作者|GUEST
编译|VK
来源|Analytics Vidhya
介绍
在当今繁忙的世界中,推荐系统变得越来越重要。人们总是在寻找最适合他们的产品/服务。因此,推荐系统非常重要,因为它们可以帮助用户在不消耗认知资源的情况下做出正确的选择。
在本博客中,我们将了解推荐系统的基础知识,并学习如何通过实现K-最近邻算法来构建一个使用协同过滤的电影推荐系统。我们还将根据邻居预测给定电影的评级,并将其与实际评级进行比较。
推荐系统的类型
推荐系统大致可分为三类
协同过滤
基于内容的筛选
混合推荐系统
协同过滤
这种过滤方法通常基于收集和分析用户的行为、活动或偏好信息,并根据与其他用户的相似性来预测他们会喜欢什么。协作过滤方法的一个主要优点是它不依赖于机器可分析的内容,因此它能够准确地推荐诸如电影之类的复杂项目,而不需要“理解”项目本身。
此外,还有几种类型的协同过滤算法
- 用户-用户协同过滤:尝试搜索相似的客户,并根据他/她的相似选择提供产品。
- 项-项协同过滤:它与前面的算法非常相似,但是我们没有找到一个看起来很相似的客户,而是尝试查找相似的项。一旦我们有了商品外观相似矩阵,我们就可以很容易地向从商店购买商品的顾客推荐相似的商品。
- 其他算法:还有其他方法,如市场篮子分析,它通过寻找交易中经常出现的项目组合来工作。
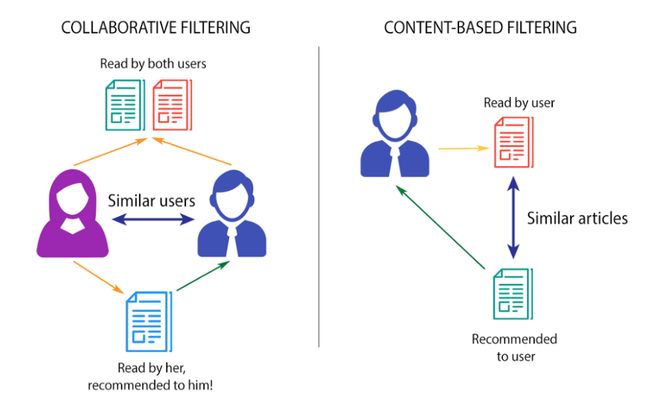
基于内容的过滤
这些过滤方法基于对项目的描述和用户的配置文件。在基于内容的推荐系统中,使用关键字来描述项目,并建立用户配置文件来说明用户喜欢的项目类型。换句话说,这些算法试图推荐与用户过去喜欢的产品相似的产品。
混合推荐系统
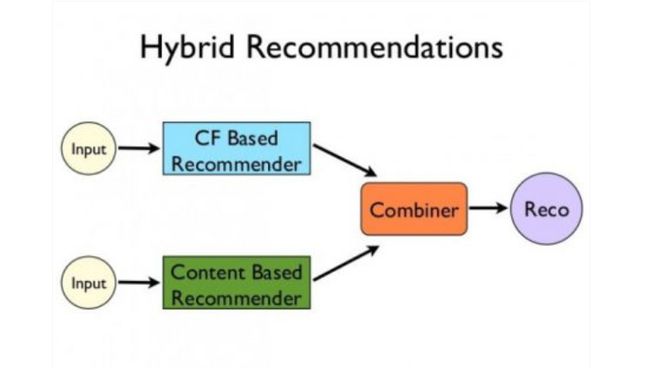
最近的研究表明,结合协作过滤和基于内容的过滤的混合方法在某些情况下可能更有效。混合方法可以通过多种方式实现,分别进行基于内容的预测和基于协作的预测,然后将它们组合在一起,将基于内容的特征添加到基于协作的方法中(或者反之亦然),或者将这些方法统一到一个模型中。
Netflix是使用混合推荐系统的一个很好的例子。该网站通过比较相似用户的观看和搜索习惯(即协作过滤)以及提供与用户评价较高的电影具有相同特征的电影(基于内容的过滤)来提出建议。
现在我们已经对推荐系统有了基本的直觉,让我们从用Python构建一个简单的电影推荐系统开始。
在这里找到包含完整代码、数据集和所有插图的Python Notebook https://www.kaggle.com/heeraldedhia/movie-ratings-and-recommendation-using-knn
TMDb-电影数据库
电影数据库(TMDb)是一个社区建立的电影和电视数据库,它拥有大量关于电影和电视节目的数据。以下是统计数据:https://www.themoviedb.org/
为了简单和易于计算,我使用了这个巨大数据集的一个子集,即TMDb 5000数据集。它有5000部电影的信息,分成2个CSV文件。
- tmdb_5000_movies.包含分数、标题、发布日期、流派等信息。
- tmdb_5000_credits.csv:包含每部电影的演员和剧组信息。
数据集的链接在这里:https://www.kaggle.com/tmdb/tmdb-movie-metadata
Python实现
步骤1-导入数据集
导入所需的Python库,如Pandas、Numpy、Seaborn和Matplotlib。然后使用Pandas中预定义的read_CSV()函数导入CSV文件。
movies = pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_movies.csv')
credits = pd.read_csv('../input/tmdb-movie-metadata/tmdb_5000_credits.csv')
步骤2-数据探索和清理
我们将首先使用head(),descripe()函数来查看数据集的值和结构,然后继续清理数据。
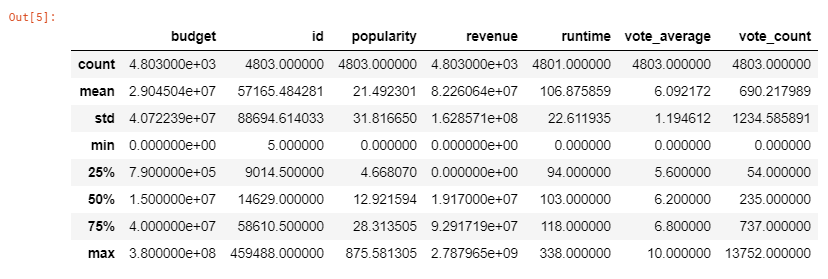
movies.head()
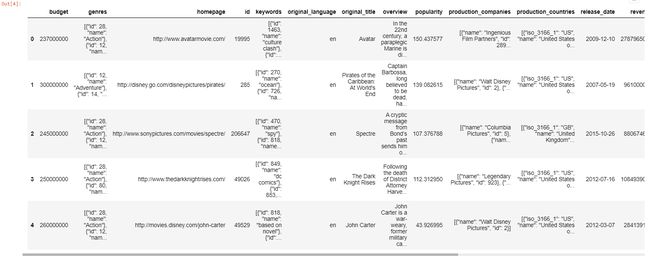
movies.describe()
类似地,我们可以得到credits数据帧,并得到如下输出

检查数据集,我们可以看到genres, keywords、production_companies、production_countries、spoken_languages都是JSON格式。类似地,在其他CSV文件中,cast和crew都是JSON格式。现在让我们将这些列转换为易于阅读和解释的格式。我们将把它们转换成字符串,稍后再转换成列表,以便于解释。
JSON格式类似于嵌入到字符串中的dictionary(key:value)对。一般来说,解析数据在计算上是昂贵和耗时的。幸运的是,这个数据集没有那么复杂的结构。列之间的一个基本相似之处是它们有一个name键,它包含我们需要收集的值。最简单的方法是解析JSON并检查每行的name键。找到name键后,将其值存储到一个列表中,并用list替换JSON。
但是我们不能直接解析这个JSON,因为它必须首先被解码。为此,我们使用json.loads把它解码。然后,我们可以通过这个列表来分析以找到所需的值。让我们看看下面正确的语法。
# 将genres列从json更改为string
movies['genres'] = movies['genres'].apply(json.loads)
for index,i in zip(movies.index,movies['genres']):
list1 = []
for j in range(len(i)):
list1.append((i[j]['name'])) # “name”包含流派的名称
movies.loc[index,'genres'] = str(list1)
以类似的方式,我们将把JSON转换为列的字符串列表:keywords、production_companys、cast和crew。我们将使用movies.iloc[index]

步骤3-合并2个CSV文件
我们将合并movies和credits数据帧并选择所需的列,并有一个统一的movies dataframe来处理。
movies = movies.merge(credits, left_on='id', right_on='movie_id', how='left')
movies = movies[['id', 'original_title', 'genres', 'cast', 'vote_average', 'director', 'keywords']]
我们可以检查像这样的电影的大小和属性-
第4步-使用“Genres”列
我们将清除“Genres ”列以找到“genre”列表
movies['genres'] = movies['genres'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['genres'] = movies['genres'].str.split(',')
让我们根据电影类型的发生情况来描绘电影类型,以便从流行程度上深入了解电影类型。
plt.subplots(figsize=(12,10))
list1 = []
for i in movies['genres']:
list1.extend(i)
ax = pd.Series(list1).value_counts()[:10].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('hls',10))
for i, v in enumerate(pd.Series(list1).value_counts()[:10].sort_values(ascending=True).values):
ax.text(.8, i, v,fontsize=12,color='white',weight='bold')
plt.title('Top Genres')
plt.show()
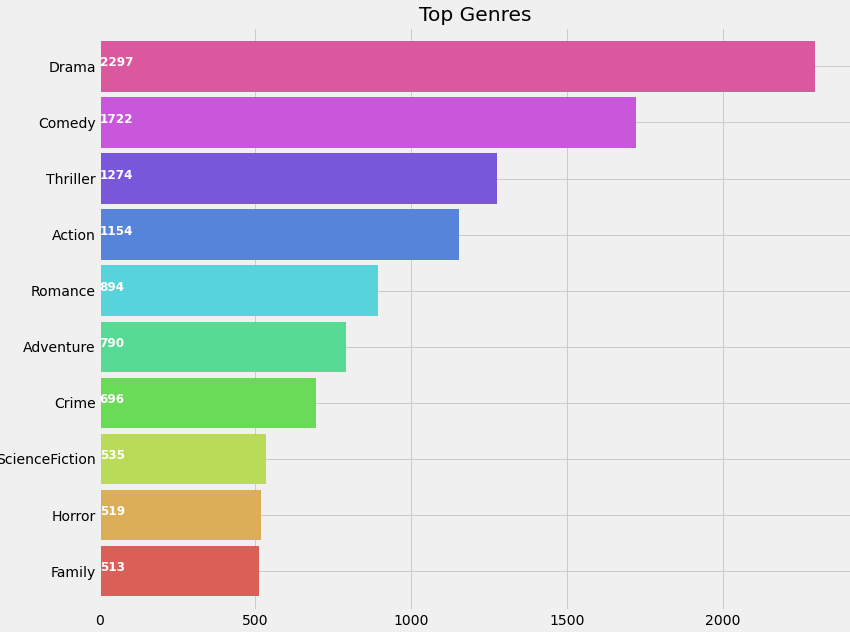
戏剧似乎是继喜剧之后最受欢迎的类型
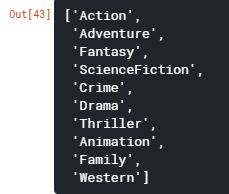
现在让我们生成一个列表“genreList”,其中包含数据集中提到的所有可能的唯一类型。
genreList = []
for index, row in movies.iterrows():
genres = row["genres"]
for genre in genres:
if genre not in genreList:
genreList.append(genre)
genreList[:10] # 现在我们有了一个流派的列表
one-hot编码
“genreList”将保存所有流派。但是我们如何才能知道每部电影所属的类型呢。现在有些电影是“动作片”,有些是“动作片,冒险片”,等等。我们需要根据电影类型对电影进行分类。
让我们在dataframe中创建一个新列,该列将保存二值,表示是否存在该流派。首先,让我们创建一个方法,它将返回每个电影流派的二值列表。“genreList”现在可用于与值进行比较。
举个例子,我们在列表中有20个流派。因此,下面的函数将返回一个包含20个元素的列表,这些元素可以是0或1。例如,我们有一部电影,其中genre='Action',那么新列将包含[1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。
类似于“动作,冒险”,我们会有[1,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]。将流派转换成这样的二值列表将有助于轻松地按流派对电影进行分类。
def binary(genre_list):
binaryList = []
for genre in genreList:
if genre in genre_list:
binaryList.append(1)
else:
binaryList.append(0)
return binaryList
将binary()函数应用于“genres”列以获取“genre_list”
对于其他特征,如演员、导演和关键字,我们将遵循相同的符号。
movies['genres_bin'] = movies['genres'].apply(lambda x: binary(x))
movies['genres_bin'].head()
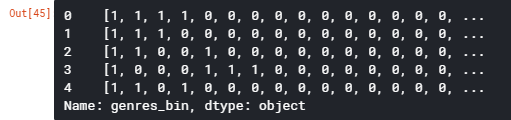
步骤5-使用Cast列
让我们画一张演员出场率最高的图表
plt.subplots(figsize=(12,10))
list1=[]
for i in movies['cast']:
list1.extend(i)
ax=pd.Series(list1).value_counts()[:15].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('muted',40))
for i, v in enumerate(pd.Series(list1).value_counts()[:15].sort_values(ascending=True).values):
ax.text(.8, i, v,fontsize=10,color='white',weight='bold')
plt.title('Actors with highest appearance')
plt.show()
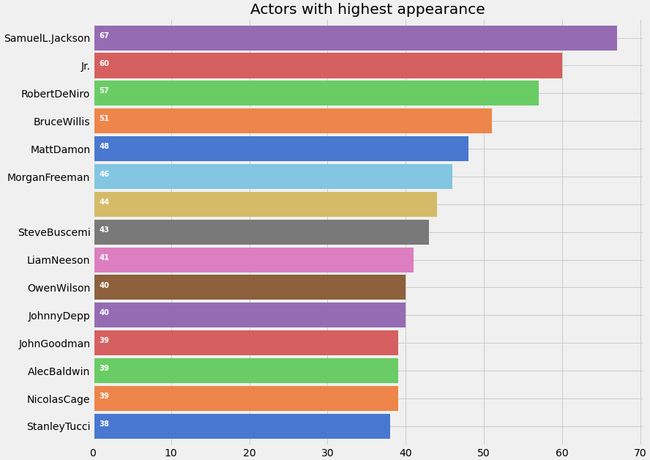
塞缪尔·杰克逊,也就是《复仇者》中的尼克·弗瑞出现在最多的电影中。我最初以为摩根·弗里曼可能是电影数量最多的演员,但数据胜于假设!
当我最初创建所有演员的列表时,它有大约5万的唯一值,因为很多电影都有大约15-20个演员的条目。
但我们需要所有这些吗?答案是否定的。我们只需要对电影有最大贡献的演员。《黑暗骑士》系列电影有很多演员参演。但是我们只会选择主要演员,比如克里斯蒂安·贝尔,迈克尔·凯恩,希斯·莱杰。我已经从每部电影中选出了4位主要演员。
你可能会想到一个问题,那就是你如何确定演员在电影中的重要性。幸运的是,JSON格式中的演员顺序是根据演员对电影的贡献而定的。
让我们看看我们是如何做到这一点的,并创建一个列“cast_bin”
for i,j in zip(movies['cast'],movies.index):
list2 = []
list2 = i[:4]
movies.loc[j,'cast'] = str(list2)
movies['cast'] = movies['cast'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['cast'] = movies['cast'].str.split(',')
for i,j in zip(movies['cast'],movies.index):
list2 = []
list2 = i
list2.sort()
movies.loc[j,'cast'] = str(list2)
movies['cast']=movies['cast'].str.strip('[]').str.replace(' ','').str.replace("'",'')castList = []
for index, row in movies.iterrows():
cast = row["cast"]
for i in cast:
if i not in castList:
castList.append(i)movies[‘cast_bin’] = movies[‘cast’].apply(lambda x: binary(x))
movies[‘cast_bin’].head()

第6步-使用“Directors ”列
让我们画一张导演出场率最高的图表
def xstr(s):
if s is None:
return ''
return str(s)
movies['director'] = movies['director'].apply(xstr)plt.subplots(figsize=(12,10))
ax = movies[movies['director']!=''].director.value_counts()[:10].sort_values(ascending=True).plot.barh(width=0.9,color=sns.color_palette('muted',40))
for i, v in enumerate(movies[movies['director']!=''].director.value_counts()[:10].sort_values(ascending=True).values):
ax.text(.5, i, v,fontsize=12,color='white',weight='bold')
plt.title('Directors with highest movies')
plt.show()
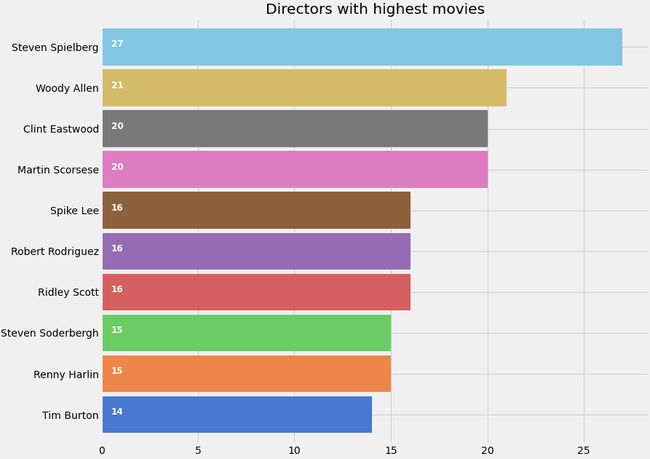
我们创建了一个新的列“director_bin”,正如我们之前所做的那样
directorList=[]
for i in movies['director']:
if i not in directorList:
directorList.append(i)movies['director_bin'] = movies['director'].apply(lambda x: binary(x))
movies.head()
最后,在完成了所有这些工作之后,我们得到了如下所示的movies数据集

步骤7-使用Keywords列
关键字或标记包含关于电影的大量信息,这是查找类似电影的关键功能。例如:像《复仇者》和《蚂蚁侠》这样的电影可能有一些共同的关键词,比如超级英雄或者奇迹。
为了分析关键词,我们将尝试不同的方法,并绘制一个词云,以获得更好的直觉:
from wordcloud import WordCloud, STOPWORDS
import nltk
from nltk.corpus import stopwordsplt.subplots(figsize=(12,12))
stop_words = set(stopwords.words('english'))
stop_words.update(',',';','!','?','.','(',')','$','#','+',':','...',' ','')words=movies['keywords'].dropna().apply(nltk.word_tokenize)
word=[]
for i in words:
word.extend(i)
word=pd.Series(word)
word=([i for i in word.str.lower() if i not in stop_words])
wc = WordCloud(background_color="black", max_words=2000, stopwords=STOPWORDS, max_font_size= 60,width=1000,height=1000)
wc.generate(" ".join(word))
plt.imshow(wc)
plt.axis('off')
fig=plt.gcf()
fig.set_size_inches(10,10)
plt.show()
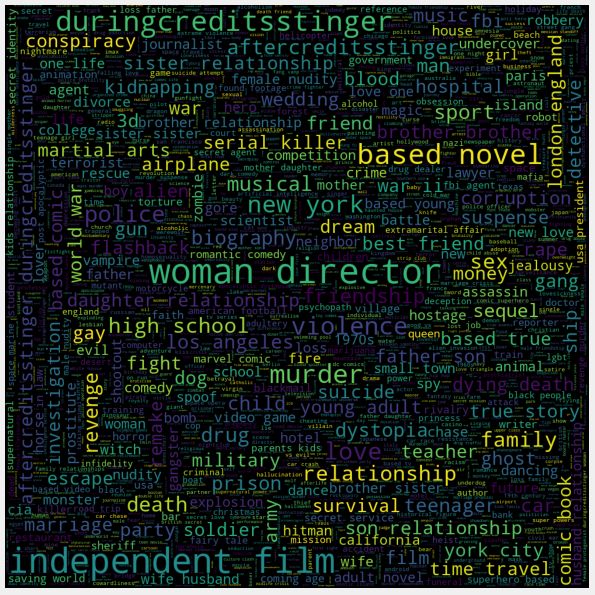
上面是一个单词云,显示了描述电影的主要关键字或标签
我们从以下关键字中找到“words_bin”
movies['keywords'] = movies['keywords'].str.strip('[]').str.replace(' ','').str.replace("'",'').str.replace('"','')
movies['keywords'] = movies['keywords'].str.split(',')
for i,j in zip(movies['keywords'],movies.index):
list2 = []
list2 = i
movies.loc[j,'keywords'] = str(list2)
movies['keywords'] = movies['keywords'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['keywords'] = movies['keywords'].str.split(',')
for i,j in zip(movies['keywords'],movies.index):
list2 = []
list2 = i
list2.sort()
movies.loc[j,'keywords'] = str(list2)
movies['keywords'] = movies['keywords'].str.strip('[]').str.replace(' ','').str.replace("'",'')
movies['keywords'] = movies['keywords'].str.split(',')words_list = []
for index, row in movies.iterrows():
genres = row["keywords"]
for genre in genres:
if genre not in words_list:
words_list.append(genre)movies['words_bin'] = movies['keywords'].apply(lambda x: binary(x))
movies = movies[(movies['vote_average']!=0)] #删除得分为0且没有drector名称的电影
movies = movies[movies['director']!='']
步骤8-电影之间的相似性
我们将使用余弦相似性来寻找两部电影之间的相似性。余弦相似性是如何工作的?
假设我们有两个向量。如果向量接近平行,即向量之间的夹角为0,那么我们可以说它们都是“相似的”,因为cos(0)=1。然而,如果向量是正交的,那么我们可以说它们是独立的或不“相似的”,因为cos(90)=0。
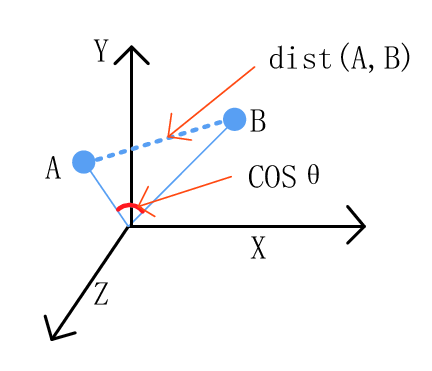
下面是详细的研究链接:http://blog.christianperone.com/2013/09/machine-learning-cosine-similarity-for-vector-space-models-part-iii/
下面我定义了一个函数相似度,它将检查电影之间的相似性。
from scipy import spatialdef Similarity(movieId1, movieId2):
a = movies.iloc[movieId1]
b = movies.iloc[movieId2]
genresA = a['genres_bin']
genresB = b['genres_bin']
genreDistance = spatial.distance.cosine(genresA, genresB)
scoreA = a['cast_bin']
scoreB = b['cast_bin']
scoreDistance = spatial.distance.cosine(scoreA, scoreB)
directA = a['director_bin']
directB = b['director_bin']
directDistance = spatial.distance.cosine(directA, directB)
wordsA = a['words_bin']
wordsB = b['words_bin']
wordsDistance = spatial.distance.cosine(directA, directB)
return genreDistance + directDistance + scoreDistance + wordsDistance
让我们检查两部随机电影之间的相似性

我们看到距离大约是2.068,这是很高的。距离越远,电影就越不相似。让我们看看这些随机电影到底是什么。
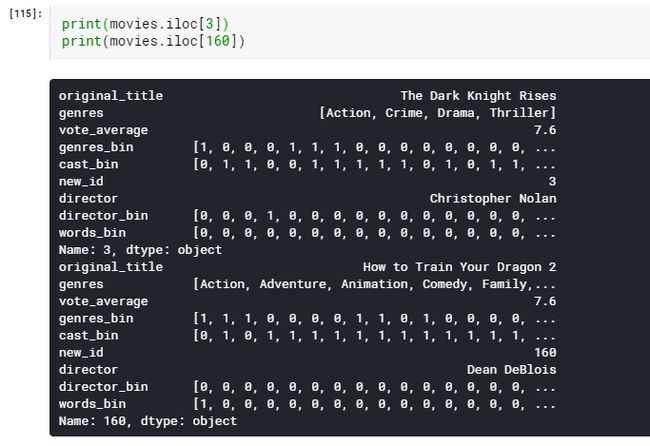
很明显,黑暗骑士崛起和驯龙高手2是非常不同的电影。因此,距离是巨大的。
步骤9-分数预测器
所以现在当我们把所有的事情都准备好了,我们现在就要建立一个分数预测器。主要函数是Similarity()函数,它将计算电影之间的相似性,并将找到10部最相似的电影。这10部电影将有助于预测我们想要的电影的分数。我们将取相似电影得分的平均值,然后找到想要的电影的分数。
现在,电影之间的相似性将取决于我们新创建的包含二值列表的列。我们知道,像导演或演员这样的特点将在电影的成功中扮演非常重要的角色。我们总是认为大卫·芬奇(David Fincher)和克里斯·诺兰(Chris Nolan)的电影会取得好成绩。此外,如果他们与自己最喜欢的演员合作,这些演员总是能给他们带来成功,并且也在他们最喜欢的题材上工作,那么成功的几率就会更高。利用这些现象,让我们尝试建立我们的分数预测器。
import operatordef predict_score():
name = input('Enter a movie title: ')
new_movie = movies[movies['original_title'].str.contains(name)].iloc[0].to_frame().T
print('Selected Movie: ',new_movie.original_title.values[0])
def getNeighbors(baseMovie, K):
distances = []
for index, movie in movies.iterrows():
if movie['new_id'] != baseMovie['new_id'].values[0]:
dist = Similarity(baseMovie['new_id'].values[0], movie['new_id'])
distances.append((movie['new_id'], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(K):
neighbors.append(distances[x])
return neighbors
K = 10
avgRating = 0
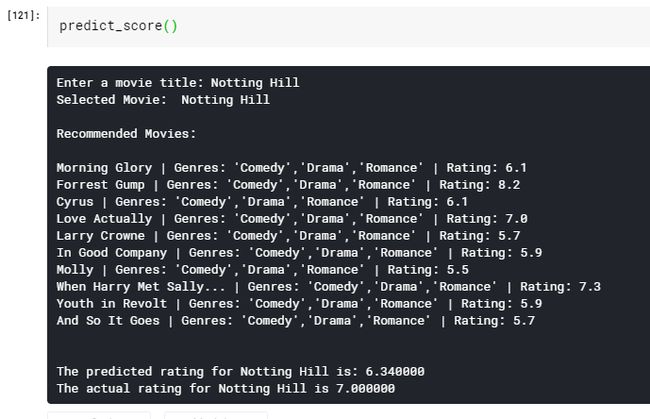
neighbors = getNeighbors(new_movie, K)print('\nRecommended Movies: \n')
for neighbor in neighbors:
avgRating = avgRating+movies.iloc[neighbor[0]][2]
print( movies.iloc[neighbor[0]][0]+" | Genres: "+str(movies.iloc[neighbor[0]][1]).strip('[]').replace(' ','')+" | Rating: "+str(movies.iloc[neighbor[0]][2]))
print('\n')
avgRating = avgRating/K
print('The predicted rating for %s is: %f' %(new_movie['original_title'].values[0],avgRating))
print('The actual rating for %s is %f' %(new_movie['original_title'].values[0],new_movie['vote_average']))
现在只需运行函数如下,并输入你喜欢的电影10个相似的电影和它的预测收视率
predict_score()

从而完成了基于K近邻算法的电影推荐系统的实现。
K值
在这个项目中,我任意选择了K=10的值。
但在KNN的其它应用中,求K值并不容易。较小的K值意味着噪声对结果的影响更大,而较大的K值会导致计算开销。数据科学家通常选择奇数,如果类的数目是2,另一个选择k的简单方法是设置k=sqrt(n)。
在这里找到包含完整代码、数据集和所有插图的Python Notebook:https://www.kaggle.com/heeraldedhia/movie-ratings-and-recommendation-using-knn
进一步阅读
推荐系统:https://en.wikipedia.org/wiki/Recommender_system
基于K近邻算法的机器学习基础:https://towardsdatascience.com/machine-learning-basics-with-the-k-nearest-neighbors-algorithm-6a6e71d01761
使用Python的推荐系统.第2部分:协同过滤(K-最近邻算法):https://heartbeat.fritz.ai/recommender-systems-with-python-part-ii-collaborative-filtering-k-nearest-neighbors-algorithm-c8dcd5fd89b2#:~:text=When%20a%20KNN%20makes%20a,the%20most%20similar%20movie%20recommendations.
什么是余弦相似性?:https://deepai.org/machine-learning-glossary-and-terms/cosine-similarity
如何在KNN中找到K的最优值?:https://towardsdatascience.com/how-to-find-the-optimal-value-of-k-in-knn-35d936e554eb
原文链接:https://www.analyticsvidhya.com/blog/2020/08/recommendation-system-k-nearest-neighbors/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/