Back Pressure是流处理系统中,非常经典常见的问题,它是让流系统能对压力变化能够呈现良好抗压性的关键所在
各个开源实时处理系统,在中后期,都开始有对背压机制有完善的考虑和设计,基本原理一致。实现方式各有千秋。
举例Spark Streaming
这句话怎么理解???
首先,服务中心的服务能力是有限的,要处理的事件时多时少,资源浪费?资源不够?
在系统架构设计中,要思考2个问题:
1、服务中心要抗住峰值事件(max问题)
2、这些事件如何有效被服务中心分配消费(match问题)
常用经典的排队理论,可以解决max问题,服务中心不会被压垮,
为了服务中心能正常服务,就需要多维护一个队列
- 原来只维护一个东西,就是服务中心
- 现在维护两东西,一个服务中心,一个队列
体现这种设计理念的经典设计模式之一(理论=> 模式),生产者-消费者模式
但match问题没解决,根本目的:
你事件多,我给资源多,处理能力够
你事件少,我给资源少,处理能力够
总结一句话就是 合适最重要
为了解决match问题,业界提出Reactive Stream的设计模式,生产者-消费者模式 + 迭代器
消费者告诉生产者消费数量,服务中心每个机器能吃多少饭,都是已知的,如果量大,吃不下,Spark就会动态调节(动态Executor模型),但怎么个调法?这个时候背压的概念和设计就出来了
背压就是背能背的起压力,从input到output,上游总给下游可承受的量,难点就是上游要知道下游能背多少???
SparkStreaming
基于SparkCore提供micro-batch处理的实时流式处理框架,就是批处理的批是很小的一批,
这个小批叫DStream(数据流 -> 转成DStream -> RDD机制处理)
SparkCore = Driver + Executor
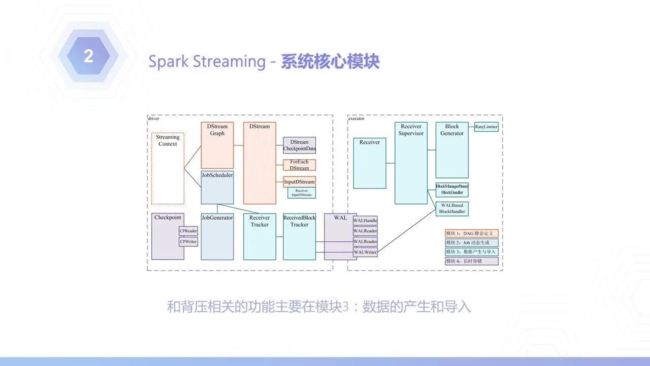
上图是SparkStreaming的系统核心模块,和背压特性相关的,主要是模块3:数据的产生和导入。

基于前面的排队理论,Spark Streaming每一批次的处理时长(batch_process_time)需要小于批次间隔batch_interval,否则batch_process_time > batch_interval,程序的处理能力不足,积累的数据越来越多,最终会造成Executor的OOM。
Spark Steaming从1.5版本开始,开始引入背压机制,第一个相关问题是经典的SPARK-7398。其大体的思路是:
通过在Driver端进行速率估算,并将速率更新到Executor端的各个Receiver,从而实现背压
1、速率控制
2、速率估算
3、速率更新
- 速率控制
整个背压机制的核心,就是Drvier端的RateContoller,它作为控制核心,继承自StreamingListener,监听Batch的完成情况,记录下它们的关键延迟,然后传递给computeAndPublish方法,遍历Executor并进行估算和更新
- 速率估算
PIDRateEstimator是目前RateEstimator的唯一官方实现,基本上也没谁去重新实现一个,因为确实好用。PID(Proportional Integral Derivative,比例积分差分控制算法)是工控领域中,经过多次的验证是一种非常有效的工业控制器算法。Spark Streaming将它引入,作为根据最新的Rate,以及比例(Proportional) 积分(Integral)微分(Derivative)这3个变量,来确定最新的Rate,实现简洁明了,也非常好理解。
- 速率更新
计算完新Rate,就该把它发布出去了。RateController通过ReceiverTracker,利用RPC消息,发布Rate到Receiver所在的节点上,该节点上的ReceiverSupervisorImpl会接收消息,并把速率更新到BlockGenerator上,从而以控制每个批次的数据生成。
仔细阅读这两个类的代码,可以发现它们充分利用了Scala的特性和高性能网络通信库,非常的简洁,一点都不拖泥带水。无论是发送端的UpdateRateLimit的case class消息类构建,还是接收端的receive的偏函数特性,都充分的体现了Scala的代码之美。
参考资料
xxx