【华录杯】深度学习吸烟打电话识别
2020华录杯基于深度学习的吸烟打电话识别算法
文章目录
- 前言
- 一、解题思路
- 二、数据预处理
- 三、模型设计
-
- 1.CBAM
- 四、训练调参
- 总结
前言
设计出能够识别人物吸烟和打电话行为的算法,难点在于数据集中人物清晰度有限,而且人物的像素大小不一,要合理利用技巧,尝试不同的图像算法,提升吸烟打电话行为识别的准确度
一、解题思路
1.拿到数据后,我们先进行图片数据的分析,统计数据样本分布,尺寸分布,图片形态等,基于训练集和测试集做一些针对性的数据预处理算法,让我们的模型更好的拟合数据。
2.根据数据是一个分类任务,即分出图像中人物吸烟、打电话、正常。既然是一个简单的分类任务,而且没有推理速度要求,那么可以选一个大的backbone,如(resnet系列、EfficientNet)作为baseline,然后基于该模型进行不断的修改、调参,调试出性能较好的参数。
二、数据预处理
包括简单的数据增强操作,保持人物的不变形图像的等比填充缩放裁剪,水平翻转、由于数据清晰度差增加高斯模糊等
代码如下(示例):
mean, std = [0.485, 0.456, 0.406], [0.229, 0.224, 0.225] 数据标准化
train_transform = transforms.Compose([
Resize(int(size), int(size)), # 等比填充缩放
transforms.RandomCrop(size),
transforms.RandomHorizontalFlip(),
RandomGaussianBlur(),
transforms.ToTensor(),
transforms.Normalize(mean=mean, std=std),
])
也可以借鉴yolov5的图像预处理padding方法。
三、模型设计
直接在resnet101基础上修改,最后采用了resnext101_32*8d_wsl网络作为基本的baseline,使用608x480作为输入,网络架构如下图,首层卷积添加cbam注意力机制增强特征表征能力,关注重要特征抑制不必要特征。后面接全连接层三分类,添加dropout降低过拟合。模型和代码借鉴了开源项目,有兴趣的可以去自己跑一下。
代码如下(示例):
model.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(2048, args.num_classes)
)

1.CBAM
Convolutional Block Attention Module (CBAM) 表示卷积模块的注意力机制模块。是一种结合了空间(spatial)和通道(channel)的注意力机制模块。即插即用,有广泛的可应用性。

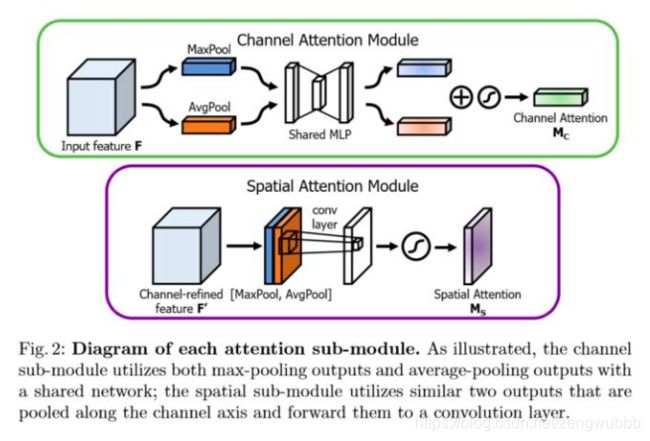
代码如下(示例):
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
四、训练调参
1.使用imagenet预训练模型,损失函数:CrossEntropyLoss,优化函数:torch.optim.SGD,学习率优化:ReduceLROnPlateau,初始学习率:0.001。训练15 epoch后达到收敛。
2.CrossEntropyLoss换成LabelSmoothCELoss防止过拟合,LabelSmooth是一种正则化的策略。其通过"软化"传统的one-hot类型标签,使得在计算损失值时能够有效抑制过拟合现象
代码如下(示例):
class LabelSmoothCELoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, pred, label, smoothing=0.1):
import torch.nn.functional as F
pred = F.softmax(pred, dim=1)
one_hot_label = F.one_hot(label, pred.size(1)).float()
smoothed_one_hot_label = (
1.0 - smoothing) * one_hot_label + smoothing / pred.size(1)
loss = (-torch.log(pred)) * smoothed_one_hot_label
loss = loss.sum(axis=1, keepdim=False)
loss = loss.mean()
return loss
3.增加warm up 使用余弦退火学习率,训练模型至收敛,由于数据量还是太少, 模型容易过拟合,提交测试模型能达99.5+的得分
代码如下(示例):
warm_up_epochs = 5
warm_up_with_cosine_lr = lambda epoch: epoch / warm_up_epochs if epoch <= warm_up_epochs else 0.5 * (
math.cos((epoch - warm_up_epochs) / (args.epochs - warm_up_epochs) * math.pi) + 1)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=warm_up_with_cosine_lr) # CosineAnnealingLR
总结
一个简单的分类任务,只要选一个足够大的模型提取特征,然后做一些调参。很容易就能拟合好数据。后续使用更加轻量的模型,以及用目标检测的方法,这样更容易用于实际场景的使用。