一、项目介绍
项目目标
1.获取链家网上的深圳市租房数据
2.将获取的数据可视化
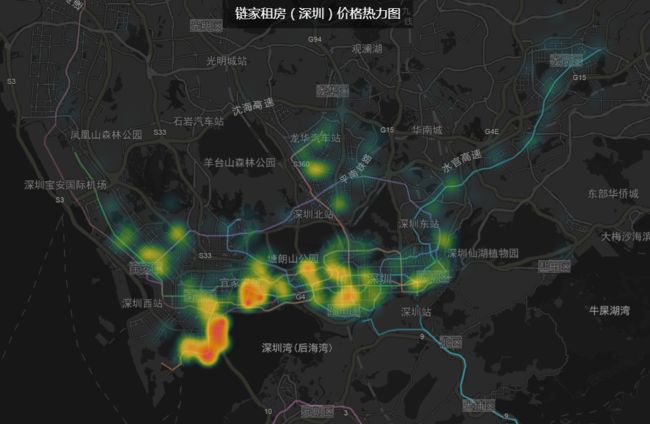
文章略长,为节约部分读者时间,提前展示可视化效果
工具
python3.6、pycharm2018.1、高德地图Map Lab
技术
数据抓取:Scarpy
数据展示:高德地图API(Map Lab)
整体思路
- 分析链家租房模块url(地区、翻页变化),找出请求url的规则
- 分析租房条目的类别(大致分为两类,青年公寓和普通租房)
- 分析房间详情页html(此处一般要注意是否是ajax加载)
- 编写项目进行数据抓取(注意存储数据的形式,方便对接高德地图)
- 使用高德地图开发者模式,导入数据,选择合适的图表类型,展示数据
二、项目搭建:
打开cmd,进入project目录(我自己的项目目录),执行scrpay startproject LianJia,创建scrapy项目;
执行cd LianJia进入项目;
执行scrapy genspider LJ lianjia.com,创建通用爬虫
三、基本设置
settings设置
这里的UA使用fake_useragent库中的UserAgent,fake_useragent是一个在git上开源的项目,维护了几百个目前比较常用的UA,导入后直接调用random就可以随机生成UA,使用方便,推荐。代码如下:
from fake_useragent import UserAgent
# 设置延迟为0.2
DOWNLOAD_DELAY = 0.2
# 关闭robots协议
ROBOTSTXT_OBEY = False
# headers设置
ua = UserAgent()
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'ua.random'
}
启动文件 - 同样创建一个start.py来负责开启爬虫
from scrapy import cmdline
# 这里使用 -o 文件名.csv -s FEED_EXPORT_ENCODING=UTF-8 将数据直接保存为csv文件,简单方便。
cmdline.execute("scrapy crawl LJ -o sz-lianjia.csv -s FEED_EXPORT_ENCODING=UTF-8".split())
# cmdline.execute("scrapy crawl LJ".split())
四、页面分析
4.1 链家的租房页面可以查看100页,每页30条数据
但是仔细观察可以发现其中很多条目是相同,这样也不难发现在深圳链家的线上房源,其实并没有页面上写的21447套在租房列表页面,可以看到两种不同的房屋类型

对应的详情页面也不同,对于这两种不用页面要分类爬取
链家的反爬其实一般,只要使用随机请求头基本都可以很顺畅的爬下来
4.2注意:在详情页面中很多信息比较繁杂,爬取时要细心分析
比如基本信息中会有12项可视数据,但是源码中有17个li,可以使用循环来剔除掉无用的li


经纬度信息(高德地图需要用到)放在一个script标签中,这里推荐使用正则进行提取

五、代码展示
5.1 spider
这里没什么好说的都是一些基本套路,当然也有一些地方经过多次调试才拿到数据
推荐大家咋终端使用scarpy shell 来进行测试提取结果
有问题的读者,可以在评论区留言,有问必答哦
# -*- coding: utf-8 -*-
import scrapy
from urllib import parse
from LianJia.items import LjApartmentItem, LjZufangItem
import re
class LjSpiderSpider(scrapy.Spider):
name = 'LJ'
allowed_domains = ['lianjia.com']
page = 1
start_urls = ['https://sz.lianjia.com/zufang/pg1/']
def parse(self, response):
"""
获取每一个租房详情页的链接
:param response:
:return:
"""
links = response.xpath("//div[@class='content__list']/div/a/@href").extract()
for link in links:
# 补全详情页链接
url = parse.urljoin(response.url, link)
if url.find('apartment') != -1:
yield scrapy.Request(url=url, callback=self.apartment_parse)
else:
yield scrapy.Request(url, callback=self.zufang_parse)
# 翻页
self.page += 1
page_urls = 'https://sz.lianjia.com/zufang/pg{}/'.format(self.page)
# 爬取100页数据
if self.page < 101:
yield scrapy.Request(url=page_urls, callback=self.parse)
else:
print('爬取结束')
def apartment_parse(self, response):
"""
爬取公寓房间信息
:param response:
:return:
"""
title = response.xpath("//p[contains(@class,'flat__info--title')]/text()").extract()[0].strip('\n').strip()
price = int("".join(response.xpath("//p[@class='content__aside--title']/span[last()]/text()").extract()).strip())
# 将response.text中的特殊符号去掉,方便正则匹配
text = re.sub(r"[{}\s':,;]", "", response.text)
address = re.match(r".*g_conf.name=(.*)g_conf.houseCode.*", text).group(1)
longitude = re.match(r".*longitude?(.*)latitude.*", text).group(1)
latitude = re.match(r".*latitude?(.*)g_conf.name.*", text).group(1)
# 将经纬度格式化,为之后数据可视化做准备
location = longitude + "," +latitude
room_url = response.url
apartment_desc = response.xpath("//p[@data-el='descInfo']/@data-desc").extract()[0]
introduction = apartment_desc.replace(r"
", "").replace("\n", "")
li_list = response.xpath("//ul[@data-el='layoutList']/li")
room_number = len(li_list)
room = []
for li in li_list:
rooms = {}
_type = li.xpath(".//p[@class='flat__layout--title']/text()").extract()[0]
room_type = _type.replace("\n", "").strip(" ")
room_img = li.xpath(".//img/@data-src").extract()[0]
li_price = li.xpath(".//p[@class='flat__layout--title']/span/text()").extract()[0]
room_price = li_price.replace("\n", "").strip(" ")
area = li.xpath(".//p[@class='flat__layout--subtitle']/text()").extract()[0]
room_area_str = area.replace("\n", "").replace(" ", "")
room_area = re.match(r".*?(\d+).*", room_area_str)
if room_area is None:
room_area = "未知"
room_price = "已满房"
else:
room_area = room_area.group(1)
room_left = li.xpath(".//p[@class='flat__layout--subtitle']/span/text()").extract()[0]
rooms['图片'] = room_img
rooms['类型'] = room_type
rooms['价格'] = room_price
rooms['面积'] = room_area
rooms['余房'] = room_left
room.append(rooms)
item = LjApartmentItem()
item['title'] = title
item['price'] = price
item['address'] = address
item['location'] = location
item['introduction'] = introduction
item['room_number'] = room_number
item['room_infos'] = room
item['room_url'] = room_url
yield item
def zufang_parse(self, response):
"""
爬取业主出租房间信息
:param response:
:return:
"""
title = response.xpath("//p[@class='content__title']/text()").extract()[0]
price = int(response.xpath("//p[@class='content__aside--title']/span/text()").extract()[0])/3
publish_time = "".join(response.xpath("//div[@class='content__subtitle']/text()").extract()).strip().split(" ")[-1]
# 将response.text中的特殊符号去掉,方便正则匹配
text = re.sub(r"[{}\s':,;]", "", response.text)
address = re.match(r".*g_conf.name=(.*)g_conf.houseCode.*", text).group(1)
longitude = re.match(r".*longitude?(.*)latitude.*", text).group(1)
latitude = re.match(r".*latitude?(.*)g_conf.subway.*", text).group(1)
# 将经纬度格式化,为之后数据可视化做准备
location = longitude + "," + latitude
room_url = response.url
room_img = "".join(response.xpath("//div[@class='content__article__slide__item']/img/@data-src").extract())
# conditions中有4项内容(租赁方式、布局、面积、朝向)
conditions = response.xpath("//p[@class='content__article__table']/span/text()").extract()
room_layout = conditions[1]
room_area = conditions[2]
room_orientation = conditions[3]
room_infos = response.xpath("//div[@class='content__article__info']/ul/li/text()").extract()
for index, li in enumerate(room_infos):
if li.find("\xa0") != -1:
del room_infos[index]
surrounding = "".join(response.xpath("//p[@data-el='houseComment']/@data-desc").extract())
surrounding_desc = surrounding.replace("
", "").replace("\n", "")
item = LjZufangItem()
item['title'] = title
item['price'] = price
item['publish_time'] = publish_time
item['address'] = address
item['location'] = location
item['room_img'] = room_img
item['room_layout'] = room_layout
item['room_area'] = room_area
item['room_orientation'] = room_orientation
item['room_infos'] = room_infos
item['surrounding_desc'] = surrounding_desc
item['room_url'] = room_url
yield item
5.2 item
在写item时一开始,按照自己的想法来,想提取什么写什么(当然前提是有些东西能你可以提取得到..),在写爬虫时,可以进行适当调整(对部分item进行取舍)
# -*- coding: utf-8 -*-
import scrapy
class LjApartmentItem(scrapy.Item):
# 公寓名称
title = scrapy.Field()
# 公寓最低单间价
price = scrapy.Field()
# 公寓地址
address = scrapy.Field()
# 公寓坐标(绘制地图备用)
location = scrapy.Field()
# 公寓介绍
introduction = scrapy.Field()
# 单间个数
room_number = scrapy.Field()
# 单间信息
room_infos = scrapy.Field()
# 房间链接
room_url = scrapy.Field()
class LjZufangItem(scrapy.Item):
# 房间名称
title = scrapy.Field()
# 房间价格
price = scrapy.Field()
# 发布日期
publish_time = scrapy.Field()
# 房间地址
address = scrapy.Field()
# 房间坐标(绘制地图备用)
location = scrapy.Field()
# 房间图片
room_img = scrapy.Field()
# 房间布局
room_layout = scrapy.Field()
# 房间面积
room_area = scrapy.Field()
# 房间朝向
room_orientation = scrapy.Field()
# 房间基本信息
room_infos = scrapy.Field()
# 周围环境描述
surrounding_desc = scrapy.Field()
# 房间链接
room_url = scrapy.Field()
六、爬取结果
两种不同的房间信息我们都拿到了
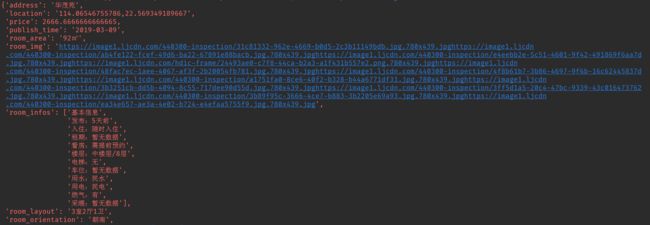
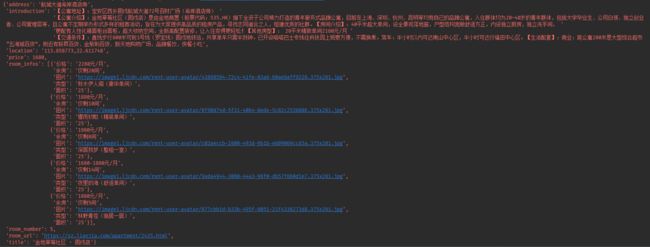
前面提到过
我们使用
scrapy crawl LJ -o sz-lianjia.csv -s FEED_EXPORT_ENCODING=UTF-8命令,直接将文件保存为csv文件。爬取完成后,项目录下会生成该文件,使用execl打开文件查看结果如下:
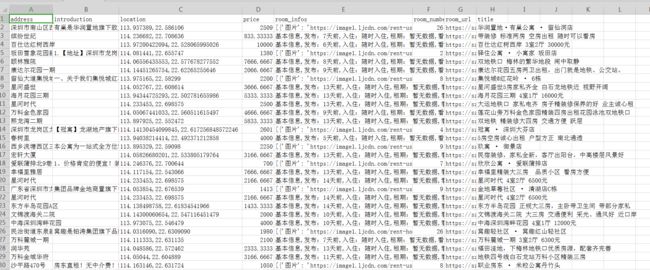
七、高德地图Map Lab 可视化
7.1 进入高德地图开发者平台
https://lbs.amap.com/



导入数据前要查看开发者文档,导入的数据格式一定要正确
格式要求:https://lbs.amap.com/faq/mapdata/platform/upload

成功导入后,我们可以删除room_infos,room_number,introdcuction等字段,主要保留price和location就可以

7.2 选择合适的呈现图
选择呈现效果,不同的图像对数据的要求也不同,可以尝试查看说明来进行选择


地图数据依赖默认选择location字段,成像数据依赖要选择price 就ok了

7.3可视化效果展示
这里分别选择了2D热力图和3D直方图来进行渲染,效果如下:

从上图可以简单分析出,目前房源大多都沿地铁线分布,租房价格最高的在南山区,福田区其次,也可以看到坂田、保安、罗湖也都有不少房源。
八、项目反思
该项目主要爬取链家网租房模块中的信息,但是爬取过程中发现整租类的大面积住房价格会很高,而青年公寓价格偏低,形成两个价格集中区域,容易出现断崖式数据分布。目前想到的解决方法是,将数据进一步处理,采用价格/面积的方式来作为成像的数据依赖,这样效果应该会更好一些,有兴趣的读者可以在此基础上加以改进。