PyTorch实现图像分类-CIFAR10数据集
CIFARr-10 是由 Hinton 的学生 Alex Krizhevsky、Ilya Sutskever 收集的一个用于普适物体识别的计算机视觉数据集,它包含 60000 张 32 X 32 的 RGB 彩色图片,总共 10 个分类。其中,包括 50000 张用于训练集,10000 张用于测试集。
它包括十种物体类别:‘飞机’,‘汽车’,‘鸟’,‘猫’,‘鹿’,‘狗’,‘青蛙’,‘马’,‘船’,‘卡车’。
CIFAR-10中的图像尺寸为3×32×32,即尺寸为32×32像素的3通道彩色图像。如下图所示:

一、数据导入:
import torch
import torchvision
#transforms 定义了一系列数据转化形式,并对数据进行处理
import torchvision.transforms as transforms
#定义归一化方法:
#transforms.Compose():将多个transforms组合起来使用
transform=transforms.Compose(
[transforms.ToTensor(), #传入数据转化成张量形式
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) #定义归一化方法
#transforms.Normalize((mean),(std)):用给定的均值和标准差对每个通道数据进行归一化:
#归一方式: (input[channel]-mean[channel])/std[channel]
]
)
#训练数据集: CIFAR10数据集
trainset=torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)
#root(string):数据集的根目录在哪里
#train(bool,optional):如果为True,则创建数据集training.pt,否则创建数据集test.pt。
#download(bool,optional):如果为true,则从Internet下载数据集并将其放在根目录中。如果已下载数据集,则不会再次下载。
#transform(callable ,optional):一个函数/转换,它接收PIL图像并返回转换后的版本。
#target_transform(callable ,optional):接收目标并对其进行转换的函数/转换。
trainloader=torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True,num_workers=0)
#dataset(dataset):输入的数据类型
#batch_size(数据类型 int):每次输入数据的行数,默认为1。
#shuffle(数据类型 bool):洗牌。默认设置为False。在每次迭代训练时是否将数据洗牌,默认设置是False。将输入数据的顺序打乱,是为了使数据更有独立性,
#num_workers(数据类型 Int):工作者数量,默认是0。使用多少个子进程来导入数据。
#测试数据集:
testset=torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform)
testloader=torch.utils.data.DataLoader(testset,batch_size=4,shuffle=False,num_workers=0)
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
训练图像数据:
#定义显示方法:
import numpy as np
import matplotlib.pyplot as plt
def imshow(img):
#输入数据:类型(torch.tensor[c,h,w]:[宽度,高度,颜色图层])
img=img/2+0.5 #反归一处理
npimg=img.numpy()
plt.imshow(np.transpose(npimg,(1,2,0))) #图像进行转置,变为[h,w,c]
plt.show()
#加载图像:
dataiter=iter(trainloader) #随机加载一个mini batch
images,labels=dataiter.next()
#显示图像:
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

二、定义神经网络:
import torch.nn as nn
import torch.nn.functional as F
#定义Net类,运用nn中的Module模块,Module是继承的父类
class Net(nn.Module):
#定义神经网络结构 1x32x32
def __init__(self):
#super()调用下一个父类,并返回父类实例的一个方法
super(Net, self).__init__()
# 第一层:卷积层
self.conv1 = nn.Conv2d(3, 6, 3) #输入频道:1 输出频道:6 3x3卷积核
# 第二层:卷积层 #上一层的输出频道是下一层的输入频道
self.conv2 = nn.Conv2d(6, 16, 3) #输入频道:6 输出频道:16 3x3卷积核
# 第三层:全连接层 28:32-2-2
self.fc1 = nn.Linear(16*28*28,512) #输入维度:16x28x28 输出维度:512
# 第四层:全连接层
self.fc2 = nn.Linear(512, 64) #输入维度:512 输出维度:64
# 第五层:全连接层
self.fc3 = nn.Linear(64, 10) #输入维度:64 输出维度:2
#定义神经网络数据流向:
def forward(self, x):
# 第一层卷积层:
x=self.conv1(x)
x=F.relu(x) #激活
#传递到第二层卷积层:
x=self.conv2(x)
x=F.relu(x) #激活
#传递到第三层全连接层:
x=x.view(-1,16*28*28) #改变x的形状
x=self.fc1(x)
x=F.relu(x)
#传递到第四层全连接层:
x=self.fc2(x)
x=F.relu(x)
#传递到第五层全连接层:
x=self.fc3(x)
return x
#打印神经网络:
net = Net()
print (net)

三、定义损失函数和优化器:
import torch.optim as optim
#计算损失:
#定义损失函数:
criterion=nn.CrossEntropyLoss() #交叉熵损失函数
optimizer=optim.SGD(net.parameters(),lr=0.001,momentum=0.9)
#实现随机梯度下降 lr(float):学习速率 momentum(float):动量因子
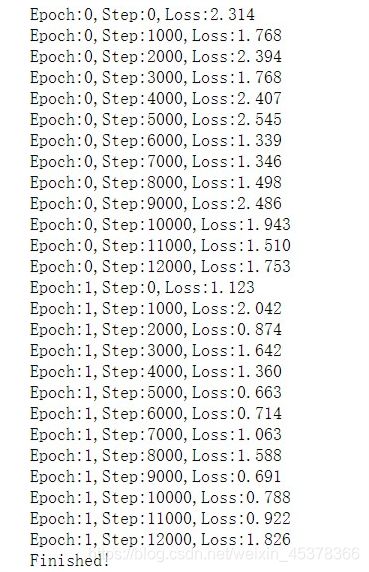
四、训练神经网络:
for epoch in range(2):
for i,data in enumerate(trainloader):
images,labels=data #数据包括图像与标签两部分
outputs=net(images)
loss=criterion(outputs,labels) #计算损失
#更新神经网络权重:
optimizer.zero_grad() #梯度清零
loss.backward() #本次学习的梯度反向传递
optimizer.step() #利用本次的梯度更新权值
#定期输出:
if(i%1000==0):
print ("Epoch:%d,Step:%d,Loss:%.3f"%(epoch,i,loss.item()))
print("Finished!")
五、测试模型
#测试模型:
#用 准确率 来评价神经网络:
correct=0.0 #测试数据中正确个数
total=0.0 #总共测试数据数量
with torch.no_grad(): #不需要梯度
for data in testloader:
images,labels = data
outputs=net(images)
_,predicted=torch.max(outputs.data,1)
#统计正确数量和总共数量
correct += (predicted==labels).sum()
total += labels.size(0)
print ('准确率:',float(correct)/total)
准确率: 0.567
#用 输出图形的类标签 来评价神经网络:
dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('原始类: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('预测类: ', ' '.join('%5s' % classes[predicted[j]] for j in range(4)))

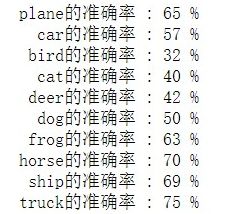
#用 每个类预测准确率 来评价神经网络:
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('%5s的准确率 : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))