前面我们介绍了3大类核心转换场景。
【ETL】系列四:核心转换场景—单表间直转
【ETL】系列五:核心转换场景-字段合并与字段拆分
【ETL】系列六:核心转换场景-行转列与列转行
之前的三篇文章,主要针对来源数据进行直接映射处理,并未涉及到来源表数据清洗后再同步到目标表的场景。今天这个篇幅,我们来介绍规格化清洗的转换场景。
希望在这篇文章结束之后,你可以对以下问题有进一步的理解。
什么是规格化清洗?
怎么用kettle对数据进行规格化清洗?
kettle的规格化清洗有哪些不足?如何改进?
一、什么是规格化清洗?
规格化就是将一个属性取值范围投射到一个特定范围之内,以消除数值型属性因大小不一而造成挖掘结果的偏差。
规格化清洗应用于来源表的数据并非直接进行转换的应用场景,即当来源表的数据与目标表数据由于一些格式上的差异产生的不一致,需要经过清洗以保证数据的规范性时,转换的流程中就会用到规格化清洗,以消除数据上的偏差,输出干净、规范的数据。
接下来,我们通过具体的实例来介绍几类常见的规格化清洗的规则。
1、文本清洗规则
2、数值清洗规则
3、日期清洗规则
(一)文本清洗规则
文本清洗规则用于处理文本字符串的,数据库的字段类型是文本类型,如CHAR、VARCHAR、TEXT等串数据类型。
文本规格化清洗样例:
| 清洗规则 | 规则描述 | 清洗前数据 | 清洗后数据 |
|---|---|---|---|
| 首字母转大写,其他小写 | 当字段值包含英文词:首字母转大写,其他小写 | BEIJING TECHNOLOGY CO.,LTD beijing technology co.,ltd |
Beijing Technology Co.,Ltd |
| 去除(数字,中文)序号 | 当字段值为“序号”+“内容”组合,去除首位序号: 1、必须包含明确序号特征 :. 。、, )】]()()【】[] 2、必须包含数字或中文数字 如 :1-999, 一-九百九十九 |
2、内容 2。内容 2,内容 2】内容 2)内容 2]内容 (2)内容 (2)内容 【2】内容 [2]内容 |
内容 |
(二)数值清洗规则
数值清洗规则用于处理数值的,数据库的字段类型是数值类型,如BIT、BIGINT、FLOAT等数值数据类型。
数值规格化清洗样例:
| 清洗规则 | 规则描述 | 清洗前数据 | 清洗后数据 |
|---|---|---|---|
| 财务类括号转为负号 | 当字段值包含财务类括号,将其转为负号 | (16,725,226.56) | -16,725,226.56 |
| 去除千分位号 | 当字段值包含千分位号,去除千分位号 | 16,725,226.56 | 16725226.56 |
(三)日期清洗规则
数值清洗规则用于处理日期和时间的,数据库的字段类型是数值类型,如DATE、DATETIME、TIME等数值数据类型。
日期规格化清洗样例:
| 清洗规则 | 规则描述 | 清洗前数据 | 清洗后数据 |
|---|---|---|---|
| 统一日期格式YYYY-MM-DD | 当字段值为日期,将日期数据统一转为YYYY-MM-DD格式 | 2019/11/25 2019年11月25日 2019.11.25 20191125 |
2019-11-25 |
| 获取系统时间(精确到秒) | 获取系统时间(精确到秒) | 2019-11-25 | 2019-11-25 15:55:00 |
二、怎么用kettle对数据进行规格化清洗?
Kettle里没有单一的数据清洗步骤,但有很多的步骤组合起来可以完成数据清洗的功能。
我们将通过几种方式来进行规格化清洗的实操。
操作方式1:通过JavaScript 函数进行数据清洗
实操样例:将来源数据中的字符串首字母转大写,其他小写,如清洗前的“BEIJING TECHNOLOGY CO.,LTD”和“beijing technology co.,ltd”清洗为“Beijing Technology Co.,Ltd”。
操作步骤:
1、点击左侧的 核心对象,选择自定义常量数据,进行待清洗数据的定义。
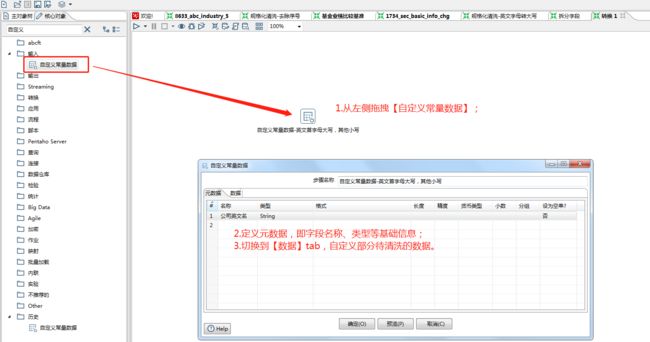
2、点击左侧的 核心对象, 选择javaScript脚本 ,进行字符串函数的配置。

变量信息输入: 由于在上一步“自定义常量数据”中已定义元数据为“公司英文名”,因此我们只需要在 “java script:”下的输入框中输入initCap(var)声明变量。
var result = initCap(公司英文名)
3、点击左侧的 **核心对象 ** ,选择 **Excel输出 **插件,定义清洗后数据的存储位置。

以上是一个通过JavaScript 函数对数据进行清洗的操作方式。
关于在Kettle中 JavaScript内置函数说明可以参考这篇文章的介绍:
https://blog.csdn.net/u010192145/article/details/102220563
操作方式2:通过字符串替换插件进行数据清洗
实操样例:将来源数据中的字符串去除(数字,中文)序号,如清洗前的“2、内容 2。内容 2,内容 2】内容 2)内容 2]内容(2)内容 (2)内容 (2)内容 【2】内容”清洗为“内容”。
操作步骤:
1、点击左侧的 核心对象,选择自定义常量数据,进行待清洗数据的定义。

2、点击左侧的 核心对象, 选择字符串替换 ,进行字符串替换的配置。

在这里,需要理解输入流字段、输出流字段、使用正则表达式、搜索、使用…替换、设置为空串、使用字段值替换等的含义。
1.输入流字段:上一步骤中自定义常量数据定义的元数据名称,该样例中输入流字段为“简介”;
2.输出流字段:自己命名,用来保存处理后的结果的字段,可以和输入流字段保持一致,也可以在命名上做一点区分,该样例中的输出流字段我们定义为“清洗后简介”;
3.使用正则表达式:可以选择使用正则表达式,搜索匹配范围会更加灵活准确,这里我们选择“是”;
4.搜索:就是你希望被替换的字符、字符串,可以是一个正则表达式,针对待清洗数据需要具体数据具体分析,这里我们使用了正则表达式来搜索,如“\d.[、,。,】))[]【】()()(【[]”;
5、使用…替换:就是你期望用什么值替换被替换的部分,这该样例是需要将数据和中文的序号去除,因此,替换为空值即可,此处不填内容;
6、设置为空串:将被选择的部分用空替换;
7、使用字段值替换:可以使用现有的某个字段的值替换你期望被替换的部分;
8、整个单词匹配:搜索范围是否是整个单词;
9、大小写敏感:搜索范围是否需要区分大小写,主要是针对字母的。
3、点击左侧的 **核心对象 ** ,选择 **Excel输出 **插件,定义清洗后数据的存储位置,查看清洗结果。
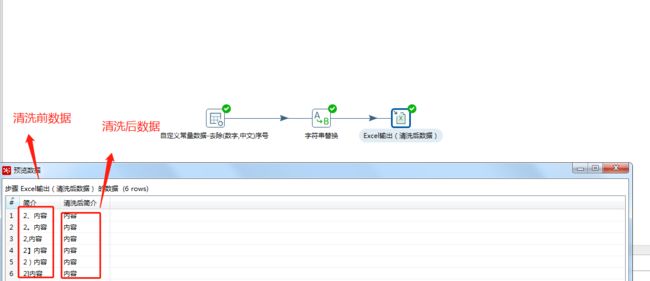
字符串替换是个比较好用的清洗插件,对于上文中提到【财务类括号转为负号】、【去除千分位号】等数值清洗都是适用的,此处不做赘述。
操作方式3:通过SQL函数进行数据清洗
实操样例:将来源库A中的【TQ_COMP_INFOCHG(机构信息变动表)】的数据推送到目标数据库B【org_basic_info_chg(机构信息变动表)】,并对来源表中的日期字段YYYYMMDD(如20191125)格式的值规格化清洗为YYYY-MM-DD(如2019-11-25)。
操作步骤:
1、选择表输入并把它拖到右侧的编辑区中进行配置,主要是进行自定义SQL语句。
SQL语句中,通过CAST函数将需要进行日期格式转换的字段进行语句的输入。
SQL语句如下:
SELECT
ID, COMPCODE,CAST(PUBLISHDATE AS DATE) , CHGTYPE, CAST(BEGINDATE AS DATE) , CAST(ENDDATE AS DATE) , BECHG, AFCHG, CHGEXP
FROM TQ_COMP_INFOCHG where COMPCODE='10000001'

2、选择插入/更新并把它拖到右侧的编辑区中进行相关配置。

3、查看清洗转换结果。
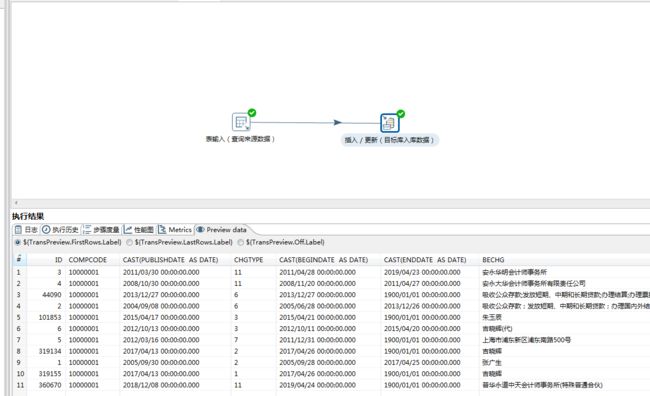
4、转换成功后,也可以检查本地数据库,查看数据是否推送成功,是否将日期字段进行正确清洗。


我们在使用SQL语句时,有一个重要的内容就是使用数据处理函数,SQL支持利用函数来处理数据,函数一般是在数据上执行的,它给数据的转换和处理提供了方便,也是规格化清洗的常见的实现方式。
操作方式4:通过获取系统信息插件进行数据清洗
实操样例:获取系统时间(精确到秒)
操作步骤:
1、点击左侧的 核心对象,选择获取系统信息插件,选择要获取的信息类型。

选择获取系统日期后,得到的日期格式为YYYY/MM/DD HH:MM:SS XXX,我们需要将改格式转换为 YYYY/MM/DD HH:MM:SS。
2、点击左侧的 核心对象,选择字段选择插件,进行日期格式的转换。

如截图所示,在元数据tab中进行字段类型的变更,将Date 类型的格式定义为yyyy-MM-dd HH:mm:ss。
3、点击左侧的 核心对象 ,选择 Excel输出插件,定义清洗后数据的存储位置,并查看清洗后的日期数据。

以上是4类规格化清洗的方式,除了已介绍的方式,kettle还提供了其他的规格化清洗的方法,在此就不一一描述了。
三、 kettle的规格化清洗有哪些不足?如何改进?
从上述介绍的一些规格化清洗的方式中,相信大家一方面觉得kettle的强大,另一方面也会发现在操作会相对繁琐,学习成本较高。
Kettle的规格化清洗有哪些不足:
1、多种清洗方式,增加学习成本:不同清洗要求的数据需要使用不同的清洗方式,在kettle中缺少聚合、交互统一的清洗模块;
2、多个清洗规则无法快速配置:实际业务中,针对来源表的清洗字段,需要用到多个清洗规则,在kettle中无法快速配置;
3、缺少批量操作:清洗插件中的操作,缺少批量操作功能,影响配置效率;
4、清洗规则缺少继承关系和互斥关系:数据表中的清洗规则部分是同通用的,可以适用于全库数据,部分清洗规则之间是互斥的,互斥规则会导致清洗结果无效,这在kettle中无法有效地满足具体的业务需求;
5、缺失清洗规则之外的管理功能:缺失以来源表等维度的清洗规则的增删查改和操作日志等管理功能。
规格化清洗的改进方向:
在实际的业务处理过程中,上述提到的kettle规格化清洗的不足,会导致ETL模型配置繁杂,耗时耗力,且无法有效地管理积累的规格化清洗规则。对于ETL工具产品来说,是明显的短板,需要去不断优化,以下就kettle规格化清洗的不足,分享几个改进方向。
1、整合kettle已有的清洗规则:kettle的清洗规则已经很全面了,但是缺少规则的系统性整合,也缺少针对具体业务的相对定制化的清洗规则,可以从数据业务中,抽取出一类业务的清洗规则,减少业务人员对具体规则的配置;
2、支持自定义规则集:一类待清洗数据使用一类已定义好的清洗规则集,减少单个规则的选择和配置;
3、增加批量操作:对于清洗规则的配置、规则集的定义、规则执行方式的设置都需要在交互上支持批量操作;
4、增加清洗服务的管理功能:对于具体的业务来说,需要支持数据表、规则名称等维度的管理功能,可以按照业务所需的维度,进行清洗规则的查看、新增、修改和删除,当然,对于规则的操作日志都需要完整地被记录下来。
除了上述的一些改进方向之外,还有很多可以挖掘改进的点,这些就需要根据具体业务来不断梳理和实现了。
总之,作为产品经理来说,你需要用户在使用产品时,能够满足多!!快!!好!!爽!!的需求。也就是:
支持的清洗规则多!
配置和运行的速度快!
产品的体验好!
才能用的爽!
以上。