hive窗口函数及笔试题目总结
窗口函数及例子
- 一、函数介绍
-
-
- 1、OVER():
- 2、其他函数
- 3、排序函数介绍
-
- 二、over使用介绍
-
- 1、数据准备
- 2、查询购买顾客姓名及购买总人数–窗口大小为筛选后的数据集
-
- 2.1 分组查询购买顾客姓名,但是没有顾客总数
- 2.2 使用over计算购买总人数
- 2.3 sql讲解:count(*) over()
- 3、查询顾客的购买明细及 月购买总额-窗口分区大小
-
- 3.1 购买明细
- 3.2 购买明细及总额
- 3.3 总额计算解析
- 4、求每个用户购买明细及将cost按照日期进行累加
- 4、其他参数介绍
- 5、查看顾客上次的购买时间-lag函数使用
- 6、查看顾客下一次购买时间-lead函数使用
- 7、查询前20%时间的订单信息-ntile函数使用
-
- 7.1 为数据分区
- 7.2 查询分区编号为1的数据就是前20%的数据
- 三、排序介绍
- 笔试题目
-
- 1 统计视频观看数Top10
- 2 统计视频类别热度Top10
- 3 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
- 4 统计视频观看数Top50所关联视频的所属类别排序
- 5 统计每个类别中的视频热度Top10,以Music为例
- 6 统计每个类别中视频流量Top10,以Music为例
- 7 统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
- 8 统计每个类别视频观看数Top10
- 总结
2.窗口函数的语法:
UDAF() over (PARTITION By col1,col2 order by col3 窗口子句(rows between … and …)) AS 列别名
注意:PARTITION By后可跟多个字段,order By只跟一个字段。
3.over()的作用
over()决定了聚合函数的聚合范围,默认对整个窗口中的数据进行聚合,聚合函数对每一条数据调用一次。
例如:
select name, orderdate, cost, sum(cost) over()
from business;
4.partition by子句:
使用Partiton by子句对数据进行分区,可以用paritition by对区内的进行聚合。
例如:
select name, orderdate, cost, sum(cost) over(partition by name)
from business;
5.order by子句:
作用:
(1)对分区中的数据进行排序;
(2)确定聚合哪些行(默认从起点到当前行的聚合)
例如:
select name, orderdate, cost, sum(cost) over(partition by name order by orderdate)
from business;
6.窗口子句
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
通过使用partition by子句将数据进行了分区。如果想要对窗口进行更细的动态划分,
就要引入窗口子句。
例如:
select name, orderdate,cost, sum(cost)
over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and CURRENT ROW)
from business;
7.几点注意:
(1)order by必须跟在partition by后;
(2)Rows必须跟在Order by子;
(3)(partition by … order by)可替换为(distribute by … sort by …)
一、函数介绍
1、OVER():
指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化,例如分区排序;
over函数相关参数:
partition by:分区,窗口大小为分区
order by:一般与分区相结合使用,窗口大小为排序后的数据起点到当前行
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
2、其他函数
LAG(col,n):往前第n行数据
LAG(col,n):往前第n行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
此三个函数都需要over() 开窗来确定数据范围大小,不然单独无法使用
3、排序函数介绍
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
一样需要over函数来开窗确定数据范围大小。
二、over使用介绍
(1)查询在2017年4月份购买过的顾客及总人数
(2)查询顾客的购买明细及月购买总额
(3)上述的场景, 将每个顾客的cost按照日期进行累加
(4)查询每个顾客上次的购买时间
(5)查询前20%时间的订单信息
1、数据准备
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,94
建表
create table business(
name string,
orderdate string,
cost int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
导入
load data local inpath "/opt/module/datas/business.txt" into table business;
2、查询购买顾客姓名及购买总人数–窗口大小为筛选后的数据集
2.1 分组查询购买顾客姓名,但是没有顾客总数
hive (default)> select name from business group by name;
2.2 使用over计算购买总人数
hive (default)> select name,count(*) over() from business group by name;
name count_window_0
jack 4
mart 4
neil 4
tony 4
2.3 sql讲解:count(*) over()
count(*) 为合计
over为当前count函数确定需要合计的数据窗口大小,由于over中没有参数,name就是筛选后的数据全集为窗口大小
3、查询顾客的购买明细及 月购买总额-窗口分区大小
数据窗口分区:按照月份分区
3.1 购买明细
select name,orderdate,cost from business;
3.2 购买明细及总额
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
name orderdate cost sum_window_0
jack 2017-01-01 10 205
tony 2017-01-02 15 205
tony 2017-01-04 29 205
jack 2017-01-05 46 205
tony 2017-01-07 50 205
jack 2017-01-08 55 205
jack 2017-02-03 23 23
mart 2017-04-13 94 341
mart 2017-04-08 62 341
mart 2017-04-09 68 341
mart 2017-04-11 75 341
jack 2017-04-06 42 341
neil 2017-05-10 12 12
neil 2017-06-12 80 80
3.3 总额计算解析
over(partition by month(orderdate)) 按照月份分区,每个窗口大小为所在分区范围大小
4、求每个用户购买明细及将cost按照日期进行累加
hive (default)> select name,orderdate,cost,sum(cost) over(partition by name order by orderdate) from business;
name orderdate cost sum_window_0
jack 2017-01-01 10 10
jack 2017-01-05 46 56
jack 2017-01-08 55 111
jack 2017-02-03 23 134
jack 2017-04-06 42 176
mart 2017-04-08 62 62
mart 2017-04-09 68 130
mart 2017-04-11 75 205
mart 2017-04-13 94 299
neil 2017-05-10 12 12
neil 2017-06-12 80 92
tony 2017-01-02 15 15
tony 2017-01-04 29 44
tony 2017-01-07 50 94
Time taken: 38.788 seconds, Fetched: 14 row(s)
sql解析:sum(cost) over(partition by name order by orderdate)
按照姓名分区,并且区内按照日期排序
4、其他参数介绍
开窗
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加
sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加
sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加
sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合
sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行
sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行
from business;
5、查看顾客上次的购买时间-lag函数使用
select name,orderdate,cost,
lag(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1,
lag(orderdate,2) over (partition by name order by orderdate) as time2
from business;
lag(orderdate,1,‘1900-01-01’):求orderdate列的前一条数据此列值,为null则用默认值1900-01-01
6、查看顾客下一次购买时间-lead函数使用
select name,orderdate,cost,
LEAD(orderdate,1,'1900-01-01') over(partition by name order by orderdate ) as time1,
LEAD(orderdate,2) over (partition by name order by orderdate) as time2
from business;
7、查询前20%时间的订单信息-ntile函数使用
7.1 为数据分区
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business;
7.2 查询分区编号为1的数据就是前20%的数据
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
三、排序介绍
1、数据准备
数据
孙悟空 语文 87
孙悟空 数学 95
孙悟空 英语 68
大海 语文 94
大海 数学 56
大海 英语 84
宋宋 语文 64
宋宋 数学 86
宋宋 英语 84
婷婷 语文 65
婷婷 数学 85
婷婷 英语 78
建表
create table score(
name string,
subject string,
score int)
row format delimited fields terminated by "\t";
导入数据
load data local inpath '/opt/module/datas/score.txt' into table score;
2、三种排序方式比较
select name,
subject,
score,
rank() over(partition by subject order by score desc) rp,
dense_rank() over(partition by subject order by score desc) drp,
row_number() over(partition by subject order by score desc) rmp
from score;
笔试题目
需求描述
统计视频网站的常规指标,各种TopN指标:
--统计视频观看数Top10
--统计视频类别热度Top10
--统计视频观看数Top20所属类别
--统计视频观看数Top50所关联视频的所属类别Rank
--统计每个类别中的视频热度Top10
--统计每个类别中视频流量Top10
--统计上传视频最多的用户Top10以及他们上传的视频
--统计每个类别视频观看数Top10
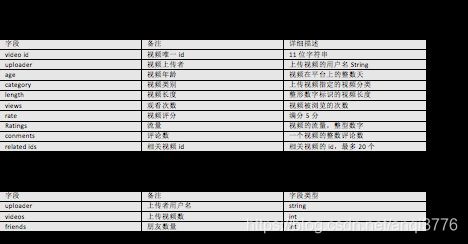
创建表:gulivideo_ori,gulivideo_user_ori,
创建表:gulivideo_orc,gulivideo_user_orc# 系列文章目录
create table gulivideo_ori( videoId string,uploader string,age int,category array<string>,length int,views int,rate float,ratings int,comments int,relatedId array<string>)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as textfile;
create table gulivideo_user_ori( uploader string,videos int, friends int)
row format delimited
fields terminated by "\t"
stored as textfile;
然后把原始数据插入到orc表中
create table gulivideo_orc( videoId string, uploader string,age int,
category array<string>, length int, views int, rate float, ratings int, comments int, relatedId array<string>)
row format delimited fields terminated by "\t"
collection items terminated by "&"
stored as orc;
create table gulivideo_user_orc(uploader string,videos int, friends int)
row format delimited
fields terminated by "\t"
stored as orc;
导入ETL后的数据
gulivideo_ori:
load data inpath "/gulivideo/output/video/2008/0222" into table gulivideo_ori;
gulivideo_user_ori:
load data inpath "/gulivideo/user/2008/0903" into table
gulivideo_user_ori;
向ORC表插入数据
gulivideo_orc:
insert into table gulivideo_orc select * from gulivideo_ori;
gulivideo_user_orc:
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
1 统计视频观看数Top10
思路:使用order by按照views字段做一个全局排序即可,同时我们设置只显示前10条。
最终代码:
select videoId,uploader,age,category,length,views,rate,ratings,comments
from gulivideo_orc
order by view desc
limit
10;
2 统计视频类别热度Top10
思路:
- 即统计每个类别有多少个视频,显示出包含视频最多的前10个类别。
- 我们需要按照类别group by聚合,然后count组内的videoId个数即可。
- 因为当前表结构为:一个视频对应一个或多个类别。所以如果要group by类别,需要先将类别进行列转行(展开),然后再进行count即可。
- 最后按照热度排序,显示前10条。
select
category_name as category, count(t1.videoId) as hot
from (
select videoId,category_name from
gulivideo_orc lateral view explode(category) t_catetory as category_name) t1
group by t1.category_name
order by hot desc
limit 10;
3 统计出视频观看数最高的20个视频的所属类别以及类别包含Top20视频的个数
思路:
- 先找到观看数最高的20个视频所属条目的所有信息,降序排列
- 把这20条信息中的category分裂出来(列转行)
- 最后查询视频分类名称和该分类下有多少个Top20的视频
select category_name as category,count(t2.videoId) as hot_with_views
from (
select videoId,category_name
from (
select * from gulivideo_orc
order by views
desc limit 20) t1
lateral view explode(category) t_catetory as category_name) t2
group by category_name
order by hot_with_views desc;
4 统计视频观看数Top50所关联视频的所属类别排序
思路:
-
查询出观看数最多的前50个视频的所有信息(当然包含了每个视频对应的关联视频),记为临时表t1
t1:观看数前50的视频
select
*
from
gulivideo_orc
order by
views
desc limit
50;
-
将找到的50条视频信息的相关视频relatedId列转行,记为临时表t2
t2:将相关视频的id进行列转行操作
select
explode(relatedId) as videoId
from
t1;
-
将相关视频的id和gulivideo_orc表进行inner join操作
t5:得到两列数据,一列是category,一列是之前查询出来的相关视频id
(select
distinct(t2.videoId),
t3.category
from
t2
inner join
gulivideo_orc t3 on t2.videoId = t3.videoId) t4 lateral view explode(category) t_catetory as category_name;
- 按照视频类别进行分组,统计每组视频个数,然后排行
最终代码:
select
category_name as category,
count(t5.videoId) as hot
from (
select
videoId,
category_name
from (
select
distinct(t2.videoId),
t3.category
from (
select
explode(relatedId) as videoId
from (
select
*
from
gulivideo_orc
order by
views
desc limit
50) t1) t2
inner join
gulivideo_orc t3 on t2.videoId = t3.videoId) t4 lateral view explode(category) t_catetory as category_name) t5
group by
category_name
order by
hot
desc;
5 统计每个类别中的视频热度Top10,以Music为例
思路:
- 要想统计Music类别中的视频热度Top10,需要先找到Music类别,那么就需要将category展开,所以可以创建一张表用于存放categoryId展开的数据。
- 向category展开的表中插入数据。
- 统计对应类别(Music)中的视频热度。
最终代码:
创建表类别表:
create table gulivideo_category(
videoId string,
uploader string,
age int,
categoryId string,
length int,
views int,
rate float,
ratings int,
comments int,
relatedId array<string>)
row format delimited
fields terminated by "\t"
collection items terminated by "&"
stored as orc;
向类别表中插入数据:
insert into table gulivideo_category
select
videoId,
uploader,
age,
categoryId,
length,
views,
rate,
ratings,
comments,
relatedId
from
gulivideo_orc lateral view explode(category) catetory as categoryId;
统计Music类别的Top10(也可以统计其他)
select
videoId,
views
from
gulivideo_category
where
categoryId = "Music"
order by
views
desc limit
10;
6 统计每个类别中视频流量Top10,以Music为例
思路:
-
创建视频类别展开表(categoryId列转行后的表)
-
按照ratings排序即可
最终代码:
select
videoId,
views,
ratings
from
gulivideo_category
where
categoryId = "Music"
order by
ratings
desc limit
10;
7 统计上传视频最多的用户Top10以及他们上传的观看次数在前20的视频
思路:
- 先找到上传视频最多的10个用户的用户信息
select
*
from
gulivideo_user_orc
order by
videos
desc limit
10;
- 通过uploader字段与gulivideo_orc表进行join,得到的信息按照views观看次数进行排序即可。
最终代码:
select
t2.videoId,
t2.views,
t2.ratings,
t1.videos,
t1.friends
from (
select
*
from
gulivideo_user_orc
order by
videos desc
limit
10) t1
join
gulivideo_orc t2
on
t1.uploader = t2.uploader
order by
views desc
limit
20;
8 统计每个类别视频观看数Top10
思路:
-
先得到categoryId展开的表数据
-
子查询按照categoryId进行分区,然后分区内排序,并生成递增数字,该递增数字这一列起名为rank列
-
通过子查询产生的临时表,查询rank值小于等于10的数据行即可。
最终代码:
select
t1.*
from (
select
videoId,
categoryId,
views,
row_number() over(partition by categoryId order by views desc) rank from gulivideo_category) t1
where
rank <= 10;