主流部署端深度学习框架
文章目录
- NCNN
-
- 同框架对比
- 支持卷积神经网络,多输入和多分支
- 无任何第三方库依赖
- 纯 C++ 实现,跨平台
- 汇编级优化,计算速度极快
- MNN
-
- 模型
- 优势
-
- 通用性
- 轻量性
- 高性能
- 易用性
- 性能测评
- Paddle lite
-
- 特点
-
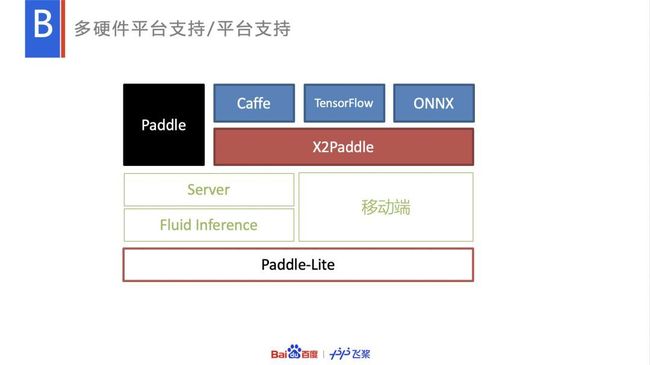
- 多硬件平台支持
- 轻量化部署
- 高性能实现
- 量化计算支持
- 优势
- 边缘端部署
- Mace
-
- 模型架构
- 优化
- Tensorflow Lite
-
- 模型结构
- 转换模型格式
- 部署流程
- 总测评
NCNN
腾讯开源的ncnn 是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部署和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP,将 AI 带到你的指尖。
同框架对比
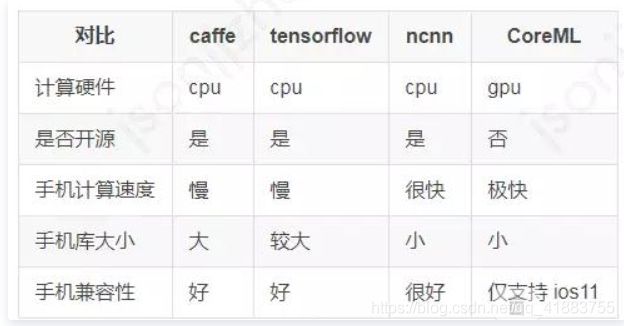
对比目前已知的同类框架,ncnn是CPU框架中最快,安装包体积最小,跨平台兼容性中最好的。CoreML 是苹果主推的 iOS GPU 计算框架,速度非常快,但仅支持 iOS 11 以上的 iphone 手机,落地受众太狭窄,非开源导致开发者无法自主扩展功能,对开源社区不友好。
支持卷积神经网络,多输入和多分支
ncnn 支持卷积神经网络结构,以及多分支多输入的复杂网络结构,如主流的 vgg、googlenet、resnet、squeezenet 等。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZX4Z9Q35-1611899997179)(NCNNMODEL.jpg)]
计算时可以依据需求,先计算公共部分和 prob 分支,待 prob 结果超过阈值后,再计算 bbox 分支。
如果 prob 低于阈值,则可以不计算 bbox 分支,减少计算量。
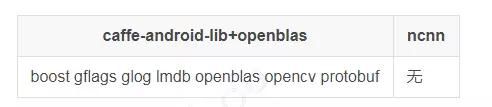
无任何第三方库依赖
ncnn 不依赖任何第三方库,完全独立实现所有计算过程,不需要 BLAS/NNPACK 等数学计算库。
纯 C++ 实现,跨平台
ncnn 代码全部使用 C/C++ 实现,以及跨平台的 cmake 编译系统,可在已知的绝大多数平台编译运行,如 Linux,Windows,MacOS,Android,iOS 等。
由于 ncnn 不依赖第三方库,且采用 C++ 03 标准实现,只用到了 std::vector 和 std::string 两个 STL 模板,可轻松移植到其他系统和设备上。
汇编级优化,计算速度极快
ncnn 为手机端 CPU 运行做了深度细致的优化,使用 ARM NEON 指令集实现卷积层,全连接层,池化层等大部分 CNN 关键层。
对于寄存器压力较大的 armv7 架构,我们手工编写 neon 汇编,内存预对齐,cache 预缓存,排列流水线,充分利用一切硬件资源,防止编译器意外负优化。
测试手机为 Nexus 6p,Android 7.1.2
MNN
AI科学家贾扬清如此评价道:“与 Tensorflow、Caffe2 等同时覆盖训练和推理的通用框架相比,MNN 更注重在推理时的加速和优化,解决在模型部署的阶段的效率问题,从而在移动端更高效地实现模型背后的业务。这和服务器端 TensorRT 等推理引擎的想法不谋而合。在大规模机器学习应用中,考虑到大规模的模型部署,机器学习的推理侧计算量往往是训练侧计算量的十倍以上,所以推理侧的优化尤其重要。”
模型
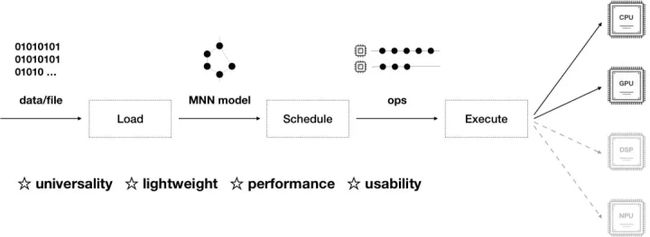

如上图所示,MNN 可以分为 Converter 和 Interpreter 两部分。
Converter 由 Frontends 和 Graph Optimize 构成。前者负责支持不同的训练框架,MNN 当前支持 Tensorflow(Lite)、Caffe 和 ONNX;后者通过算子融合、算子替代、布局调整等方式优化图。
Interpreter 由 Engine 和 Backends 构成。前者负责模型的加载、计算图的调度;后者包含各计算设备下的内存分配、Op 实现。在 Engine 和 Backends 中,MNN应用了多种优化方案,包括在卷积和反卷积中应用 Winograd 算法、在矩阵乘法中应用 Strassen 算法、低精度计算、Neon 优化、手写汇编、多线程优化、内存复用、异构计算等。
优势
通用性
- 支持 Tensorflow、Caffe、ONNX 等主流模型格式,支持 CNN、RNN、GAN 等常用网络;
- 支持 86 个 TensorflowOp、34 个 CaffeOp ;各计算设备支持的 MNN Op 数:CPU 71 个,Metal 55 个,OpenCL 40 个,Vulkan 35 个;
- 支持 iOS 8.0+、Android 4.3+ 和具有POSIX接口的嵌入式设备;
- 支持异构设备混合计算,目前支持 CPU 和 GPU,可以动态导入 GPU Op 插件,替代 CPU Op 的实现;
轻量性
- 针对端侧设备特点深度定制和裁剪,无任何依赖,可以方便地部署到移动设备和各种嵌入式设备中;
- iOS 平台上,armv7+arm64 静态库大小 5MB 左右,链接生成可执行文件增加大小 620KB 左右,metallib 文件 600KB 左右;
- Android 平台上,so 大小 400KB 左右,OpenCL 库 400KB 左右,Vulkan 库 400KB 左右;
高性能
- 不依赖任何第三方计算库,依靠大量手写汇编实现核心运算,充分发挥 ARM CPU 的算力;
- iOS 设备上可以开启 GPU 加速(Metal),支持iOS 8.0以上版本,常用模型上快于苹果原生的 CoreML;
- Android 上提供了 OpenCL、Vulkan、OpenGL 三套方案,尽可能多地满足设备需求,针对主流 GPU(Adreno和Mali)做了深度调优;
- 卷积、转置卷积算法高效稳定,对于任意形状的卷积均能高效运行,广泛运用了 Winograd 卷积算法,对 3x3 -> 7x7 之类的对称卷积有高效的实现;
- 针对 ARM v8.2 的新架构额外作了优化,新设备可利用半精度计算的特性进一步提速;
易用性
- 完善的文档和实例;
- 有高效的图像处理模块,覆盖常见的形变、转换等需求,一般情况下,无需额外引入 libyuv 或 opencv 库处理图像;
- 支持回调机制,方便提取数据或者控制运行走向;
- 支持运行网络模型中的部分路径,或者指定 CPU 和 GPU 间并行运行;
性能测评
采用业务常用的 MobileNet、SqueezeNet 和主流开源框架进行比较,结果如下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zRW31KIT-1611899997217)(mnn.jpg)]
MNN 相比于 NCNN、Mace、Tensorflow Lite、Caffe2 都有 20% 以上的优势。我们其实更加聚焦在内部使用的业务模型优化上,针对人脸检测等模型进行深入优化,iPhone6 可以达到单帧检测 5ms 左右。
注:Mace、Tensorflow Lite、Caffe2 均使用截止 2019 年 3 月 1 日 GitHub 代码仓库的 master 分支;NCNN 由于编译问题采用 20181228 Release 预编译库。
Paddle lite
特点
Paddle Lite 支持如下特性:
多硬件平台支持
目前支持如下 7 种硬件:ARM CPU V7、V8、Mali GPU, Adreno GPU, Metal GPU、Huawei NPU、FPGA
轻量化部署
完善的多硬件平台支持必须至少有如下支持,比如完整的各类硬件后端支持,多份硬件相关算子的实现,计算图详尽的分析和优化能力。这些能力的支持必然带来最终部署库的体积膨胀,难以轻量化部署。
Paddle Lite 针对这个问题,在架构上做了相应的设计:
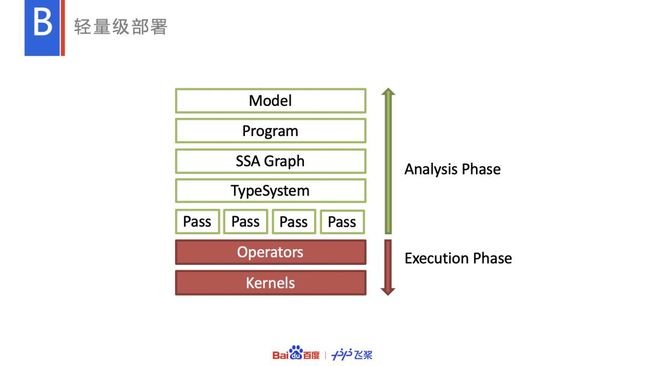
在具体架构上,由模型加载执行的顺序,严格拆分为分析和执行两个阶段。分析阶段有完整的计算图分析优化的能力(比如算子融合,内存优化等),由于策略较多,体积较大;执行阶段只包含相关算子,功能简单,但体积很小。
在体积敏感的场景下,Paddle Lite 可以选择轻量化部署方案,即可以只部署执行阶段,而复杂的分析优化则封装到了离线工具中。当然,在体积不敏感的场景下,比如服务器端推理,Paddle Lite 也支持两个阶段合并在一起部署,以支持一些预测前需要针对具体硬件和上下文信息调整动态图优化的能力。
Paddle Lite 核心库(ARM V8)是 1.4M,在主流实现中较有优势。
高性能实现
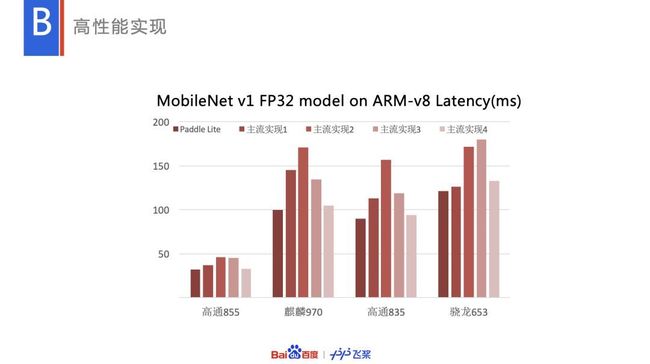
Paddle Lite 的实现也是比较有优势的,比如在端侧推理非常主流的硬件 ARM CPU 上,MobileNet V1 的性能如上,也是比较有优势的。
量化计算支持
量化计算是神经网络计算的趋势。神经网络有信息冗余的特点,即使使用低精度计算也能保证效果,基于这个优点,各硬件平台都通过量化计算来提供更快,功耗体积更有优势的硬件。Paddle Lite 在这方面也有很好的支持。

优势
- 更易用的API,更好的封装,更快速的业务集成;
- 占用内存小,速度快,因为Paddle在百度内部也服务了众多大并发大数据场景,工业经验也很丰富;
- 本土化支持,也是唯一有官方中文文档的深度学习框架;
- 在自然语言处理上有很多现成的应用,比如情感分类,神经机器翻译,阅读理解、自动问答等,使用起来相对简单;
- PaddlePaddle支持多机多卡训练,并且本身支持多种集群方式
边缘端部署
-
Paddle Lite 支持 Fpga 硬件原理:
Paddle Lite 完整支持从 Mobile 到 Server 多种硬件,这主要得益于对不同硬件的统一抽象,不同的硬件提供统一的接口给上层框架,形成了硬件的可插拔,极大方便了底层硬件的扩展与支持。Fpga 作为 Paddle Lite 的 Backends 之一,将自身硬件相关的 kernel、驱动及内核进行了包装并向 Paddle Lite 提供了统一的 op 调用接口,使得 Paddle Lite 能很方便的集成 Fpga 的计算能力。同时通过 Paddle Lite 上层框架对模型的优化能力,包括各种 op 融合、计算剪枝、存储复用、量化融合的优化 pass, 以及 kernel 的最优调度、混合布署等功能,进一步实现了模型加速。
-
EdgeBoard 模型布署
利用 Paddle Lite 在 EdgeBoard 上进行模型布署很简单,只需将 include 下头文件包含到调用 Paddle Lite 的代码文件中,将静态库文件与工程文件联编成可执行程序,替换模型即可运行。训练模型效果对比:
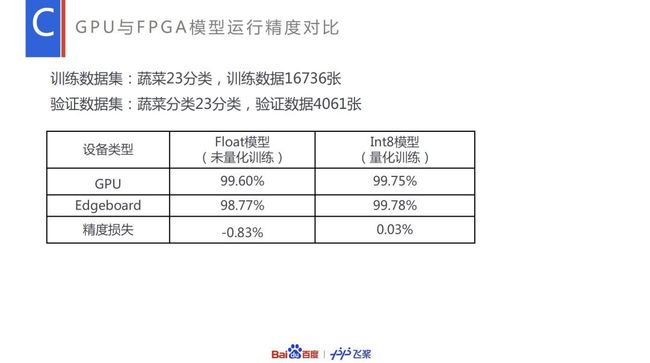
利用 Paddle Lite 推理引擎在 EdgeBoard 计算卡上布署 Inceptionv4 蔬菜识别模型,实现了边缘端智能识别蔬菜品类的功能,可用于多种场景。整个应用借助 Paddle Lite 的上层框架优化能力与 Fpga 的底层计算加速能力,每秒可识别 30 帧,真正实现实时高效的蔬菜识别。
Mace
模型架构

对于深度学习框架,尤其是推理框架,最核心的部分是高性能的kernel实现。MACE的NEON, GPU的kernel实现均达到较高水平,同时对于Hexagon DSP也进行了支持和优化。
目前,MACE支持主流的CNN模型,同时也支持机器翻译、语音识别的部分模型。除此之外,与MACE一同开源的,还有MACE Model Zoo项目(https://github.com/XiaoMi/mace-models),这个项目聚合了了一些常用的深度学习模型。
何亮亮介绍道,MACE的核心框架是C++,算子分别设计为OpenCL和汇编语言,具体选择哪个取决于底层的硬件,而周边工具则采用了更灵活的Python。
目前,MACE还无法做到在安卓和苹果系统之间自由切换,只支持安卓和Linux。MACE提供了丰富的文档和Model Zoo,让开发者可以快速入手,且兼容主流的ARM CPU和常见的移动端GPU,开发者可以灵活地选择不同的CPU/GPU/DSP计算设备
优化
-
性能
-
- 代码经过NEON指令,OpenCL以及Hexagon HVX专门优化,并且采用 Winograd算法来进行卷积操作的加速。 此外,还对启动速度进行了专门的优化。
-
功耗
-
- 支持芯片的功耗管理,例如ARM的big.LITTLE调度,以及高通Adreno GPU功耗选项。
-
系统响应
-
- 支持自动拆解长时间的OpenCL计算任务,来保证UI渲染任务能够做到较好的抢占调度, 从而保证系统UI的相应和用户体验。
-
内存占用
-
- 通过运用内存依赖分析技术,以及内存复用,减少内存的占用。另外,保持尽量少的外部 依赖,保证代码尺寸精简。
-
模型加密与保护
-
- 模型保护是重要设计目标之一。支持将模型转换成C++代码,以及关键常量字符混淆,增加逆向的难度。
-
硬件支持范围
-
- 支持高通,联发科,以及松果等系列芯片的CPU,GPU与DSP(目前仅支持Hexagon)计算加速。 同时支持在具有POSIX接口的系统的CPU上运行。
Tensorflow Lite
模型结构
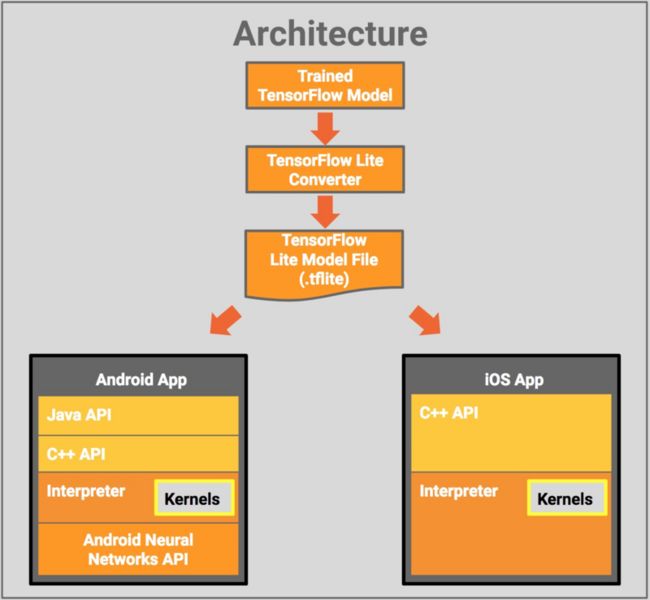
Tensorflow Lite模型的数据格式与Tensorflow桌面端不同,需要使用Tensorflow Lite转换为.tflite格式,然后应用到移动端。
模型结构:
- java-API:包装C++API,以便在android上使用java调用
- C+±API:加载Tensorflow Lite模型和解释器
- 解释器:执行模型一系列核心操作,支持选择内核加载。全部加载300kb,不加载只有100kb
- 在android8.1以上设备,可通过相关api进行硬件加速(硬件支持的情况下),否则在CPU执行
转换模型格式
Tensorflow Lite转换器支持以下格式:
- 使用python API执行SavedModel保存的模型文件
- tf.keras保存的.h5模型文件
- 转换后的GraphDef文件
部署流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-H29bcC0P-1611899997251)(https://www.mouser.com/images/microsites/tensorflow-mcu-ai-edge-fig2.jpg)]
根据TensorFlow Lite for Microcontrollers的附带文档,开发人员的工作流程可以分为五个关键步骤(图), 具体如下:
| 1. | **创建或获取一个TensorFlow模型:**该模型必须足够小,以便在转换后适合目标设备,并且它只能使用支持的运算。如果要使用当前不支持的运算,可以提供自定义实现。 |
|---|---|
| 2. | 将模型转换为TensorFlow Lite FlatBuffer:您将使用TensorFlow Lite转换器将模型转换为标准TensorFlow Lite格式。您可能希望输出一个量化模型,因为这种模型的尺寸更小,执行效率更高。 |
| 3. | **将FlatBuffer转换为C字节数组:**模型保存在只读程序内存中,并以简单的C文件形式提供。可以使用标准工具将FlatBuffer转换为C字节数组。 |
| 4. | **集成TensorFlow Lite for Microcontrollers C++库:**编写微控制器代码来收集数据,使用C++库执行推理,然后使用结果。 |
| 5. | **部署到设备:**编写程序并将其部署到您的设备。 |
在选择与TensorFlow Lite库一起使用的兼容嵌入式平台时,开发人员应注意以下几点:
| 1. | 基于32位架构(如Arm Cortex-M处理器)和ESP32的系统。 |
|---|---|
| 2. | 它可以运行在内存大小达数十KB的系统上。 |
| 3. | TensorFlow Lite for Microcontrollers是用C++ 11编写的。 |
| 4. | TensorFlow Lite for Microcontrollers可作为Arduino库提供。该框架还可以为其他开发环境(如Mbed)生成项目。 |
| 5. | 不需要操作系统支持、动态内存分配或任何C/C++标准库。 |
Google提供四个事先训练好的模型作为示例,可用于在嵌入式平台上运行。只需稍做修改,就能在各种开发板上使用。这些示例包括:
| 1. Hello World: | 演示使用TensorFlow Lite for Microcontrollers的必备基础知识 |
|---|---|
| 2.Micro-Speech: | 用麦克风捕捉音频以检测单词“yes”和“no”。 |
| 3.Person Deflection: | 用图像传感器捕捉摄像头数据,以检测是否有人。 |
| 4.Magic Wand: | 捕获加速度计数据以对三种不同的手势进行分类。 |
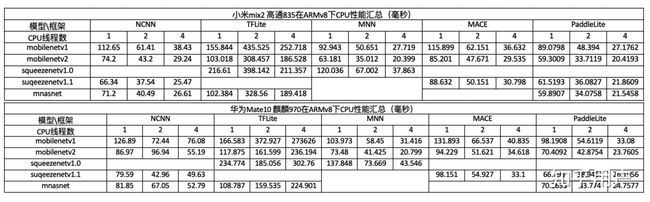
总测评
总体结论: paddle-lite>mnn>ncnn>MACE>TFLite
- CPU单线程性能比较(从快到慢):PaddleLite > MNN > NCNN > MACE > TFLite;
- CPU2线程性能比较(从快到慢):PaddleLite ≥ MNN > NCNN > MACE > TFLite;
- CPU4线程性能比较(从快到慢):MNN ≥ PaddleLite > NCNN > MACE > TFLite;
PC端: ncnn 分支d2bf77c, 20200624, 平台 Mac ,CPU Intel Core [email protected],注意ncnnx86实现仅为了验证结果正确性,没有针对性优化,所以性能并不会太好,但也比原始的caffe要好不少。