深入解读无服务器架构下的数据库

Serverless 数据库
随着业务的专注度越来越高,抽象的程度也越来越高,李志阳以汽车作为 Serverless 的类比,我们以前去购买一辆汽车,是为了开车去买车,现在可以租车、打车了,我们只需要知道目的地就行了,不需要关注过程,而是关注核心诉求。
在计算服务上面,演进也是类似的,我们从前是自建机房、维护整个机房;到后来在云上购买虚拟机部署业务,去负责里面的扩缩容;再到后来的函数计算,我们只需要关注业务带,整个 CICD 到部署扩容这些东西完全不用关注,整个业界的抽象程度会越来越高。
狭义的 Serverless 分为 FAAS 和 BAAS 两个方面,其基本特点是无需运维、主要以 API 的方式提供服务、按实际使用计费或无使用无费用等。假如用户去浏览网页的时候可能会涉及 CDN 资源,CDN 资源里面如果是静态内容,Serverless 就会通过对象存储里面把照片和视频拉取出来,如果是动态的内容就会触发一个函数计算,函数计算里面再去相应的云数据库里面拉取相应的资源,生成用户所要的动态内容。
如果要将数据库 Serverless 化,传统数据库是怎么样的呢?内存 CPU 是一个固定规格,用户会选择规格去购买,磁盘相对灵活,支持一定步长设置上限,以月预付的方式付费。Serverless 的特点,第一,自动扩缩容,用户不需要关注它的规格,当访问量上来的时候能够自动扩,当访问量下来的时候自动缩,不需要关注规格。第二,按照实际使用去付费。第三,不使用则不计费,存储方面,如果我计数据的存储只需要按实际的存储去计费,如果不使用,这些计算的资源其实不应该去收费。
Serverless 数据库选型
在讲述 Serverless 数据库选型之前,李志阳先介绍了云数据库架构的演进。
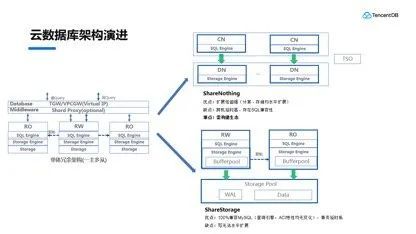
左边是现在主流的架构——单体冗余架构,俗称一主多从,是现在绝大部分用户会使用的一种架构。这种架构的问题是什么呢?就是它的扩展性,不管是做实际的升降级,还是做扩展,都是需要数据搬迁去实现,随着用户量越来越大,搬迁的时间会越来越长。
为了解决这个问题,业界整体趋势是存算分离,计算和存储分离开独自扩展。延伸出来有两类,一个是 ShareNothing 架构,支持水平扩展,它的扩展能力非常强,这是它的最大优势;也存在部分缺点,其中最重要的是它是自研产品,存在 SQL 兼容性的问题,需要构建自己的生态,让用户进到相应生态里面使用,这它一直在努力的方向。另外一种是 SharedStorage 共享存储的架构,共享存储的架构里并没有改变查询引擎和 ACI 这些基础特性,整个兼容性可以做到 100%,完全兼容 MySQL。但它也有个缺点,就是只做了存储的池化,所以它的计算节点目前来说写还是没有办法扩展的,这个也是未来演进的方向。
随后,李志阳又关注到了 Serverless 数据库的用户群,主要面向中长尾用户,他们对于扩展性的诉求并不强,更多的关注使用的便利。兼容性是最重要的一个点,所以我们决定优先去做 Serverless 化,会选择 SharedStorage 的方式去做。
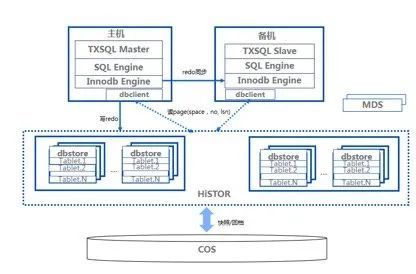
李志阳对 TDSQL-C 的总体架构进行了介绍,TDSQL-C 是腾讯云共享存储数据库,于 2017 年开始研发,在一开始就定下了一个基本原则,即复用云上的成熟组件。在计算层使用腾讯维护的 TXSQL,复用它的 bugfix 和新的特性;存储侧选择在腾讯内部有十几年历史的云硬盘 CBS,把 CBS 的存储部分和硬盘部分进行剖离,打造了 HiSTOR 存储平台,支持云硬盘、云间系统和数据库,数据安全完全由 HiSTOR 去保证,它的副本同步、故障自动迁移、数据校验平台都有一个完整的团队去支撑,这是产品能够完整对外售卖的重要基础。另外,它有很强的特性,比如它的备份/回档速度非常快,快照以 MB 粒度并发,可以达到 GB/s 级的速度。另外,提供 SSD 的场景之外,还有混存和 EC 版本,可以应对归档类的业务,提供更低成本的存储。
基于上述两个存储组件,在计算侧实现物质复制,使用 dbstore 做数据同步,实时生成并实时同步到备机,延时非常低,小于 1 毫秒。同时做日志下沉,传统的数据库先写日志异步,TDSQL-C 对存储只会写日志,通过后端 dbstore 的模块去将日志转化数据,日志下沉有非常多的优点这里不做赘述。
腾讯云是国内首家提供 Serverless 数据库的厂家,当时参考了国外 AWS 的 Aurora Serverless,它的三大特性是怎么实现的?
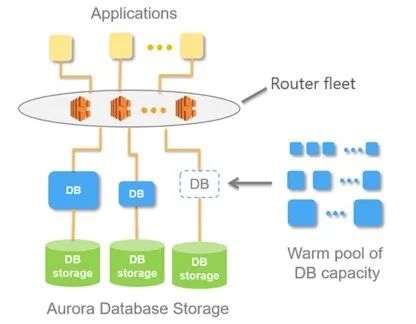
最右边是有一个共享的虚拟池,规格不尽相同,当它扩容的时候是从 1 核 2G 到 4 核 8G 递增式的扩容,比如从 1 核 2G 扩大到 2 核 4G 里面就去一个池子里面找到 2 核 4G 的虚拟机将它挂载在虚拟机里面自动服务就可以提供自动扩容了。这里面有一个问题,假设用户访问过来本身需要 4 核 8G,他仍然需要 1 核 2G 一直递增到 4 核 8G,这个扩容的过程会相对慢一点。另外一个点,他每次去扩容的时候会选择一个新的虚拟机,所以说它的 BP 会失效,每次扩容的时候用户这边会有一次冷启动的过程。
按使用量计费做法比较简单,使用哪一个规格就按照那个规格计费就可以了。不使用不计费,最短是 5 分钟,上面有一个代理节点,知道用户有访问之后会按照刚才的方法共享池子里面找虚拟机拉起来业务的访问,对业务来说就是一个卡顿,但是他的链接是不会有影响的。优点说清楚了,但是它的缺点是什么呢?因为有代理节点,用户需要为这个代理节点去付费,整个恢复时长可能 30 秒,耗时相对比较长。
 扩容时BP失效导致的问题
扩容时BP失效导致的问题
TDSQL-C Serverless
了解完业界情况之后,李志阳介绍了 TDSQL-C Serverless。
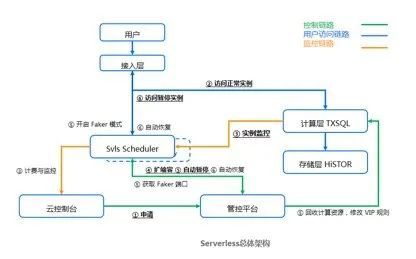
整体架构方面,核心的模块就是 svls scheduler。中控节点做决策,要不要去扩缩容,按照计费的规则上传到云控制台那边去进行计费。这里相对于 Aurora Serverless 的区别在于暂停的应对,TDSQL-C Serverless 有 faker 模块,当用户上这个计算节点的时候会把四层的 vip pod 绑定到 faker 端口,用户过来可以识别出来是协议把它拉起,其优点在于用户不需要为代理节点付费。
整体架构介绍完以后,李志阳介绍了 TDSQL-C Serverless 在实现三大特性方面的能力。
从自动扩缩容来看,我们希望做到秒级的扩缩容,这个期间用户是无感知的,很平滑的。用户购买时会选择最小和最大规格,从 0.25 核开始到 4 核 8G,用户可以选择最小最大规格。
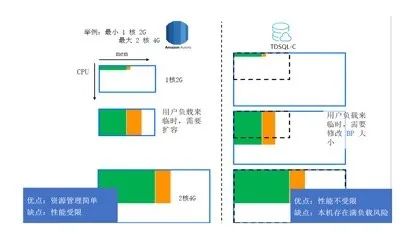
右边的例子可以看到,如果用户选择最小是 1 核,最大是 2 核的情况下,在这边 Amazon Aurzora 是怎么做的呢?当业务访问过来的时候,纵坐标是 CPU,已经把 CPU1 核占满了,持续一段时间会扩大到 2 核 4G。TDSQL-C Serverless 是一上来就会给用户最大的规格,它的 CPU 资源是不会受限的,内存里面是从最小规格开始,假设用户的 CPU 超过了 1 核,一段时间之后就会把他的内存从 2G 扩到 4G,但是他的 CPU 资源不会受限,可以在设置的最大规格上任意使用他的 CPU 资源。
TDSQL-C Serverless 的优点是性能不受限,但是缺点是整机给他最大的资源规格,整机容易出现满负载的情况,因为我们 TDSQL-C 是做计算存储分离的,一旦监控整机的资源超过一定的比例之后,就会去做快速的迁移,迁移的概念就是在另外一个机组拉起这个实例就 OK 了,这个速度可以做到秒级,在资源整体的负载上面可以控制的比较精准。现在云数据库里面普遍的情况是 CPU 整机使用率都是相对偏低的,基于这两个 TDSQL-C Serverless 去做这个应对。
按使用量计费上面我们希望是秒级粒度,我们定义了一个算力单元,CPU 和内存指定的最小规格,规格都是 CPU 和内存比都是 1:2,内存除以 2 可以把它换算成 CPU,整体还是以 CPU 决定整个算力的。我们就通过每个小时 CCU 的值平均给用户进行计费。

李志阳举例说,用户假设选择 0.25 核到 4 核之间,可以看到整个表格 CCU 的计算。右边这边可以看到,如果业务的峰值过来,一开始会用到 3 核的时候,右边图里面可以直接上到 3 核的 CPU,那么就按照 3 核 CPU 的 CCU 去计费,很好的应对整个业务的负载。
最后一部分就是说不使用无计费,里面很核心的点是怎么做到快速恢复,自动启停的逻辑也是比较简单,只要 10 分钟内监测到没有用户访问就回收掉,业务访问回来的时候就把节点拉起。这里面核心的点是怎么快速的拉起,之前提过做日志下沉很大的好处,后端接收到日志之后会源源不断的回放,整个数据库在计算节点启动的过程不需要像传统数据库一样加载到日志然后回放,没有这个过程,所以启动相对比较简单。VDL 是日志已经持久化的日志点,小于 VDL 的话所有的日志多已经持久化了,在运行阶段把日志下放推行 VDL,同时把 VDL 具体值存储到后端。Recovery 阶段,第一个从后端获取 last-vdl,广播所有相关的小表获取,会找到最后的一个连续的 vdl 点作为日志恢复的点,就可以把这个实例拉起来,整个过程都是并行化的,也没有数据存放的过程,时间可以小于 100 毫秒。另外,我们也做了对整个 MySQL 的启动过程做了濒行数据化,现在能做到 2 秒内就能恢复这个实例。
总结与展望
李志阳表示,后续 TDSQL-C Serverless 会将冷启动从 2 秒缩到 200 毫秒,贴近云函数的时间做冷启动优化,整体思路跟 Aurora 相似,以共享池子在线挂载存储,减少进程启动时间。
另外,在进一步降低用户的存储成本方面正在考虑的优化方案,如果很长时间没有访问之后,将用户的数据转存到对象存储里面,用户只需要付对象存储的费用就可以了。