流畅的python学习笔记(三):数据结构(1)
文章目录
-
-
- 概述
- 序列
-
- 列表推导和生成器表达式
-
- 列表推导和可读性
- 列表推导同filter和map的比较
- 笛卡尔积
- 生成器表达式
- 元组不仅仅是不可变的列表
-
- 把元组用作记录
- 元组拆包
- 嵌套元组拆包
- 具名元组
- 切片
-
- 对对象进行切片
- 给切片赋值
- 对序列使用 + 和 *
-
- 建立由列表组成的列表
- 序列的增量赋值
- list.sort方法和内置函数sorted
- 用bisect来管理已排序的序列
-
- 用bisect.insort插入新元素
- 队列
-
- 双向队列的几个典型操作:
- 其他队列
-
概述
本章讨论的内容几乎可以应用到所有的序列类型上,从我们熟悉的list,到 Python 3 中特有的 str 和 bytes。我还会特别提到跟列表、元组、数组以及队列有关的话题。
序列
- 最重要也最基础的序列类型应该就是列表(list)了。list 是一个可变序列,并且能同时存放不同类型的元素。我想你应该对它很了解了,因此让我们直接开始讨论列表推导(listcomprehension)吧。列表推导是一种构建列表的方法,它异常强大,然而由于相关的句法比较晦涩,人们往往不愿意去用它。掌握列表推导还可以为我们打开生成器表达式(generator expression)的大门,后者具有生成各种类型的元素并用它们来填充序列的功能。下面就来看看这两个概念
列表推导和生成器表达式
- 列表推导是构建列表(list)的快捷方式,而生成器表达式则可以用来创建其他任何类型的序列。如果你的代码里并不经常使用它们,那么很可能你错过了许多写出可读性更好且更高效的代码的机会。
列表推导和可读性
"""
列表推导式使用原则:只用列表推导式创建新的列表,并且尽量保持简短
如果列表推导式的代码超过了两行,建议使用for循环重写
"""
# 2_1 普通实现
def str_to_unicode1(symbols: str) -> list:
"""把一个字符串变成unicode码位的列表"""
codes = []
for symbol in symbols:
codes.append(ord(symbol))
return codes
# 2_1 列表推导式实现
def str_to_unicode2(symbols: str) -> list:
"""把一个字符串变成unicode码位的列表"""
return [ord(symbol) for symbol in symbols]
if __name__ == '__main__':
a = ")(@#$"
unicode_a1 = str_to_unicode1(a)
unicode_a2 = str_to_unicode2(a)
print(unicode_a1) # [41, 40, 64, 35, 36]
print(unicode_a2) # [41, 40, 64, 35, 36]
列表推导同filter和map的比较
- filter 和 map 合起来能做的事情,列表推导也可以做,而且还不需要借助难以理解和阅读的 lambda 表达式
"""
map(function, iterable, ...): 据提供的函数对指定序列做映射。Python 2.x 返回列表,Python 3.x 返回迭代器。
filter(function, iterable):用于过滤序列,过滤掉不符合条件的元素。Python2.7 返回列表,Python3.x 返回迭代器
"""
if __name__ == '__main__':
symbols = "&¥)(@#$~——"
# 列表推导式
beyond_ascii1 = [ord(s) for s in symbols if ord(s) > 127]
# filter + map
beyond_ascii2 = list(filter(lambda c: c > 127, map(ord, symbols)))
print(beyond_ascii1) # [65509, 8212, 8212]
print(beyond_ascii2) # [65509, 8212, 8212]
笛卡尔积
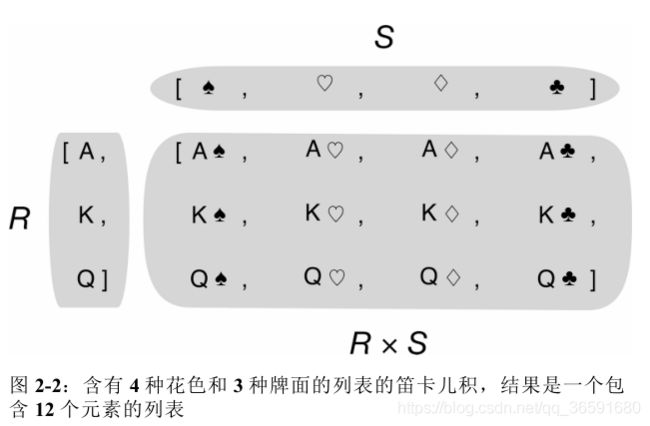
- 使用列表推导可以生成两个或以上的可迭代类型的笛卡儿积
"""
使用列表计算笛卡尔积
"""
if __name__ == '__main__':
colors = ["black", "white"]
sizes = ["S", "M", "L"]
t = [(color, size) for color in colors for size in sizes]
for e in t:
print(e)
# ('black', 'S')
# ('black', 'M')
# ('black', 'L')
# ('white', 'S')
# ('white', 'M')
# ('white', 'L')
- 列表推导的作用只有一个:生成列表。如果想生成其他类型的序列,生成器表达式就派上了用场。
生成器表达式
'''
虽然可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的选择。
这是因为生成器表达式背后遵守了迭代器协议,可以逐个产出元素,而不是先建立一个完整的列表,然后再把这个列表传递到某个函数里。
生成器表达式的语法和列表推导式差不多,只不过把方括号换成了圆括号。
如果生成器表达式是一个函数调用过程中的唯一参数,那么不需要额外再用括号把它围起来
'''
def generator_expression_tuple(symbols):
"""
generator_expression_tuple(symbols:str) -> tuple
生成器表达式生成元组
"""
return tuple(ord(symbol) for symbol in symbols)
def generator_expression_array(symbols):
"""
generator_expression_array(symbols:str) -> array
生成器表达式生成数组
"""
return array.array('I', (ord(symbol) for symbol in symbols))
if __name__ == '__main__':
symbols = "$¢£¥€¤"
t = generator_expression_tuple(symbols)
print(t) # (36, 162, 163, 165, 8364, 164)
a = generator_expression_array(symbols)
print(a) # array('I', [36, 162, 163, 165, 8364, 164])
元组不仅仅是不可变的列表
- 除了用作不可变的列表,它还可以用于没有字段名的记录
把元组用作记录
import os
if __name__ == '__main__':
# 洛杉矶经纬度
lax_coordinates = (33.9425, -118.6465774)
# 东京市的一些信息:市名、年份、人口(单位:百万)、人口变化(单位:百分比)和面积(单位:平方千米)
city, year, pop, chg, area = ("Tokyo", 2003, 32450, 0.66, 8014)
# 元组列表
traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'), ('ESP', 'XDA205856')]
# 使用元组匹配 % 格式运算符
for passport in sorted(traveler_ids):
print("%s/%s" % passport)
# BRA/CE342567
# ESP/XDA205856
# USA/31195855
# for循环可以分别提取元组中的元素,也叫拆包(unpacking)。
# 如果元组中第二个元素无需使用,可以使用"_"占位符进行赋值
for country, _ in traveler_ids:
print(country)
# USA
# BRA
# ESP
元组拆包
- 最好辨认的元组拆包形式就是平行赋值,也就是说把一个可迭代对象里的元素,一并赋值到由对应的变量组成的元组中
latitude, longitude = (33.9425, -118.408056)
- 另外一个很优雅的写法当属不使用中间变量交换两个变量的值:
b, a = a, b
- 还可以用 * 运算符把一个可迭代对象拆开作为函数的参数:
if __name__ == '__main__':
d1 = divmod(20, 8)
print(d1) # (2, 4)
t = (20, 8)
quotient, remainder = divmod(*t)
print((quotient, remainder)) # (2, 4)
- 函数可以用元组的形式返回多个值,然后调用函数的代码就能轻松地接受这些返回值:
if __name__ == '__main__':
# 函数使用元组的形式返回多个值,无用数据使用'_'占位符接收
_, filename = os.path.split('/home/luciano/.ssh/idrsa.pub')
print(filename) # idrsa.pub
- 使用 * 处理部分元素: 在平行赋值中,* 前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置
if __name__ == '__main__':
a, b, *rest = range(5)
print(rest) # [2, 3, 4]
m, *body, n = range(5)
print(body) # [1, 2, 3]
嵌套元组拆包
- 接受表达式的元组可以是嵌套式的,例如 (a, b, (c, d))。只要这个接受元组的嵌套结构符合表达式本身的嵌套结构,Python 就可以作出正确的对应
"""
使用嵌套元组获取城市经纬度
"""
if __name__ == '__main__':
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('Sao Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
fmt = '{:15} | {:9.4f} | {:9.4f}'
for name, cc, pop, (latitude, longitude) in metro_areas:
# 经度小于0(西半球)
if longitude < 0:
print(fmt.format(name, latitude, longitude))
# Mexico City | 19.4333 | -99.1333
# New York-Newark | 40.8086 | -74.0204
# Sao Paulo | -23.5478 | -46.6358
具名元组
- collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类。namedtuple 构建的类的实例所消耗的内存跟元组是一样的,因为字段名都被存在对应的类里面。
from collections import namedtuple
if __name__ == '__main__':
City = namedtuple("City", "name country population coordinates")
tokyo = City("Tokyo", "JP", "36.933", (35.689722, 139.691667))
print(tokyo) # City(name='Tokyo', country='JP', population='36.933', coordinates=(35.689722, 139.691667))
# _fields 属性是一个包含这个类所有字段名称的元组
print(City._fields) # ('name', 'country', 'population', 'coordinates')
# _make() 通过接受一个可迭代对象来生成这个类的一个实例,它
# 的作用跟 City(*delhi_data) 是一样的
delhi_data = ('Delhi NCR', 'IN', 21.935, (28.613889, 77.20))
delhi1 = City._make(delhi_data)
delhi2 = City(*delhi_data)
# _asdict() 把具名元组以 collections.OrderedDict 的形式返回
asdict = delhi1._asdict()
print(asdict) # {'name': 'Delhi NCR', 'country': 'IN', 'population': 21.935, 'coordinates': (28.613889, 77.2)}
for k, v in delhi1._asdict().items():
print(k + ":", v)
# name: Delhi NCR
# country: IN
# population: 21.935
# coordinates: (28.613889, 77.2)
切片
- 在 Python 里,像列表(list)、元组(tuple)和字符串(str)这类序列类型都支持切片操作,但是实际上切片操作比人们所想象的要强大很多。
- 在切片和区间操作里不包含区间范围的最后一个元素是 Python 的风格。
对对象进行切片
- 可以用
s[a:b:c]的形式对 s 在 a 和b 之间以 c 为间隔取值
if __name__ == '__main__':
s = 'bicycle'
print(s[::3]) # bye
print(s[::-1]) # elcycib
print(s[::-2]) # eccb
给切片赋值
- 如果把切片放在赋值语句的左边,或把它作为 del 操作的对象,我们就可以对序列进行嫁接、切除或就地修改操作
'''
如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象。
即便只有单独一个值,也要把它转换成可迭代的序列
'''
if __name__ == '__main__':
a = list(range(10))
a[2:5] = [20, 30]
print(a) # [0, 1, 20, 30, 5, 6, 7, 8, 9]
del a[5:7]
print(a) # [0, 1, 20, 30, 5, 8, 9]
a[3::2] = [11, 22]
print(a) # [0, 1, 20, 11, 5, 22, 9]
# a[2:5] = 100 # TypeError: must assign iterable to extended slice
a[2:5] = [100]
print(a) # [0, 1, 100, 22, 9]
对序列使用 + 和 *
- 通常 + 号两侧的序列由相同类型的数据所构成,在拼接的过程中,两个被操作的序列都不会被修改,Python 会新建一个包含同样类型数据的序列来作为拼接的结果
- 如果想要把一个序列复制几份然后再拼接起来,更快捷的做法是把这个序列乘以一个整数。同样,这个操作会产生一个新序列:
if __name__ == '__main__':
l = [1, 2, 3]
m = l * 5
print(l) # [1, 2, 3]
print(m) # [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
- +和 * 都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列
建立由列表组成的列表
- 如果在 a * n 这个语句中,序列 a 里的元素是对其他可变对象的引用的话,你就需要格外注意了,因为这个式子的结果可能会出乎意料。
"""
一个包含 3 个列表的列表,嵌套的 3 个列表各自有 3 个元素来代表井字游戏的一行方块
"""
if __name__ == '__main__':
board = [['_'] * 3 for i in range(3)]
print(board) # [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
# 把第 1 行第 2 列的元素标记为 X,再打印出这个列表。
board[1][2] = "X"
print(board) # [['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
# 错误使用
# 外面的列表其实包含 3 个指向同一个列表的引用
weird_board = [['_'] * 3] * 3
print(weird_board) # [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
# 我们试图标记第 1 行第 2 列的元素,就立马暴露了列表内的 3 个引用指向同一个对象的事实
weird_board[1][2] = '0'
print(weird_board) # [['_', '_', '0'], ['_', '_', '0'], ['_', '_', '0']]
序列的增量赋值
- += 背后的特殊方法是
__iadd__(用于“就地加法”)。但是如果一个类没有实现这个方法的话,Python 会退一步调用__add__
"""
如果 a 实现了 __iadd__ 方法,就会调用这个方法。同时对可变序列,a 会就地改动,就像调用了 a.extend(b) 一样.
但是如果 a 没有实现 __iadd__ 的话,a += b 这个表达式的效果就变得跟 a = a + b 一样了:
首先计算 a + b,得到一个新的对象,然后赋值给 a
"""
a += b
- 总体来讲,可变序列一般都实现了
__iadd__方法,因此 += 是就地加法。而不可变序列根本就不支持这个操作
if __name__ == '__main__':
l = [1, 2, 3]
print(id(l)) # 2529999769088
# 运用增量乘法后,列表的 ID 没变,新元素追加到列表上
l *= 2
print(id(l)) # 2529999769088
t = (1, 2, 3)
print(id(t)) # 2530029913024
# 运用增量乘法后,新的元组被创建
t *= 2
print(id(t)) # 2530029785632
- 对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素(str除外)
- 来看一个边界情况:
"""
出人意料的结果:t[2] 被改动了,但是也有异常抛出
"""
if __name__ == '__main__':
t = (1, 2, [3, 4])
try:
print(t) # (1, 2, [3, 4])
t[2] += [5, 60]
except TypeError as e:
print(e) # 'tuple' object does not support item assignment
print(t) # (1, 2, [3, 4, 5, 60])
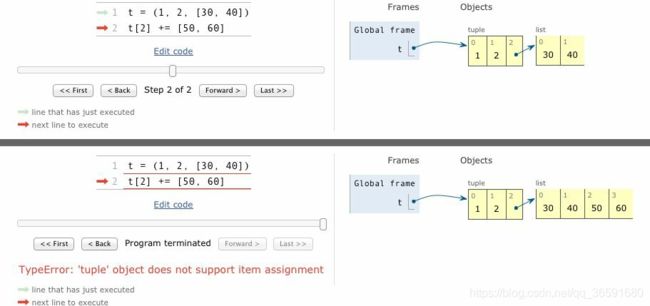
边界示例实际流程:
- 将
t[a]的值存入 TOS(Top Of Stack,栈的顶端) - 计算 TOS += b。这一步能够完成,是因为 TOS 指向的是一个可变对象
- t[a] = TOS 赋值。这一步失败,是因为 t 是不可变的元组
list.sort方法和内置函数sorted
-
list.sort 方法会就地排序列表,也就是说不会把原列表复制一份。这也是这个方法的返回值是 None 的原因。
-
与 list.sort 相反的是内置函数 sorted,它会新建一个列表作为返回值。这个方法可以接受任何形式的可迭代对象作为参数,甚至包括不可变序列或生成器。
-
不管是 list.sort 方法还是 sorted 函数,都有两个可选的关键字参数
- reverse
如果被设定为 True,被排序的序列里的元素会以降序输出。这个参数的默认值是 False - key
一个只有一个参数的函数,这个函数会被用在序列里的每一个元素上,所产生的结果将是排序算法依赖的对比关键字。比如说,在对一些字符串排序时,可以用 key=str.lower 来实现忽略大小写的排序,或者是用 key=len 进行基于字符串长度的排序。这个参数的默认值是恒等函, 也就是默认用元素自己的值来排序
- reverse
if __name__ == '__main__':
fruits = ['grape', 'raspberry', 'apple', 'banana']
f = sorted(fruits) # ➊
print(f) # ['apple', 'banana', 'grape', 'raspberry']
f1 = sorted(fruits, reverse=True) # ➋
print(f1) # ['raspberry', 'grape', 'banana', 'apple']
f2 = sorted(fruits, key=len) # ➌
print(f2) # ['grape', 'apple', 'banana', 'raspberry']
f3 = sorted(fruits, reverse=True, key=len) # ➍
print(f3) # ['raspberry', 'banana', 'grape', 'apple']
print(fruits) # ['grape', 'raspberry', 'apple', 'banana']
fruits.sort() # ➎
print(fruits) # ['apple', 'banana', 'grape', 'raspberry']
"""
1: 按照字母降序排序
2: 新建一个按照长度排序的字符串列表
3: 新建一个按照字母降序排序的字符串列表
4: 按照长度降序排序的结果
5: 此时 fruits 本身被排序
"""
用bisect来管理已排序的序列
- 已排序的序列可以用来进行快速搜索,而标准库的 bisect 模块给我们提供了二分查找算法。
- bisect 模块包含两个主要函数,bisect 和 insort,两个函数都利用二分查找算法来在有序序列中查找或插入元素
- bisect.bisect(haystack, needle)系列返回的是插入数据(needle)索引的位置,必须保证序列haystack为有序序列。
import bisect, sys
HAYSTACK = [1, 4, 5, 6, 8, 12, 15, 20, 21, 23, 23, 26, 29, 30]
NEEDLES = [0, 1, 2, 5, 8, 10, 22, 23, 29, 30, 31]
ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}'
def demo(bisect_fn):
for needle in reversed(NEEDLES):
# 用特定的 bisect 函数来计算元素应该出现的位置
position = bisect_fn(HAYSTACK, needle)
# 利用该位置来算出需要几个分隔符号
offset = position * ' |'
# 把元素和其应该出现的位置打印出来
print(ROW_FMT.format(needle, position, offset))
if __name__ == '__main__':
# 根据命令上最后一个参数来选用 bisect 函数
bisect_fn = bisect.bisect_left if sys.argv[-1] == "left" else bisect.bisect
print('DEMO:', bisect_fn.__name__)
print('haystack ->', ' '.join('%2d' % n for n in HAYSTACK))
demo(bisect_fn)
- 输出
DEMO: bisect_right
haystack -> 1 4 5 6 8 12 15 20 21 23 23 26 29 30
31 @ 14 | | | | | | | | | | | | | |31
30 @ 14 | | | | | | | | | | | | | |30
29 @ 13 | | | | | | | | | | | | |29
23 @ 11 | | | | | | | | | | |23
22 @ 9 | | | | | | | | |22
10 @ 5 | | | | |10
8 @ 5 | | | | |8
5 @ 3 | | |5
2 @ 1 |2
1 @ 1 |1
0 @ 0 0
-
注意:bisect 函数其实是 bisect_right 函数的别名,还有个bisect_left,bisect_left 返回的插入位置是原序列中跟被插入元素相等的元素的位置,也就是新元素会被放置于它相等的元素的前面,而 bisect_right 返回的则是跟它相等的元素之后的位置。
-
bisect 可以用来建立一个用数字作为索引的查询表格,比如说把分数和成绩 对应起来,如下示例:
import bisect
def grade(score, breakpoints=None, grades='FDCBA'):
"""根据一个分数,找到它所对应的成绩"""
if breakpoints is None:
breakpoints = [60, 70, 80, 90]
i = bisect.bisect(breakpoints, score)
return grades[i]
if __name__ == '__main__':
print([grade(score) for score in [33, 99, 77, 70, 89, 90, 100]])
# ['F', 'A', 'C', 'C', 'B', 'A', 'A']
用bisect.insort插入新元素
- 排序很耗时,因此在得到一个有序序列之后,我们最好能够保持它的有序。bisect.insort 就是为了这个而存在的。
- insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持seq 的升序顺序
import bisect, random
if __name__ == '__main__':
SIZE = 7
random.seed(1729)
my_list = []
for i in range(SIZE):
new_item = random.randrange(SIZE * 2)
bisect.insort(my_list, new_item)
print('%2d ->' % new_item, my_list)
# 10 -> [10]
# 0 -> [0, 10]
# 6 -> [0, 6, 10]
# 8 -> [0, 6, 8, 10]
# 7 -> [0, 6, 7, 8, 10]
# 2 -> [0, 2, 6, 7, 8, 10]
# 10 -> [0, 2, 6, 7, 8, 10, 10]
'''
insort 跟 bisect 一样,有 lo 和 hi 两个可选参数用来控制查找的范围。
它也有个变体叫 insort_left,这个变体在背后用的是bisect_left
'''
队列
- 利用 .append 和 .pop 方法,我们可以把列表当作栈或者队列来用。但是删除列表的第一个元素(抑或是在第一个元素之前添加一个元素)之类的操作是很耗时的,因为这些操作会牵扯到移动列表里的所有元素。
- collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。在新建一个双向队列的时候,你可以指定这个队列的大小,如果这个队列满员了,还可以从反向端删除过期的元素,然后在尾端添加新的元素。
双向队列的几个典型操作:
from collections import deque
if __name__ == '__main__':
"""
新建一个双向队列
maxlen 是一个可选参数,代表这个队列可以容纳的元素的数量,而且一旦设定,这个属性就不能修改了
"""
dq = deque(range(10), maxlen=10)
print(dq) # deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
"""
队列的旋转操作接受一个参数 n,当 n > 0 时,队列的最右边的 n个元素会被移动到队列的左边。
当 n < 0 时,最左边的 n 个元素会被移动到右边
"""
dq.rotate(3)
print(dq) # deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
dq.rotate(-4)
print(dq) # deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
"""
当试图对一个已满(len(d) == d.maxlen)的队列一端(头部或者尾部)做添加操作的时候,它另一端的元素会被删除掉
extendleft(iter) 方法会把迭代器里的元素逐个添加到双向队列的左边(头部),因此迭代器里的元素会逆序出现在队列里
"""
dq.appendleft(-1) # 头部添加一个元素
print(dq) # deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
dq.append(10) # 尾部添加一个元素
print(dq) # deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], maxlen=10)
dq.extend([11, 22, 33]) # 尾部添加3个元素
print(dq) # deque([4, 5, 6, 7, 8, 9, 10, 11, 22, 33], maxlen=10)
dq.extendleft([10, 20, 30, 40]) # 头部添加4个元素
print(dq) # deque([40, 30, 20, 10, 4, 5, 6, 7, 8, 9], maxlen=10)
其他队列
- queue(队列)
'''
queue提供了同步(线程安全)类 Queue、LifoQueue 和PriorityQueue,不同的线程可以利用这些数据类型来交换信息。
这三个类的构造方法都有一个可选参数 maxsize,它接收正整数作为输入值,用来限定队列的大小。但是在满员的时候,这些类不会扔掉旧的元素来腾出位置。
相反,如果队列满了,它就会被锁住,直到另外的线程移除了某个元素而腾出了位置。这一特性让这些类很适合用来控制活跃线程的数量
'''
- multiprocessing
"""
multiprocessing包是Python中的多进程管理包.
这个包实现了自己的 Queue,它跟 queue.Queue 类似,是设计给进程间通信用的。
同时还有一个专门的multiprocessing.JoinableQueue 类型,可以让任务管理变得更方便
"""
- asyncio
"""
Python 3.4 新提供的包,里面有Queue、LifoQueue、PriorityQueue 和 JoinableQueue,
这些类受到 queue 和 multiprocessing 模块的影响,但是为异步编程里的任务管理提供了专门的便利
"""
- heapq
"""
跟上面三个模块不同的是,heapq 没有队列类,而是提供了heappush 和 heappop 方法,让用户可以把可变序列当作堆队列或者优先队列来使用
"""