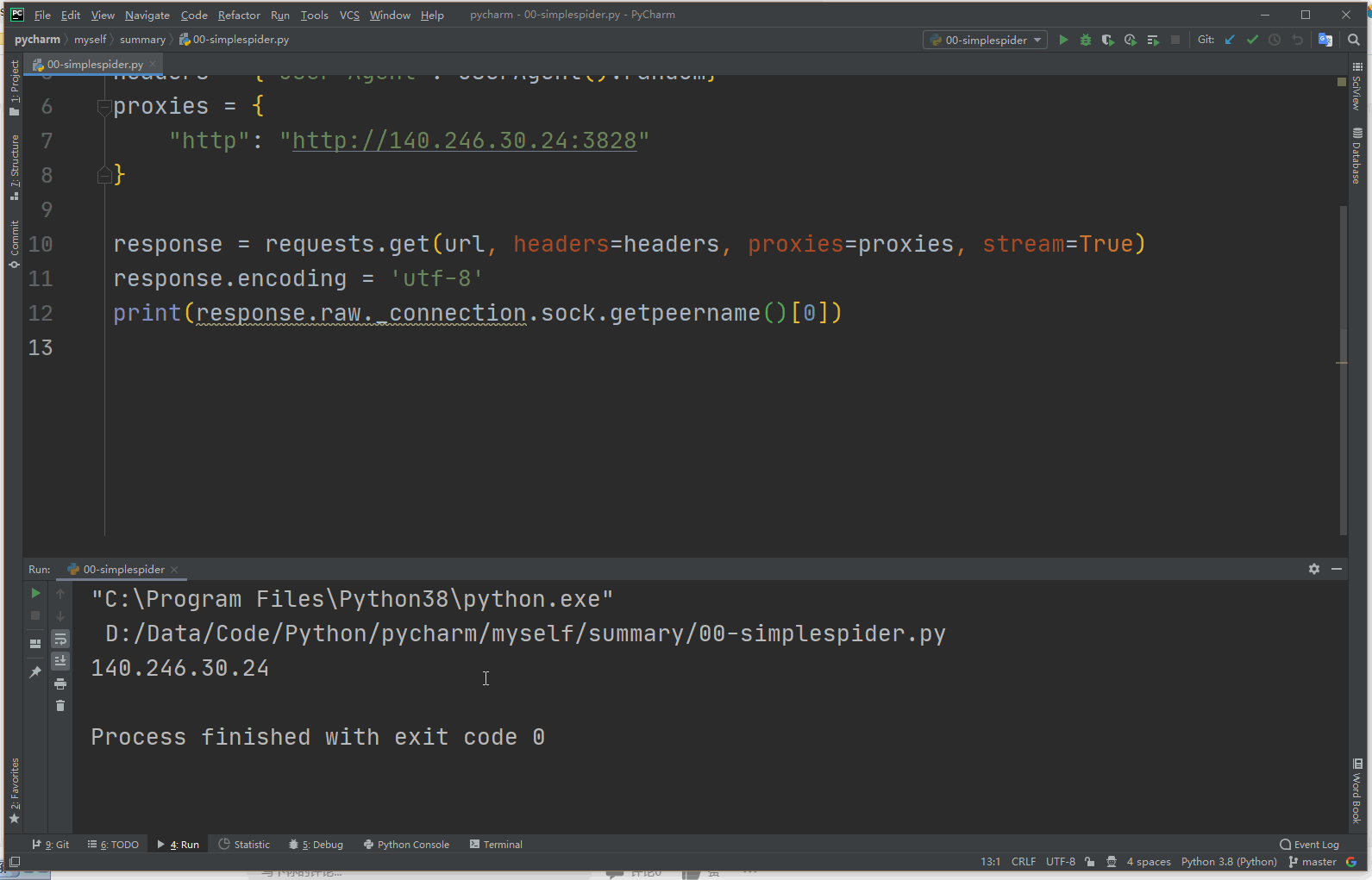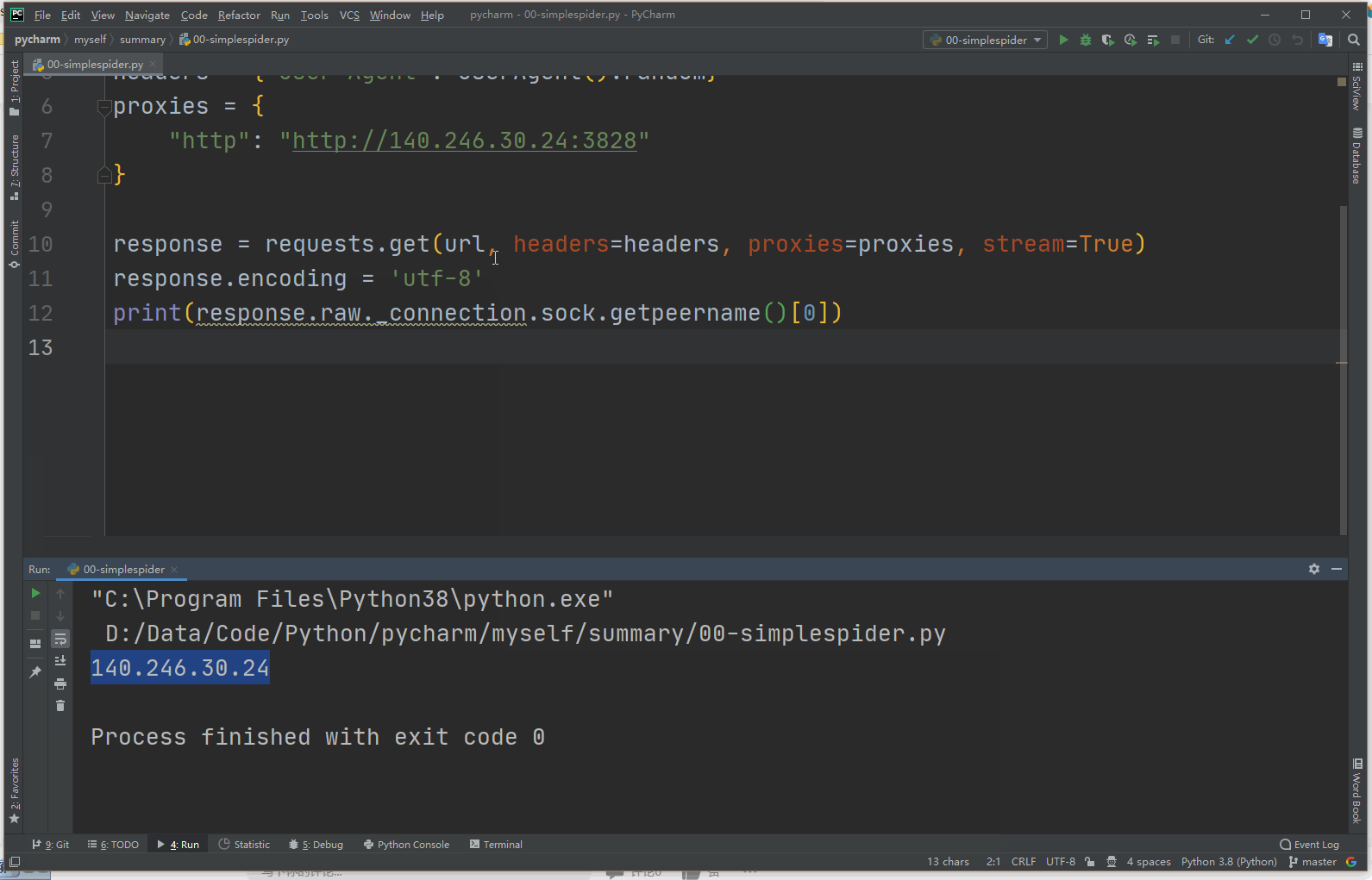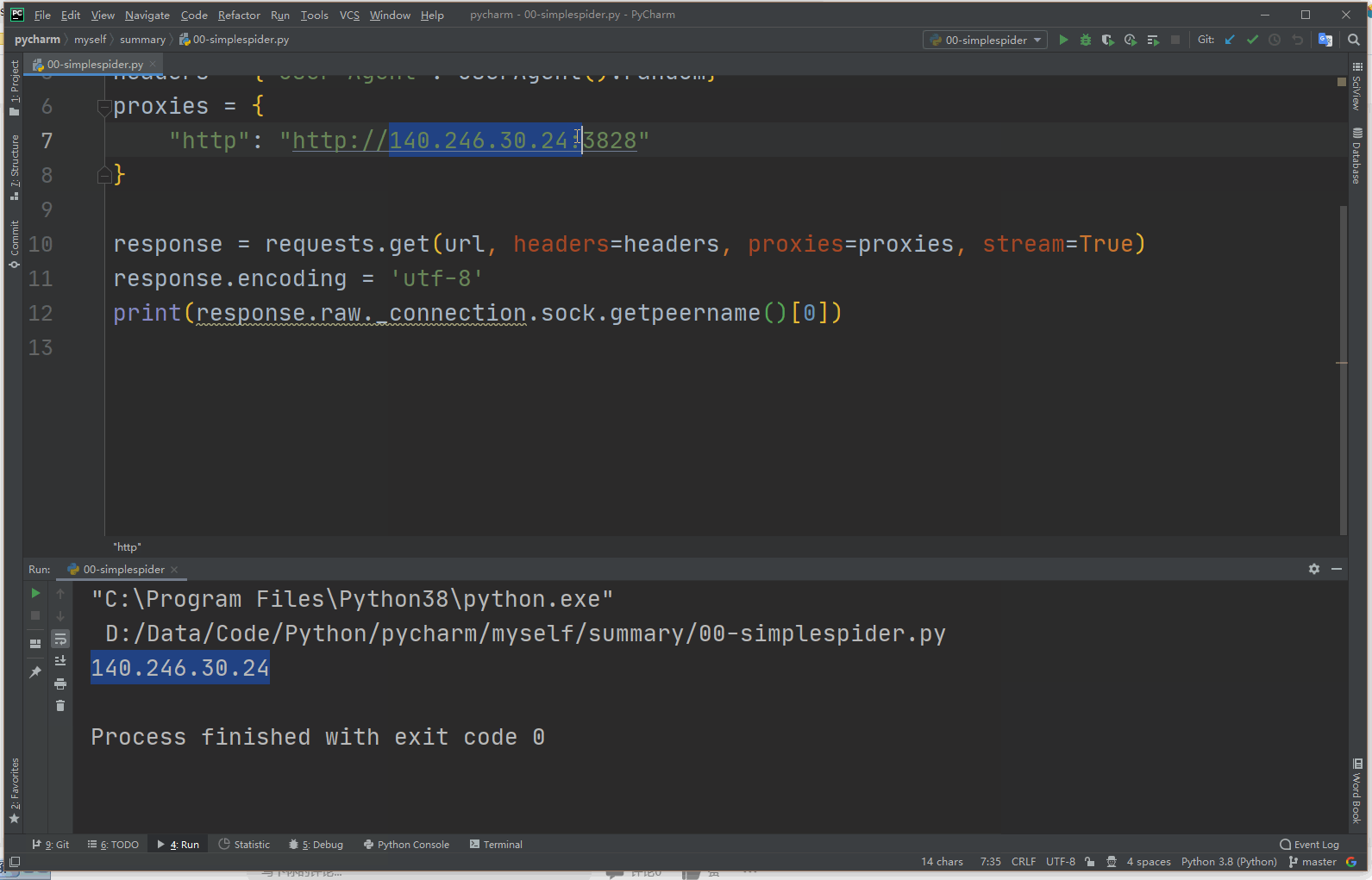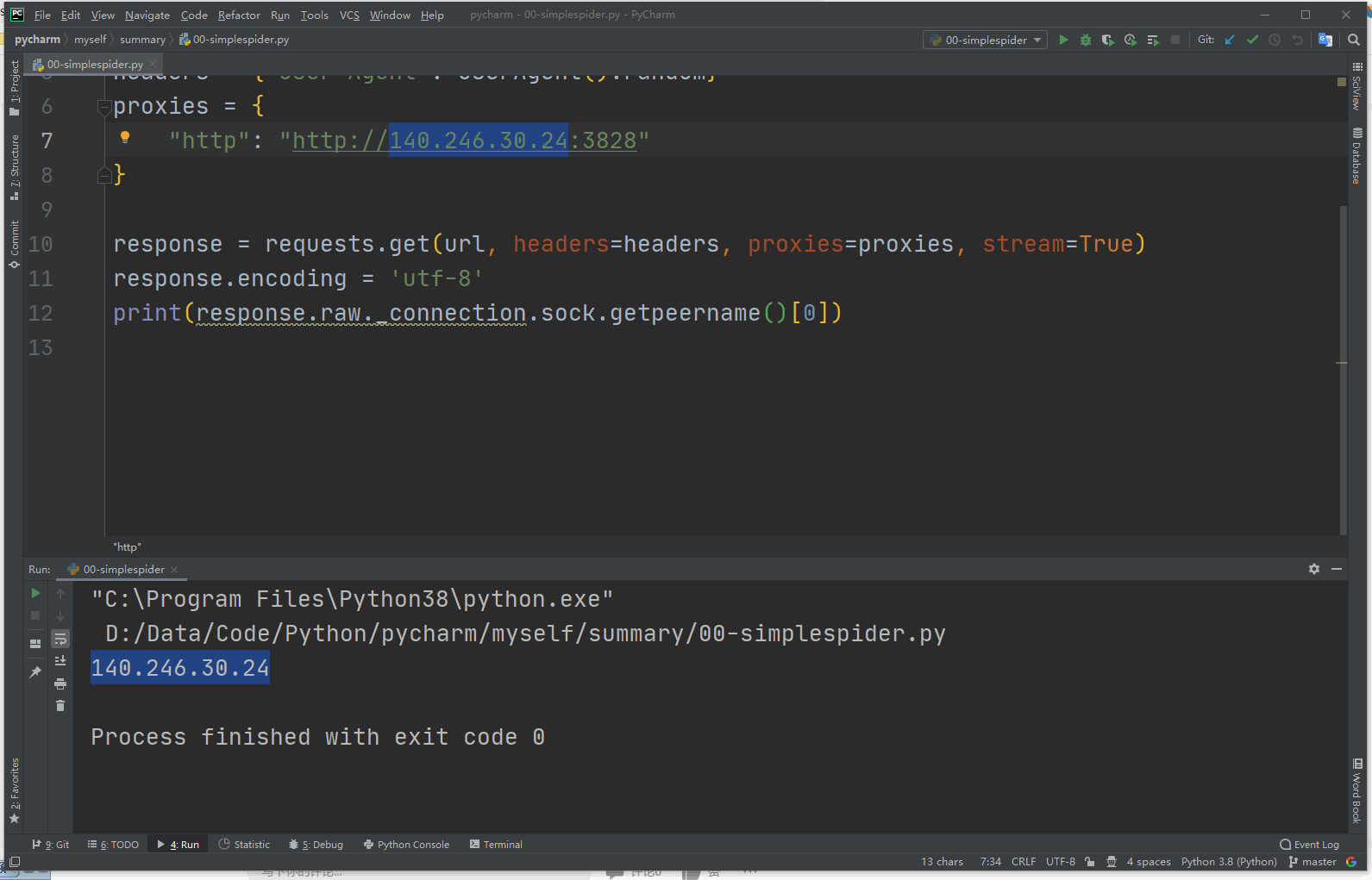
如果是你购买的的ip的话,输入ip的时候就需要输入你的用户名和密码。另外,代理为百度而来,所以可能已失效。
import requests
from fake_useragent import UserAgent
url = 'http://httpbin.org/get'
headers = {'User-Agent': UserAgent().random}
proxies = {
"http": "http://user:[email protected]:3828/"
}
response = requests.get(url, headers=headers, proxies=proxies, stream=True)
response.encoding = 'utf-8'
print(response.raw._connection.sock.getpeername()[0])
2.3.5 输入cookies
爬虫不得不说的一种情况就是现今大多数网站都加入了验证机制。如果你只是短时间要用一下的话,完全可以自己先登录,登录之后再从浏览器拿到自己的cookies信息,将cookies信息传入到爬虫程序中,如此就可以实现短时间的内容爬取。
例如,我们要爬取猫眼电影,现今猫眼电影使用加入了美团验证,爬虫一旦遇上验证的话,就会直接歇菜。除非你进行了相应的设置,因此我们使用cookies的方式进行短时爬取。
这一次的运气很好啊,我们没有碰上验证中心,不过总是有可能翻车的嘛,所以我们还是加上cookies吧。
加入cookies除了用于验证外,也可用于登录用户的验证。因此,cookies的处理也是较为重要的。
2.3.6 动态数据
我们目前使用requests获得的数据都是静态网页数据,也就是说数据都在HTML结构里面。然而,有可能我们使用爬虫爬取的数据是动态数据,也就是JavaScript渲染的数据。因此,我们可以使用selenium进行动态渲染后,再进行数据的爬取。这一部分放在后面介绍,现在先有个概念就行了。
3. 爬虫信息提取
我们见面介绍的requests库的get方法和各种参数的添加,都只拿到了整个网页信息。如同我们前面的Gif动态图中展示的一样,我们每次爬到的数据都是整个HTML页面的数据,这样的数据如果不经过处理虽然人眼依旧可以找到我们想要的数据。但是,当数据量很大之后,这样的效率实在是太低了,为了提高效率。我们介绍以下几种数据提取方法。
3.1 xpath选择器
| 命令 | 作用 |
|---|---|
| / | 从根节点开始选取数据 |
| // | 从任意满足条件的节点选取数据 |
| . | 当前节点 |
| .. | 上一个节点 |
| /[@属性='值'] | 根据属性值选取数据 |
| /@属性 | 获得某个属性的值 |
| /text | 获得文本内容 |
| /标签[i] | 获得该标签的第i个的内容 |
| /标签[last()-i] | 获得该标签的倒数第i+1个的内容 |
| /* | 获得某个路径下所有的标签 |
| /@* | 获得某个标签下的所有属性内容 |
比如我们要获得这个笑话下面的内容:http://xiaohua.zol.com.cn/detail60/59364.html
import requests
from fake_useragent import UserAgent
from lxml import etree
url = 'http://xiaohua.zol.com.cn/detail60/59364.html'
headers = {
'User-Agent': UserAgent().random
}
response = requests.get(url, headers=headers)
response.encoding = 'gbk'
# 实例化HTML对象
html = etree.HTML(response.text)
# 取出笑话数据
jokes = html.xpath("//div[@class='article-text']/p")
# 遍历所有的笑话变量,取出每一个的text属性
for joke in jokes:
print(joke.text)
3.2 css选择器
| 命令 | 作用 |
|---|---|
| .值1 | class属性的值为值1 |
| #值1 | id属性的值为值1 |
| 标签1,标签2 | 选择标签1和标签2 |
| 标签1 标签2 | 标签1 下面的 标签2 |
| 标签1 > 标签2 | 标签1 下面的 标签2 |
| [属性1] | 获得所有具有属性1的标签 |
| [属性1='某个值'] | 获得所有属性1的值为某个值的标签 |
| 标签:nth-child[i] | 标签下的第几个节点(子节点) |
| 标签:nth-last-child[i] | 标签下的倒数第几个节点(子节点) |
| 标签:last-child | 标签的最后一个子节点 |
| 标签.get_attribute('属性名') | 获得某个标签下的属性名这个属性的值 |
- 依旧是爬取同一个笑话的内容,首先安装pyquery三方包。
from pyquery import PyQuery as pq from fake_useragent import UserAgent url = 'http://xiaohua.zol.com.cn/detail60/59364.html' headers = { 'User-Agent':UserAgent().random } datas = pq(url=url,headers=headers) jokes = datas('div.article-text p') for joke in jokes: print(joke.text)
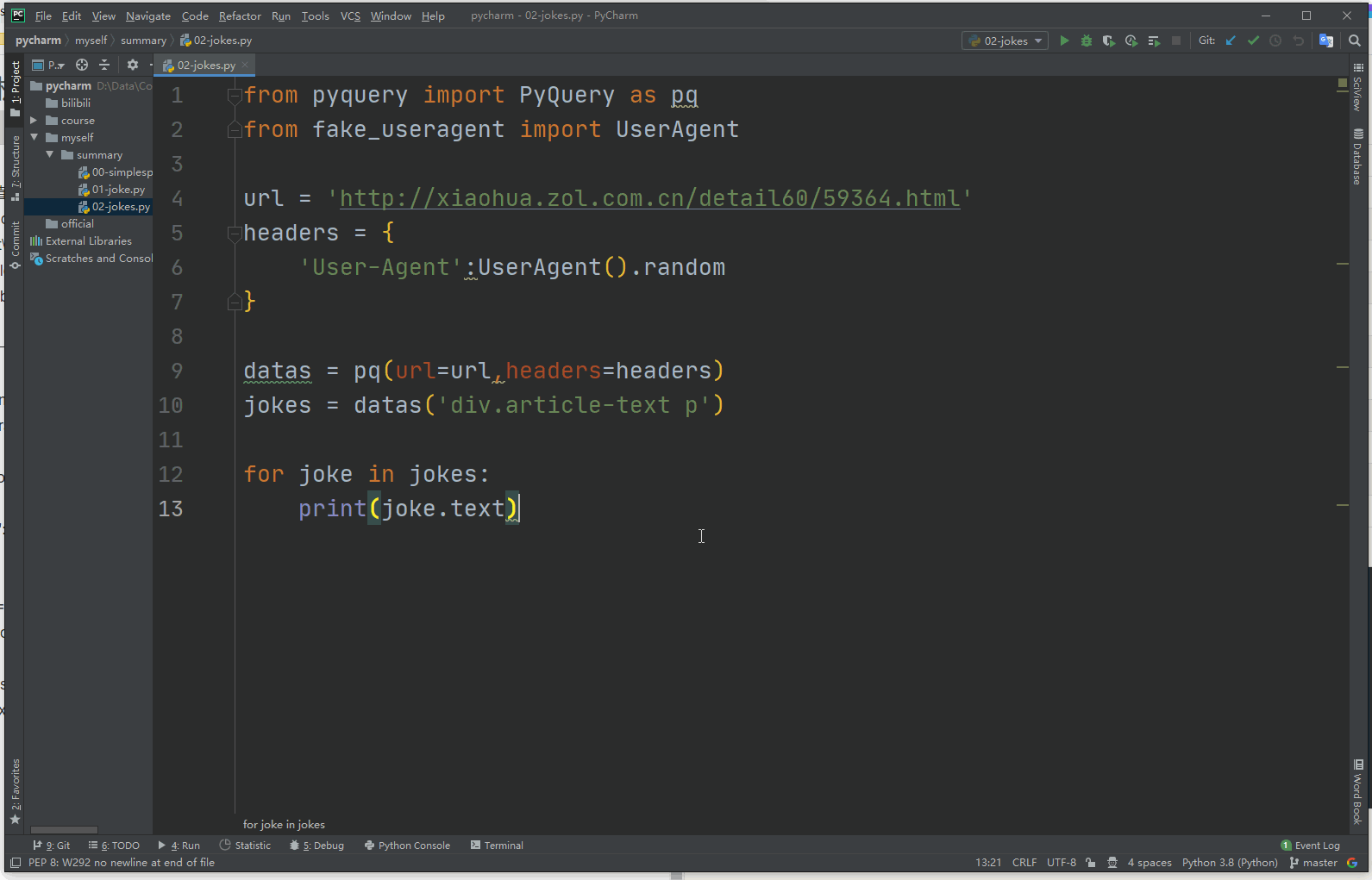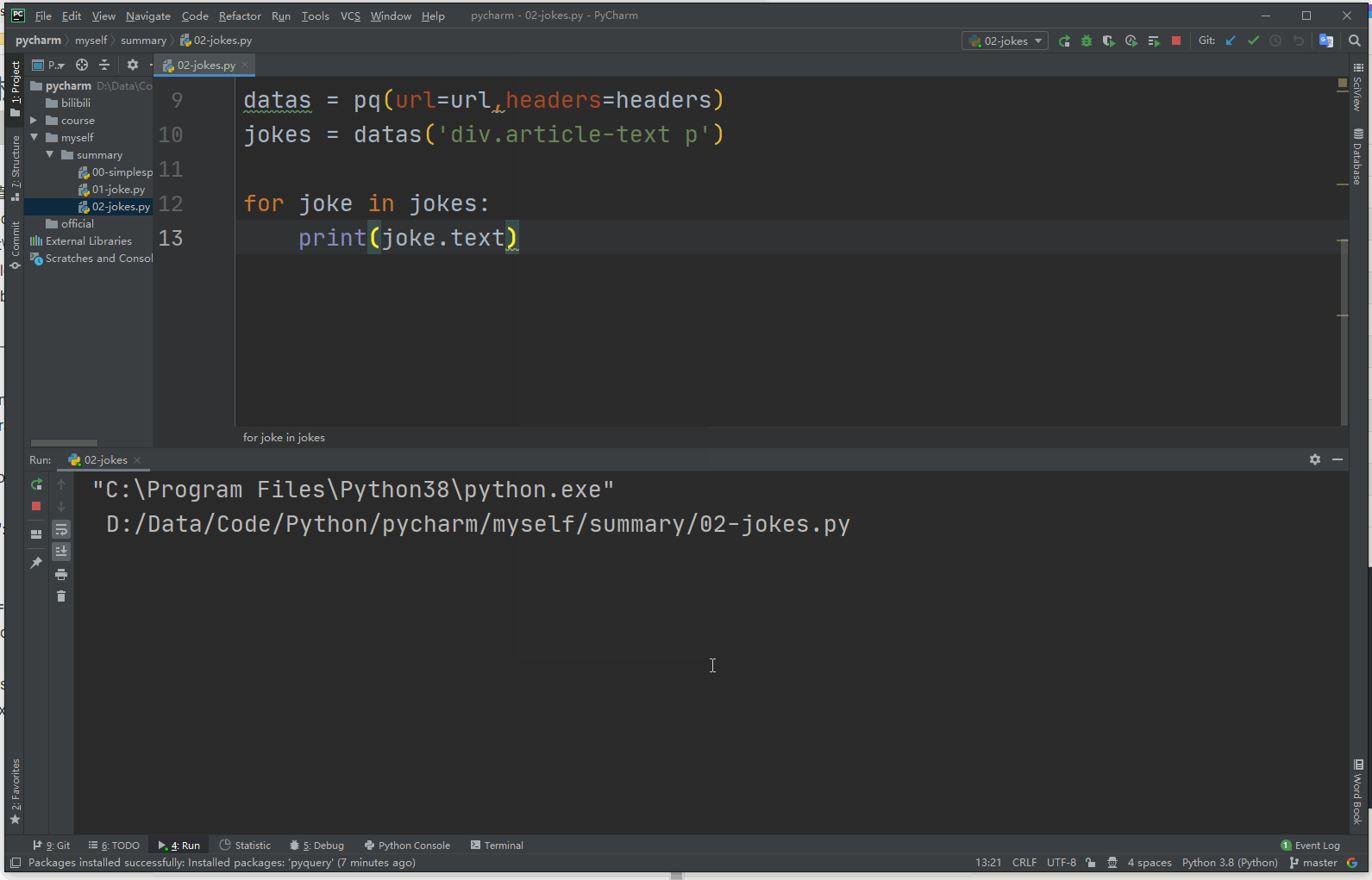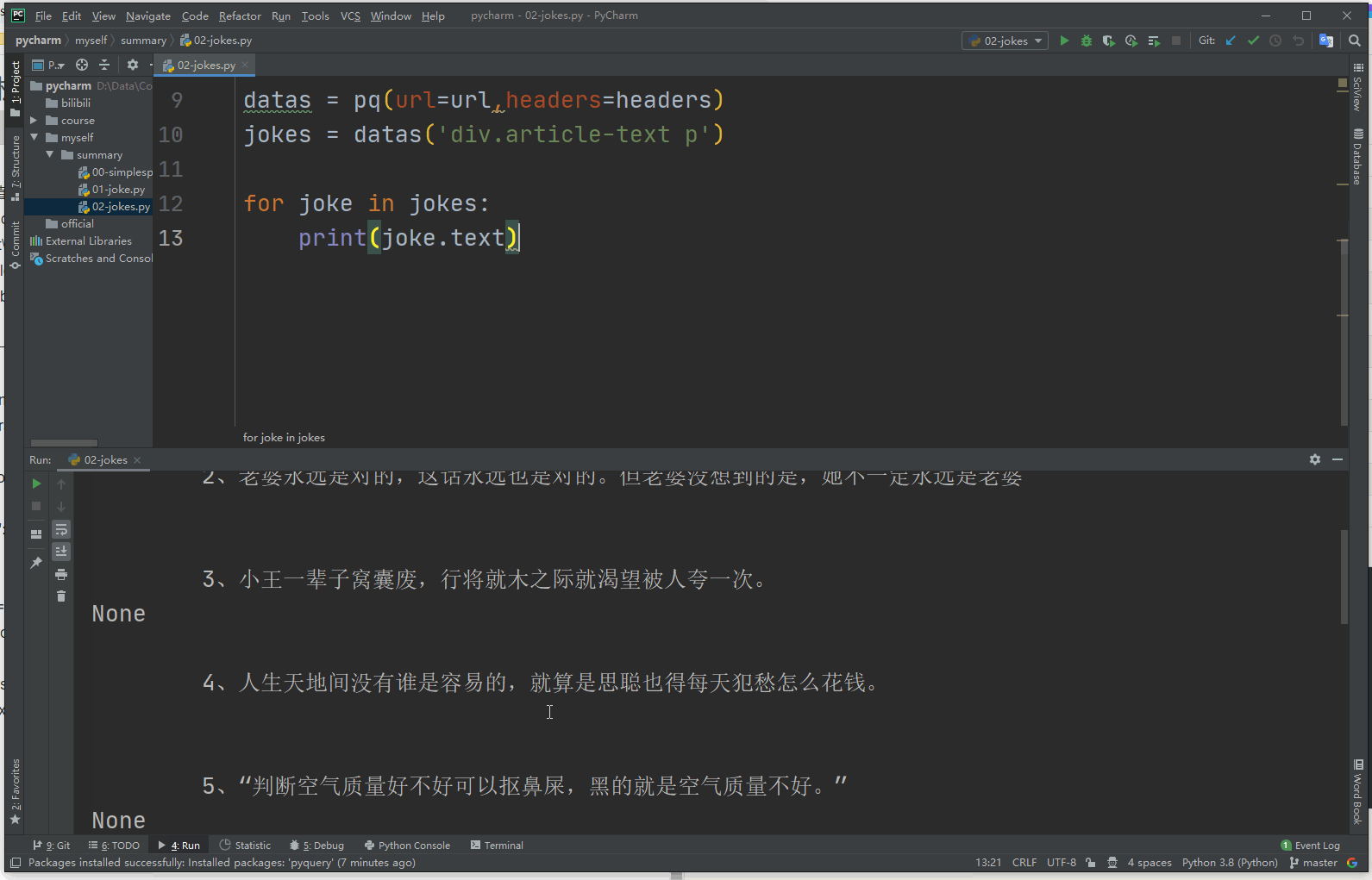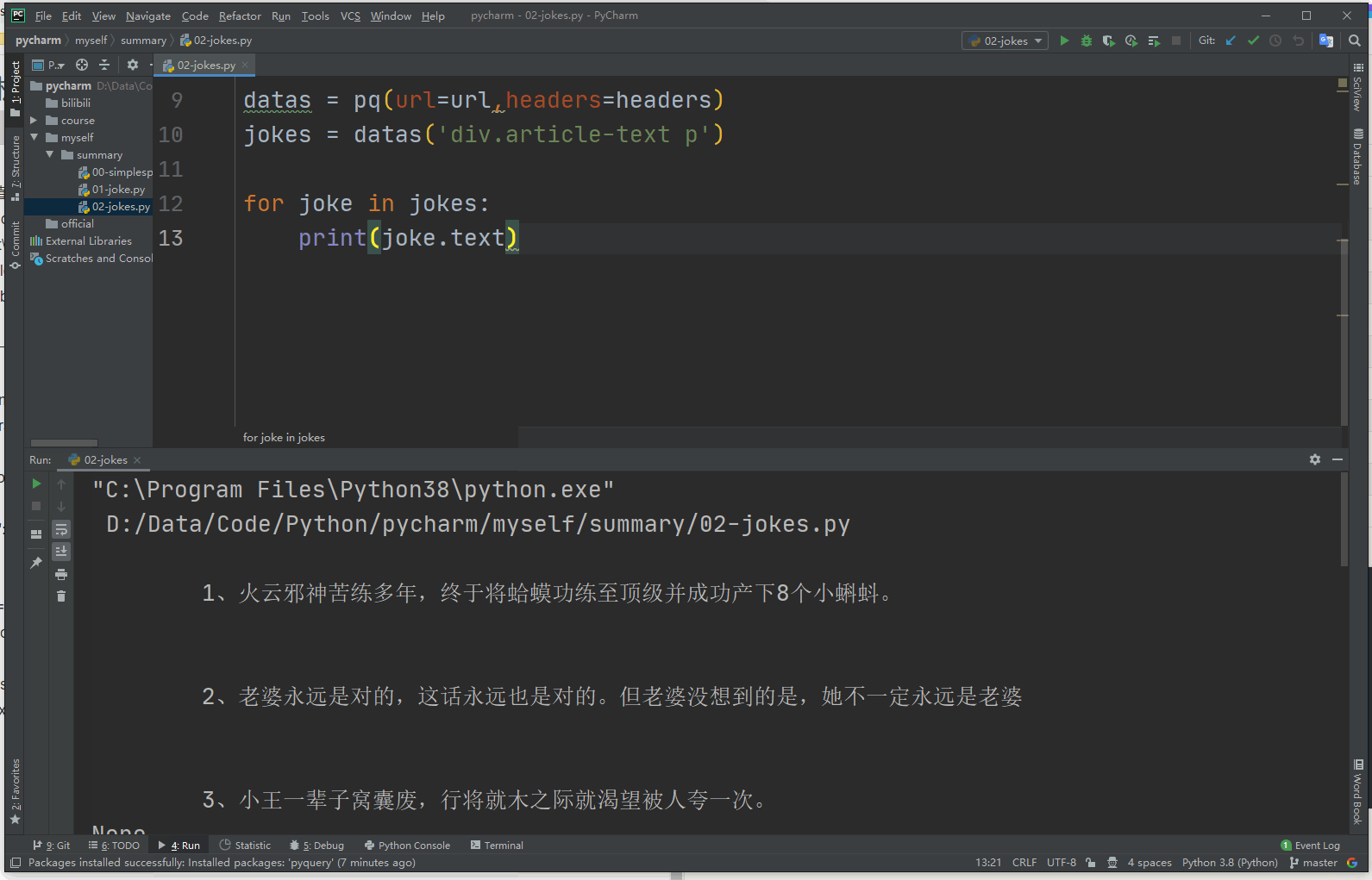
3.3 beautifulsoup选择器
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | 1. Python的内置标准库 2. 执行速度适中 3.文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 1. 速度快 2.文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”]) BeautifulSoup(markup, “xml”) |
1. 速度快 2.唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 1. 最好的容错性 2.以浏览器的方式解析文档 3.生成HTML5格式的文档 4.速度慢 | 不依赖外部扩展 |
| 对象 | 命令 | 作用 |
|---|---|---|
| tag | .标签 | beautifulsoup 文档树的标签,可类比HTML中的双标签进行理解。输出标签及内部的值。 |
| NavigableString | .string | 获取字符串内容 |
| .text | 获取文本内容 | |
| 搜索对象 | find_all('标签名称') | 找到所有的叫做标签名称的标签的内容 |
| find('标签名称') | 找到第一个符合条件的标签及内容 | |
| css选择器 | .select() | 对应的css语法即可,参考上一小部分内容。 |
- 依旧是获取同一个笑话的内容,需要先安装beautifulsoup4这个三方包
import requests from bs4 import BeautifulSoup from fake_useragent import UserAgent url = 'http://xiaohua.zol.com.cn/detail60/59364.html' headers = { 'User-Agent': UserAgent().random } datas = requests.get(url, headers=headers) html = datas.text # 实例化soup对象 soup = BeautifulSoup(html, 'lxml') jokes = soup.find_all('div', attrs={'class':'article-text'}) for joke in jokes: print(joke.text)
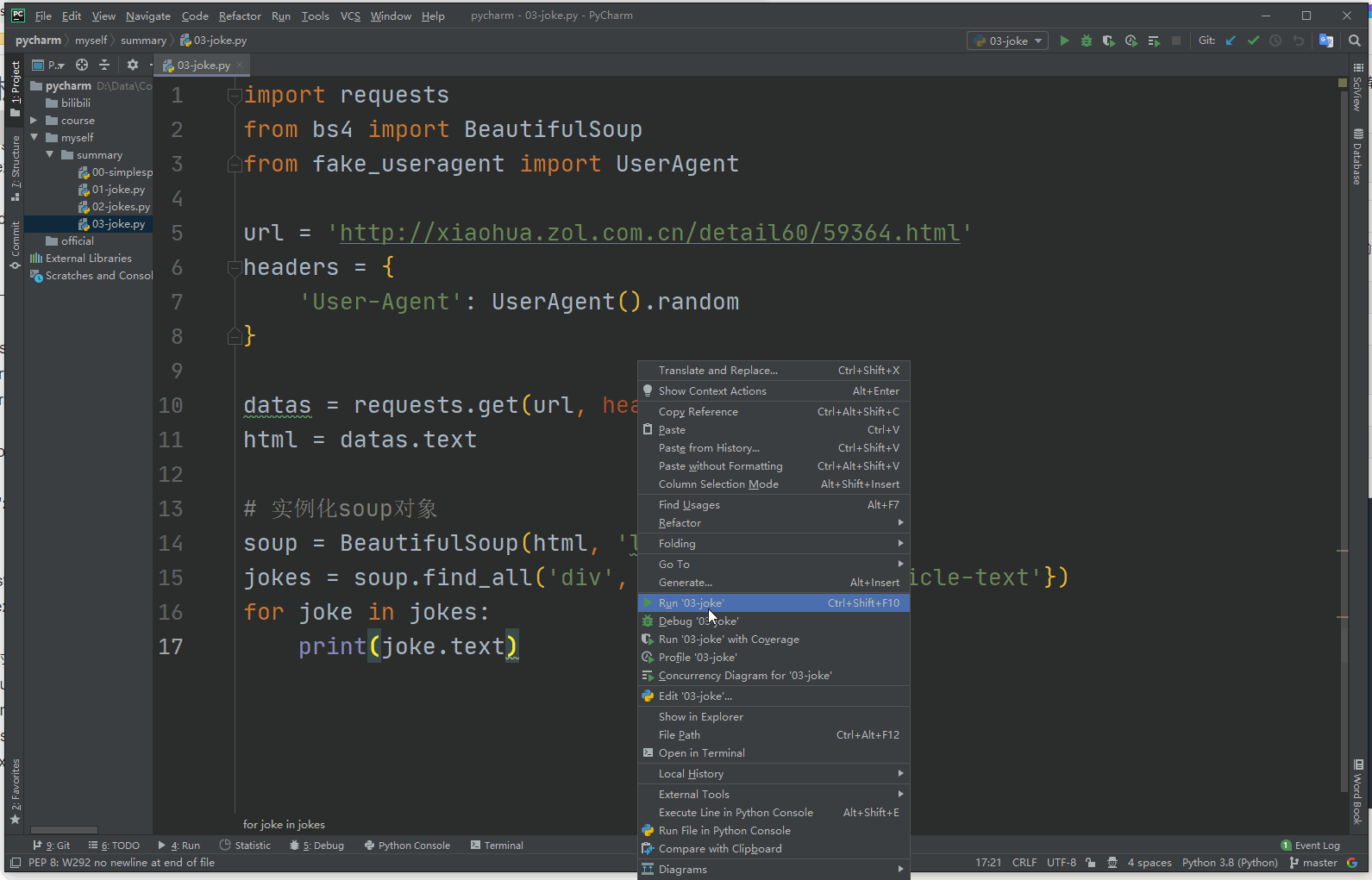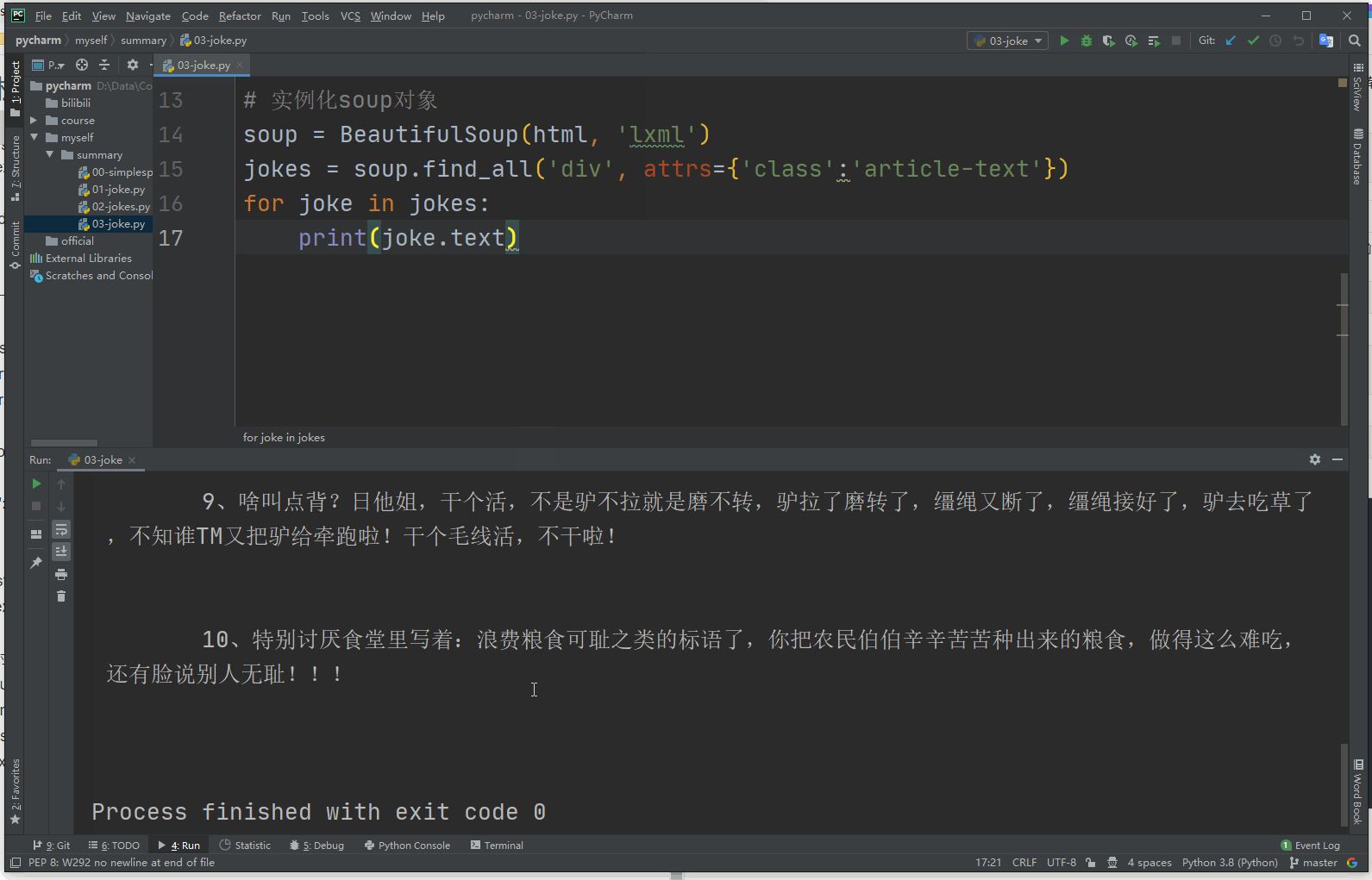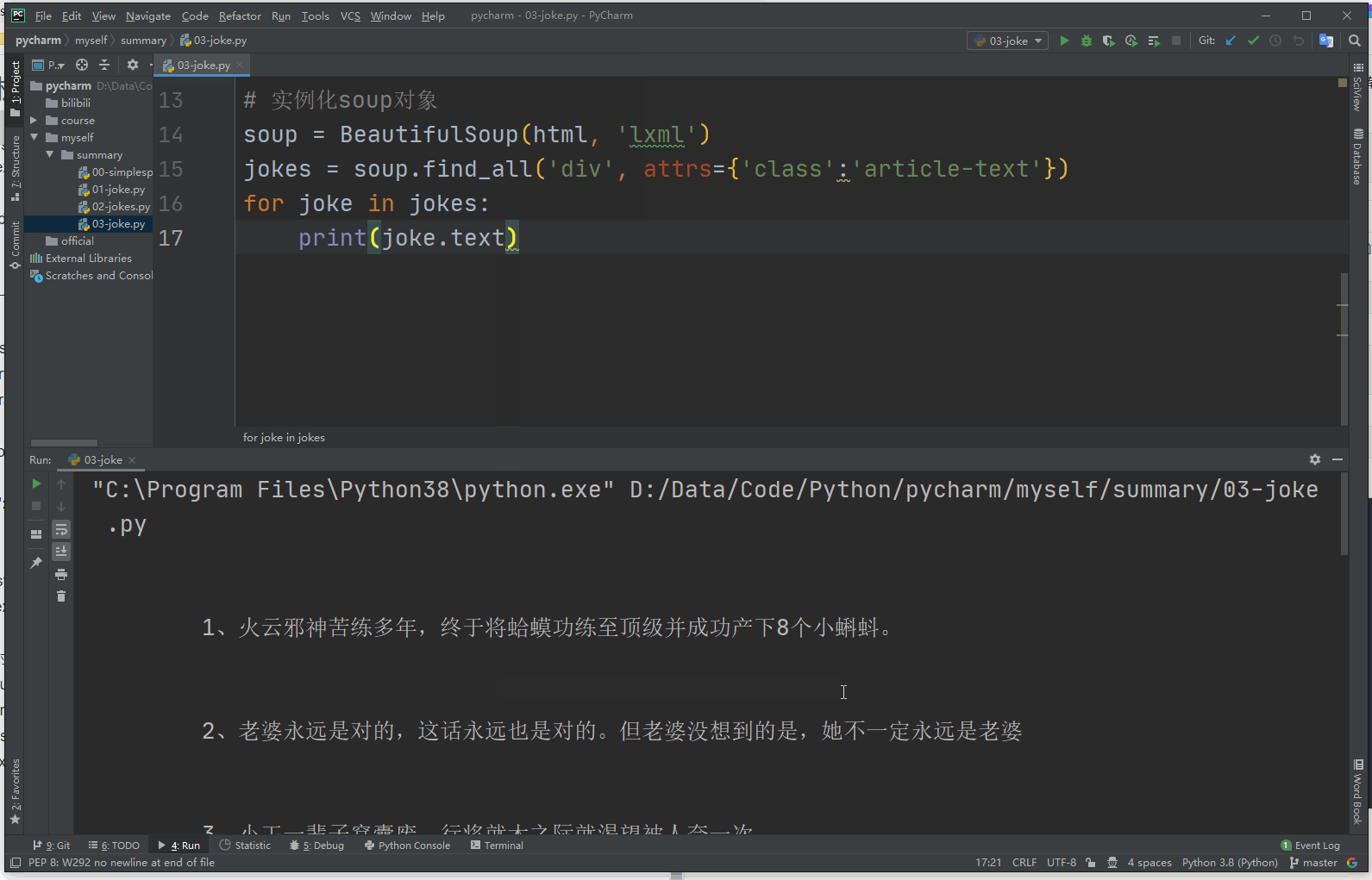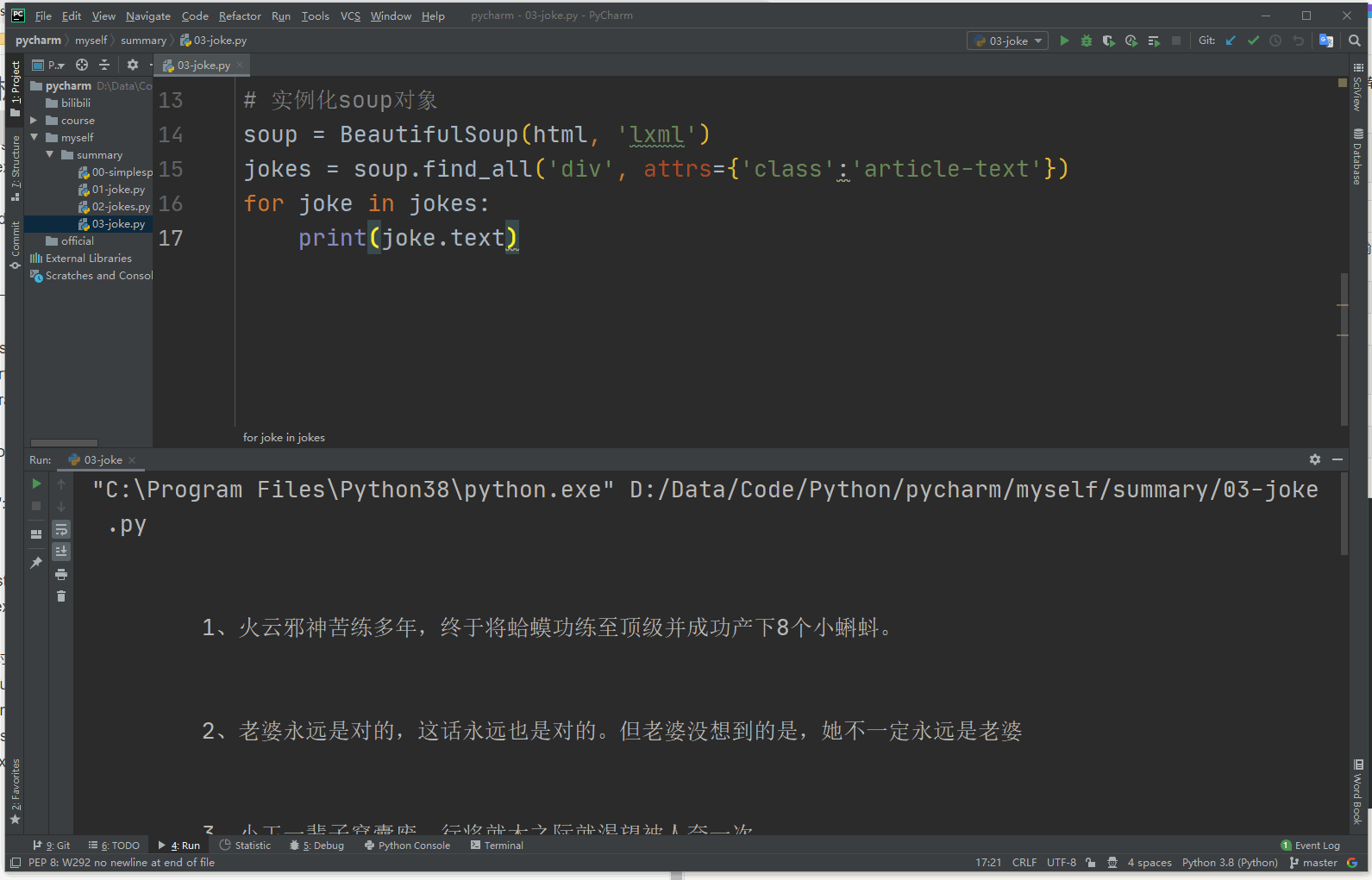
3.4 Python正则表达式
| 命令 | 说明 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| . | 匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 |
| [...] | 用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k' |
| [^...] | 不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符 |
| * | 匹配0个或多个的表达式 |
| + | 匹配1个或多个的表达式 |
| ? | 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式 |
| { n} | 前面的表达式出现n次 |
| { n,} | 前面表达式至少出现n次 |
| re{ n, m} | 前面的正则表达式出现n到m之间次 |
| a | 匹配为a字符 |
| () | 括号内的表达式,表示一个组 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符,等价于 [\t\n\r\f]. |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字,等价于 [0-9] |
| \D | 匹配任意非数字 |
| \A | 匹配字符串开始 |
| \Z | 匹配字符串结束,如果是存在换行,只匹配到换行前的结束字符串。c |
| \z | 匹配字符串结束 |
| \G | 匹配最后匹配完成的位置 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er' |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er' |
| \n, \t, 等. | 匹配一个换行符。匹配一个制表符。等 |
| \1...\9 | 匹配第n个分组的内容 |
| \10 | 匹配第n个分组的内容,如果它经匹配。否则指的是八进制字符码的表达式 |
| [\u4e00-\u9fa5] | 中文 |
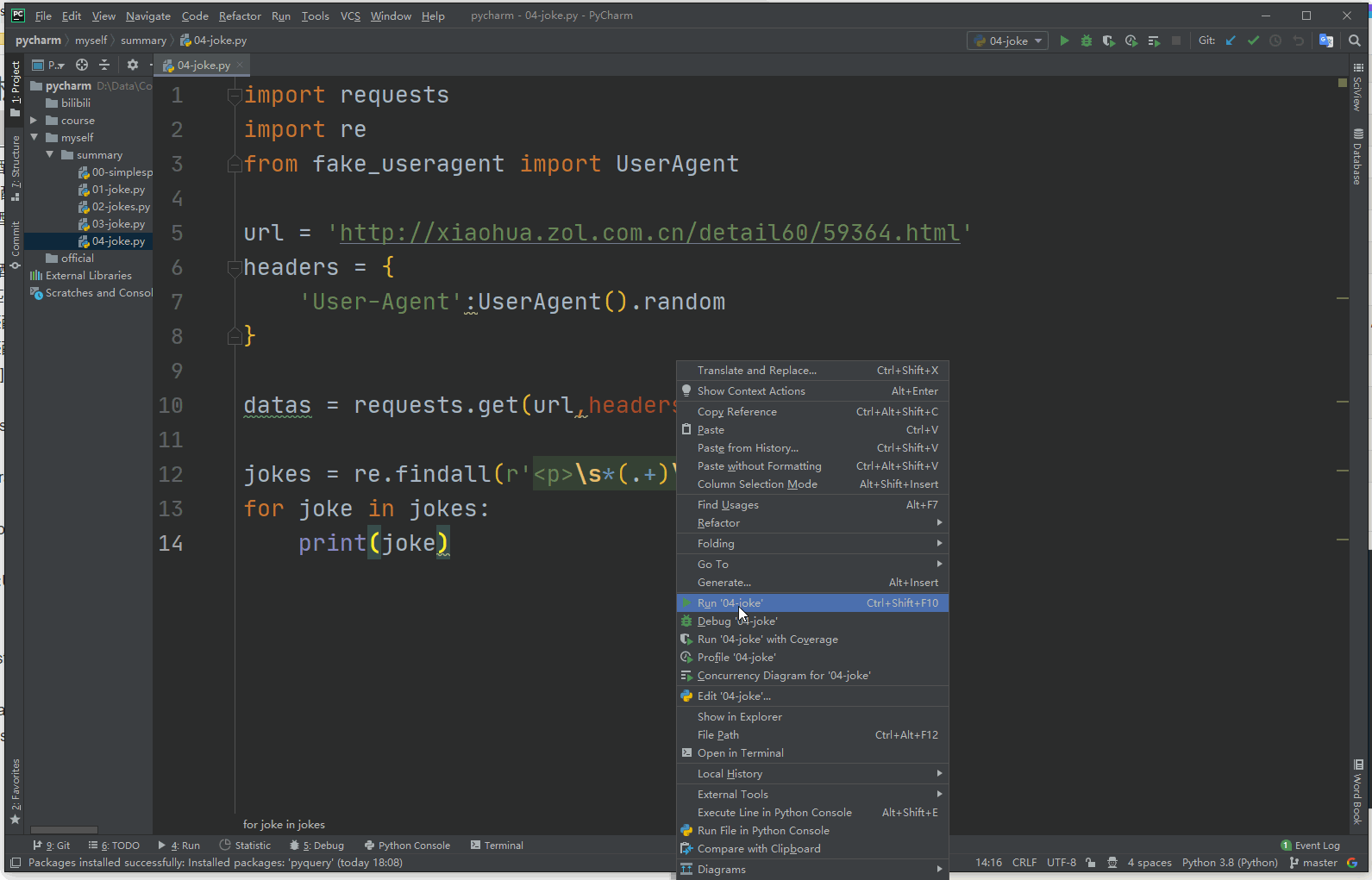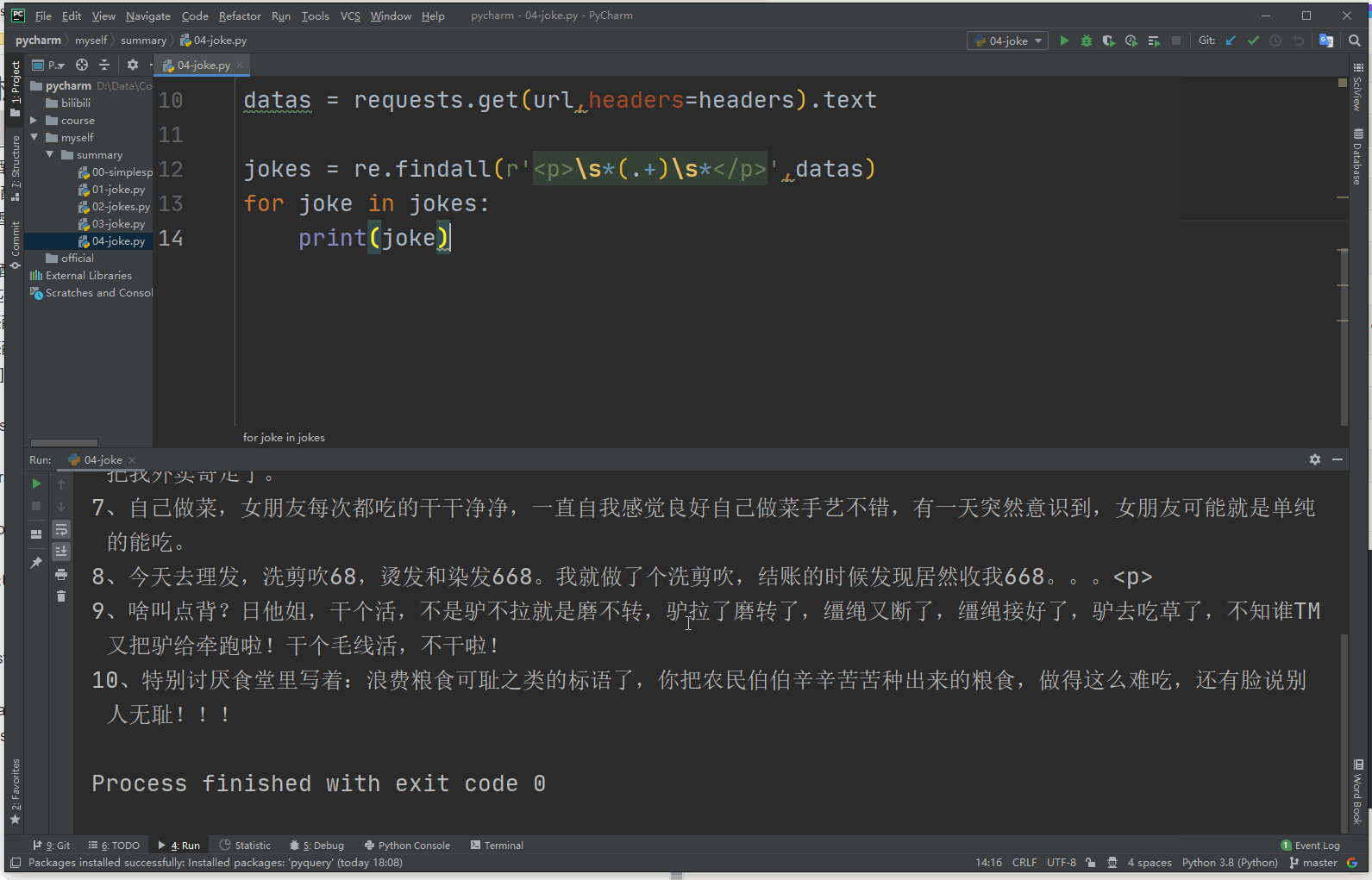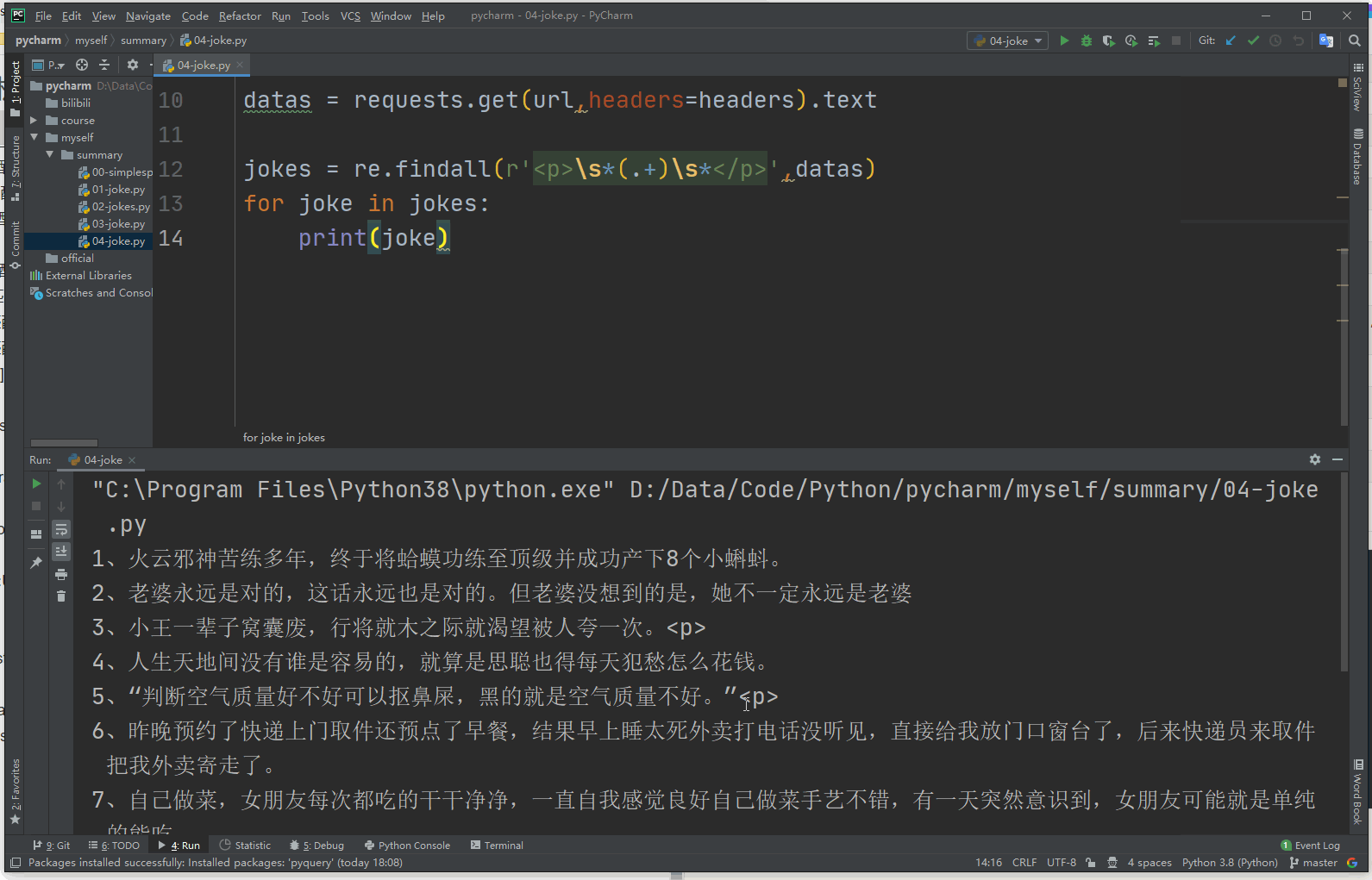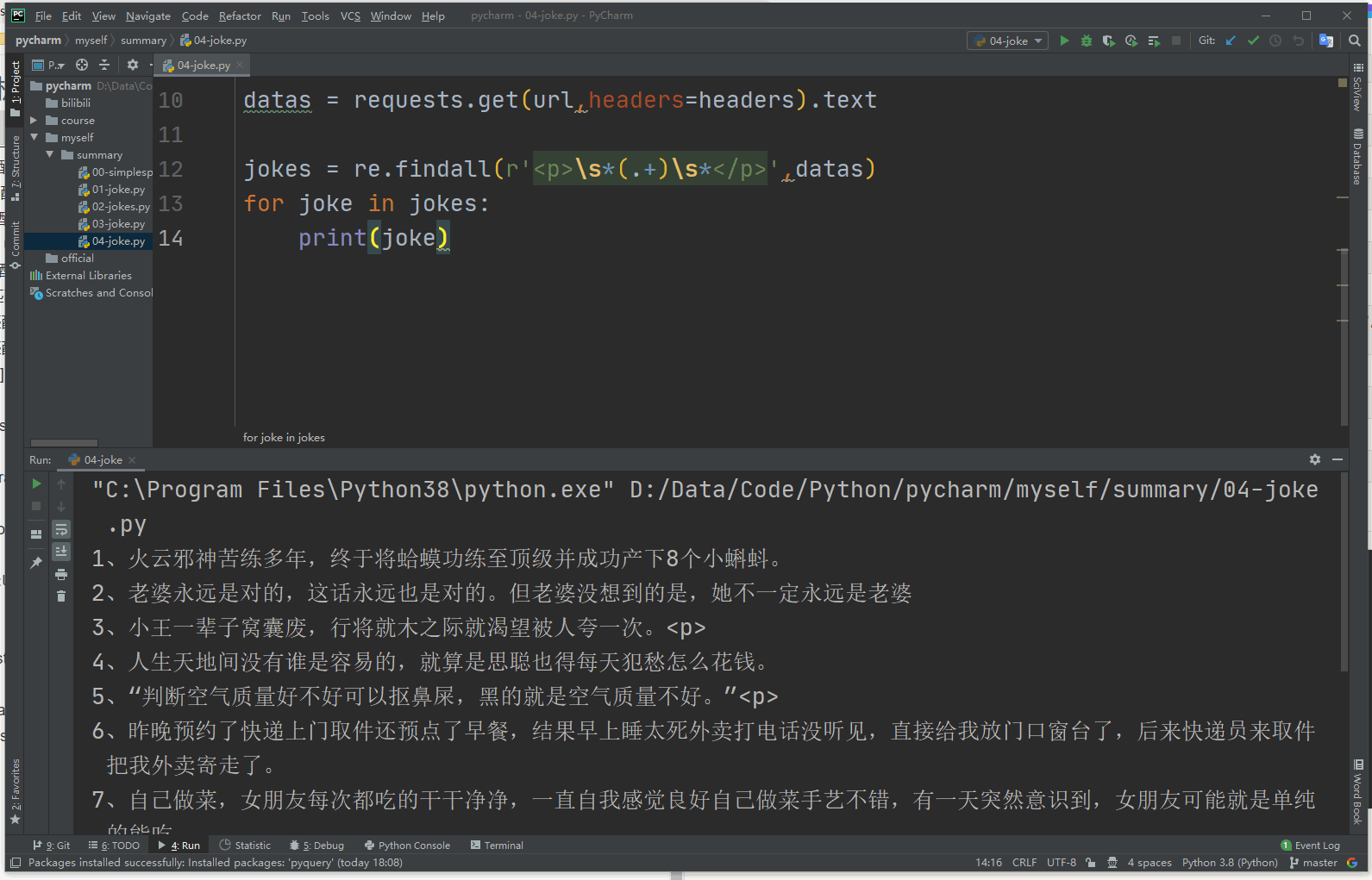
import requests
import re
from fake_useragent import UserAgent
url = 'http://xiaohua.zol.com.cn/detail60/59364.html'
headers = {
'User-Agent':UserAgent().random
}
datas = requests.get(url,headers=headers).text
jokes = re.findall(r'\s*(.+)\s*
',datas)
for joke in jokes:
print(joke)
4. 实例
经过第2部分的参数设置,第3部分的信息提取,现在我们已经能够将静态页面想要爬取的数据全部爬取出来了。所以,我们现在来做一个案例吧。
案例:爬取哔哩哔哩的每日排行榜
还记得我们前面说过的爬虫套路么?现在可以ctrl+Home回到首页看看有哪些套路哦,我们按照这个套路来爬去我们的哔哩哔哩视频网站的每日排行榜吧。
- 首先我们要找到哔哩哔哩的每日排行版的url界面,拿到url。
https://www.bilibili.com/ranking](https://www.bilibili.com/ranking - 提取那些数据
F12可以查看网页HTML代码哈。所以,我们对页面分析之后确定我们要拿'标题', '排名', '得分', '播放量', '热度', 'up', 'upid', '视频地址' - 如何提取
我们可以使用上述介绍到的多种方法进行数据提取哦,我这边就选用xpath和beautifulsoup两种方式进行讲解。 - 接下来就是编码了。
- beautifulsoup提取信息
import requests from bs4 import BeautifulSoup import csv from datetime import datetime url = 'https://www.bilibili.com/ranking' # 发起网络请求 response = requests.get(url) html = response.text soup = BeautifulSoup(html, 'html.parser') items = soup.find_all('li', {"class": "rank-item"}) contents = [] for item in items: title = item.find('a', {"class": "title"}).text # 视频标题 video_url = item.find_all('a')[1].get('href') # av号链接 score = item.find('div', {"class": "pts"}).find('div').text # 综合得分 rank = item.find('div', {"class": "num"}).text # 排名 up = item.find_all('span', {"class": "data-box"})[2].text # up up_id = item.find_all('a')[2].get('href') # upid up_url = 'https:' + up_id plays = item.find_all('span', {"class": "data-box"})[0].text # 播放量 hots = item.find_all('span', {"class": "data-box"})[1].text # 热度 content = [title, rank, score, plays, hots, up, up_url, video_url] contents.append(content) now = datetime.now().strftime('%Y%m%d_%H%M%S') file_name = f'{now}top.csv' # 保存为csv文件 with open(file_name, 'w+', encoding='utf-16', newline='') as f: f_csv = csv.writer(f) f_csv.writerow(['标题', '排名', '得分', '播放量', '热度', 'up', 'upid', '视频地址']) f_csv.writerows(contents)
- beautifulsoup提取信息
- xpath提取信息
import requests from lxml import etree import csv from datetime import datetime url = 'https://www.bilibili.com/ranking' # 发起网络请求 response = requests.get(url) html = response.text datas = etree.HTML(html) # 取数据 titles = datas.xpath("//div[@class='info']/a") # 视频标题 video_urls = datas.xpath("//div[@class='info']/a/@href") # av号链接 scores = datas.xpath("//div[@class='pts']/div") # 综合得分 ranks = datas.xpath("//li[@class='rank-item']/div[@class='num']") # 排名 ups = datas.xpath("//div/a/span[@class='data-box']") # up up_ids = datas.xpath("//div[@class='detail']/a[@target='_blank']/@href") # upid plays = datas.xpath("//div[@class='detail']/span[1]") # 播放量 hots = datas.xpath("//div[@class='detail']/span[2]") # 热度 contents = [] for i in range(100): title = titles[i].text video_url = video_urls[i] score = scores[i].text rank = ranks[i].text up = ups[i].text up_id = up_ids[i] up_url = 'https:' + up_id play = plays[i].text hot = hots[i].text content = [title, rank, score, play, hot, up, up_url, video_url] contents.append(content) now = datetime.now().strftime('%Y%m%d_%H%M%S') file_name = f'{now}top.csv' with open(file_name, 'w+', encoding='utf-16', newline='') as f: f_csv = csv.writer(f) f_csv.writerow(['标题', '排名', '得分', '播放量', '热度', 'up', 'upid', '视频地址']) f_csv.writerows(contents)
三:动态爬虫
上面我们提及到的爬虫都是属于静态网站的爬虫,该类爬虫的资源都直接摆放在HTML页面里面,因此十分容易爬取。但是,也有资源放置在动态JavaScript里面的网页,比如我们的部分图片网站。
上面我们爬取了视频网站,也爬取了笑话网站,那么这一次我们试一下动态爬取图片网站。我选择poco这个网站,链接如下:https://www.poco.cn/,可以自己进入网站看看哈。
首先,为了爬取动态网站的资源,我们需要安装对应浏览器的webdriver,以下贴出chrome的webdrive地址为:http://npm.taobao.org/mirrors/chromedriver/
Edge的webdriver地址为:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
我们除了要安装webdriver外,还必须要为我们的python安装selenium这个第三方包。安装命令为
pip install selenium
如此,我们的准备工作就做完了,在我们爬取poco网站的图片时,必须要注意传入选用的webdriver的地址给selenium,否则selenium会不知道使用哪个浏览器,以及没有工具打开浏览器。
至于其余的爬虫思路和我们最开始提到的爬虫套路是一模一样的,没有什么区别,只是我们爬虫使用的工具换成了selenium而已。
案例:selenium爬取poco图片
我录制了一个视频,上传到了B站,可以直接点击下方链接查看selenium的基础使用:
【爬虫】【python】动态网站图片爬取之再也不怕小姐姐没有地方放了
https://www.bilibili.com/video/BV1A7411u7Ys
四:scrapy框架的使用
无论是使用我们的requests爬取静态资源库,还是使用我们的selenium爬取动态资源库,手动要写的代码都要写的较多。为了写更少的代码,我们可以直接使用scrapy框架来进行模式化爬虫。
在使用之前,我们必须要先安装scrapy框架。如果直接安装scrapy框架,会提示我们安装一个几个G的C框架。为了不这么麻烦,因此我们下载twisted的whl文件,本地安装之后就可以直接安装scripy框架了。
我们到如下网站:https://www.lfd.uci.edu/~gohlke/pythonlibs/,搜索twisted文件,结合你的python版本选择whl文件下载到本地。
使用本地安装命令
pip install '本地路径/twisted的对应python版本文件.whl'
之后再使用pip安装scripy即可成功安装。
案例:一个小说爬虫的多种实现方式
我依旧录制了一个视频,上传到了B站,可以直接点击下方的链接查看scripy的基础使用:
[python][scrapy]一个简单小说爬虫的多种实现方式及Debug过程
https://www.bilibili.com/video/BV1Uj411f7K5
说明
- 本文由我本人原创,发布于卯月七账号、知乎卯月七账号、CSDN卯月七账号。
- 本文允许转载、学习,转载请注明出处,谢谢。
- 作者邮箱[email protected],有问题可以联系。
- 本文为我整理的Python爬虫的入门文章,更多知识可以购买专业书籍学习。
- 创作不易,如果对你有帮助,希望能给我一些反馈,包括不限于点赞,评论,转发,非常感谢!!