graphpad prism显著性差异分析_spss数据分析之均值比较分析
1.统计推断与假设检验:
统计推断就是根据随机样本的实际数据,对总体的数量特征做出具有一定可靠程度的估计和推断。统计推断的基本内容有参数估计和假设检验两方面。
研究一个随机变量,推断它具有什么样的数量特征,按什么样的模式来变动,这属于估计理论。而推测这些随机变量的数量特征和变动模式是否符合事先所做的假设,这属于检验理论。
参数估计和假设检验的异同点:参数估计和假设检验的共同点是他们都对总体物质或不是很了解,都是利用样本观察值所提供的信息,对总体的数量特征做出估计和判断,但二者所要解决问题的着重点及所用方法有所不同。
假设检验:
1)当总体分布已知(如总体为正态分布)的情况下,对总体包含的参数进行推断的问题称为参数检验
2)当总体分布未知的情况下,根据样本数据对总体的分布形式或特征进行推断,通常采用的统计推断方法是非参数检验方法。
假设检验的基本思想:
反证法及小概率原理。其原理就是首先在原假设正确的条件下计算出现该样本或样本统计量的概率,如果这种事件发生的概率很小,比如小于5%,那么就拒绝原来的假设,而接受备择假设。
假设检验的几个概念:
1)统计假设:
原假设:在很多情况下,我们给出一个统计假设仅仅是为了拒绝它。比如:如果要判断给定的一枚硬币是否均匀,则假设硬币是均匀的(即p=0.5,其中p是正面出现的概率),又比如:如果要判断一种方法是否由于其他方法,则假设两种方法之间没有差异。这样的假设通常称为零假设或原假设,记为H0.
备择假设:任何不同于零假设的假设都称为备择假设。比如:如果零假设是p=0.5,则备择假设是p≠0.5,备择假设记为H1.
2)假设检验的两类错误:
第一类错误:在假设检验中拒绝了本来是正确的零假设,称为“弃真”错误。
第二类错误:在假设检验中没有拒绝本来是错误的零假设,称为“取伪”错误。
3)显著性水平:在作假设检验时,犯第一类错误的最大概率称为检验的显著水平,这个概率常记为p,通常抽样前就指定好,这样得到的结果才不会影响我们的选择。
在实际问题中,显著性水平可以有多重选择,但最为普通的是0.05和0.01.比如:如果设计一个决策法则选择的显著性水平是0.05(5%),那么在100次中可能有5次机会使我们拒绝本该接受的假设,即,大约有95%的把握做出正确的决策,此时,我们说拒绝假设的显著性水平为0.05,即犯拒绝本应该接受的假设这类错误的概率是0.05.
4)概率p值:
p值是当原假设正确时,观测到的样本信息出现的概率。如果这个概率很小,以至于几乎不可能在原假设正确时出现目前的观测数据时,我们就拒绝零假设。p值越小,拒绝原假设的理由就越充分。通常是与预先设定的显著性水平值比较,若值为0.05。p值小于0.05则认为该概率值足够小,应拒绝原假设。
5)假设检验的基本步骤:
1.建立假设:
根据统计推断的目的而提出的对总体特征的假设。统计学中的假设有两方面的内容:
一.是检验假设,也称为原假设或零假设,记为H0
二.是与H0相对立的备择假设,记为H1.后者的意义在于当H0被拒绝时供采用。两者是互斥的,非此即彼。
H0:u=u0 H1:u≠u0
2.选择检验统计量
在统计推断中,总是通过构造样本的统计量并计算统计量的概率值进行推断,一般构造的统计量应服从或近似服从常用的一致分布,例如均值检验中常用的t分布或F分布。
2.在给定显著性水平条件下,做出统计推断结果
显著性水平指的是当假设正确时被拒绝的概率,即弃真概率,一般取0.01或0.05.当检验统计量的概率p值小于显著性水平时,则认为此时拒绝零假设而犯弃真错误的概率小于显著性水平,即低于预先给定的水平,即犯错误的概率小到能我们能容忍得范围,此时可以拒绝原假设;繁殖,如果检验统计量的概率p值大于显著性水平,如果拒绝原假设,犯弃真错误的概率大于预先给定的容忍水平,此时不应该拒绝原假设。(概率p值小于显著性水平,拒绝原假设;概率p值大于显著性水平,不应该拒绝原假设)
3.假设检验应注意的问题:
1.结论不能绝对化
2.本身保留了犯错误的可能性
3.样本量导致的检验效能问题:
1)样本量太小,导致检验效能不同,从而无法检验出可能存在的差异
2)样本量太大,得出的有统计学意义的结论可能根本就没有实际意义。


二.均值比较分析
方法操作:分析---比较均值
比较均值子菜单:
1.均值比较:用于计算指定变量的综合描述统计量
2.单样本T检验,检验单个变量的均值与假设检验值之间是否存在差异
3.独立样本T检验,用于检验两组来自独立总体的样本,其独立总体的均值或中心位置是否一样
4.配对样本T检验,用于检验两个相关的样本是否来自具有相同均值的总体
1)均值过程的主要功能:均值过程,其主要功能是分组计算,比较指定变量的描述性统计量包括均值,标准差,总和,观测量数,方差等一系列单变量描述性统计量,还可以给出方差分析表和线性检验结果。
均值过程中系统默认的描述统计量可按分组给出指定变量的均值,标准差,观测量数等,对话框中的选项可以给出其他更加丰富的描述统计量。
分析方法:
因变量列表(选择待分析的变量)---自变量列表:选择分组变量。可定义多层分组变量,每层分组变量中也可以有多个变量---上一张按钮:选择前一层的分组变量---下一张按钮:选择下一层的分组变量--单击“选项”按钮,弹出下页子对话框。---统计量文本框:在该文本框中列出可以选择的描述性统计量,这些统计量的具体含义同喵星统计分析同的统计量含义一样---单元格统计量文本框:列出要输出的统计量,默认输出均值,个案数和标准差---第一层统计量选项组:该选项组定义是否进行分组第一层变量的方差分析和线性相关性检验。
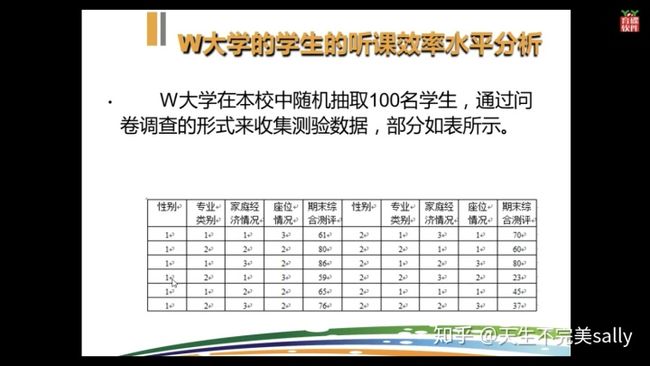
问题:1.描述不同性别学生的综合素质测评成绩平均水平(单层分组)
解题思路:在此案例中,因变量是期末综合测评成绩的得分。自变量是抽样调查的性别、专业、家庭经济情况和上课座位位置。要描述不同性别学生的期末综合测评成绩,可以直接均值比较过程实现。
操作方法:分析---比较均值---均值---因变量(综合素质测评成绩)---自变量(性别)
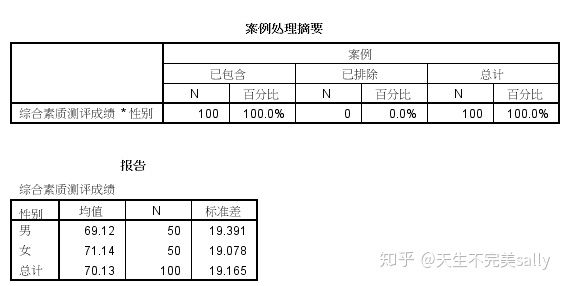
2.描述不同性别和座位情况学生期末综合测评成绩平均水平(多层分组)
解题思路:在此案例中,如果要描述不同性别和不同座位情况的学生的期末综合测评成绩的平均水平,需要有两层来分组,分别以“性别”和“座位情况”为分组变量,可以通过均值比较中添加分组层次的功能来实现。
具体操作方法:
分析--比较均值---均值--因变量(综合素质成绩评定)--自变量(性别)--下一张自变量(座位)

三.单样本T检验:
单样本T检验的目的:是利用来自某总体的样本数据,推断该总体的均值是否与制定的检验值之间存在显著性差异。它是对总体均值的假设检验。
比如:从新生的入学成绩的抽样数据推断今年的平均成绩是否为75分;在人口普查中,某地区职工今年的平均收入是否和往年的平均收入有显著差异。
单样本T检验的步骤:
第1步提出原假设:
单样本T检验需要检验总体均值与指定的检验值是否存在显著性差异。给出检验均值u0,原假设为u=u0,其中,u为总体均值。
例如:假设储户一次平均存(取)款金额与2000元无显著性差异,原假设则为u=u0=2000

第3步:计算检验统计量的观测值及其发生的概率:
在给定原假设的前提下,spss将检验值带入t统计量,得到检验观测值以及根据t分布的分布函数计算出概率p值。
第4步:给定显著性水平α,与检验统计量的概率p值作比较。当检验统计量的概率p值小于显著性水平时,则拒绝原假设,认为总体均值 与要检验的u0之间存在差异;反之,如果检验统计量的概率p值大于显著性水平,则接受原假设,认为总体均值与检验值u0之间无显著性差异。
单样本T检验的操作界面:
检验变量:从候选变量框中选择要进行T检验的变量移入此框中,可同时选择多个变量,此时,spss就将分别产生多个变量的T检验分析结果
检验值:在此框中输入检验值,即检验与什么值有无显著性差异。
选项:单击该按钮弹出选项对话框,该对话框用于指定置信水平和缺失值的处理方法。

操作步骤:分析---比较均值---单样本T检验---检验变量(治愈时间)--检验值6(2013年治愈时间为6个月)--确定
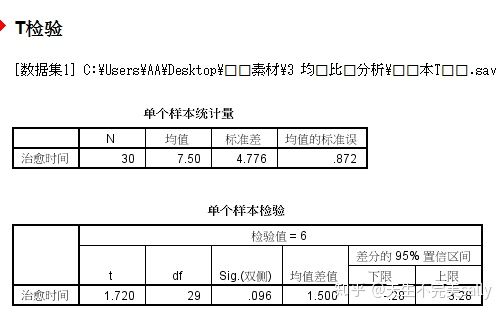
第一个表显示了单个样本的描述性统计。
第二个表显示了单样本T检验的结果:T值,自由度(df),检验概率(Sig),均值差值,差分的95%置信区间的上下限。检验概率为0.096>0.05(显著性水平),所以接受原假设,即2014年全国大学生恋爱失败后情感治疗时间与2013年的治疗时间6个月没有明显差异。
二.独立样本T检验
1.目的:单样本T检验是检验样本均值和总体均值是否有显著性差异,而独立样本T检验的目的是利用来自某两个总体的独立样本,推断两个总体的均值是否存在显著性差异。
在两个样本平均数差异检验中,根据两个样本是否相关,分为独立样本和配对样本。独立样本是指两个样本的数据之间没有关联性,即从一总体中抽取的一批样本对另一总体中抽取的一批样本没有任何影响,是独立的。
2.独立样本T检验的步骤:
第一步:提出原假设:
两独立样本T检验需要检验两个总体的均值是否存在显著性差异。因此,原假设H0为u1=u2,即假设两样本均值相等,备择假设为u1不等于u2 ,即假设两样本均值不等。


第3步:计算检验统计量的观测值及其发生的概率
在给定零假设的前提下,spss将检验值0带入统计量u1-u2部分,得到检验统计量观测值以及根据T分布的分布函数计算出概率P值。
第4步:给出显著性水平,做出统计推断
给出显著性水平,与检验统计量的概率P值作比较。当检验统计量概率p值小于显著性水平时,则拒绝原假设,认为两个总体均值之间存在差异;反之,如果检验统计量的概率p值大于显著性水平,则接受零假设,认为两个总体均值之间无显著性差异。
独立样本T检验的操作界面:
检验变量(从候选变量框中选择要进行T检验的变量移入此框中)---分组变量(选择分组变量,在选择变量进入该框后,“定义组”按钮将被激活,单击该按钮定义分组信息)--选项:单击该按钮弹出“选项”对话框,该对话框用于指定置信水平和缺失值的处理方法。
比如:

在spss中的操作步骤:分析---比较均值---独立样本T检验---检验变量(次数)---分组变量(性别)---定义组(指定值:1代表男性,2代表女性)
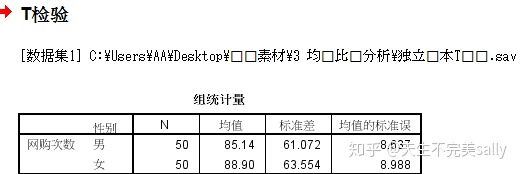

第一个表显示了:单个样本的描述性统计量的值
第二个表显示了:方差齐性检验的结果,T检验的结果(T值,自由度(df),检验概率(sig),均值差值,标准误差值,置信区间的上限和下限)。
方差齐性检验(F值和显著性概率0.547,因为显著性概率0.547>0.05,接受原假设,说明两总体的方差没有显著性差异)
均值方程的T检验:双侧检验的概率为0.764>0.05,因此接受两个独立样本T检验的原假设,即两个样本所代表的总体的平均数是相同的,说明男生和女生网购次数是没有显著性差异的。均值差值为-3.760是描述性统计量中男女两个组的平均数的差,说明样本中男生的网购次数比女生的网购次数少了3.760次,但是这种差异是不显著的。
三.配对样本T检验的目的
配对样本T检验的目的是检验两个相关样本是否来自相同均值的正态总体,即推断两个总体的均值是否存在显著性差异。
配对是指两个样本的各样本值之间存在着对应关系,配对样本的两个样本值之间的配对是一一对应的,并且两个样本的容量相同。配对样本T检验与独立样本T检验的差别之一是要去样本是配对的。所谓配对样本可以是个案在“前”、后”两种状态下某属相的两种状态,也可以是对某事物两个不同侧面或方面的描述,其差别在于抽样不是相互独立的,而是相互关联的。
配对样本T检验的步骤:
第一步:提出原假设:
配对样本T检验需要检验两个总体均值是否存在显著性差异,其原假设为H0:u1=u2,其中,u1和u2分别为第一个总体和第二个总体的均值。

第3步:计算检验统计量的观测值及其发生的概率:
该步骤的目的是计算T统计量的观测值以及相应的概率p值,spss将计算两组样本的差值,并将相应数据带入上试的T检验统计量计算公式中,计算出T统计量的观测值和对应的概率p值。
第4步:给出显著性水平,并做出统计推断结果
给出显著性水平,与检验统计量的p值作比较。如果概率p值小于显著性水平,则应当拒绝原假设,认为差值的总体均值与0有显著不同,拒绝原假设;反之,如果概率p值大于显著性水平,则不应拒绝原假设,认为差值的总体均值与0无显著不同,量总体的均值不存在显著性差异。
配对样本T检验的操作界面:
成对变量:该列表框中的变量作为分析变量,总是成对出现,可以有多对被分析的变量。
选项:单击选项按钮,弹出选项对话框,该对话框用于指定置信水平和缺失值的处理方法
如:

解题思路:在该案例中,电视观众看国内电视台和韩国电视节目的时间是来自筒体人是成对出现并相互影响,且样本容量较大(N>30),可以认为总体分布近似正态,因此,选用两配对样本T检验对二者的差异是否存在显著进行检验。
操作步骤:分析--比较均值---配对样本T检验---成对变量(看国剧的时间,看韩剧的时间)


第一个表:单个样本的描述性统计量的值
第二个表:成对样本的相关系数,对两个样本进行相关性检验,是能够进行两配对样本T检验的前提检验,这两个样本之间是否存在相关关系。根据相关系数和显著性概率,说明在95%的置信水平上差异是显著的,观众看韩剧和国剧的时间相关性是显著的,符合配对样本T检验的前提条件。
第三个表:对两个相关样本T检验的结果,显著性概率为0.124>0.05,说明看韩剧和看国剧的时间是没有显著性差异的。