我们已经知道,神经网络的参数主要是权重(weights):W, 和偏置项(bias):b。
训练神经网络的时候需先给定一个初试值,才能够训练,然后一点点地更新,但是不同的初始化方法,训练的效果可能会截然不同。本文主要记录一下不同的初始化的方法,以及相应的效果。
笔者正在学习的Andrew Ng的DeepLearning.ai提供了相应的模型框架和数据,我们这里要自己设置的就是不同的初值。
数据可视化之后是这样的:
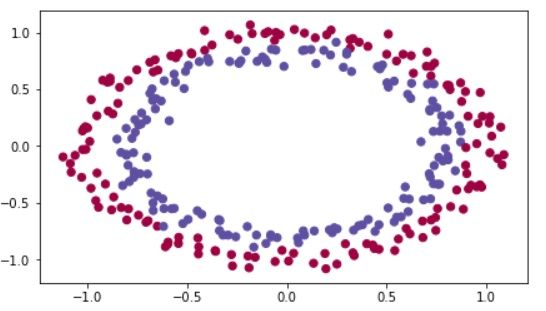
我们需要做的就是把上面的红点和蓝点分类。
一、直接把参数都初始化为0
这是大家可以想到的最简单的方法,也确实很多其他的地方都采用0初值,那神经网络中这样做是否可行呢?
在python中,可以用np.zeros((维度)) 来给一个向量/矩阵赋值0,
于是,对于L层神经网络,可这样进行0-initialization:
for l in range(1,L): #总共L层,l为当前层
W = np.zeros((num_of_dim[l],num_of_dim[l-1])) # W的维度是(当前层单元数,上一层单元数)
b = np.zeros((num_of_dim[l],1)) # b的维度是(当前层单元数,1)
通过这样的初值,我们run一下模型,得到的cost-iteration曲线以及在训练集、测试集上面的准确率如下:

可以发现, 压根就没训练!得到的模型跟瞎猜没有区别。
为什么呢?
我们看看神经网络的结构图:

这是一个3层神经网络,可以看出,神经网络结构是十分 对称的,不管有几层。
当我们把所有的参数都设成0的话,那么上面的每一条边上的权重就都是0,那么神经网络就还是对称的,对于同一层的每个神经元,它们就一模一样了。
这样的后果是什么呢?我们知道, 不管是哪个神经元,它的前向传播和反向传播的算法都是一样的,如果初始值也一样的话,不管训练多久,它们最终都一样,都无法打破对称(fail to break the symmetry),那每一层就相当于只有一个神经元, 最终L层神经网络就相当于一个线性的网络,如Logistic regression,线性分类器对我们上面的非线性数据集是“无力”的,所以最终训练的结果就瞎猜一样。
因此,我们决不能把所有参数初始化为0,同样也不能初始化为任何相同的值,因为我们必须“打破对称性”!
二、随机初始化
好,不用0,咱们随机给一批值总可以吧。确实可以!咱们看看:
【下面的演示会试试多种参数或超参数,为了方便大家看,我分4步:①②③④】
①随机初始化
python中,随机初始化可以用 np.random.randn(维度) 来随机赋值:
于是前面的代码改成:
for l in range(1,L): #总共L层,l为当前层
W = np.random.randn(num_of_dim[l],num_of_dim[l-1]) # W的维度是(当前层单元数,上一层单元数)
b = np.zeros((num_of_dim[l],1)) # b的维度是(当前层单元数,1)
这里有三点需要说明一下:
- b不用随机初始化,因为w随机之后,已经打破对称,b就一个常数,无所谓了
- random.rand()是在0~1之间随机,random.randn()是标准正态分布中随机,有正有负
- np.zeros(())这里是两个括号,random.randn()是一个括号,奇怪的很,就记着吧
那看看run出来的效果如何呢:

效果明显比0初始化要好多了,cost最后降的也比较低,准确率也不错,92%。给分类效果可视化:
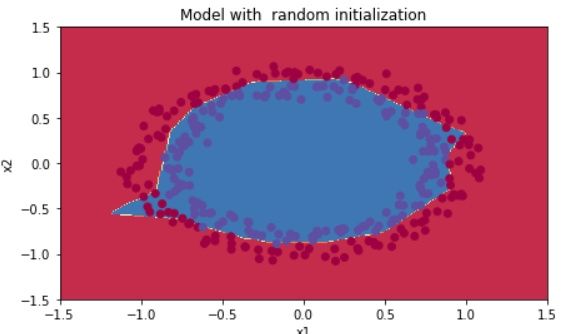
我们接着试试,如果把随机初始化的值放大一点会出现什么:
②放大版随机初始化
for l in range(1,L): #总共L层,l为当前层
W = np.random.randn(num_of_dim[l],num_of_dim[l-1])*10 # W的维度是(当前层单元数,上一层单元数)
b = np.zeros((num_of_dim[l],1)) # b的维度是(当前层单元数,1)
上面的代码中,我们给W最后多乘以10,run的效果:
【注意啊,乘以10不一定就是变大,因为我们的w的随机取值可正可负,所以乘以10之后,正数更大,负数更小】

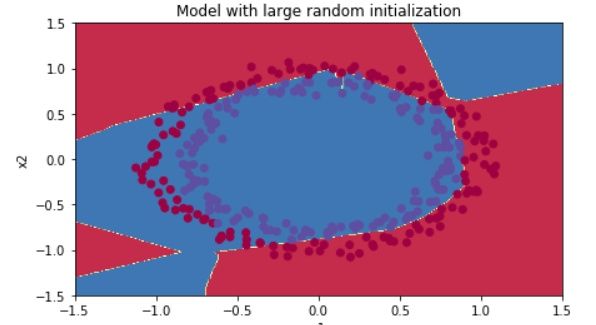
咦~~ 真o心 ~~
准确率明显降低了许多,到86%。
为什么把随机初始化的值放大就不好了呢?
我们看看神经网络中常用的sigmoid函数:
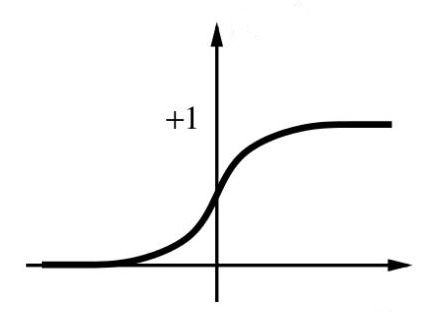
这家伙,中间的斜率大,两边的斜率小还趋于零。所以当我们把随机的值乘以10了之后,我们的初值会往两边跑,那么我们的梯度下降就会显著变慢,可能迭代半天,才下降一点点。
这就是问题的症结。
我们上面的实验,可以从图的横坐标看出,都是设定的一样的迭代次数(iteration number):15000次,因此,在相同的迭代次数下,放大版的随机初始化的模型的学习就像一个“笨学生”,没别人学的多,因此效果就更差。
为了验证我说的,我们可以试试吧迭代次数加大,看看我说的是不是对的:
③增大迭代次数
测试了好久。。。
然后打脸了。。。
不过还是值得玩味~~
我把迭代次数显示设为60000,也就是增大了4,5倍,结果cost function后来下降十分十分缓慢,最后效果还不如之前的。然后我再把迭代次数增加到了160000,相当于比一开始增大了10倍多,结果....

可以看到,cost基本从20000次迭代之后就稳定了,怎么都降不下去了,实际上是在降低,但是十分十分十分X10地缓慢。难道这就是传说中的梯度消失???
所以结果并没有我想象地把迭代次数加大,就可以解决这个问题,实际上,可以看到,在训练集上准确度确实上升了,所以说明确实模型有所改进,只不过改进的太缓慢,相当于没有改进。
仔细分析了一下,由于W太大或者太小,导致激活函数对w的倒数趋于零,那么计算cost对w的导数也会趋于零,所以下降如此缓慢也是可以理解。
好,放大的效果如此差,我们缩小试试?
④缩小版随机初始化
还是回到迭代14000次,这次把w除以10看看:

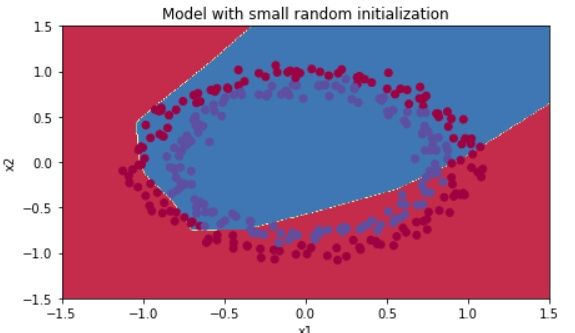
嘿~缩小结果甚至更差!连圈圈都没有了。
上面这个图,说明学习到的模型太简单了,因为我们把w都除以10,实际上就接近0了,深度学习中我们认为参数越大,模型越复杂;参数越小,模型越简单。所以除以10之后,参数太小了,模型就too simple了,效果当然不好。
最后再试一次吧,再多的话大家都烦了我也烦了。
上面乘以10和除以10,效果都很差,那我们试一个中间的,比如:除以3(真的是随便试试)

好了好了,终于提高了!这个准确率是目前的最高水平了!
可见,只要找到一个恰当的值来缩小,是可以提高准确率的。但是,这里除以三是我拍脑门出来的,不能每次都这么一个个地试吧,有没有一个稳健的,通用的方法呢?
有!接着看:
三、何氏初试法(He Initialization)(不知道是不是何,我音译的)
上面试了各种方法,放大缩小都不好,无法把握那个度。还好,总有大神为我们铺路,论文He et al., 2015.中提出了一种方法,我们称之为He Initialization,它就是在我们随机初始化了之后,乘以
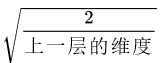
这样就避免了参数的初始值过大或者过小,因此可以取得比较好的效果,代码也很简单,用np.sqrt()来求平方根:
for l in range(1,L): #总共L层,l为当前层
W = np.random.randn(num_of_dim[l],num_of_dim[l-1])**np.sqrt(2/num_of_dim[l-1]) # W的维度是(当前层单元数,上一层单元数)
b = np.zeros((num_of_dim[l],1)) # b的维度是(当前层单元数,1)
取得的效果如下:

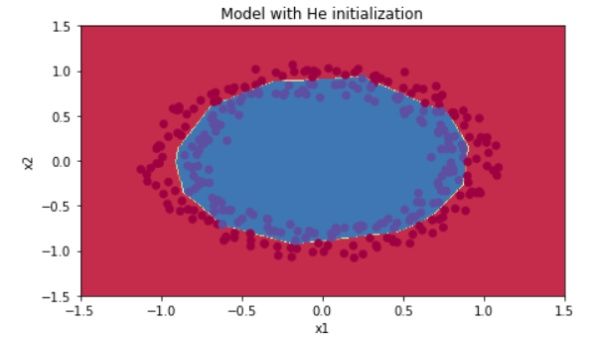
啧啧啧,看这效果,看这优美的损失曲线,看着卓越的准确率... ...
以后就用你了,He Initialization !
其实吧,He Initialization是推荐针对使用ReLU激活函数的神经网络使用的,不过对其他的激活函数,效果也不错。
还有其他的类似的一些好的初始化方法,例如:
推荐给sigmoid的Xavier Initialization:随机化之后乘以
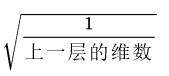
总结一下:
- 神经网络不可用0来初始化参数!
- 随机赋值是为了打破对称性,使得不同的神经元可以有不同的功能
- 推荐在初始化的时候使用He Initialization
我的其他[深度学习笔记]文章:
【DL笔记1】Logistic回归:最基础的神经网络
【DL笔记2】神经网络编程原则&Logistic Regression的算法解析
如果觉得写的不错,随手点个赞吧!