ELK分布式日志收集系统介绍
1.ElasticSearch是一个基于Lucene的开源分布式搜索服务器。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
2.Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
3.Kibana是一个基于浏览器页面的Elasticsearch前端展示工具,也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
为什么要使用ELK
在传统项目中,如果在生产环境上,将项目部署在多台服务器上进行集群,如果生产环境需要通过日志定位到BUG的话,需要在每台服务器节点上使用传统的命令方式查询,这样的查询是非常低效,且非常考验人的忍耐力的,而ELK恰恰就帮助我们解决这样的问题
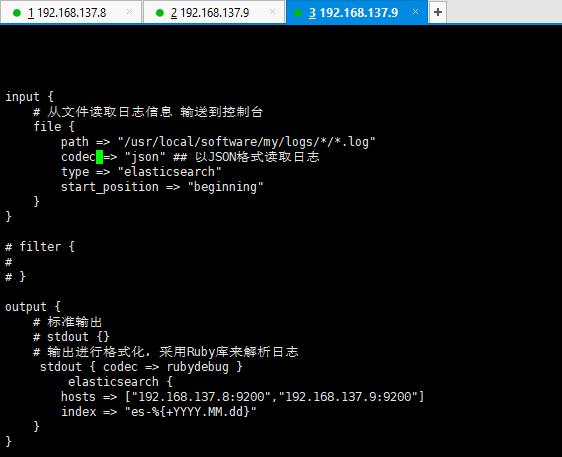
ELK的工作原理
1.在集群环境中,每一个实例节点都进行安装Logstash插件
2.每个服务器节点,都会将自身的本地日志文件输入到Logstash中
3.Logstash获取日志文件后格式化为json格式,根据每天创建不同的索引,输出到ES服务中进行存放
4.以图形化界面进行展示,搜索日志
Logstash介绍
Logstash是一个完全开源的工具,它可以对你的日志进行收集、过滤、分析,支持大量的数据获取方法,并将其存储供以后使用(如搜索)。说到搜索,logstash带有一个web界面,搜索和展示所有日志。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
核心流程:Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
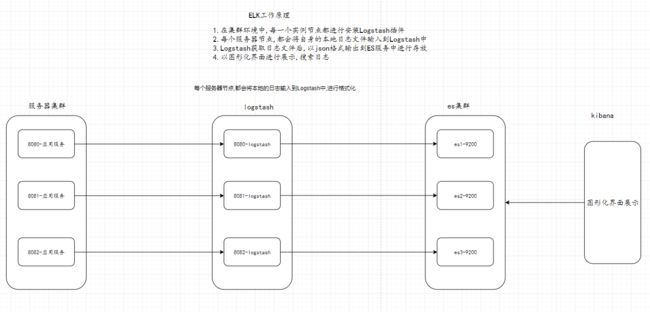
Logstash工作原理
简单来说
1.本地数据文件输入到logstash中
2.logstash过滤些不要的数据,然后将数据转成指定的格式
3.输出到指定的数据源中
前提准备:
1.ES+kibana+logstash 一台虚拟机配置运行内存3G,由于本人电脑资源有限开了2台
共6个G
一、安装jdk
1.安装之前先检查一下系统有没有自带open-jdk
命令:
rpm -qa |grep java
rpm -qa |grep jdk
rpm -qa |grep gcj
如果没有输入信息表示没有安装。
如果安装可以使用rpm -qa | grep java | xargs rpm -e --nodeps 批量卸载所有带有Java的文件 这句命令的关键字是java
2.首先检索包含java的列表
yum list java*
3.检索1.8的列表
yum list java-1.8*
4.安装1.8.0的所有文件
yum install java-1.8.0-openjdk* -y
5.使用命令检查是否安装成功
java -version
二、集群环境下基于docker安装es和kibana
启动两个虚拟机 分别在不同的虚拟机启动es容器和kibana
启动虚拟机1,es名称为:es1
下载es 和 kibana
docker pull elasticsearch:6.7.2
docker pull kibana:6.7.2
运行容器
docker run -it --name es1 -d -p 9200:9200 -p 9300:9300 -p 5601:5601 elasticsearch:6.7.2
docker run -it -d -e ELASTICSEARCH_URL=http://127.0.0.1:9200 --name kibana --network=container:es1 kibana:6.7.2
启动虚拟机2,es名称为:es2
下载es 和 kibana
docker pull elasticsearch:6.7.2
docker pull kibana:6.7.2
运行容器
docker run -it --name es2 -d -p 9200:9200 -p 9300:9300 -p 5601:5601 elasticsearch:6.7.2
docker run -it -d -e ELASTICSEARCH_URL=http://127.0.0.1:9200 --name kibana --network=container:es2 kibana:6.7.2
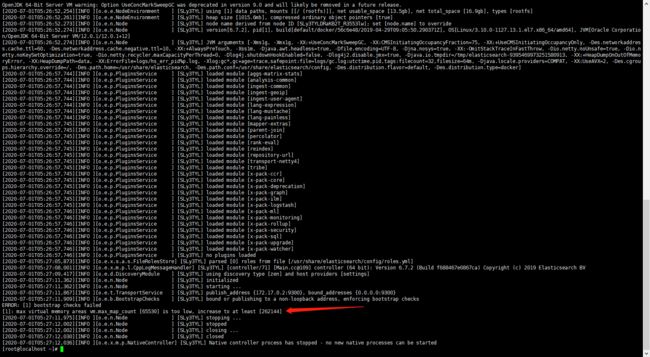
如果在启动的ES过程中,报如下错误
解决方案:
分配给ES的内存太小了
1.进入etc目录,编辑sysctl.conf文件:
vi /etc/sysctl.conf
2.添加配置:
vm.max_map_count=262144 或者 655360
3.执行:
sysctl -p
重启服务器
三、配置ES集群
进入容器修改集群配置服务器1
#进入容器
docker exec -it 容器ID /bin/bash
#编辑配置文件
vi /usr/share/elasticsearch/config/elasticsearch.yml
#注释掉原有的配置 添加配置
cluster.name: elasticsearch-cluster
node.name: es-node1
network.bind_host: 0.0.0.0
network.publish_host: 192.168.137.8
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.137.8:9300","192.168.137.9:9300"]
discovery.zen.minimum_master_nodes: 2
#保存退出
#退出容器
exit

进入容器修改集群配置服务器2
#进入容器
docker exec -it 容器ID /bin/bash
#编辑配置文件
vi /usr/share/elasticsearch/config/elasticsearch.yml
#注释掉原有的配置 添加配置
cluster.name: elasticsearch-cluster
node.name: es-node2
network.bind_host: 0.0.0.0
network.publish_host: 192.168.137.9
http.port: 9200
transport.tcp.port: 9300
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["192.168.137.8:9300","192.168.137.9:9300"]
discovery.zen.minimum_master_nodes: 2
#保存退出
#退出容器
exit

最后重启两个服务器docker里面的es,让配置进行生效
docker restart 容器id
网页访问集群的两台es,可以发现es配置已经生效了


但是这样还并不能确定是否成功集群,访问如下ES集群其中任何IP地址即可
http://192.168.137.8:9200/_cat/nodes?pretty
如下图,就代表es集群成功搭建

四、下载logstash源码包
需要注意:每台服务器上都需要安装logstash,如下面操作,我这里只示例一个
因为集群下每个服务器都会有日志,所以每个服务都需要安装logstash去收集日志发到es中
下载源码包
官方地址
https://www.elastic.co/cn/downloads/logstash
国内加速下载网址
https://www.newbe.pro/Mirrors/Mirrors-Logstash/
下载地址
wget https://mirrors.huaweicloud.com/logstash/6.7.2/logstash-6.7.2.zip
下载zip命令解压
yum -y install zip
解压
unzip logstash-6.7.2.zip
修改配置文件
进入到logstash/config目录
#新建sunny_log.conf文件
vim sunny_log.conf
#添加配置文件
input {
# 从文件读取日志信息 输送到控制台
file {
path => "/usr/local/software/my/logs/eureka_all_2020-06-30_0.log"
codec => "json" ## 以JSON格式读取日志
type => "elasticsearch"
start_position => "beginning"
}
}
# filter {
#
# }
output {
# 标准输出
# stdout {}
# 输出进行格式化,采用Ruby库来解析日志
stdout { codec => rubydebug }
elasticsearch {
hosts => ["192.168.137.8:9200","192.168.137.9:9200"]
index => "es-%{+YYYY.MM.dd}"
}
}
#保存
添加完配置后,进入logstash/bin目录下,启动logstash
./logstash -f ../config/sunny_log.conf
启动成功


五、通过kibana查看日志

以上的配置是读取一个日志文件,那如果需要读取多个日志文件该怎么办呢?
很简单,我们稍微改动配置文件即可
读取logs目录下,所有以log结尾的文件,都输出到es中

可能又会有人疑惑,我能否同步多个目录呢
假如logs下有两个目录,每个目录不同的日志文件
/:代表logs下所有目录都匹配
//*.log:代表logs下匹配所有目录下的目录里面的log文件