简述匈牙利算法求解最大匹配的主要过程。_带你入门多目标跟踪(三)匈牙利算法&KM算法...
匈牙利算法(Hungarian Algorithm)与KM算法(Kuhn-Munkres Algorithm)是做多目标跟踪的小伙伴很容易在论文中见到的两种算法。他们都是用来解决多目标跟踪中的数据关联问题。
对理论没有兴趣的小伙伴可以先跳过本文,进行下一篇的学习,把匈牙利算法这些先当作一个黑箱来用,等需要了再回过头来学习理论。但个人建议,至少要明白这些算法的目的与大致流程。
如果大家用这两种算法的名字在搜索引擎上搜索,一定会首先看到这个名词:二分图(二部图)。匈牙利算法与KM算法都是为了求解二分图的最大匹配问题。

有一种很特别的图,就做二分图,那什么是二分图呢?就是能分成两组,U,V。其中,U上的点不能相互连通,只能连去V中的点,同理,V中的点不能相互连通,只能连去U中的点。这样,就叫做二分图。
读者可以把二分图理解为视频中连续两帧中的所有检测框,第一帧所有检测框的集合称为U,第二帧所有检测框的集合称为V。同一帧的不同检测框不会为同一个目标,所以不需要互相关联,相邻两帧的检测框需要相互联通,最终将相邻两帧的检测框尽量完美地两两匹配起来。而求解这个问题的最优解就要用到匈牙利算法或者KM算法。
1. 匈牙利算法(Hungarian Algorithm)
先介绍匈牙利算法,引用百度百科的说法,匈牙利算法是一种在多项式时间内求解任务分配问题的组合优化算法,并推动了后来的原始对偶方法。美国数学家哈罗德·库恩于1955年提出该算法。此算法之所以被称作匈牙利算法,是因为算法很大一部分是基于以前匈牙利数学家Dénes Kőnig和Jenő Egerváry的工作之上创建起来的。
https:// blog.csdn.net/dark_scop e/article/details/8880547#commentBox
这篇博文对匈牙利算法进行了非常简单清晰的解释,我这里引用它来说明一下匈牙利算法的流程。

以上图为例,假设左边的四张图是我们在第N帧检测到的目标(U),右边四张图是我们在第N+1帧检测到的目标(V)。红线连起来的图,是我们的算法认为是同一行人可能性较大的目标。由于算法并不是绝对理想的,因此并不一定会保证每张图都有一对一的匹配,一对二甚至一对多,再甚至多对多的情况都时有发生。这时我们怎么获得最终的一对一跟踪结果呢?我们来看匈牙利算法是怎么做的。
第一步.
首先给左1进行匹配,发现第一个与其相连的右1还未匹配,将其配对,连上一条蓝线。

第二步.
接着匹配左2,发现与其相连的第一个目标右2还未匹配,将其配对。

第三步.
接下来是左3,发现最优先的目标右1已经匹配完成了,怎么办呢?
我们给之前右1的匹配对象左1分配另一个对象。
(黄色表示这条边被临时拆掉)

可以与左1匹配的第二个目标是右2,但右2也已经有了匹配对象,怎么办呢?
我们再给之前右2的匹配对象左2分配另一个对象(注意这个步骤和上面是一样的,这是一个递归的过程)。

此时发现左2还能匹配右3,那么之前的问题迎刃而解了,回溯回去。
左2对右3,左1对右2,左3对右1。

所以第三步最后的结果就是:

第四步.
最后是左4,很遗憾,按照第三步的节奏我们没法给左4腾出来一个匹配对象,只能放弃对左4的匹配,匈牙利算法流程至此结束。蓝线就是我们最后的匹配结果。至此我们找到了这个二分图的一个最大匹配。
再次感谢Dark_Scope的分享,我这里只是把其中的例子替换成了多目标跟踪的实际场景便于大家理解。
最终的结果是我们匹配出了三对目标,由于候选的匹配目标中包含了许多错误的匹配红线(边),所以匹配准确率并不高。可见匈牙利算法对红线连接的准确率要求很高,也就是要求我们运动模型、外观模型等部件必须进行较为精准的预测,或者预设较高的阈值,只将置信度较高的边才送入匈牙利算法进行匹配,这样才能得到较好的结果。
匈牙利算法的流程大家看到了,有一个很明显的问题相信大家也发现了,按这个思路找到的最大匹配往往不是我们心中的最优。匈牙利算法将每个匹配对象的地位视为相同,在这个前提下求解最大匹配。这个和我们研究的多目标跟踪问题有些不合,因为每个匹配对象不可能是同等地位的,总有一个真实目标是我们要找的最佳匹配,而这个真实目标应该拥有更高的权重,在此基础上匹配的结果才能更贴近真实情况。
KM算法就能比较好地解决这个问题,我们下面来看看KM算法。
2.KM算法(Kuhn-Munkres Algorithm)
KM算法解决的是带权二分图的最优匹配问题。
还是用上面的图来举例子,这次给每条连接关系加入了权重,也就是我们算法中其他模块给出的置信度分值。

KM算法解决问题的步骤是这样的。
第一步
首先对每个顶点赋值,称为顶标,将左边的顶点赋值为与其相连的边的最大权重,右边的顶点赋值为0。

第二步,开始匹配
匹配的原则是只和权重与左边分数(顶标)相同的边进行匹配,若找不到边匹配,对此条路径的所有左边顶点的顶标减d,所有右边顶点的顶标加d。参数d我们在这里取值为0.1。
对于左1,与顶标分值相同的边先标蓝。
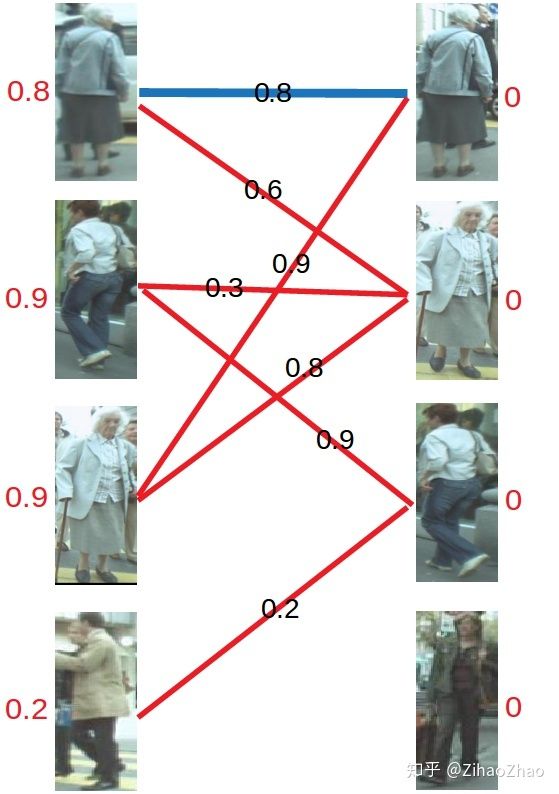
然后是左2,与顶标分值相同的边标蓝。

然后是左3,发现与右1已经与左1配对。首先想到让左3更换匹配对象,然而根据匹配原则,只有权值大于等于0.9+0=0.9(左顶标加右顶标)的边能满足要求。于是左3无法换边。那左1能不能换边呢?对于左1来说,只有权值大于等于0.8+0=0.8的边能满足要求,无法换边。此时根据KM算法,应对所有冲突的边的顶点做加减操作,令左边顶点值减0.1,右边顶点值加0.1。结果如下图所示。

再进行匹配操作,发现左3多了一条可匹配的边,因为此时左3对右2的匹配要求只需权重大于等于0.8+0即可,所以左3与右2匹配!

最后进行左4的匹配,由于左4唯一的匹配对象右3已被左2匹配,发生冲突。进行一轮加减d操作,再匹配,左四还是匹配失败。两轮以后左4期望值降为0,放弃匹配左4。
至此KM算法流程结束,三对目标成功匹配,甚至在左三目标预测不够准确的情况下也进行了正确匹配。可见在引入了权重之后,匹配成功率大大提高。
这篇文章可能信息量有点大,读起来略费脑。不过笔者力求排除复杂的理论推导,使用形象的例子来说明这两种算法。至于具体的理论,有兴趣的读者可以再去搜寻,网上有很多资料,相信有了感性的理解后,对理论的掌握会更加容易。
最后还有一点值得注意,匈牙利算法得到的最大匹配并不是唯一的,预设匹配边、或者匹配顺序不同等,都可能会导致有多种最大匹配情况,所以有一种替代KM算法的想法是,我们只需要用匈牙利算法找到所有的最大匹配,比较每个最大匹配的权重,再选出最大权重的最优匹配即可得到更贴近真实情况的匹配结果。但这种方法时间复杂度较高,会随着目标数越来越多,消耗的时间大大增加,实际使用中并不推荐。
复杂的理论终于结束了,下一篇将是大家喜闻乐见的网络环节,轻松易懂不费脑,感谢大家的关注!
码字仓促,文中若有错误,还请各位不吝指教。欢迎各位在评论区留言,大家互相交流学习。
转载请联系作者并注明出处,侵权必究。