本文旨在实现抠图算法 Semantic Human Matting 的第二阶段模型 M-Net,也即 Deep Image Matting。值得说明的是,本文实现的模型与原始论文略有出入,除了模型的输入层有细微差别之外,损失函数也作了简化(但无本质差别)。
本文完整代码见 GitHub: deep_image_matting_pytorch。Pytorch 需要 1.1.0 或后续版本。
本文 训练数据 来源于 爱分割 公司开源的 数据集,总共包含 34426 张图片和对应的 alpha 通道,数据量非常大,能公开特别值得点赞。但同时因为标注数据的 alpha 通道精度不高,导致训练后测试效果较差。建议使用 Deep Image Matting 的数据集训练。
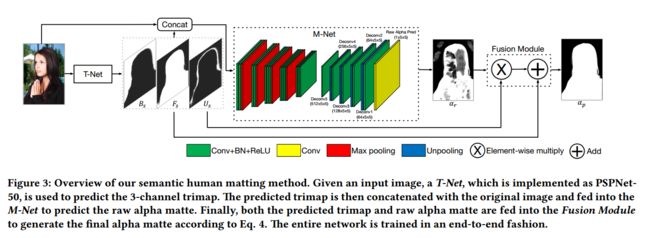
总的来说,Semantic Human Matting 论文提出的自动抠图的思路特别清晰明了(如上图),对于一张待抠图像,首先通过语义分割模型(即 T-Net)分割出前景、背景和未知区域(),然后广义的认为前景()+ 未知区域()组成一个三分图( Trimap),此时再利用 Deep Image Matting(即 M-Net) 即可高质量的完成抠图。完整的模型将在接下来的几篇文章逐步实现,本文只关注该模型的第二阶段(M-Net)。
M-Net 接受待抠图像(前景与背景的 RGB 3 通道合成)以及语义分割模型输出的 3 通道预测()拼接而成的 6 通道输入,经过编码器提取图像特征之后,由解码器得到预测 。如果语义分割模型分割的精度较高,那么可以认为 对应的区域已经很好的抠出了大部分的前景和背景,唯一需要提升准确率的是待抠对象的边缘区域,所以模型的第二阶段 M-Net 的目的就是细化的预测边缘区域(这正是 Deep Image Matting 要干的事情),两部分结合即得到最终的预测:
这个公式可以这样理解:
也就是:
根据全概率公式,用符号来表示则是:
但上述公式存在一个缺陷,即如果待抠目标外有大块噪声,则最终的预测也消除不了这个噪声,如下图:

为了消除第一阶段可能包含的外部噪声,本文的在实现 M-Net 的时候做了一个小的改动:第二阶段的输入改为由待抠图像 + 组成的 4 通道图片(此时,相当于将 看成是三分图 trimap),并且将第二阶段的预测则作为最终的预测。另外,第二阶段损失函数简化为只用 alpha 通道的损失更好。
一、模型实现
Deep Image Matting 原文的模型如下:
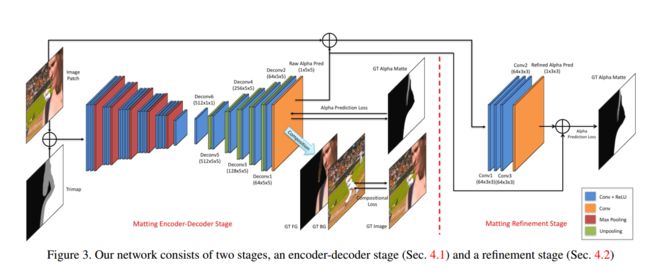
模型先通过一个编码器提取特征,之后经过一个解码器预测一个初始的 alpha 通道,这个预测值效果已经很好,但作者为了进一步提升抠图的精度,又额外的接了几层细化的小网络,然后将细化后的输出作为整个模型的最终输出。具体来说,首先将待抠图像(3 通道)以及事先准备好的三分图(trimap)合成一个 4 通道图像,然后经过 VGG16 的前 13 个卷积层以及之后的 1 个全连接层(看成是 1x1 的卷积层),总共 14 个卷积层提取图像特征(此时已做了 5 个最大池化,因此图像分辨率下降了 32 倍,如果输入是 320x320,那么特征映射的分辨率就变成了 10x10),这是模型的编码器阶段。接下来对图像特征进行解码,即开始解码器阶段。解码器使用 6 个卷积层(5x5 的卷积核)和 5 个 反池化层,每个反池化层将特征映射的分辨率提升 2 倍,因此解码器的输出与模型输入的大小一样。这里,使用反池化层的效果要比直接使用转置卷积(deconvolution)的效果要好。虽然他们都是为了提升图像分辨率,但使用转置卷积并不能很好的抠出细节,而使用反池化层却可以抠图头发丝等非常细的前景。为了最求极致效果,作者又接了一个小网络,将待抠图像和编码器预测的 alpha 通道合成一个 4 通道图像,然后通过 4 个 3x3 的卷积层得到细化后的 alpha 通道预测,作为最后的输出。
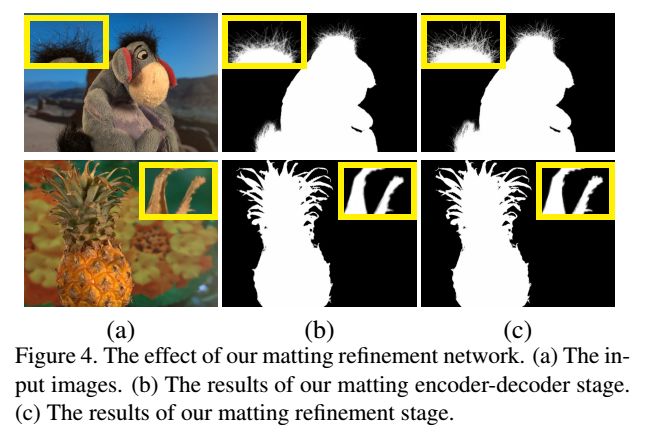
损失方面,总共用了 3 个分损失来合成网络的损失:
- 编码器阶段预测的 alpha 通道和真实的 alpha 通道的损失;
- 编码器阶段使用预测的 alpha 合成的图像和真实的 alpha 合成的图像的损失;
- 细化阶段预测的 alpha 通道和真实的 alpha 通道的损失。
这些损失都是逐点损失,即平方和误差:
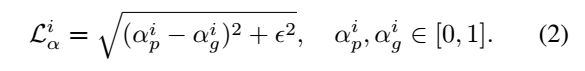
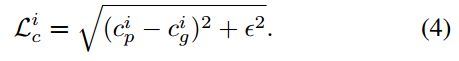
三个损失使用加权和形成整个网络最后反向传播的总损失。
Deep Image Matting 虽然论文上报告的效果很惊人,但实际实现时(在个人应用数据集上)泛化性能不够理想。
Semantic Human Matting(SHM)这篇论文的 M-Net 在以上基础上做了一些简化和修改。首先,为了防止网络容量太大造成过拟合,SHM 只使用 VGG16 的前 13 个卷积层及 4 个最大池化层来作为编码器,相应的,解码器阶段也就少一个反池化层。另外,为了加速网络收敛,所有的卷积层(编码器以及解码器的)都带批标准化(Batch Normalization)处理。其次,网络的输入由 4 通道变成了 6 通道,这样做一方面没有影响网络性能(论文 4.2 节),另一方面也是为了方便与 T-Net 对接,因为 T-Net 输出 前景、背景、未知 3 个预测通道,与待抠图像的 3 通道直接合成即得到 6 通道输入。最后,SHM 直接去掉了 Deep Image Matting 网络的细化阶段,因此损失也相应的减少为 2 个分损失。
本文基本忠实的实现了 SHM 的 M-Net 结构,但如本文开始时候说的那样,将 6 通道的输入改成了 4 通道,且为了完全引入 VGG16 的预训练模型,直接在 VGG16 的最前面接了一个输入为 6 通道、输出为 4 通道的卷积层。此外,本文将 M-Net 的预测作为最终的输出,以及训练时不再求合成图像的损失(以下模型实现时,loss 函数是支持合成图像损失的)。
总的来说,Deep Image Matting (或 M-Net)网络是非常清晰明了的,实现也很简单,模型文件 model.py 如下:
# -*- coding: utf-8 -*-
"""
Created on Sun Jul 21 07:08:58 2019
@author: shirhe-lyh
Implementation of paper:
Deep Image Matting, Ning Xu, eta., arxiv:1703.03872
"""
import torch
import torchvision as tv
VGG16_BN_MODEL_URL = 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth'
VGG16_BN_CONFIGS = {
'13conv':
[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512,
'M', 512, 512, 512],
'10conv':
[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512]
}
def make_layers(cfg, batch_norm=False):
"""Copy from: torchvision/models/vgg.
Changs retrue_indices in MaxPool2d from False to True.
"""
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [torch.nn.MaxPool2d(kernel_size=2, stride=2,
return_indices=True)]
else:
conv2d = torch.nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, torch.nn.BatchNorm2d(v),
torch.nn.ReLU(inplace=True)]
else:
layers += [conv2d, torch.nn.ReLU(inplace=True)]
in_channels = v
return torch.nn.Sequential(*layers)
class VGGFeatureExtractor(torch.nn.Module):
"""Feature extractor by VGG network."""
def __init__(self, config=None, batch_norm=True):
"""Constructor.
Args:
config: The convolutional architecture of VGG network.
batch_norm: A boolean indicating whether the architecture
include Batch Normalization layers or not.
"""
super(VGGFeatureExtractor, self).__init__()
self._config = config
if self._config is None:
self._config = VGG16_BN_CONFIGS.get('10conv')
self.features = make_layers(self._config, batch_norm=batch_norm)
self._indices = None
def forward(self, x):
self._indices = []
for layer in self.features:
if isinstance(layer, torch.nn.modules.pooling.MaxPool2d):
x, indices = layer(x)
self._indices.append(indices)
else:
x = layer(x)
return x
def vgg16_bn_feature_extractor(config=None, pretrained=True, progress=True):
model = VGGFeatureExtractor(config, batch_norm=True)
if pretrained:
state_dict = tv.models.utils.load_state_dict_from_url(
VGG16_BN_MODEL_URL, progress=progress)
model.load_state_dict(state_dict, strict=False)
return model
class DIM(torch.nn.Module):
"""Deep Image Matting."""
def __init__(self, feature_extractor):
"""Constructor.
Args:
feature_extractor: Feature extractor, such as VGGFeatureExtractor.
"""
super(DIM, self).__init__()
# Head convolution layer, number of channels: 4 -> 3
self._head_conv = torch.nn.Conv2d(in_channels=4, out_channels=3,
kernel_size=5, padding=2)
# Encoder
self._feature_extractor = feature_extractor
self._feature_extract_config = self._feature_extractor._config
# Decoder
self._decode_layers = self.decode_layers()
# Prediction
self._final_conv = torch.nn.Conv2d(self._feature_extract_config[0], 1,
kernel_size=5, padding=2)
self._sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self._head_conv(x)
x = self._feature_extractor(x)
indices = self._feature_extractor._indices[::-1]
index = 0
for layer in self._decode_layers:
if isinstance(layer, torch.nn.modules.pooling.MaxUnpool2d):
x = layer(x, indices[index])
index += 1
else:
x = layer(x)
x = self._final_conv(x)
x = self._sigmoid(x)
return x
def decode_layers(self):
layers = []
strides = [1]
channels = []
config_reversed = self._feature_extract_config[::-1]
for i, v in enumerate(config_reversed):
if v == 'M':
strides.append(2)
channels.append(config_reversed[i+1])
channels.append(channels[-1])
in_channels = self._feature_extract_config[-1]
for stride, out_channels in zip(strides, channels):
if stride == 2:
layers += [torch.nn.MaxUnpool2d(kernel_size=2, stride=2)]
layers += [torch.nn.Conv2d(in_channels, out_channels,
kernel_size=5, padding=2),
torch.nn.BatchNorm2d(num_features=out_channels),
torch.nn.ReLU(inplace=True)]
in_channels = out_channels
return torch.nn.Sequential(*layers)
def loss(alphas_pred, alphas_gt, images=None, epsilon=1e-12):
losses = torch.sqrt(
torch.mul(alphas_pred - alphas_gt, alphas_pred - alphas_gt) +
epsilon)
loss = torch.mean(losses)
if images is not None:
images_fg_gt = torch.mul(images, alphas_gt)
images_fg_pred = torch.mul(images, alphas_pred)
images_fg_error = images_fg_pred - images_fg_gt
losses_image = torch.sqrt(
torch.mul(images_fg_error, images_fg_error) + epsilon)
loss += torch.mean(losses_image)
return loss
Pytorch 的官方是带有 VGG 系列模型的,使用也很方便,比如使用带批标准化层的 VGG16 直接写为:
vgg = torchvision.models.vgg16_bn(pretrained=True)
其中 pretrained=True 表示导入在 ImageNet 上预训练的参数。但因为,我们是只使用 VGG16 的前 13 个卷积层,而不需要后面的全连接层,因此,不会像上面那样直接使用,而是要从 torchvision 的官方实现中截取卷积层的部分(官方实现见文件 Python 安装路径下的 site-packages/torchvision/models/vgg.py)。我们主要复制该文件中的 make_layers 函数,但因为后面解码器阶段要用反池化,所以还要做一些修改:要把
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
改为
layers += [torch.nn.MaxPool2d(kernel_size=2, stride=2, return_indices=True)]
之所以要加上 return_indices=True,是因为后面反池化层要用到这些池化层的池化过程中的最大值的下标(从而要记下来)。也正因为池化层多返回了一个值(同时返回特征映射和最大值下标张量),因此在重载 forward 函数时要进行如下的区别对待:
def forward(self, x):
self._indices = []
for layer in self.features:
if isinstance(layer, torch.nn.modules.pooling.MaxPool2d):
x, indices = layer(x)
self._indices.append(indices)
else:
x = layer(x)
return x
除此之外,编码器阶段都是非常简单的,无需赘言。
来看解码器阶段。只需要重点关注一下反池化层(接后续的卷积层)的实现即可。具体也很简单:
unpool = torch.nn.MaxUnpool2d(kernel_size=2, stride=2)
conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size=5, padding=2)
即,先用反池化操作提升 2 倍分辨率,然后再接一个普通卷积层(可选操作:批标准化、整流线性单元)。实际前向传播时的计算如下:
x = unpool(x, indices)
x = conv(x)
其中,indices 是编码器阶段对应的池化层返回的最大池化操作返回的最大值下标。反池化层与转置卷积层都是可以训练的(都带有参数),作用也几乎相同(提升分辨率),但对于抠图这个任务来说,最关心的就是目标的边界区域,而这些边界因为都是前景、背景的交界区,因此表现在特征映射的响应上,就基本都是局部极大值,从而在池化操作时,返回的最大值下标就基本完整的记录下了待抠目标的边界,反池化操作因为会重点关注这些区域,所以效果较好。
DIM 类的 decode_layers 函数就是整个的解码器的定义。它看起来有点晦涩,其实不难理解。我们看编码器阶段的配置:
[64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512]
其中的 M 表示最大池化层,其它的数字就是全部的 13 个卷积层对应的输出通道数。解码器执行的操作基本上就是以上操作的逆过程:
[512, 'U', 512, 'U', 256, 'U', 128, 'U', 64]
其中的 U 表示 torch.nn.MaxUnpool2d 反池化操作。
二、训练过程
本节训练数据来源于爱分割开源的 数据集。该数据集内的所有 34426 张图片都类似于如下的上身模特图:

可以明显看到标注的 alpha 通道是非常粗陋的,远达不到头发丝的精度。因为这个数据集直接给出了原始图像,所以不需要前景、背景图片的合成。
数据准备
当你下载好爱分割开源数据集(并解压)之后,我们需要一次性将所有图片的掩码(mask)都准备好,因此你需要打开 data/retrieve.py 文件,将 root_dir 改成你的 Matting_Human_Half 文件夹的路径,然后执行 retrieve.py 等待生成所有图片的 alpha 和 mask(在 Matting_Human_Half 文件夹内),以及用于训练的 train.txt 和 val.txt(在 data 文件夹内,其中默认随机选择 100 张图像用于验证)。假如,你训练时不再改动 Matting_Human_Half 文件夹的路径,那么你不需要再做其它处理了。如果你训练时,Matting_Human_Half 与以上制作 train.txt 和 val.txt 时指定的 root_dir 路径不一致了,那么你可以使用诸如 Notepad ++ 之类的工具,将 root_dir 替换为空,形成如下的形式:
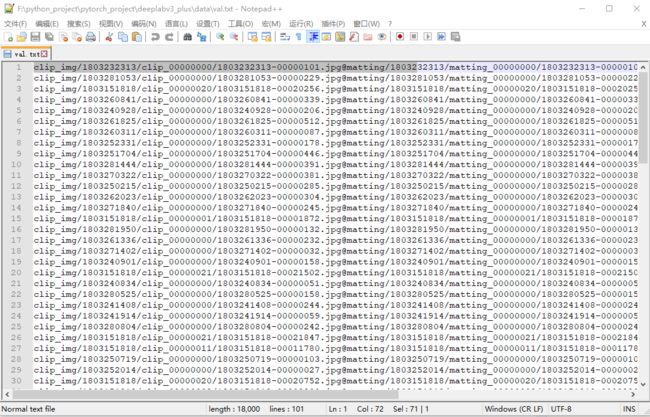
train.txt 和 val.txt 分别记录了训练和验证图像的路径,每一行对应一张图像的 4 个路径,分别是 原图像路径(3 通道)、透明图路径(4 通道)、alpha 通道图像路径、mask 路径,它们通过 @ 符号分隔。
训练
直接在命令行执行:
python3 train.py --root_dir "xxx/Matting_Human_Half" [--gpu_indices 0 1 ...]
开始训练,如果你从制作数据时开始, Matting_Human_Half 这个文件夹的路径始终没有改动过,那么 root_dir 这个参数也可以不指定(指定也无妨)。后面的 [--gpu_indices ...] 表示需要根据实际情况,可选的指定可用的 GPU 下标,这里默认是使用 0,1,2,3 共 4 块 GPU,如果你使用一块 GPU,则指定
--gpu_indices 0
如果使用多块,比如使用 第 1 块和第 3 块 GPU,则指定
--gpu_indices 1 3
即可。其它类似。训练过程中的所有超参数都在 train.py 文件的开头部分,可以直接修改默认值或通过命令行指定。
训练开始几分钟后,你在项目路径下执行:
tensorboard --logdir ./models/logs
可以打开浏览器查看训练的学习率、损失曲线,和训练过程中的分割结果图像。这里使用的是 Pytorch 自带的类:from torch.utils.tensorboard import SummaryWriter 来调用 tensorboard,因此需要 Pytorch 1.1.0 以及之后的版本才可以。(但好像浏览器刷新不了新结果,需要不断重开 tensorboard 才可以观看训练进展)
训练结束后(默认训练 30 个 epoch),在 models 文件夹中保存了训练过程中的模型参数文件(模型使用参考 predict.py)。直接执行:
python3 predict.py
将在 test 文件夹里生成测试图片的抠图结果。
其它数据集上训练
训练 Pytorch 模型时,需要重载 torch.utils.data.Dataset 类,用来提供数据的批量生成。重载时,只需要实现 __ init __, __ getitem __, __ len __ 这三个函数。在这个项目里,我们使用的是 dataset.py 的重载类 MattingDataset。读者可以按照自己的方式依据自己的标注格式来重载,也可以依照 MattingDataset 来改写。
对于只提供前、背景分离的数据,建议先一次性提前合成好合成图像,和制作好 alpha 通道图像。此时你就可以适当修改一下 get_image_mask_paths 函数即可。这个函数需要返回一个如下格式的列表:
[[image_path, alpha_path],
[image_path, alpha_path],
...
[image_path, alpha_path]]
另外,__ getitem __ 函数数据增强的方式裁剪、缩放、水平翻转(以及 alpha 通道随机膨胀腐蚀),如果你还有其它的处理方式请自行添加或删减。另外,这里指定的裁剪尺寸:
crop_sizes = [320, 480, 600, 800]
是根据爱分割提供的数据来划定的,里面所有图片都是 600x800 的分辨率。一般来说,根据 Deep Image Matting 论文,是从 320 开始,每隔 160 像素的尺寸裁剪,最后统一缩放到 320 即可。
三、Deep Image Matting 数据集上的复现
本节将在 Deep Image Matting 数据集上进行训练(训练数据可联系论文作者获取),因部分参数未仔细调整,训练结果并非最优。使用的背景图像集是 COCO/train2017。
数据准备
我们将前景图像和背景图像通过 alpha 通道合成训练集。假设你已经获取了 DIM 数据集,那么进入 data_dim 文件夹,打开 composition.py,将 root_dir 替换成你保持 Combined_Dataset 文件夹的路径,bg_image_root_dir 填写背景图像的文件夹路径,output_dir 填写合成图像的保持文件夹路径。num_bg_images_per_fg 表示一张前景图像对应多少张背景图像,论文里这个值取 100(这里为了减少训练时间,我取的是 50,读者根据具体情况修改)。当这些值都确认无误后,执行 composition.py,将花费很长一段时间来合成图片。合成图像结束后,在当前路径下生成 train.txt 和 val.txt 两个标注文件。train.txt 文件里每一行对应 4 个路径,分别是合成图像路径、前景图像路径、alpha 通道路径、背景图像路径,val.txt 里除了缺少合成图像路径之外,其它顺序一致。
训练时,我们只需要 train.txt 中的第 1 个和第 3 个路径,因此和训练爱分割开源数据集的标注文件格式一致,从而可以共用同一个 dataset.py,只需要确保 dataset.py 里面的函数 __ getitem __ 中的
crop_sizes = [320, 480, 640]
即可。
训练过程
执行
python3 train.py --annotation_path "./data_dim/train.txt" [gpu_indices 0 1 2 ...]
开始训练,期间可通过 tensorboard 查看训练进程。训练的所有超参数可在 train.py 内修改,也可以通过命令行直接指定。
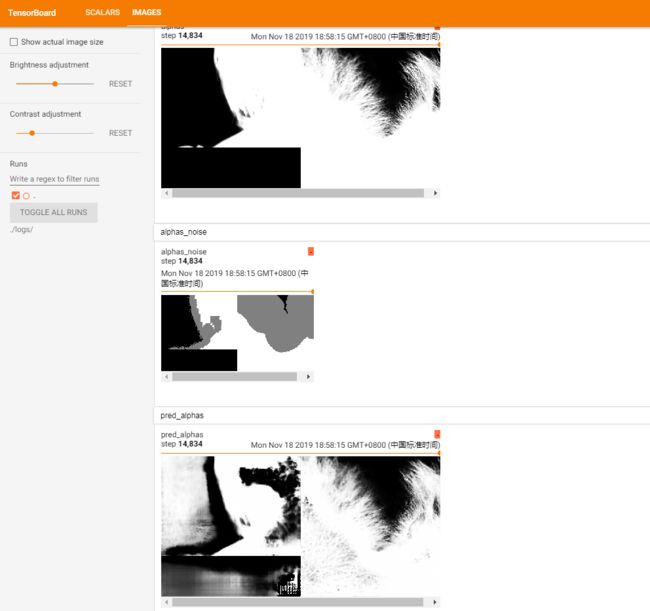
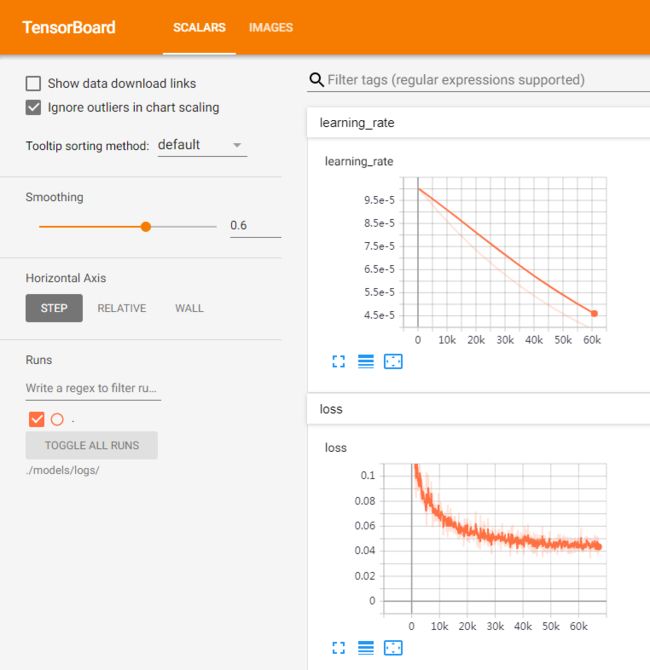
本次训练,超参数采用的都是 train.py 中的默认值,由损失曲线可以看到,如果再继续训练(已训练 200 epoch),损失会进一步下降,抠图效果会更好。
结果展示
训练结束后,执行(如果模型保存路径是默认的 ./models,否则需要修改一下 ckpt_path):
python3 predict_trimap.py
会在 data_dim/test 文件夹里生成预测结果(见文件夹 preds):


从以上抠图结果可看出,在某些细节上效果还不理想。如果你想获得更好的结果,一方面可以在合成训练图片时提升 1 张前景对应的背景图片数(我取的是 1:50,论文是 1:100);其次,仔细调整学习率及其衰减;再次,增加训练的轮次(epoch,我训练了 200 个 epoch)等。
【附录】
快速上手 Pytorch 的资料:PyTorch Tutorial for Deep Learning Researchers。