1. HDFS Federation架构介绍:
1. HDFS介绍:
HDFS包含两层,分别是Namespace (命名空间)和 Block Storage service (块存储服务)。
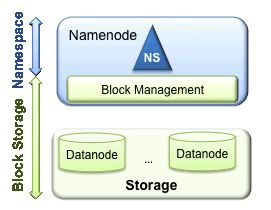
Block Storage Service包含两部分:
(1)Block Management (Namenode实现)
(2)Storage (Datanode实现)
传统的HDFS一般使用一个Namespace来管理整个集群,而且由一个namenode来管理这个namespace。HDFS Federation可以突破这个限制,可以支持多个namenodes/namespaces。
2. HDFS Federation:
为了水平扩展name service , federation使用多个独立的 Namenodes/Namespaces。
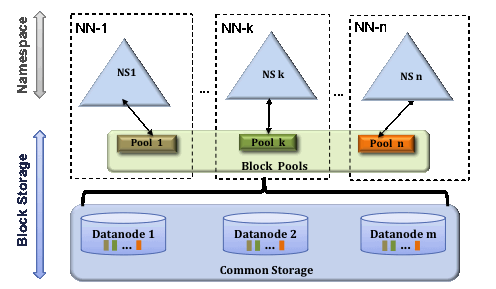
(1)Block pool
Block Pool是属于一个namespace的一组块,datanode存储集群中所有block pools的块。
(2)Cluster ID:
集群中的每一个节点都分配一个ClusterID。
3. 使用HDFS Federation的原因:
(1)NameSpace可扩展性:HDFS的存储可以通过增加datanode节点来随意扩展。但是namenode保存元数据,如果存储的数据过大、或者集群中存在很多小文件,增加namenode可以很好地解决问题。
(2)性能:文件系统操作吞吐量(磁盘IO)是以往HDFS的瓶颈,对HDFS的访问和修改都需要经过namenode。
(3)隔离:在多用户环境下,一个namenode无法提供隔离,如果一个应用的负载过大的话,可能会影响其他关键任务。在多namenode节点环境下,不同的应用和用户可以被隔离到不同的namespace上。
2. HDFS Federation 环境配置:
1. 资源安装规划:
HDFS Federation只涉及到Namenode和Datanode,所以只考虑这2个角色的规划即可。在senior01上安装nn1,在senior02上安装nn2,同时在三台主机上安装datanode。
2. Federation配置:
(1). 配置hdfs-site.xml:
根据官网的配置样例,配置hdfs-site.xml。配置dfs.nameservices 的 ns1和ns2。
(2). 配置core-site.xml :
在分布式集群配置中,因为只有一个namenode,所以所有节点的fs.defaultFS配置项都是一致的(即namenode节点的URL)。但是在配置HDFS Federation时,由于有多个namenode,所以这些namenode的该项的访问地址都应该是自己。
(3) 同步配置到其他节点:
同步配置到其他节点:
scp -r hadoop-2.5.0 [email protected]:/opt/modules/
scp -r hadoop-2.5.0 [email protected]:/opt/modules/
另外,由于senior02也是namenode,需要修改senior02的配置文件core-site.xml的fs.defaultFS配置项。
(4)在每一个Namenode节点格式化Namenode。
使用下面命令来格式化(需要在2个namenode上格式化):
$ bin/hdfs namenode -format -clusterId hdfs-cluster
这块需要注意,在格式化时候,指定了一个clusterId。在两个namenode上使用同样的语句进行格式化时,也就表明为这2个namenode指定了同一个clusterId,这样就表示2个namenode是属于同一个联盟的(Federation在这里体现)
(5)启动hdfs:
$ sbin/start-dfs.sh
(6)测试HDFS Federation:
在启动了2个hdfs federation后,我们访问50070端口,可以发现2个active 状态的 namenode:
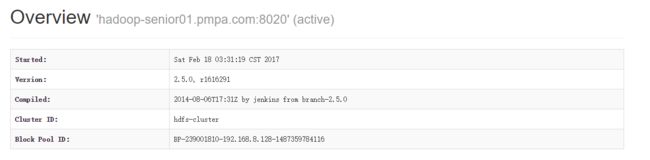
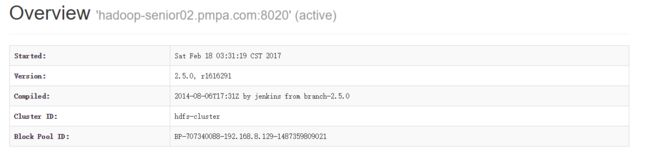
在senior01上传一个文件:
$ bin/hdfs dfs -put sort.txt /
这时候,我们发现,在senior01上可以查看到这个文件,但是在senior02上查不到。


我们在第三台服务器senior03上 使用命令查看文件时能查看到sort.txt:
$ bin/hdfs dfs -ls /
因为,senior03的core-site.xml的配置项fs.defaultFS 的值为:hdfs://hadoop-senior01.pmpa.com:8020 。 如果修改这个值为hdfs://hadoop-senior02.pmpa.com:8020,在测试结果:
$ bin/hdfs dfs -ls /
这时候再查询时,已经查不到这个文件了。这其实说明HDFS Federation是配置了2个访问入口[ns1]和[ns2],他们之间是不重合的。
3. 三种启动方式:
(1)单独启动:
启动namenode,datanode:
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
启动Resource Manager, Node Manager :
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
(2)按模块启动:
$ sbin/start-dfs.sh
$ sbin/start-yarn.sh
(3)全部启动:
$ sbin/start-all.sh
4.常用工具distcp和hftp
Distcp工具是使用运行在Yarn的HDFS集群内和集群间的数据拷贝工具,使用MapReduce开发。该工具往往应用于同版本hadoop不同集群间的数据的复制。那么hftp主要应用于不同版本的hadoop集群间的数据拷贝。
下面以上边实验的基础来实验这2个命令。我在hadoop-senior01(namenode1)上上传2个文件,分别是/sort.txt 和 /input/wordcount.txt,下面分别利用 distcp和hftp来将这2个文件分别拷贝到hadoop-senior02(namenode2)上。
1. distcp :
这里需要特别注意,因为distcp是使用mapreduce开发的,运行在yarn上,所以运行这个命令的时候,一定要保证yarn是在正常运行的。我的yarn的主节点(Resource Manager)运行在senior02上,所以需要在senior02上运行 sbin/start-yarn.sh来启动yarn。
之后运行distcp命令即可拷贝:
$ bin/hadoop distcp hdfs://hadoop-senior01.pmpa.com:8020/sort.txt hdfs://hadoop-senior02.pmpa.com:8020/
成功后,我们可以在namenode02上也看到这个文件了。
2.hftp:
上边提过hftp类似于网络层的ftp协议。使用hftp可以实现不同版本hadoop间的数据拷贝,例如从0.x版本拷贝到2.x版本。在使用hftp协议时候,应该使用50070端口(Web访问协议),拷贝到hdfs协议(8020 rpc端口)。
如下边语句运行:
$ bin/hadoop distcp -i hftp://hadoop-senior01.pmpa.com:50070/input/wordcount.txt hdfs://hadoop-senior02.pmpa.com:8020/input/wordcount.txt
其中-i参数的含义:忽略错误。
5. MapReduce执行流程:
XXX
6. 使用MapReduce实现二次排序:
XXX