前言
使用man grep查看grep的帮助文档,有如下内容:
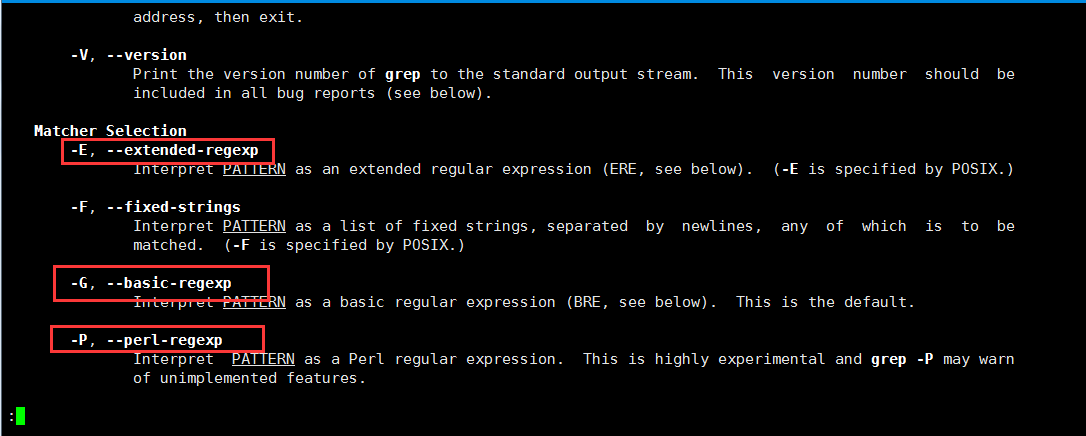
可以看出,正则表达式由三类,分别是
- 基本的正则表达式(Basic Regular Expression 又叫 Basic RegEx 简称 BREs)
- 扩展的正则表达式(Extended Regular Expression 又叫 Extended RegEx 简称 EREs)
- Perl 的正则表达式(Perl Regular Expression 又叫 Perl RegEx 简称 PREs)
由于BREs语法中需要大量转义字符,导致正则表达式不易看懂,因此本文使用Perl类型的正则表达式。
1.校验MAC地址
我们常见的MAC地有如下两种格式:
48-5D-60-DE-3D-C5
48:5D:60:61:3D:C5
我们以第一种为例,即一共有6组十六进制的数中间由短横线“-”连接。每组十六进制的数据可以看成是由取值范围为a-f、A-F或0-9的两个字符组成。
首先,用正则表达式表示a-f、A-F或0-9的两个字符
[a-fA-F0-9] [a-fA-F0-9]
可以发现[a-fA-F0-9]重复了两次,因此上述表达式可以写成
[a-fA-F0-9] {2}
然后,用正则表达式表示六组a-f、A-F或0-9的两个字符中间用短横线连接:
[a-fA-F0-9]{2}-[a-fA-F0-9]{2}-[a-fA-F0-9]{2}-[a-fA-F0-9]{2}-[a-fA-F0-9]{2}-[a-fA-F0-9]{2}
上述正则表达式太臃肿了,一组两位的其实我们可以看成
[a-fA-F0-9]{2}-重复了5次(注意后边有个短横线),最后又加了一组[a-fA-F0-9]{2},而其中的0-9可以用\d代替。基于这样的思路,对上述正则表达式进行修改后如下所示:
([a-fA-F\d]{2}-){5}[a-fA-F\d]{2}
最后,我们检验下上述正则表达式是否满足要求。创建一个mac.txt,内容如下所示:
48-5D-60-61-3D-C5
08-D4-hM-1D-AD-AE
28-D2-44-B7-AD-EC
XX-5D-60-61-3D-C5
其中第2和第4行是错误的MAC地址,检测结果如下:

由以上结果可以看出上述正则表达式是正确的。
2.校验邮箱地址
下表是常见的邮箱格式:
| @前缀 | 纯数字 | [email protected] |
|---|---|---|
| 纯字母 | [email protected] | |
| 字母数字混合 | [email protected] | |
| 带点的 | [email protected] | |
| 带下划线 | [email protected] | |
| 带连接线 | [email protected] | |
| @后缀 | 二级域名 | [email protected] |
| 三级域名 | [email protected] |
根据上述常见邮箱格式,我们可以总结出邮箱格式符合的规则
1) 邮箱必有一个@
2) 邮箱@前缀由数字或字母开头
3) 邮箱@前缀由多个字母、数字、段横线-、下划线_、英文句号.自由拼接而成
4) 邮箱@后缀由两级或三级域名组成,其中每个域名中间由英文句号“.”隔开, 而每级域名都是由字母或数字组成
根据以上规则,可以得到如下正则表达式:
1) 邮箱必有一个@ ,对应正则表达式如下所示:
@
2) 邮箱@前缀由数字或字母开头,对应正则表达式如下所示:
^[a-zA-Z0-9]@
其中^表示开始位置,[a-zA-Z0-9]表示数字或字母
3) 邮箱@前缀由多个字母、数字、段横线-、下划线_、英文句号.自由拼接而成
^[a-zA-Z0-9][a-zA-Z0-9-._]+@
其中+表示重复1到多次
4) 邮箱@后缀由两级或三级域名组成,其中每个域名中间由英文句号“.”隔开,而每级域名都是由字母或数字组成。
@([a-zA-Z0-9]+.){1,2}[a-zA-Z0-9]+$
其中([a-zA-Z0-9]+.){1,2}可以拆分成如下内容:
[a-zA-Z0-9] 数字或字母
[a-zA-Z0-9]+数字或字母重复1到多次
[a-zA-Z0-9]+.数字或字母重复1到多次后边加上英文句号.
([a-zA-Z0-9]+.){1,2}数字或字母重复1到多次后边加上英文句号.做为一个整体重复1到2次。
最后的[a-zA-Z0-9]+表示以多个数字或字母结尾。
将上述邮箱@前缀的正则表达式和邮箱@后缀的正则表达式组合在一起,同时由于0-9的数字可以用\d表示,可以用\d替换内容中的0-9,最后得到的表达式我们想要的可以匹配邮箱的正则表达式,如下所示:
^[a-zA-Z\d][a-zA-Z\d-._]+@([a-zA-Z\d]+.){1,2}[a-zA-Z\d]+$
下面我们来检验下写出来的正则表达式:
新建一个mail.txt,内容如下:
[email protected]
其中最后三行为错误的格式,使用正则表达式进行校验:

由上述结果可以看出,我们的正则表达式是符合要求的。
3.校验手机号
要校验手机号,我们首先需要知道手机号的组成格式。目前国内的手机号有以下格式:
1)由数字1开头
2)第二位数字的取值范围是3、4、5、7、8、
3)最后为9位数字
根据以上规则,写出对应的正则表达式
- 由数字1开头
^1
- 第二位数字的取值范围是3、4、5、7、8、
[34578]
- 最后为9位数字
[0-9]{9}$
其中[0-9]{9}表示0-9的数字取值重复9次,$表示结尾。由于0-9的数字可以由\d表示,上述内容等价于
\d{9}$
将上述正则表达式组合在一起,就可以得到我们想要的正则表达式,如下所示:
^1[34578]\d{9}$
下面开始进行校验,新建一个phone.txt,内容如下:
138537721989
146398702123
12200993333
23848270281
13849199233
d333300-903
其中只有倒数第二行的号码是正确的,使用正则表达式进行校验:
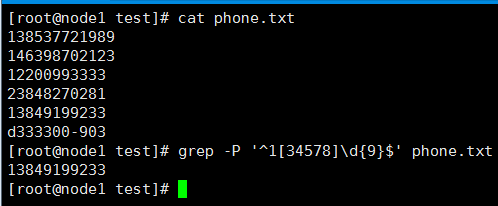
由上述结果可以看出,我们的正则表达式是符合要求的。
4.校验IP地址
对IP地址进行严格校验比较麻烦,首先要确定一个标准可用的IP地址需要满足如下条件:
1) 由四组不大于255的数字组成,中间由“.”连接
2) 取值范围为0.0.0.0-255.255.255.255
一个IP地址可以看成是四组0-255的数组中间由.隔开,进一步可以看成是0-255.重复三次(注意0-255后有点),后边再跟上一个0-255的数字。
下面对0-255的数字可能的组成情况进行分析:
| 数字 | 取值 | 正则表达式 |
|---|---|---|
| 三位数 | ||
| 25开头 | 250-255 | 25[0-5] |
| 20-24开头 | 200-249 | 2[0-4][0-9] |
| 1开头 | 100-199 | 1[0-9][0-9]等价于1\d{2} |
| 二位数 | ||
| 两位数 | 10-99 | [1-9]\d |
| 一位数 | ||
| 一位数 | 0-9 | \d |
将上述五种情况组合在一起就是我们想要的结果,这里注意五种情况之间是或的关系,用|连接,可以得到(0-255)的正则表达式如下:
(25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d
以上是一组0-255的数据,上边已经分析了思路,IP由三组(0-255).和一组0-255组成,三组(0-255).就是(0-255).重复三次。
首先是(0-255).的表达式:
((25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d).
然后重复三次:
(((25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d).){3}
最后加上一组(0-255):
(((25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d).){3}((25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d)
为了更严谨点,需要加上开始和结束限定符,如下所示:
^(((25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d).){3}((25[0-5])|(2[0-4]\d)|(1\d{2})|([1-9]\d)|\d)$
下面开始验证,新建一个ip.txt,内容如下:
290.244.1900.3
254.263.233.0
192.168.266.900
aa.3.0.1
2.2.2.3b
127.02.0.00
192.168.212.11
0.0.0.0
255.255.255.255
其中只有最后三行的IP地址是正确的,我们检验下刚才写的正则表达式:
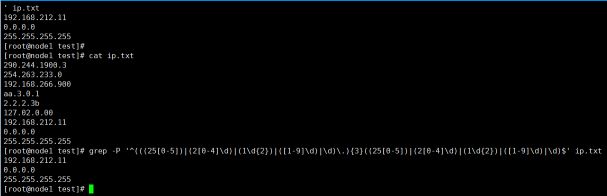
可以看到输出结果达到了预期的效果,证明正则表达式是有效的。