本篇文章的主要内容如下:
- 1、Java线程概念
- 2、Android线程的实现
- 3、线程的阻塞
- 4、关于线程上下文切换
- 5、关于线程的安全问题
- 6、守护线程
- 7、线程的内存
一、线程概念
(一)、进程
在现代的操作系统中,进程是资源分配的最小单位,而线程是CPU调度的基本单位。一个进程中最少有一个线程,名叫主线程。进程是程序执行的一个实例,比如说10个用户同时执行Chrome浏览器,那么就有10个独立的进程(尽管他们共享一个可执行代码)。
1、进程的特点:
每一个进程都有自己的独立的一块内存空间、一组资源系统。其内部数据和状态都是完全独立的。进程的优点是提高CPU的运行效率,在同一个时间内执行多个程序,即并发执行。但是从严格上将,也不是绝对的同一时刻执行多个程序,只不过CPU在执行时通过时间片等调度算法不同进程告诉切换。
所以总结来说:进程由操作系统调度,简单而且稳定,进程之间的隔离性好,一个进程的奔溃不会影响其他进程。单进程编程简单,在多个情况下可以把进程和CPU进行绑定,充分利用CPU。
当然多进程也有一些缺点
2、进程的缺点:
一般来说进程消耗的内存比较大,进程切换代价很高,进程切换也像线程一样需要保持上一个进程的上下文环境。比如在Web编程中,如果一个进程处理一个请求的话,如果提高并发量就要提高进程数,而进程数量受内存和切换代价限制。
(二)、线程
线程是进程的一个实体,是CPU调度和分配的基本单位,它比进程更下偶读能独立运行的基本单位,线程自己基本上不拥有系统资源,只拥有一点在运行中不可少的资源(如程序计数器、栈),但是它可与同属一个进程的其他线程共享进程所拥有的全部资源。
同类的多线程共享一块内存空间一组系统资源,线程本身的数据通常只有CPU的寄存器数据,以及一个供程序执行的堆栈。线程在切换时负荷小,因此,线程也称为轻负荷进程。一个进程中可以包含多个线程。
在JVM中,本地方法栈、虚拟机栈和程序计数器是线程隔离的,而堆区和方法区是线程共享的。
(三)、进程线程的区别
地址空间:线程是进程内的一个执行单元;进程至少有一个线程;一个进程内的多线程它们共享进程的地址空间;而进程自己独立的地址空间
资源有用:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源。
线程是处理器调度的基本单位,但进程不是
二者均可并发执行(下面补充了并发和并行的区别)
并发:多个事件在同一个时间段内一起执行
并行:多个事件在同一时刻同时执行
(四)、多线程
为了进一步提高CPU的利用率,多线程便诞生了。一个程序可以运行多个线程,多个线程可以同时执行,从整个应用角度上看,这个应用好像独自拥有多个CPU一样。虽然多线程进一步提高了应用的执行效率,但是由于线程之间会共享内存资源,这会导致一些资源同步的问题,另外,线程之间切换也会对资源有所消耗。
这里需要注意的是,如果一台电脑只有一个CPU核心,那么多线也并没有真正的"同时"运行,它们之间需要通过相互切换来共享CPU核心,所以,只有一个CPU核心的情况下,多线程不会提高应用效率。但是,现在计算机一般都会有多个CPU,并且每个CPU可能还有会多个核心,所以现在硬件资源条件下,多线程编程可以极大的提高应用的效率。

在Java程序中,JVM负责线程的调度。线程调度是按照特定的机制为多个线程分配CPU的使用权。
调度的模式有两种:分时调度和抢占式调度。分时调度是所有线程轮流获得CPU使用权,并平均分配每个线程占用CPU的时间;抢占式调度是根据线程的优先级别来获取CPU的使用权。JVM的线程调度模式采用了抢占式模式。
二、Android线程的实现
Android线程,一般地就是指Android虚拟机线程,而虚拟机线程是由通过系统调用而创建的Linux线程。纯粹的Linux线程与虚拟机线程区别在于虚拟机线程具有运行Java代码的runtime。
在Android 中当担也就对应一个类。从这一点上看Thread和其他类并没有任何区别,只不过Thread的属性和方法仅用于完成"线程管理"这个任务而已。在Android系统中,我们经常需要启动一个新的线程,这些线程大多从Thread这个类继承
(一)、Thread类
Thread.java
public class Thread implements Runnable {
.....
}
通过上面代码,我们可以知道Thread实现了Runnable,侧面也说明线程是"可执行的代码"。
public interface Runnable {
public abstract void run();
}
Runnable是一个接口类,唯一提供的方法就是run()。
1、Thread的使用:
一般情况下,我们是这样使用Thread的:
(1)、继承Thread:
public MyThread extends Thread{
}
MyThread mt=new MyThread();
mt.start();
(2)、直接使用Runnable:
Thread的关键就是Runnable,因此下面的是另一个常见的用法。
new Thread(Runnable runnable).start();
2、Thread的常用方法:
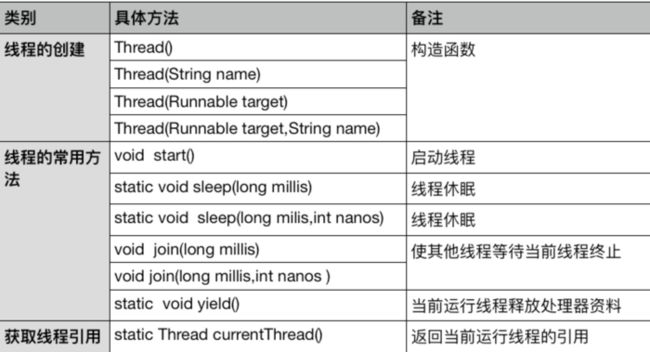
3、Thread的常用字段:
volatile ThreadGroup group;
volatile boolean daemon;
volatile String name;
volatile int priority;
volatile long stackSize;
Runnable target;
private static int count = 0;
/**
* Holds the thread's ID. We simply count upwards, so
* each Thread has a unique ID.
*/
private long id;
/**
* Normal thread local values.
*/
ThreadLocal.Values localValues;
我们就依次说下:
- group:每一个线程都属于一个group,当线程被创建是,就会加入一个特定的group,当线程运行结束,会从这个group移除。
- deamon:当前线程不是守护线程,守护线程只会在没有非守护线程运行下才会运行
- name:线程名称
- priority:线程优先级,Thread的线程优先级取值范围为[1,10],默认优先级为5
- stackSize:线程栈大小,默认是0,即使用默认的线程栈大小(由dalvik中的全局变量gDvm.stackSize决定)
- target:一个Runnable对象,Thread的run()方法中会转调target的run()方法,这是线程真正处理事务的地方。
- id:线程id,通过递增的count得到该id,如果没有显式给线程设置名字,那么就会使用Thread+id当前线程的名字。注意这里不是真正的线程id,即在logcat中打印的tid并不是这个id,那tid是指dalvik线程id
- localValues:本地线程存储(TLS)数据 关于TLS后面会详细介绍
4、create()方法:
为什么要研究create()方法?因为Thread有9个构造函数,其中8个里面最终都是调用了create()方法
在Thread.java 402行
/**
* Initializes a new, existing Thread object with a runnable object,
* the given name and belonging to the ThreadGroup passed as parameter.
* This is the method that the several public constructors delegate their
* work to.
*
* @param group ThreadGroup to which the new Thread will belong
* @param runnable a java.lang.Runnable whose method run will
* be executed by the new Thread
* @param threadName Name for the Thread being created
* @param stackSize Platform dependent stack size
* @throws IllegalThreadStateException if group.destroy() has
* already been done
* @see java.lang.ThreadGroup
* @see java.lang.Runnable
*/
private void create(ThreadGroup group, Runnable runnable, String threadName, long stackSize) {
//步骤一
Thread currentThread = Thread.currentThread();
//步骤二
if (group == null) {
group = currentThread.getThreadGroup();
}
if (group.isDestroyed()) {
throw new IllegalThreadStateException("Group already destroyed");
}
this.group = group;
synchronized (Thread.class) {
id = ++Thread.count;
}
if (threadName == null) {
this.name = "Thread-" + id;
} else {
this.name = threadName;
}
this.target = runnable;
this.stackSize = stackSize;
this.priority = currentThread.getPriority();
this.contextClassLoader = currentThread.contextClassLoader;
// Transfer over InheritableThreadLocals.
if (currentThread.inheritableValues != null) {
inheritableValues = new ThreadLocal.Values(currentThread.inheritableValues);
}
// add ourselves to our ThreadGroup of choice
//步骤二
this.group.addThread(this);
}
我把create内部代码大体上分为3个部分
- 步骤一:通过静态函数currentThread获取创建线程所在的当前线程
- 步骤二:将创新线程所在的当前线程的一些属性赋值给即将创建的线程
- 步骤三:通过调用ThreadGroup的addThread方法将新线程添加到group中。
5、Thread的生命周期:
线程共有6种状态;在某一时刻只能是这6种状态之一。这些状态由Thread.State这个枚举类型表示,并且可以通过getState()方法获得当前具体的状态类型。
Thread.State这个枚举类在在Thread.java 78行
/**
* A representation of a thread's state. A given thread may only be in one
* state at a time.
*/
public enum State {
/**
* The thread has been created, but has never been started.
*/
NEW,
/**
* The thread may be run.
*/
RUNNABLE,
/**
* The thread is blocked and waiting for a lock.
*/
BLOCKED,
/**
* The thread is waiting.
*/
WAITING,
/**
* The thread is waiting for a specified amount of time.
*/
TIMED_WAITING,
/**
* The thread has been terminated.
*/
TERMINATED
}
我们在说明下:
- NEW : 起劲尚未启动的线程的状态。当使用new一个新线程时,如new Thread(runnable),但还没有执行start(),线程还有没有开始运行,这时线程的状态就是NEW。
- RUNNABLE:可运行线程的线程状态。此时的线程可能正在运行,也可能没有运行。
- BLOCKED:受阻塞并且正在等待监视锁的某一线程的线程状态。
进入阻塞状态的情况:
① 等待某个操作的返回,例如IO操作,该操作返回之前,线程不会继续后面的代码
② 等待某个"锁",在其他线程或程序释放这个"锁"之前,线程不会继续执行。
③ 等待一定的触发条件
④ 线程执行了sleep()方法
⑤ 线程被suspend()方法挂起
一个被阻塞的线程在下列情况下会被重新激活
⑤ 线程被suspend()方法挂起
一个被阻塞的线程在下列情况下会被重新激活
① 执行了sleep(),随眠时间已到
② 等待的其他线程或者程序持有"锁"已经被释放
③ 正在等待触发条件的线程,条件已得到满足
④ 执行suspend()方法,被调用了resume()方法
⑤ 等待的操作返回的线程,操作正确返回。- WAITING:某一等待线程的线程状态。线程因为调用了Object.wait()或者Thread.join()而未运行,就会进入WAITING状态。
- TIMED_WAITING:具有指定等待时间的某一等待线程的线程状态。线程是应为调用了Thread.sleep(),或者加上超时值在调用Object.wait()或者Thread.join()而未运行,则会进入TIMED_WAITING状态。
- TERMINATED:已终止线程状态。线程已运行完毕,它的run()方法已经正常结束或者通过抛出异常而技术。线程的终止,run()方法结束,线程就结束了。
总结称为一幅图就是下图

6、线程的启动:
上面说的这两种方法获取Thread,最终都通过start()方法启动。
代码在Thread.java 1058行
/**
* Starts the new Thread of execution. The run() method of
* the receiver will be called by the receiver Thread itself (and not the
* Thread calling start()).
*
* @throws IllegalThreadStateException - if this thread has already started.
* @see Thread#run
*/
public synchronized void start() {
//保证线程只启动一次
checkNotStarted();
hasBeenStarted = true;
nativeCreate(this, stackSize, daemon);
}
private void checkNotStarted() {
if (hasBeenStarted) {
throw new IllegalThreadStateException("Thread already started");
}
}
通过上面代码我们看到,start()方法里面首先是判断是不是启动过,如果没启动过直接调用nativeCreate(Thread , long, boolean)方法,通过方法名,我们知道是一个nativce方法
代码在Thread.java 1066行
private native static void nativeCreate(Thread t, long stackSize, boolean daemon);
6.1、nativeCreate()函数
nativeCreate()这是一个native方法,那么其所对应的JNI方法在哪里?在java_lang_Thread.cc中getMethods是一个JNINativeMethod数据
代码在java_lang_Thread.cc 179行
static JNINativeMethod gMethods[] = {
NATIVE_METHOD(Thread, currentThread, "!()Ljava/lang/Thread;"),
NATIVE_METHOD(Thread, interrupted, "!()Z"),
NATIVE_METHOD(Thread, isInterrupted, "!()Z"),
NATIVE_METHOD(Thread, nativeCreate, "(Ljava/lang/Thread;JZ)V"),
NATIVE_METHOD(Thread, nativeGetStatus, "(Z)I"),
NATIVE_METHOD(Thread, nativeHoldsLock, "(Ljava/lang/Object;)Z"),
NATIVE_METHOD(Thread, nativeInterrupt, "!()V"),
NATIVE_METHOD(Thread, nativeSetName, "(Ljava/lang/String;)V"),
NATIVE_METHOD(Thread, nativeSetPriority, "(I)V"),
NATIVE_METHOD(Thread, sleep, "!(Ljava/lang/Object;JI)V"),
NATIVE_METHOD(Thread, yield, "()V"),
};
其中一项为:
NATIVE_METHOD(Thread, nativeCreate, "(Ljava/lang/Thread;JZ)V")
这里的NATIVE_METHOD定义在java_lang_Object.cc文件中,如下:
代码在java_lang_Object.cc 25行
#define NATIVE_METHOD(className, functionName, signature, identifier) \
{ #functionName, signature, reinterpret_cast(className ## _ ## identifier) }
将宏定义展开并带入,可得所对应的方法名为Thread_nativeCreate
6.2、Thread_nativeCreate()函数
代码在thread.cc 388行
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
CHECK(java_peer != nullptr);
Thread* self = static_cast(env)->self;
Runtime* runtime = Runtime::Current();
// Atomically start the birth of the thread ensuring the runtime isn't shutting down.
bool thread_start_during_shutdown = false;
{
MutexLock mu(self, *Locks::runtime_shutdown_lock_);
if (runtime->IsShuttingDownLocked()) {
thread_start_during_shutdown = true;
} else {
runtime->StartThreadBirth();
}
}
if (thread_start_during_shutdown) {
ScopedLocalRef error_class(env, env->FindClass("java/lang/InternalError"));
env->ThrowNew(error_class.get(), "Thread starting during runtime shutdown");
return;
}
Thread* child_thread = new Thread(is_daemon);
// Use global JNI ref to hold peer live while child thread starts.
child_thread->tlsPtr_.jpeer = env->NewGlobalRef(java_peer);
stack_size = FixStackSize(stack_size);
// Thread.start is synchronized, so we know that nativePeer is 0, and know that we're not racing to
// assign it.
env->SetLongField(java_peer, WellKnownClasses::java_lang_Thread_nativePeer,
reinterpret_cast(child_thread));
// Try to allocate a JNIEnvExt for the thread. We do this here as we might be out of memory and
// do not have a good way to report this on the child's side.
std::unique_ptr child_jni_env_ext(
JNIEnvExt::Create(child_thread, Runtime::Current()->GetJavaVM()));
int pthread_create_result = 0;
if (child_jni_env_ext.get() != nullptr) {
pthread_t new_pthread;
pthread_attr_t attr;
child_thread->tlsPtr_.tmp_jni_env = child_jni_env_ext.get();
CHECK_PTHREAD_CALL(pthread_attr_init, (&attr), "new thread");
CHECK_PTHREAD_CALL(pthread_attr_setdetachstate, (&attr, PTHREAD_CREATE_DETACHED),
"PTHREAD_CREATE_DETACHED");
CHECK_PTHREAD_CALL(pthread_attr_setstacksize, (&attr, stack_size), stack_size);
/***这里是重点,创建线程***/
pthread_create_result = pthread_create(&new_pthread,
&attr,
Thread::CreateCallback,
child_thread);
CHECK_PTHREAD_CALL(pthread_attr_destroy, (&attr), "new thread");
if (pthread_create_result == 0) {
// pthread_create started the new thread. The child is now responsible for managing the
// JNIEnvExt we created.
// Note: we can't check for tmp_jni_env == nullptr, as that would require synchronization
// between the threads.
child_jni_env_ext.release();
return;
}
}
// Either JNIEnvExt::Create or pthread_create(3) failed, so clean up.
{
MutexLock mu(self, *Locks::runtime_shutdown_lock_);
runtime->EndThreadBirth();
}
// Manually delete the global reference since Thread::Init will not have been run.
env->DeleteGlobalRef(child_thread->tlsPtr_.jpeer);
child_thread->tlsPtr_.jpeer = nullptr;
delete child_thread;
child_thread = nullptr;
// TODO: remove from thread group?
env->SetLongField(java_peer, WellKnownClasses::java_lang_Thread_nativePeer, 0);
{
std::string msg(child_jni_env_ext.get() == nullptr ?
"Could not allocate JNI Env" :
StringPrintf("pthread_create (%s stack) failed: %s",
PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
ScopedObjectAccess soa(env);
soa.Self()->ThrowOutOfMemoryError(msg.c_str());
}
}
这里面重点是pthread_create()函数,pthread_create是pthread库中的函数,通过syscall再调用到clone来创建线程。
原型:int pthread_create((pthred_t thread,pthread_attr_t * attr, void * (start_routine) (void * ), void * arg))
头文件:#include
入参: thread(线程标识符)、attr(线程属性设置)、start_routine(线程函数的起始地址)、arg(传递给start_rountine参数):
返回值:成功则返回0;失败则返回-1
功能:创建线程,并调用线程其实地址指向函数start_rountine。
再往下就到内核层了,由于篇幅限制,就先不深入,有兴趣的同学可以自行研究
三、线程的阻塞
线程阻塞指的是暂停一个线程的执行以等待某个条件发生(如某资源就绪)。Java提供了大量的方法来支持阻塞,下面让我们逐一分析。
(一)、sleep()方法
sleep()允许指定以毫米为单位的一段时间作为参数,它使得线程在指定的时间内进入阻塞状态,不能得到CPU时间,指定的时间已过,线程重新进入可执行状态。典型地,sleep()被用在等待某个资源就绪的情形:测试发现条件不满足后,让线程阻塞一段后重新测试,直到条件满足为止。
(二) suspend()和resume()方法
两个方法配套使用,suspend()使得线程进入阻塞状态,并且不会自动恢复,必须其对应的resume()被调用,才能使得线程重新进入可执行状态。典型地,suspend()和resume()被用在等待另一个线程产生结果的情形:测试发现结果还没有产生后,让线程阻塞,另一个线程产生了结果后,调用resume()使其恢复。
(三) yield()方法
yeield()使得线程放弃当前分得的CPU时间,但是不使线程阻塞,即线程仍处于可执行状态,随时可能再次分的CPU时间。调用yield()效果等价于调度程度认为该线程已执行了足够的时间从而转到另一个线程。
(四) wait()和notify()方法
两个方法配套使用,wait()使得线程进入阻塞状态,它有两种形式,一种允许指定以毫秒为单位的一段时间作为参数,另一种没有参数是,当前对应的notify()被调用或者超出指定时间,线程重新进入可执行状态,后者则必须对应的notify()被调用。初看起来它们与suspend()和resume()方法对没有什么分别,但是事实上它们是截然不同的。区别的核心在于,前面叙述的所有方法,阻塞时都不会释放占用的锁(如果占用的话),而这一对方法则相反。
这里需要重点介绍下wait()和notify()
- 首先,前面叙述的所有方法都隶属于Thread类,但是这一对却直接隶属于Object类,也就是说,所有对象都拥有这一对方法。初看起来十分不可思议,但是实际上却是很自然的,因为这一对方法阻塞时需要释放占用的锁,而锁是任何对象都具有的,调用对象wait()方法导致线程阻塞,并且该对象上的锁释放。而调用对象的notify()方法则导致因调用对象的wait()方法而阻塞线程中随机选择的一个解除阻塞(但要等待获得锁后才真正可执行)。
- 其次,前面叙述的所有方法都可在任何位置调用,但是这一对方法却必须在synchronized方法或块中调用,理由也很简单,只有synchronized方法或块中当前线程才占有锁,才有锁可以释放。同样的道理,调用这一对方法的对象上的锁必须为当前线程所拥有,这样才有锁可以释放。
- 第三,调用notify()方法导致解除阻塞的线程是从因调用该对象的wait()方法而阻塞的线程中随机选取的,我们无法预料那个一个线程将会被选择,所以编程时需要特别小心,避免因这种不确定性而产生问题。
- 最后,除了notify(),还有一个方法notifyAll()也可能其到类似作用,唯一的区别是在于,调用notifyAll()方法将把 因 调用该对象的wait()方法而阻塞的所有线程一次性全部解除阻塞。当然,只有获得锁的那一个线程才能进入可执行状态。
四、关于线程上下文切换
在多线程编程中,多个线程公用资源,计算机会多个线程进行调度。因此各个线程会经历一系列不同的状态,以及在不同的线程间进行切换。
既然线程需要被切换,在生命周期中处于各种状态,如等待、阻塞、运行。就需要能够保存线程,在线程被切换后/回复后需要继续在上一个状态运行。这就是所谓的上下文切换。为了实现上下文切换,势必会消耗资源,造成性能损失。因为我们在进行多线程编程过程中需要减少上下文切换,提高程序运行性能。
一些常用的方法:
- 无锁并发编程:可以采用一些方法避免锁的使用,如不同线程去处理不同段
- CAS常用算法:原子操作不需要加锁
- 使用最少线程:避免创建不需要的线程
- 协程:在单线程里实现多任务调度
五、关于线程的安全问题
线程安全无非是要控制多个线程对某个资源的有序访问或修改。即多个线程,一个临界区,通过通知这些线程对临界区的访问,使得每个线程的每次执行结果都相同(搞清楚这个问题,可以避免多线程编程的狠多错误)
(一)、实现线程安全的工具:
- 1 隐式锁:synchronized
- 2 显式锁:java.util.concurrent.lock
- 3 关键字:volatile
- 4 原子操作:java.util.concurrent.atomic
(二)、线程同步阀:
- 1 CountDownLatch类是一个同步计数器。(java.util.concurrent.CountDownLatch)
- 2 CyclicBarrier是一个同步辅助类,它允许一组线程相互等待,直到到到某个公共屏蔽点(common barrier point)。在涉及一组固定大小的线程的程序中,这些线程不时地相互等待,这时候CyclicBarrier很有用。因为barrier在释放等待线程后可以重用,因此称为循环的barrier。
- 3 信号量(java.util.concurrent.Semaphone),计数信号量,该信号量维护一定大小的许可集合,规定最多允许多少个进程同时访问临界区。其中,semp.acquire()类似于操作系统中的P操作,semp.release类似于操作系统的V操作。
- 4 任务机制(java.util.concurrent.Future->FutureTask)。结合Runnable使用!一般FutureTask多用于耗时的计算,主线程在完成自己的任务后再去获取结果;只有计算完成时获取,否则一直阻塞。
六、守护线程
(一) 概念
守护线程我觉得还是很有用的。首先看看守护进程是什么?守护线程就是后台运行的线程。普通线程结束后,守护线程自动结束。一般main线程视为守护线程,以及GC、数据库连接池等,都做成守护进程。
(二) 特点
守护线程就像备胎一样,JRE(女神)根本不会管守护进程有没有,在不在,只要前台线程结束,就算执行完毕了。
(三) 如何使用
直接调用setDeamon() 即可。
(四) 注意事项
setDaemon(true) 必须在start()方法之前调用;在守护线程中开启的线程也是守护线程;守护线程中不能进行I/O操作。
七、线程的内存
(一) Java内存模型
Java内存模型规范了Java虚拟机与计算机内存是符合协同工作的。Java虚拟机是一个完整的计算机的一个模型,因此这个模型自然也包含一个内存模型——又称为Java内存模型。
如果你想设计表现良好的并发程序,理解Java内存模型是非常重要的。Java内存模型规定了如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。
原始的Java内存模型存在一些不足,因此Java内存模型在Java 1.5时被重新修订。这个版本的Java内存模型在Java8中仍在使用。
(二) Java 线程内存模型原理
Java内存模型把Java虚拟机内部划分为线程栈和堆。下面这张图演示了Java内存模型的逻辑视图。
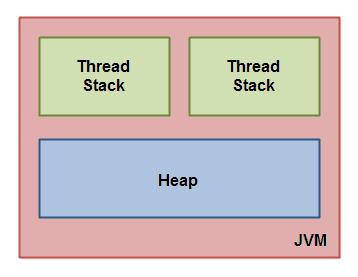
- 每一个运行在Java虚拟机里的线程都拥有自己的线程栈。这个线程栈包含了这个线程调用的方法当前执行点相关的信息。一个线程仅能访问自己的线程栈。一个线程创建的本地变量对其他线程不可见,仅自己可见。即使两个线程执行同样的代码,这两个线程仍然在自己的线程栈中的代码来创建本地变量。因此,每个线程拥有每个本地变量的独有版本。
- 所有原始类型的本地变量都存放在线程栈上,因此对其他线程不可见。一个线程可能向另一个线程传递一个原始类型变量的拷贝,但是它不能共享这个原始类型变量自身。
- 堆上包含在Java程序中创建的所有对象,无论是哪一个对象创建的。这包括原始类型的对象版本。如果一个对象被创建然后赋值给一个局部变量,或者用来作为另一个对象的成员变量,这个对象仍然是存在堆上。
下面这张图演示了调用栈和本地变量存放在线程栈上,对象存放在堆上。

所以大体可以分为以下几种情况:
- 一个本地变量可能是原始类型,在这种情况下,它总是"待在"线程栈上。
- 一个本地变量也可能是指向一个对象的一个引用。在这种情况下,引用(这个本地变量)存放在这个线程栈上,但是对象本身存放在堆上。
- 一个对象可能包含方法,这些方法可能包含本地变量。这些本地变量仍然存放在线程栈上,即使这些方法是所属的对象存放在堆上。
- 一个对象的成员变量可能随着这个对象自身存放在堆上。不管这个成员变量是原始类型还是引用类型。
静态成员变量跟随着类定义一起也存放在堆上。- 存放在堆上的对象可以被所有持有这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个本地变量的私有拷贝。
下图演示了上面提到的点:

PS:
- 1、两个线程拥有一系列的本地变量。其中一个本地变量(Local Variable 2)执行堆上的一个共享对象(Object 3)。这两个线程分贝拥有同一个对象的不同引用。这些引用都是本地变量,因此存放在各自线程的线程栈上。这两个不同的引用指向堆上同一个对象。
- 2、这个共享对象(Object 3)持有Object 2和Object 4一个引用作为其成员员变量(如图中Object 3 指向 Object 2和Object 4的箭头)。通过这在Object 3中这些成员变量引用,这两个线程就可以访问到Object 2和 Object 4。
上面这张图也展示了指向堆上两个不同对象的一个本地变量。在这种情况下,指向两个不同对象的引用不是同一个对象。理论上,两个线程都可以访问Object 1 和Object 5,如果两个线程都拥有两个对象的引用。但是在上图中,每个线程仅有一个引用指向两个对象其中之一。
(三) 硬件内存架构
现代硬件内存模型与Java模型有一些不同。理解内存模型结构以及Java内存模型如何与它协同工作也是非常重要的。这部分描述了通用的硬件内存架构,下面的部分将会描述内存是如何与它"联合"工作的。
现代计算机硬件架构的简单图示:
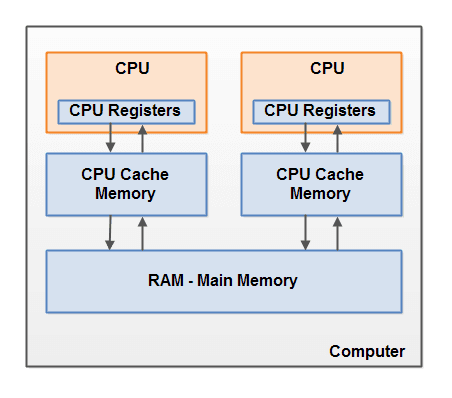
- 一个现代计算机通常由两个或者多个CPU。其中一些CPU还有多核。从这一点可以看出,在一个或者多个CPU的现代计算上运行多个线程是可能的。每个CPU在某一时刻运行一个线程是没有问题的。这意味着,如果你的Java程序是多线程的,在你的Java程序中每个CPU上一个线程可能同时(并发)执行。
- 每个CPU都包含一系列的寄存器,它们是CPU内存的基础。CPU在寄存器上执行操作的速度远大于主存上执行的速度。这是因为CPU访问寄存器的速度远大于主存。
- 每个CPU可能还有一个CPU缓存层。实际上,多数的现代CPU都有一定大小的缓存层。CPU访问缓存层的速度快于访问主存的速度,但通常比访问内部寄存器的速度还要慢一点。一些CPU还有多层缓存,但这些对理解Java内存模型如何和内存交互不是那么重要。只要知道CPU中可以由一个缓存层就可以了。
- 一个计算机还包含一个主存。所有CPU都可以访问主存。主存通常比CPU缓存大得多。
- 通常情况下,当一个CPU需要读取主存时,它会将主存的部分读到CPU缓存中。它甚至可能将缓存中的部分内容读到它的内部寄存器中,然后在寄存器中执行操作。当CPU需要将结果写回到主存中时,它会将内部寄存器值刷新到缓存中,然后在某个时间点将值刷新回主存。
- 当CPU需要在缓存层存放一些东西的时候,存放在缓存中的内容通常会刷新回主存。CPU缓存可以在某一时刻将数据局部写到它的内存中,和在某一时刻局部刷新它的内存。它不会在某一时刻读/写整个缓存。通常,在一个被称作"cache lines"的更小内存块中缓存被更新。一个或者多个缓存行可能被读到缓存,一个或者多个缓存行可能再被刷新回主存。
(四) Java内存模型和硬件内存架构之间的桥接
上面已经提到,Java内存模型与硬件内存架构之间存在差异。硬件内存架构没有区分线程栈和堆。对于硬件,所有的线程栈和堆都分布在主内中。部分线程栈和堆可能有时候会出现在CPU缓存中和CPU内部的寄存器中。
如下图所示:
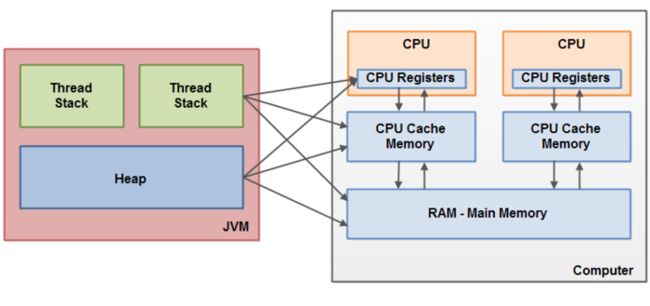
当对象和变量被存放在计算机中各个不同的内存区域中时,就可能会出现一些具体的问题。主要包含两个方面:
- 线程对共享变量修改的可见性
- 当读、写和检查共享变量时rece conditions(竞争条件)
下面我们专门来解释一下上面的两个问题
1、对象的可见性
如果两个或者更多的线程在没有正确使用volatile声明或者同步的情况下共享一个对象,一个线程更新这个共享对象可能对其他线程来说是不可见的。
想象一下,共享对象那个被初始化在主存中。跑在CPU上的一个线程将这个共享对象读到CPU缓存中。然后修改了这个对象。要CPU缓存没有被刷新到主存,对象修改后的版本对跑在其他CPU上的线程都是不可见的。这种方式可能导致每个线程拥有这个共享对象的私有拷贝,每个拷贝停留在不同的CPU缓存中。
下面示意了这种情形。

跑在左边的CPU的线程拷贝这个共享对象到它的CPU缓存中,然后将count变量的值修改为2,这个修改对跑在右边的CPU上的其他线程是不可见的,因为修改后count的值还没有被刷新回主存中去。
解决这个问题你可以使用volatile关键字。volatile关键字可以保证直接从主存中读取一个变量,如果这个变量被修改后,总是会写回到主存中去。
2、Race Conditions(竞争条件)
如果两个或者更多的线程共享一个对象,多个线程在这个共享对象上更新变量,就可能发生Race Conditions(竞争条件)。如果两个或者更多的线程共享一个对象,多个线程在这个共享对象上更新变量,就可能放生Race Conditions(竞争条件)。想象一下,如果线程A读取一个共享对象的变量count到它的CPU缓存中。再想象一下,线程B也做了同样的事情,但是往一个不同的CPU缓存个中。现在线程A将count加1,线程B也做了同样的事情,现在count已经被增加了两个,每个CPU缓存中一次。如果这些增加操作被顺序执行,变量count应该被增加两次,然后原值+2倍写回到主存中区。然而,两次增加都是在没有适当的同步下并发执行的。无论线程A还是线程B将count修改后的版本写回到主存中去,修改后的值仅会被原值大1,尽管增加了两次。
下图演示了上面描述的情况:
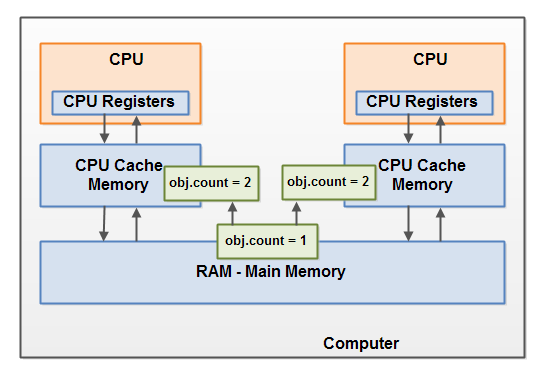
解决这个问题可以使用Java同步块。一个同步块可以保证在同一时刻仅有一个线程可以进入代码的临界区。同步块还可以保证代码块中所有被访问的变量将会从主存中读入,当线程退出同步代码块时,所有被更新的变量会被刷新回主存中区,不管这个变量是否被声明为volatile。
参考文献
Android Handler机制1之Thread