三.深度学习YOLO_opencv_dnn部署实践记录
三.深度学习YOLO_opencv的实际部署
opencv4.3+cuda10.2 GPU完美编译版 SDK附件的说明
文章目录
- 三.深度学习YOLO_opencv的实际部署
- 前言
- 一、opencv_dnn编译
- 二、编译yolo调用例子
- 总结
前言
1.opencv4.4dnn模块封装yolo的SDK方法
2.darknet的工程实现yolo的调用.
一、opencv_dnn编译
opencv需要4.4的版本,下载源码编译.
勾选:
cuda

dnn相关选项
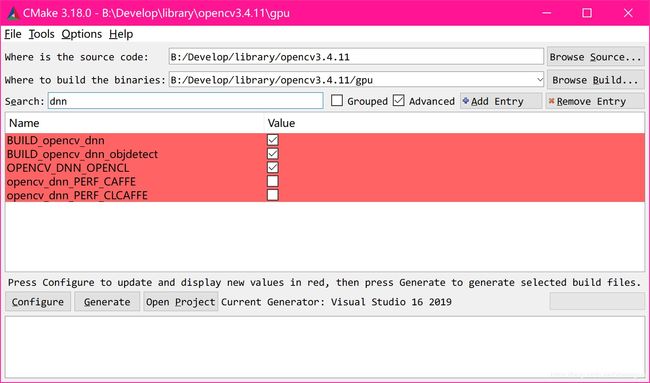
其他的看个人需求吧
我这里为了部署简单全部采用/MT编译的 不再依赖VS的CRT运行库.
编译时间特别慢,挂机 vs2019下P51(E3-1505CPU-32G) 大概4小时完事了.多多少少还是有些麻烦.多cmake几次你就习惯了
依赖如下图:
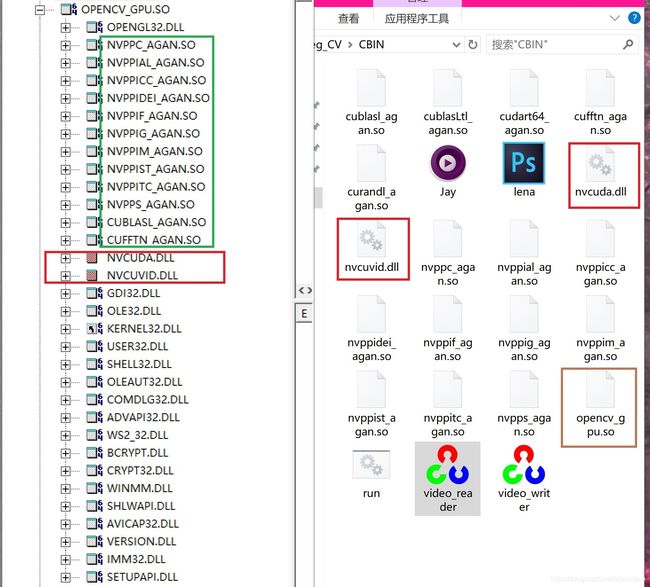
看我的文件是有点怪,全网都没有人这么弄过.名字我修改了叫opencv_gpu.so(约931M很大的)
还有就是cuda10.2的依赖库我都改成了so结尾 主要是为了防止和别的版本的opencv库冲突.好多项目依赖opencv版本不一致SDK又是其他方提供 没有源码.所以才这样的 这些SO文件其实就是dll,所以不要见怪! 运行无影响的.
当你生成了opencv的GPU库后可以用opencv里面simple中的GPU例子测测看能不能运行.
二、编译yolo调用例子
首先准备yolo自己训练的模型和cfg (训练过程另篇)
我这里是一个挖掘机检测的cfg是3类(挖机身体,臂,斗) 模型都做了最好优化了(用darknet来练)
# Testing
batch=1
subdivisions=1
# Training
# 每64个样本进行一次参数更新
#batch=32
# 将batch分割为4个子batch(内存不够大)
# 降低对显存的占用情况
#subdivisions=2
# 图片宽和高
# 只设置成32的倍数(考虑precision)
#width=608
#height=608
width=416
height=416
# 输入图像的通道数
channels=3
# 动量
# 梯度下降到最优值的速度,建议配置为0.9
momentum=0.9
# 权重衰减正则项(防止过拟合)
# decay参数越大,对过拟合的抑制能力越强
decay=0.0005
# 通过旋转角度来生成更多训练样本
# 如果angle=10,就是生成新图片时随机旋转-10~10度
angle=0
# 调整饱和度
saturation = 1.5
# 调整曝光量
exposure = 1.5
# 调整色调
hue=.1
#初始学习率
learning_rate=0.001
# 在迭代次数小于burn_in时,其学习率的更新有一种方式
# 大于burn_in时,采用policy的更新方式
burn_in=1000
# 训练达到max_batches后,停止学习
max_batches = 120000
# 调整学习率的policy
# policy:CONSTANT, STEP, EXP, POLY, STEPS, SIG, RANDOM
policy=steps
# 根据batch_num调整学习率
steps=400000,450000
# 学习率变化的比例,累计相乘
scales=.1,.1
[convolutional]
# BN?
batch_normalize=1
# 输出特征图数
filters=16
# 卷积核的尺寸3X3
size=3
# 步长
stride=1
# pad=1,padding为size/2
pad=1
# 激励函数
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[maxpool]
size=2
stride=1
[convolutional]
batch_normalize=1
filters=1024
size=3
stride=1
pad=1
activation=leaky
###########
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
# 每一个[region/yolo]层前的最后一个卷积层filters数
# 计算公式为filter=num*(classes+5)
# 5:tx,ty,tw,th,to
# 修改filters = 3 * (类别 + 5)
filters=24
activation=linear
[yolo]
mask = 3,4,5
# 修改anchors值
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
# 类别
classes=3
num=6
# 通过抖动增加噪声,抑制过拟合
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[route]
# 将两层的featuremap做concat
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 8
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24
activation=linear
[yolo]
# 当前属于第几个预选框
mask = 0,1,2
# 修改anchors值
# 若不设置,默认是0.5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
# 类别,不加1
classes=3
# anchor的数量
num=6
# 通过抖动增加噪声,防止过拟合
jitter=.3
# 是否需要计算IOU误差的参数
# 大于thresh,IOU误差不会在cost function
ignore_thresh = .7
truth_thresh = 1
# random=1,启用Multi-Scale Training,随机使用多尺度图片进行训练
# random=0,训练图片大小与输入大小一致
random=1
Darknet.mk编译yolo.cpp
INCLUDES=.\
//nmake /f cv.mk
Darknet :yoloDetection.obj
cl.exe -EHsc opencv.res yoloDetection.obj -o Darknet
del *.obj
yoloDetection.obj:yoloDetection.cpp
cl.exe -EHsc /W0 /I $(INCLUDES) -c yoloDetection.cpp
clean:
del *.obj *.exe
yoloDetection.cpp
#include 
总结
opencv_dnn调用yolo模块官方的例子只要opencv_world的GPU版生成后可以直接复现 。非常容易. 封装的代码我就不贴出来了,参考yoloDetection.cpp即可.更换cfg和weight文件就是一个很好的识别框架了.
将opencv4.3+cuda10.2 GPU完美编译版 SDK 里面直接更换cfg和weight文件就可以直接跑起来了