正点原子IMX6ULL阿尔法USB摄像头的远程调用(六)配带口罩检测制作
上一次把前期都作完了,下面可以开始制作了。。。。先来看看源码吧。。。。
检测算法源码初探
打开opencv_dnn_infer.py文件,我们可以初步看一下程序是如何执行的。。。
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Face Mask Detection")
parser.add_argument('--proto', type=str, default='models/face_mask_detection.prototxt', help='prototxt path')
parser.add_argument('--model', type=str, default='models/face_mask_detection.caffemodel', help='model path')
parser.add_argument('--img-mode', type=int, default=0, help='set 1 to run on image, 0 to run on video.')
parser.add_argument('--img-path', type=str, default='img/demo2.jpg', help='path to your image.')
parser.add_argument('--video-path', type=str, default='0', help='path to your video, `0` means to use camera.')
# parser.add_argument('--hdf5', type=str, help='keras hdf5 file')
args = parser.parse_args()
Net = cv2.dnn.readNet(args.model, args.proto)
if args.img_mode:
img = cv2.imread(args.img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
result = inference(Net, img, target_shape=(260, 260))
cv2.namedWindow('detect', cv2.WINDOW_NORMAL)
cv2.imshow('detect', result[:,:,::-1])
cv2.waitKey(0)
cv2.destroyAllWindows()
else:
video_path = args.video_path
if args.video_path == '0':
video_path = 0
run_on_video(Net, video_path, conf_thresh=0.5)
在opencv_dnn_infer.py主程序中,我们可以分析一下:
在第3行和第4行,是检测算法模型文件所存放的地址,这两个文件需要传送给第11行的Net = cv2.dnn.readNet(args.model, args.proto),其中args.model的地址为’models/face_mask_detection.caffemodel’,而args.proto的地址为’models/face_mask_detection.prototxt’,
第5行是为img-mode参数进行赋值,img-mode可以有两个参数,一个是1,进行图片识别,另一个是0,进行摄像头或视频识别,这个参数在程序执行时是在命令行进行输入的,在下面这句命令中加粗斜体部分就是为img-mode进行赋值:
python opencv_dnn_infer.py –img-mode 1 --img-path /path/to/your/img ,命令行中所赋的值传入程序中进行执行。。。。
第6行是为img-path参数进行赋值,img-path也是从命令行传入的,可以从上面命令的最后一部分找到,如果不输入的话,默认调用同级目录下’img/demo2.jpg’图片。。。
第7行是为video-path参数进行赋值,video-path也是从命令行传入,例如把img-path换成video-path就可以,如果输入0,表示调取摄像头,如果调取视频,则输入相应的路径就可以了。。。
下面的if…else语句,用img_mode来区分图片识别,还是视频摄像头识别。。。
摄像头远程调用界面设计
如下图所示。
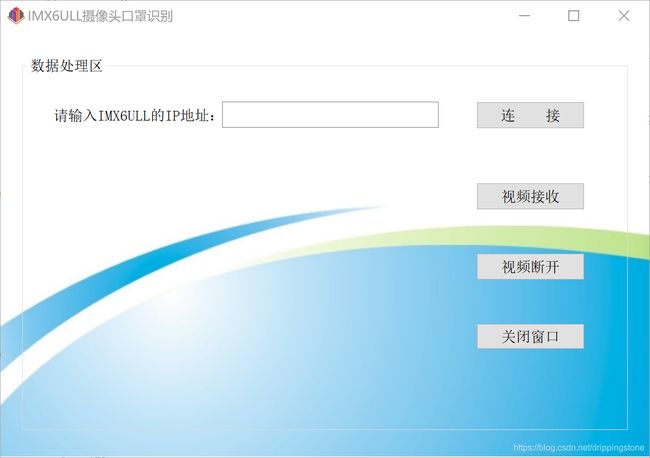
界面超简单,有四个按钮,和几个Label控件,源码中都定义了,不再赘述。。。。执行时如下图。。。。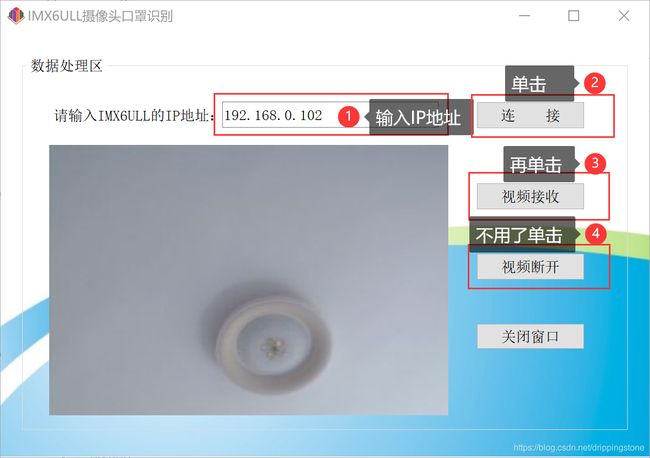
本例程源码
# -*- coding: utf-8 -*-
# Form implementation generated from reading ui file 'F:\源代码\video.ui'
#
# Created by: PyQt5 UI code generator 5.11.3
#
# WARNING! All changes made in this file will be lost!
from PyQt5 import QtCore, QtGui, QtWidgets
from PyQt5.QtGui import QIcon, QPixmap, QPainter, QPen
from PyQt5.QtWidgets import *
import threading
from threading import *
import sys
import cv2
import requests
import numpy as np
from PyQt5.Qt import Qt
import time
import argparse
from utils.anchor_generator import generate_anchors
from utils.anchor_decode import decode_bbox
from utils.nms import single_class_non_max_suppression
from PIL import Image, ImageDraw, ImageFont
from TypeConversion import *
feature_map_sizes = [[33, 33], [17, 17], [9, 9], [5, 5], [3, 3]]
anchor_sizes = [[0.04, 0.056], [0.08, 0.11], [0.16, 0.22], [0.32, 0.45], [0.64, 0.72]]
anchor_ratios = [[1, 0.62, 0.42]] * 5
# generate anchors
anchors = generate_anchors(feature_map_sizes, anchor_sizes, anchor_ratios)
# for inference , the batch size is 1, the model output shape is [1, N, 4],
# so we expand dim for anchors to [1, anchor_num, 4]
anchors_exp = np.expand_dims(anchors, axis=0)
id2class = {
0: 'Mask', 1: 'NoMask'}
id2chiclass = {
0: '您戴了口罩', 1: '您没有戴口罩'}
id3chiclass = {
0: '口罩OK', 1: '口罩NO'}
colors = ((0, 255, 0), (255, 0 , 0))
class Ui_video(object):
def setupUi(self, video):
video.setObjectName("video")
video.resize(1200, 788)
self.label = QtWidgets.QLabel(video)
self.label.setGeometry(QtCore.QRect(0, -2, 1200, 788))
self.label.setText("")
self.label.setObjectName("label")
pixmap = QPixmap('2.png')
self.label.setPixmap(pixmap)
self.label.setScaledContents (True)
self.groupBox = QtWidgets.QGroupBox(video)
self.groupBox.setGeometry(QtCore.QRect(40, 50, 1120, 688))
font = QtGui.QFont()
font.setPointSize(10)
self.groupBox.setFont(font)
self.groupBox.setObjectName("groupBox")
self.pushButton = QtWidgets.QPushButton(self.groupBox)
self.pushButton.setGeometry(QtCore.QRect(840, 490, 200, 48))
font = QtGui.QFont()
font.setPointSize(10)
self.pushButton.setFont(font)
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(self.groupBox)
self.pushButton_2.setGeometry(QtCore.QRect(840, 230, 200, 50))
self.pushButton_2.setObjectName("pushButton_2")
self.pushButton_4 = QtWidgets.QPushButton(self.groupBox)
self.pushButton_4.setGeometry(QtCore.QRect(840, 360, 200, 50))
self.pushButton_4.setObjectName("pushButton_4")
self.label_2 = QtWidgets.QLabel(self.groupBox)
self.label_2.setGeometry(QtCore.QRect(58, 80, 300, 50))
self.label_2.setObjectName("label_2")
self.lineEdit = QtWidgets.QLineEdit(self.groupBox)
self.lineEdit.setGeometry(QtCore.QRect(370, 80, 400, 48))
self.lineEdit.setObjectName("lineEdit")
self.pushButton_5 = QtWidgets.QPushButton(self.groupBox)
self.pushButton_5.setGeometry(QtCore.QRect(840, 80, 200, 50))
self.pushButton_5.setObjectName("pushButton_5")
self.label_3 = QtWidgets.QLabel(self.groupBox)
self.label_3.setGeometry(QtCore.QRect(50, 160, 738, 500))
self.label_3.setText("")
self.label_3.setObjectName("label_3")
self.xmin = 0
self.ymin = 0
self.xmax = 0
self.ymax = 0
self.class_id = "3"
self.Video1 = " "
self.retranslateUi(video)
self.pushButton.clicked.connect(self.pushButtonClick)
self.pushButton_2.clicked.connect(self.pushButton_2Click)
self.pushButton_4.clicked.connect(self.pushButton_4Click)
self.pushButton_5.clicked.connect(self.pushButton_5Click)
self.status = True
QtCore.QMetaObject.connectSlotsByName(video)
def retranslateUi(self, video):
_translate = QtCore.QCoreApplication.translate
video.setWindowTitle(_translate("video", "IMX6ULL摄像头口罩识别"))
video.setWindowIcon(QIcon('1.png'))
self.groupBox.setTitle(_translate("video", "数据处理区"))
self.pushButton_2.setText(_translate("video", "视频接收"))
self.pushButton_4.setText(_translate("video", "视频断开"))
self.label_2.setText(_translate("video", "请输入IMX6ULL的IP地址:"))
self.pushButton_5.setText(_translate("video", "连 接"))
self.pushButton.setText(_translate("video", "关闭窗口"))
def puttext_chinese(self,img, text, point, color):
pilimg = Image.fromarray(img)
draw = ImageDraw.Draw(pilimg) # 图片上打印汉字
fontsize = int(min(img.shape[:2])*0.04)
font = ImageFont.truetype("simhei.ttf", fontsize, encoding="utf-8")
y = point[1]-font.getsize(text)[1]
if y <= font.getsize(text)[1]:
y = point[1]+font.getsize(text)[1]
draw.text((point[0], y), text, color, font=font)
img = np.asarray(pilimg)
return img
def getOutputsNames(self,net):
# Get the names of all the layers in the network
layersNames = net.getLayerNames()
# Get the names of the output layers, i.e. the layers with unconnected outputs
return [layersNames[i[0] - 1] for i in net.getUnconnectedOutLayers()]
def inference(self,net, image, conf_thresh=0.5, iou_thresh=0.4, target_shape=(160, 160), draw_result=True, chinese=True):
height, width, _ = image.shape
blob = cv2.dnn.blobFromImage(image, scalefactor=1/255.0, size=target_shape)
net.setInput(blob)
y_bboxes_output, y_cls_output = net.forward(self.getOutputsNames(net))
# remove the batch dimension, for batch is always 1 for inference.
y_bboxes = decode_bbox(anchors_exp, y_bboxes_output)[0]
y_cls = y_cls_output[0]
# To speed up, do single class NMS, not multiple classes NMS.
bbox_max_scores = np.max(y_cls, axis=1)
bbox_max_score_classes = np.argmax(y_cls, axis=1)
# keep_idx is the alive bounding box after nms.
keep_idxs = single_class_non_max_suppression(y_bboxes, bbox_max_scores, conf_thresh=conf_thresh, iou_thresh=iou_thresh)
# keep_idxs = cv2.dnn.NMSBoxes(y_bboxes.tolist(), bbox_max_scores.tolist(), conf_thresh, iou_thresh)[:,0]
tl = round(0.002 * (height + width) * 0.5) + 1 # line thickness
for idx in keep_idxs:
conf = float(bbox_max_scores[idx])
class_id = bbox_max_score_classes[idx]
bbox = y_bboxes[idx]
# clip the coordinate, avoid the value exceed the image boundary.
xmin = max(0, int(bbox[0] * width))
ymin = max(0, int(bbox[1] * height))
xmax = min(int(bbox[2] * width), width)
ymax = min(int(bbox[3] * height), height)
if draw_result:
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), colors[class_id], thickness=tl)
if chinese:
image = self.puttext_chinese(image, id2chiclass[class_id], (xmin, ymin), colors[class_id]) ###puttext_chinese
else:
cv2.putText(image, "%s: %.2f" % (id2class[class_id], conf), (xmin + 2, ymin - 2),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, colors[class_id])
return image
def run_on_video0(self,Net,conf_thresh=0.5):
tt="Facemaskdetect"
Video1=self.Video1
print(Video1)
self.status = True
while self.status:
url1 = 'http://' + Video1 + ':8080/?action=snapshot'
req = requests.get(url1).content
print('222')
pix = QPixmap()
pix.loadFromData(req)
image = np.asarray(bytearray(req), dtype="uint8")
img = cv2.imdecode(image, cv2.IMREAD_COLOR)
img_raw = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_raw = self.inference(Net, img_raw, target_shape=(260, 260), conf_thresh=conf_thresh)
cv2.namedWindow(tt, cv2.WINDOW_NORMAL)
cv2.moveWindow(tt,568,248)
cv2.imshow(tt, img_raw[:,:,::-1])
cv2.waitKey(1)
cv2.destroyAllWindows()
def run_on_video1(self,Net,conf_thresh=0.5):
Video1=self.Video1
print(Video1)
self.status = True
while self.status:
url1 = 'http://' + Video1 + ':8080/?action=snapshot'
req = requests.get(url1).content
print('333')
pix = QPixmap()
pix.loadFromData(req)
image = np.asarray(bytearray(req), dtype="uint8")
img = cv2.imdecode(image, cv2.IMREAD_COLOR)
img_raw = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_raw = self.inference(Net, img_raw, target_shape=(260, 260), conf_thresh=conf_thresh)
img_raw = cv2.cvtColor(img_raw, cv2.COLOR_RGB2BGR)
img=opencv2pixmap(img_raw)
self.label_3.setPixmap(img)
self.label_3.setScaledContents(True)
cv2.waitKey(1)
cv2.destroyAllWindows()
def pushButtonClick(self):
video.close()
def pushButton_2Click(self):
model='models/face_mask_detection.prototxt'
proto='models/face_mask_detection.caffemodel'
Net = cv2.dnn.readNet(model, proto)
video_path = 0
#self.run_on_video0(Net, conf_thresh=0.5)
self.run_on_video1(Net, conf_thresh=0.5)
def pushButton_4Click(self):
self.status = False
def pushButton_5Click(self):
self.Video1=self.lineEdit.text()
if len(self.Video1)==0:
QtWidgets.QMessageBox.information(video, "信息提示", "视频IP不能为空!")
else:
self.flag=0
QtWidgets.QMessageBox.information(video, "信息提示", "连接成功,可以正常操作。")
if __name__ == "__main__":
import sys
app = QtWidgets.QApplication(sys.argv)
video = QtWidgets.QWidget()
ui = Ui_video()
ui.setupUi(video)
video.show()
sys.exit(app.exec_())
源码简单分析
在这里我们重点看一下视频接收按钮,下面是视频接收按钮的源码:
def pushButton_2Click(self):
model='models/face_mask_detection.prototxt'
proto='models/face_mask_detection.caffemodel'
Net = cv2.dnn.readNet(model, proto)
video_path = 0
#self.run_on_video0(Net, conf_thresh=0.5)
self.run_on_video1(Net, conf_thresh=0.5)
由于我们是用按钮实现摄像头的调用,所以模型文件直接赋值就可以了,第2行和第3行就是这个功能。。。第4行:用模型构建网络,第5行为video_path赋值,其实这个例程中我们只用了摄像头,这个参数也没有用,去掉也可以。。。,第6行:调取run_on_video0或run_on_video1进行摄像头数据采集和识别,这两个函数的区别只是一个是在label控件上显示结果,另一个是CV2单独窗口显示。。。不同需要时自行切换就可以了。
结果显示

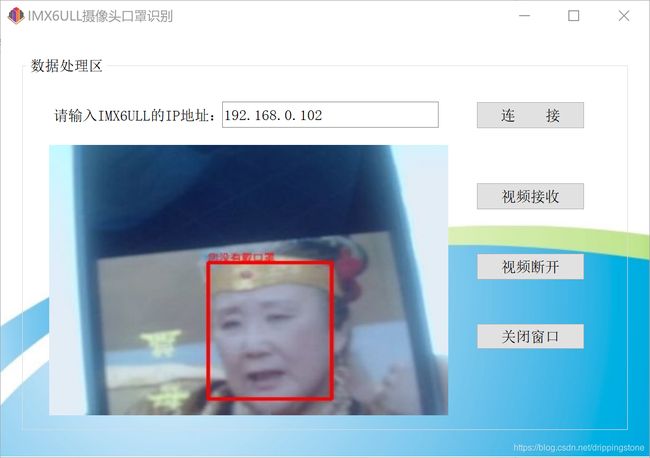
这个小实例就完全做完了,后面还可以结合IMX6ULL的语音系统进行语音报警等,目前先做到这样。。。算法的识别率还是相当可以的,只是当人脸的一半在镜头外时容易出现误报,其他还真是OK。。。。,后面有时间我们再研究这个开源的算法吧。。。。