转载: 奔跑的鳄鱼 菜鸟学Python
菜鸟学Python累计写了400多篇文章,其中的入门干货非常多。但是技术类文章含有很多代码、公式、图片等,即使爬到了内容阅读体验也很差。如果能整理成电子书该多好啊,可以系统的阅读!想到了万能的Python,于是把我的上的“菜鸟学python”进行爬取,效果还不错。
总体思路是获取文章列表和URL、对每篇文章进行滚动截屏、图片处理和拼接、图片转换为pdf、将多个pdf文件进行合并成一个文档并添加标签,由于涉及内容较多决定分两篇文章来进行阐述。
1.爬取列表页课程大纲
1)建立sitemap
使用webscraper前最好把开发者模式调到页面底部,这样看起来方便,按下图所示依次选择web scraper——create new sitemap——create sitemap选项,建立sitemap。
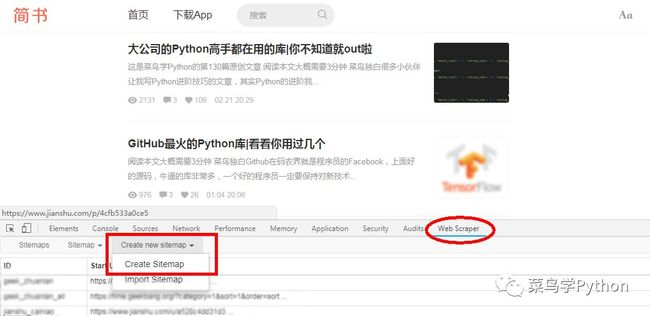
在对应位置输入sitemap名称和起始页URL即可完成创建(下图)

2).选择爬取对象
在这一步要做的主要就是选择爬取目标,与我们自己写爬虫时用的选择器功能类似。对本次任务来说,我们只需要获取文章名称、文章URL和发布时间(发布时间主要用于文章排序和筛选)。
点击“add new selector”按钮新建选择器,下图中的ID是选择器名称,Type是要取的数据类型,比如text、link等等。
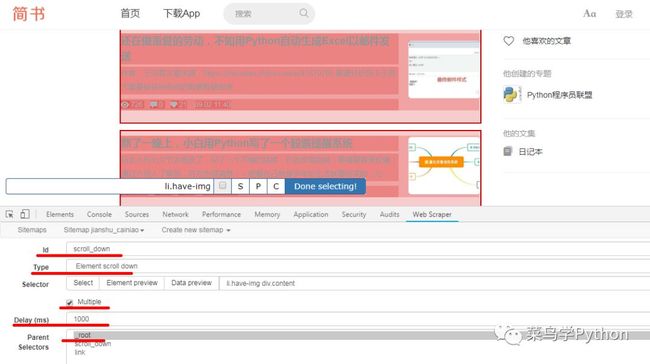
首先要获取容器列表,然后才能在对应的容器中提取目标数据,另外由于中的列表页是滚动加载的,所以我们这里选择的类型为element scroll down
如果需要多选,multiple一定要勾选,这样只要连续选择前两个目标就会自动选定所有同类项(图中红色区域)
对于element scroll down来说,delay是滚动间隔延时,具体数值可以根据自己网络情况设置,但是不能为0,否则无法获取到页面滚动后加载的页面数据;
parent是当前选择器的父节点,这里选择root
之后就可以在刚才选定的element的基础上选择目标数据了,因为文章标题、URL、发布时间三项数据的获取方式基本相同,我们仅以文章标题为例进行演示:
文章标题需要获取的是文字内容,Type栏当然选择text;
需要注意的是,每条数据(比如每个标题、URL)都有各自对应的父节点element(图中黄色部分),所以这里的“multiple”选项不要勾选;
parent selectors当然是选择刚才建立的element scroll down了;
其他选项使用默认值就可以,最后点击左下角的save selector即可完成操作。
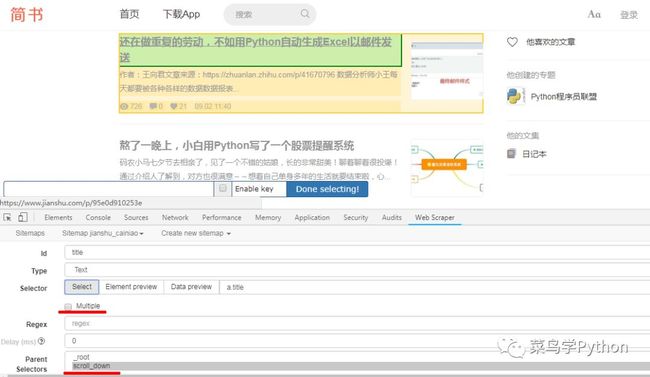
补充一点关于selector选择的技巧:在点击select按键后会出现一个显示栏,通常使用鼠标选择目标元素然后点击Done selecting按钮即可。
但是有些目标元素自带页面跳转功能,这时可以勾选显示栏中的Enable key选项,显示栏会变成下图中的样子,之后就可以使用快捷键(S\P\C)进行元素选择了。
3).爬取数据
在爬取数据之前,我们可以进入sitemap (name)下的selector graph页面,在这里可以比较直观地看到选择器的结构,如果爬虫层次比较多、结构比较复杂,为了避免不必要的错误,爬取前可以通过这种方式进行检查。
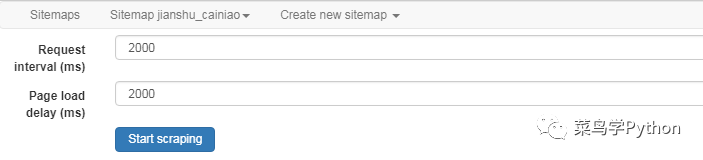
现在我们正式开始爬取数据,进入sitemap (name)下的scrape页面,设置访问和页面加载延时(下图),点击start scraping开始爬取。
由于数据量很小,爬取工作几秒钟就能完成,结果如下,可以通过sitemap (name)下的export data as CSV选项将数据以csv文件格式导出。不过webscraper获取到的数据是乱序的,因此我们才需要获取文章的发布时间,并以此为依据进行排序。

****2.使用selenium进行页面截图****
1).获取文章列表
在这一步需要获取文章名列表和文章地址列表,其中文章名称用于设置文件名、建立标签(后面会讲到),文章地址用于访问文章的详情页。通过pandas可以很方便地从csv文件中获取相关信息,代码如下:
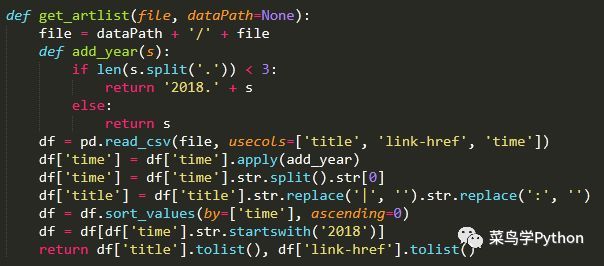
由于当本年度发表的文章其发布时间一栏没有年份,所以在数据清洗的时候要进行补全,之后才能按时间顺序对数据进行排序;另外有些文章名中含有“|”、“:”这种无法作为文件名的字符,需要去掉;在这一步还可以对文章进行筛选,比如可以只选择发表时间为2018年的文章。
2).文章页截图
说起网页截图不得不提PhantomJS,可惜它对JS的支持不够好,有时候会出现取不到真实数据的问题,所以我们还是使用Chrome。Chrome最大的问题是不支持截长图,只能采用逐一截取当前显示区域图片再拼接的方式获取文章内容。
文章内容元素的高度在selenium中可以使用选定元素的size属性来获取,而当前窗口的显示高度只能通过JS代码来获取,幸运的是selenium的execute_script方法允许python执行给定的JS指令,这种方法同样可以用于页面翻动操作,具体代码如下:
需要注意的是,execute_script执行的js代码和主线程代码是同步运行的,为了保证程序同步可以加一个小小的延时。接下来写一个入口函数,获取文章列表并为每篇文章建立独立文件夹,然后进行滚动截图,截取的图片保存到相应的文件夹内。
来看几张截取到的图片,可以发现每张图的顶部都飘着一条的“横幅”,不但影响阅读体验,还遮挡住了一部分文章内容。
3).截图优化
发现问题就要改正问题,页面顶部的“横幅”栏是最初没有考虑到的,为了防止文章内容被遮挡,需要调整页面每次翻动的步长,通过减小每次翻动的距离来防止未截图的内容被遮挡,顶部栏元素的高度获取方式与文章内容元素的获取方式相同。直接来看改动后的代码:
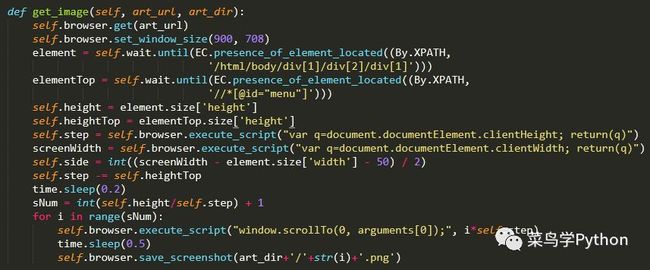
上面的代码不但获取了页面顶部栏的高度,还顺便获取了文章两侧的空白宽度,这个参数可以用于将文章内容两侧多余的部分去除,可以说是为后期的图片处理做的准备。