Spring Boot+Spring Data JPA
1.JPA
JPA是什么?
- Java Persistence API:用于对象持久化的 API
- Java EE 5.0 平台标准的 ORM 规范,使得应用程序以统一的方式访问持久层
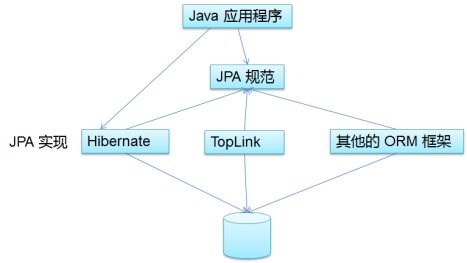
JPA和Hibernate的关系
- JPA 是 Hibernate 的一个抽象(就像JDBC和JDBC驱动的关系);
- JPA 是规范:JPA 本质上就是一种 ORM 规范,不是ORM 框架,这是因为 JPA 并未提供 ORM 实现,它只是制订了一些规范,提供了一些编程的 API 接口,但具体实现则由 ORM 厂商提供实现;
- Hibernate 是实现:Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现
- 从功能上来说, JPA 是 Hibernate 功能的一个子集
JPA的优势
- 标准化: 提供相同的 API,这保证了基于JPA 开发的企业应用能够经过少量的修改就能够在不同的 JPA 框架下运行。
- 简单易用,集成方便: JPA 的主要目标之一就是提供更加简单的编程模型,在 JPA 框架下创建实体和创建 Java 类一样简单,只需要使用 javax.persistence.Entity 进行注解;JPA 的框架和接口也都非常简单。
- 可媲美JDBC的查询能力: JPA的查询语言是面向对象的,JPA定义了独特的JPQL,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询。
- 支持面向对象的高级特性: JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系,最大限度的使用面向对象的模型
JPA包含的技术
- ORM 映射元数据:JPA 支持 XML 和 JDK 5.0 注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中。
- JPA 的 API:用来操作实体对象,执行CRUD操作,框架在后台完成所有的事情,开发者从繁琐的 JDBC 和 SQL 代码中解脱出来。
- 查询语言(JPQL):这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序和具体的 SQL 紧密耦合
2.Spring Data
Spring Data 是 Spring 的一个子项目。用于简化数据库访问,支持NoSQL 和 关系数据存储。其主要目标是使数据库的访问变得方便快捷。Spring Data 具有如下特点:
1.SpringData 项目支持 NoSQL 存储:
MongoDB (文档数据库)
Neo4j(图形数据库)
Redis(键/值存储)
Hbase(列族数据库)
2.SpringData 项目所支持的关系数据存储技术:
JDBC
JPA
3.Spring Data Jpa 致力于减少数据访问层(DAO)的开发量。开发者唯一要做的,就是声明持久层的接口,其他都交给 Spring Data JPA 完成。比如:当有一个UserDao.findUserById()这样一个方法声明,大致应该能判断出这是根据给定条件的 ID 查询出满足条件的 User 对象。Spring Data JPA做的便是规范方法的名字,根据符合规范的名字来确定方法需要实现什么样的逻辑。
3.Spring Boot整合Spring Data JPA
添加依赖、配置datasource和JPA
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
runtime
com.alibaba
druid-spring-boot-starter
1.1.10
spring.datasource.url=jdbc:mysql://localhost:3306/demo?serverTimezone=GMT%2B8&characterEncoding=UTF-8
spring.datasource.username=root
spring.datasource.password=admin
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
# JPA配置
spring.jpa.database=mysql
# 在控制台打印SQL
spring.jpa.show-sql=true
# 数据库平台
spring.jpa.database-platform=mysql
# 每次启动项目时,数据库初始化策略
spring.jpa.hibernate.ddl-auto=update
# 指定默认的存储引擎为InnoDB
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
创建实体类
ORM(Object Relational Mapping)框架表示对象关系映射,使用ORM框架我们不必再去创建表,框架会自动根据当前项目中的实体类创建相应的数据表。因此,我这里首先创建一个User对象,如下:
@Data
@Entity(name = "t_book")
public class book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
@Column(name = "name")
private String name;
private String author;
}
@Entity注解表示这是一个实体类,那么在项目启动时会自动针对该类生成一张表,默认的表名为类名,@Entity注解的name属性表示自定义生成的表名。@Id注解表示这个字段是一个id,@GeneratedValue注解表示主键的自增长策略,对于类中的其他属性,默认都会根据属性名在表中生成相应的字段,字段名和属性名相同,如果开发者想要对字段进行定制,可以使用@Column注解,去配置字段的名称,长度,是否为空等等。
之后,启动Spring Boot项目,数据库中就会自动创建一个名为t_user的表

针对该表的操作,则需要我们提供一个Repository,如下:
package com.example.jpa.dao;
import com.example.jpa.bean.Book;
import org.springframework.data.jpa.repository.JpaRepository;
public interface BookDao extends JpaRepository {
}
这里,自定义UserDao接口继承自JpaRepository,JpaRepository提供了一些基本的数据操作方法,例如保存,更新,删除,分页查询等。
普通增删改查
@Test
void insert() {
Book book = new Book();
book.setName("百年孤独");
book.setAuthor("马尔克斯");
bookDao.save(book);
}
@Test
public void update(){
Book book = new Book();
book.setAuthor("马尔克斯");
book.setName("霍乱时期的爱情");
book.setId(1);
bookDao.saveAndFlush(book);
}
@Test
public void delete(){
bookDao.deleteById(1);
}
@Test
void find(){
Optional byId = bookDao.findById(2);
System.out.println(byId.get());
List all = bookDao.findAll();
System.out.println(all);
}
JPA实现分页查询:
Pageable pageable = PageRequest.of(0,2);
Page page = bookDao.findAll(pageable);
System.out.println("记录数"+page.getTotalElements());
System.out.println("当前页记录数"+page.getNumberOfElements());
System.out.println("每页记录数"+page.getSize());
System.out.println("获取总页数"+page.getTotalPages());
System.out.println("查询结果"+page.getContent());
System.out.println("当前页(从零开始)"+page.getNumber());
查询结果如下:

开发者也可以在接口中自己声明相关的方法,只需要方法名称符合规范即可,在Spring Data中,只要按照既定的规范命名方法,Spring Data Jpa就知道你想干嘛,这样就不用写SQL了,那么规范参考下图:

如查询id大于等于3的记录
List findBookByIdGreaterThan(Integer id);
查询结果如下
这种方法命名主要是针对查询,但是一些特殊需求,可能并不能通过这种方式解决,例如想要查询id最大的用户,这时就需要开发者自定义查询SQL了,如上代码所示,自定义查询SQL,使用@Query注解,在注解中写自己的SQL,默认使用的查询语言不是SQL,而是JPQL,这是一种数据库平台无关的面向对象的查询语言,有点定位类似于Hibernate中的HQL,在@Query注解中设置nativeQuery属性为true则表示使用原生查询,即大伙所熟悉的SQL。上面代码中的只是一个很简单的例子,还有其他一些点,例如如果这个方法中的SQL涉及到数据操作,则需要使用@Modifying和@Transactional注解。
如查询id最大的记录
@Query(value = "select * from t_book where id=(select max(id) from t_book)",nativeQuery = true)
Book getMaxIdBook();
@Query(value = "insert into t_book(name,author) value (:name,:author)",nativeQuery = true)
@Modifying
@Transactional
Integer addBook(@Param("name") String name,@Param("author") String author);
查询结果如下

4.多数据源查询
创建项目
创建项目时选择Spring Web、Spring Data JPA以及MySQL Driver
手动添加druid-spring-boot依赖
com.alibaba
druid-spring-boot-starter
1.1.10
多数据源配置
接下来配置多数据源,这里基本上还是和JdbcTemplate多数据源的配置方式一致,首先在application.properties中配置数据库基本信息,然后提供两个DataSource,再加上jpa的配置即可。与单数据源配置不同,多数据源的jpa配置中要加上.properties,表示这些属性最终都要放在properties中。
application.properties中的配置如下:
spring.datasource.one.url=jdbc:mysql://localhost:3306/demo?serverTimezone=GMT%2B8&useSSL=false
spring.datasource.one.username=root
spring.datasource.one.password=admin
spring.datasource.one.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.url=jdbc:mysql://localhost:3306/demo2?serverTimezone=GMT%2B8&useSSL=false
spring.datasource.username=root
spring.datasource.password=admin
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.jpa.properties.hibernate.ddl-auto=update
spring.jpa.properties.database-platform=mysql
spring.jpa.properties.database=mysql
spring.jpa.properties.show-sql=true
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
创建实体类和配置类
@Data
@Entity(name = "t_book")
public class Book {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private String name;
private String author;
}
配置DataSource
这里的配置和Mybatis以及jdbc的多数据源配置基本一致,但是多了一个在Spring中使用较少的注解@Primary,@Primary表示当某一个类存在多个实例时,优先使用哪个实例。这个注解一定不能少,否则在项目启动时会出错,
@Configuration
public class DataSourceConfig {
@Bean
@Primary
@ConfigurationProperties(prefix = "spring.datasource.one")
DataSource dsOne(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.two")
DataSource dsTwo(){
return DruidDataSourceBuilder.create().build();
}
}
配置JPA
@Configuration
@EnableJpaRepositories(basePackages = "com.example.jpa2.dao1",
entityManagerFactoryRef = "localContainerEntityManagerFactoryBean1",
transactionManagerRef = "platformTransactionManager1")
public class JpaConfig1 {
@Autowired
@Qualifier("dsOne")
DataSource dsOne;
@Autowired
JpaProperties jpaProperties;
@Bean
@Primary
LocalContainerEntityManagerFactoryBean localContainerEntityManagerFactoryBean1(EntityManagerFactoryBuilder builder){
return builder.dataSource(dsOne)
.properties(jpaProperties.getProperties())
.persistenceUnit("pu1")
.packages("com.example.jpa2.bean")
.build();
}
//事务管理器
@Bean
PlatformTransactionManager platformTransactionManager(EntityManagerFactoryBuilder builder){
return new JpaTransactionManager(localContainerEntityManagerFactoryBean1(builder).getObject());
}
}
首先这里注入dsOne,再注入JpaProperties,JpaProperties是系统提供的一个实例,里边的数据就是我们在application.properties中配置的jpa相关的配置。然后我们提供两个Bean,分别是LocalContainerEntityManagerFactoryBean和PlatformTransactionManager事务管理器,不同于MyBatis和JdbcTemplate,在Jpa中,事务一定要配置。在提供LocalContainerEntityManagerFactoryBean的时候,需要指定packages,这里的packages指定的包就是这个数据源对应的实体类所在的位置,另外在这里配置类上通过@EnableJpaRepositories注解指定dao所在的位置,以及LocalContainerEntityManagerFactoryBean和PlatformTransactionManager分别对应的引用的名字。这样第一个就配置好了,第二个基本和这个类似,主要有几个不同点:
- dao的位置不同
- persistenceUnit不同
- 相关bean的名称不同
- 实体类可以共用。
代码如下:
@Configuration
@EnableJpaRepositories(basePackages = "com.example.jpa2.dao2",
entityManagerFactoryRef = "localContainerEntityManagerFactoryBean2",
transactionManagerRef = "platformTransactionManager2")
public class JpaConfig2 {
@Autowired
@Qualifier("dsTwo")
DataSource dsTwo;
@Autowired
JpaProperties jpaProperties;
@Bean
LocalContainerEntityManagerFactoryBean localContainerEntityManagerFactoryBean2(EntityManagerFactoryBuilder builder){
return builder.dataSource(dsTwo)
.properties(jpaProperties.getProperties())
.persistenceUnit("pu2")
.packages("com.example.jpa2.bean")
.build();
}
//事务管理器
@Bean
PlatformTransactionManager platformTransactionManager2(EntityManagerFactoryBuilder builder){
return new JpaTransactionManager(localContainerEntityManagerFactoryBean2(builder).getObject());
}
}
接下来,在对应位置分别提供相关的实体类和dao即可。
数据源一的dao如下:
public interface BookDao extends JpaRepository {}
数据源二的dao如下:
public interface BookDao2 extends JpaRepository {}
到此,所有的配置就算完成了,接下来就可以在Service中注入不同的UserDao,不同的UserDao操作不同的数据源。