基于Amos路径分析的模型拟合参数详解
基于Amos路径分析的模型拟合参数详解
- 1 卡方、自由度、卡方自由度比
- 2 GFI、AGFI
- 3 RMR、RMSEA
- 4 CFI
- 5 NFI、TLI(NNFI)
- 6 ECVI
- 7 AIC、BIC、CAIC
前面两篇博客,分别对Amos的基本操作与模型、参数等加以详细介绍,点击下方即可进入对应文章。
博客1:基于Amos的路径分析与模型参数详解
博客2:基于Amos路径分析的输出结果参数详解
本文(也就是博客3)则将由模型拟合度指标入手,对Amos所得到的路径分析模型结果加以度量。同时,模型结果度量后,对模型加以修正的方法与实践请见 博客4。
1 卡方、自由度、卡方自由度比
在模型运行完毕后,将软件中间区域的第四个白色方框下拉到底,将会显示模型对应最优迭代时的卡方(Chi-square)与自由度(df)。

其中,卡方表示整体模型中的变量相关关系矩阵与实际情况中的相关关系矩阵的拟合度。其数值越大,代表模型与实际情况的差异越大;反之则代表差异越小,也就是差异越不显著;若卡方等于0,则说明模型与实际情况完全符合。
而结合卡方的计算公式,可知随着变量数目的增加,其会不断增加。因此,引入卡方自由度比这一概念。自由度即不同样本矩的数量与必须估计的不同参数的数量之间的差异,具体大家可以查看这篇博客的2.8部分。
因此,可以用卡方自由度比这一参数作为衡量整体模型拟合度的指标:若其值处于1至3之间,表示模型拟合度可以接受。
2 GFI、AGFI
在模型运行完毕后,点击软件左侧“View Text”按钮,可以查看更为详细的模型结果。
首先点击“Model Fit”。这里需要注意,在右侧展示出的多个表格均有三行:
Default model:默认模型,就是我们自己构建、运行的模型
Saturated model:饱和模型,所有变量两两之间均含有因果关系的模型
Independence model:独立模型,所有变量两两之间都不含任何因果关系的模型
关于饱和模型,可以查看这篇博客的3.1部分。
因此,相当于饱和模型与独立模型属于结构方程模型的两个极端,而我们的默认模型就位于二者之间。
我们继续看参数。在第二个表格中找到“GFI”与“AGFI”。
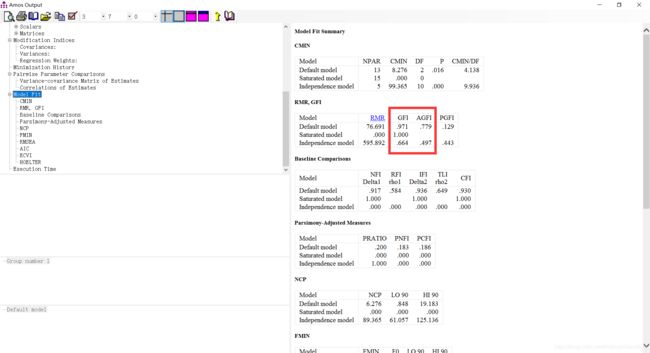
GFI(Goodness of Fit Index),即拟合度指数。其与上述卡方类似,会受到自由度的影响;因此,将自由度对其的影响剔除,便得到了AGFI(Adjusted Goodness of Fit Index)。GFI最大为1,其数值越大,表示模型与实际中的矩阵越接近,即拟合程度越高;反之则说明拟合程度越低。AGFI同样最大为1,其数值越大,表示模型与实际中的矩阵越接近,即拟合程度越高;反之则说明拟合程度越低。二者大于0.9时可以认为模型拟合程度较理想。
3 RMR、RMSEA
点击“Model Fit”,在表格中分别找到“RMR”与“RMSEA”。

RMR(Root Mean Square Residual),即均方根残差(是不是感觉与均方根误差RMSE很像),其代表实际情况下的矩阵与模型矩阵做差后,所得残差的平方和的平方根,也可以视作拟合残差。因此,RMR越小越好,其为0时代表实际情况与模型中的矩阵完全一致,即模型最优。小于0.05时,说明模型拟合优度可以接受。
RMSEA(Root Mean Square Error of Approximation),即近似均方根误差,其代表渐近残差平方和的平方根。同样的,其越小越好,最小为0;若其小于0.05(也有认为小于0.10),则说明模型拟合程度可以接受;大于0.10,则说明模型拟合程度不佳。
4 CFI
点击“Model Fit”,在表格中找到“CFI”。
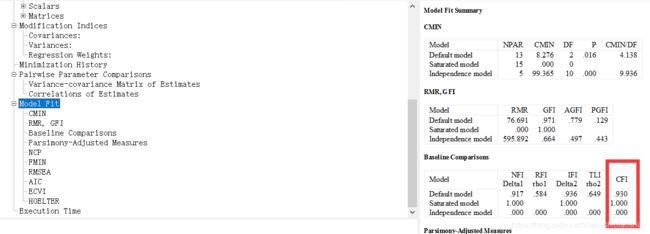
CFI(Comparative Fit Index),即比较拟合指数,其数值处于0到1之间,越接近1表明模型拟合程度越高。其大于0.9时认为模型拟合程度可以接受。
5 NFI、TLI(NNFI)
点击“Model Fit”,在表格中找到“NFI”与“TLI”。
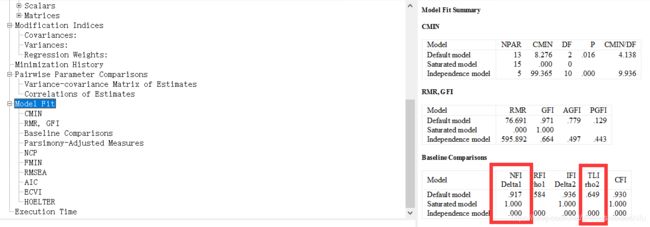
NFI(Normed Fit Index),即规范拟合指数,其数值处于0到1之间,越接近1表明模型拟合程度越高。其大于0.9时认为模型拟合程度可以接受。
TLI(Tucker-Lewis Coefficien),又作NNFI(Non-normed Fit Index),即非规范拟合指数,其数值处于0到1之间,越接近1表明模型拟合程度越高。其大于0.9时认为模型拟合程度可以接受。
6 ECVI
综上可知,结构方程模型对应的模型拟合指标参数很多多。一般的,通常情况下只需要关注上述提及的卡方自由度比、GFI、RMSEA、RMR、CFI、NFI与TFI等指标即可,有时甚至只需关注RMSEA、RMR、CFI、NFI等指标即可。但除此之外,还有一些参数也具有类似的作用,我们可以了解。
点击“Model Fit”,在表格中找到“ECVI”。

ECVI(Expected Cross-Validation Index),即期望复核指数。其在除恒定比例因子情况外与AIC相同。其数值越小,表明模型内不同样本间的一致性越高,说明这一模型具有预测效度,即模型可以用于不同的样本。
7 AIC、BIC、CAIC
点击“Model Fit”,在表格中分别找到“AIC”“BIC”与“CAIC”。
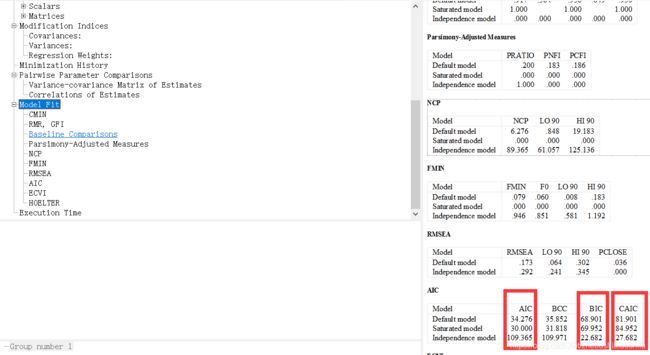
AIC(Akaike Information Criterion),即赤池信息准则,其将待估计变量的个数考虑进假设模型拟合度中,从而比较两个具有不同潜在变量数量的模型的拟合优度。
BIC(Bayes Information Criterion),即贝叶斯信息准则,与CAIC较为类似但计算具体方法不一样。
CAIC(Consistent AIC),即一致性赤池信息准则,其在模型拟合度程度计算中,将样本大小也加以考虑。
以上三者均为综合拟合指标,其数值越小表明模型拟合程度越好。
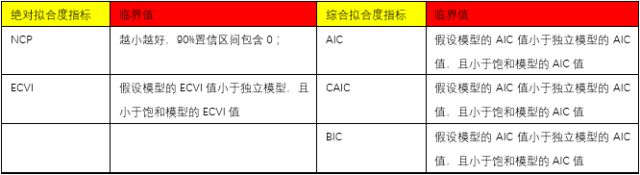
最后,分别用两张图来总结以上内容。
图1,来源于:https://www.spssau.com/helps/questionnaire/pathAnalyse.html。

图2,来源于:https://mp.weixin.qq.com/s?__biz=MjM5MTI5MDgxOA==&mid=2650100246&idx=1&sn=f0b1dcce7c60372db69a5b3158047479&chksm=beb636bb89c1bfaddb97856c75a0b52fb10381982d2ad9abb7473e63210515193735a4cdf255&scene=21#wechat_redirect。

欢迎关注公众号:疯狂学习GIS
