
Explain是我们平时使用最多的MySQL优化关键字了,了解它的使用是掌握MySQL优化的基础。当在查询语句前加上Explain关键字,MySQL会展示引擎优化后的sql执行计划,除此之外,还可以在Explain后面加上Extended关键字,它可以提供额外的一些信息,我们可以通过执行计划来优化sql的执行效率。
先来看个例子,我们执行一条简单的sql来看一下Explain的输出。
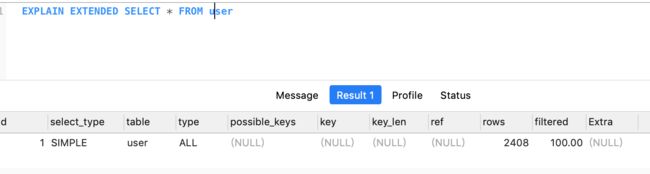
MySQL给我们返回了一个表格,了解每列所代表的含义是我们优化SQL的前提。让我们分别来介绍一下。
id
代表着查询的序列号。这个序列号代表着语句执行的顺序。id相同执行顺序从上到下;id不同id值越大,优先级越高,越先被执行。
select_type
在说它之前,先来了解一下MySQL的表连接算法,下面会用到,MySQL对于表连接使用nested-loop方法,该算法表示MySQL将会在第一个表中读取一条数据,然后在第二个表、第三个表等寻找匹配的记录。当所有的表都被处理,MySQL再从第一个表继续读取下一行,如此循环。类似于嵌套for循环。
foreach rowin t1 matching range {
foreach rowin t2 matching reference key {
foreach rowin t3 {
if row satisfies join conditions,
send to client
}
}
}
说回来,该列代表着查询类型,它的值有很多,这里挑几个重要的来讲。
SIMPLE:简单查询,不包含子查询与union操作
PEIMARY:主查询,即上面我们说的nested-loop最外层的for循环
UNION:SQL中含有union查询时nested-loop的内层循环
UNION RESULT:union的结果集
SUBQUERY:子查询中的第一个查询
DERIVED:查询产生的派生表
table
这个比较直接,代表着查询使用的表名
type
这一列比较重要,这一列的值代表着SQL的执行效率的好坏,我们把常见的结果值排个序,从好到坏依次是
system:表只有一行或者查询的是系统表
const:最多有一行匹配,通常在主键精确匹配时type会为该类型,例如SELECT * FROM tbl_name WHERE primary_key=1
eq_ref:唯一性索引扫描。当连接使用索引的所有部分并且索引是PRIMARY KEY或UNIQUE NOT NULL索引时使用它,例如SELECT * FROM ref_table,other_table WHERE ref_table.key_column=other_table.column;
ref:非唯一性索引扫描。ref可用于使用=或<=>运算符进行比较的索引列。例如SELECT * FROM ref_table WHERE key_column=expr
ref_or_null:类似于ref,但是MySQL对于为空值的列做了额外的搜索,常见于解析子查询,例如SELECT * FROM ref_table WHERE key_column=expr OR key_column IS NULL
range:使用索引检索指定范围内的数据
index:会扫描整个索引树
ALL:全表扫描
一般来说我们要保证大表得查询至少要达到range级别,最好达到ref
possible_keys
指出查询可能使用的索引,注意并不是真正使用的索引
key
查询真正使用的索引。查询中若使用了覆盖索引(select 后要查询的字段刚好和创建的索引字段完全相同),则该索引仅出现在key列表中 (意味着possible_keys为null)
key_len
查询使用的索引的长度
ref
显示索引的被使用列(联合索引)
rows
MySQL预计会检索的行数
filtered
按条件筛选行数的百分比
Extra
包含MySQL解析查询的一些额外信息,该列可能的值有太多,不一一介绍,只说几个比较重要的。
Using filesort:order by关键字使用了文件排序,即在无索引的列上进行排序,出现它意味着可能需要进行SQL优化
Using temporary :为满足查询需要创建临时表,同上
Using index:表示查询使用了覆盖索引,避免访问了表的数据行,效率还可以。
一些小tips
优化SQL时都需要查看执行计划,然后对SQL进行改写,直到得到满意的type。
这里写几个基本的查询时需要注意的地方,帮助大家少走弯路。
1.关联查询时关联列长度与类型要相同,例如一个为char(10)一个为char(15)则不能使用索引
2.如果order by和group by列名不同或者来自不同的表那么将会产生临时表
3.join语句,小表驱动大表,即小表在join前,大表在join后。
4.索引最佳左前缀原则:若索引了多列,则查询时从索引最左列开始是可以使用索引的。举个例子,比如有index_a_b_c,abc三列的联合索引,查询时 条件= a,条件= ab,条件= abc均可使用索引,而条件=bc或ac则无法使用索引,总结一句话“带头大哥不能丢,中间兄弟不能断”(这是BTree索引的实现上导致的,具体见我的另一篇文章MySQL中的几种索引介绍)
5.不能在索引列上做函数计算,类型转换等操作,会导致索引失效
6.尽量使用覆盖索引,少使用select *
7.like以通配符“%”开头将无法使用索引
8.关于exists与in:
select from a where exists(select from b where a.id=b.id )先执行外查询
select from a where a.id in (select from b),先执行内查询
由上面的nested-loop表连接算法可以得到如下结论,a表比b表大用in,a比b小用exists。
9.not in与not exists使用not exists,因为后者会使用索引。
10、尽量使用覆盖索引而非二级索引,二级索引会回表
11、对于select where x = aa group by y,不要分别对x和y建立索引,而是建立xy联合索引
Join 查询总结
接下来给大家一张福利图,SQL中所有的join情形都可以在这张图里体现,一图在手,天下我有!
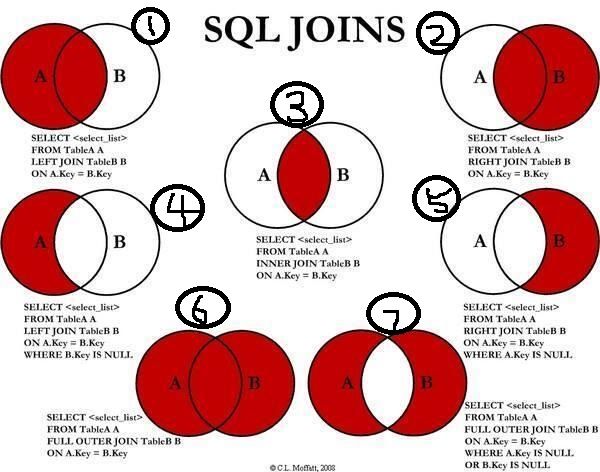
注:由于mysql不支持full join,所以第6条和7条查询需要改写
6改写后: 1+union+2 (注:union自带去重)
7改写后: 4+union+5
最后
SQL的改写其实是很难的一件事情(自己总被diss SQL性能差),能够进行简单的索引优化只是基础,了解官方文档是熟练掌握SQL改写的前提,所以呢有时间啃啃文档是极好的MySQL5.7官方文档。
希望大家都能在实践中不断进步,写出不被DBA diss的SQL!!!