R-CNN,SSP-Net,fast-RCNN,faster-RCNN论文读后笔记
一:R-CNN(Rich feature hierarchies for accurate object detection andsemantic segmentation v5.pdf)
R指的是region,也就是在数据进入深度网络(CNNs)之前进行预处理,在预训练图像中生成若干个regionproposals,再将这些regionproposals进行resize,因为CNN网络要求输入数据维度相同。
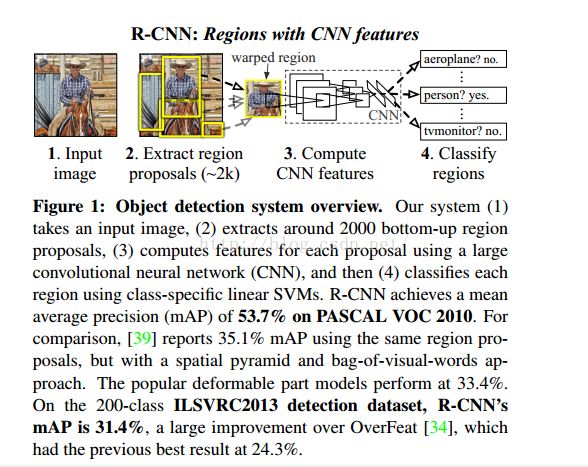
训练过程:
①supervised pre-training,使用传统的CNN来训练大规模数据集ImageNet,获得初始化权重。
所谓的有监督预训练,我们也可以把它称之为迁移学习。比如你已经有一大堆标注好的人脸年龄分类的图片数据,训练了一个CNN,用于人脸的年龄识别。然后当你遇到新的项目任务是:人脸性别识别,那么这个时候你可以利用已经训练好的年龄识别CNN模型,去掉最后一层,然后其它的网络层参数就直接复制过来,继续进行训练。这就是所谓的迁移学习,说的简单一点就是把一个任务训练好的参数,拿到另外一个任务,作为神经网络的初始参数值,这样相比于你直接采用随机初始化的方法,精度可以有很大的提高。
图片分类标注好的训练数据非常多,但是物体检测的标注数据却很少,如何用少量的标注数据,训练高质量的模型,这就是文献最大的特点,这篇paper采用了迁移学习的思想。文献就先用了ILSVRC2012这个训练数据库(这是一个图片分类训练数据库),先进行网络的图片分类训练。这个数据库有大量的标注数据,共包含了1000种类别物体,因此预训练阶段cnn模型的输出是1000个神经元,或者我们也直接可以采用Alexnet训练好的模型参数。
这点在微调过程能够看得出来:原文:Aside from replacing the CNN’s ImageNetspecific 1000-wayclassification layer with a randomly initialized (N+ 1)-way classification layer (whereNis the
number of object classes, plus 1 for background),将最后的分类器部分替换掉。
为什么要进行预训练呢?
物体检测的一个难点在于,物体标签训练数据少,如果要直接采用随机初始化CNN参数的方法,那么目前的训练数据量是远远不够的。这种情况下,最好的是采用某些方法,把参数初始化了,然后在进行有监督的参数微调,这边文献采用的是有监督的预训练。所以paper在设计网络结构的时候,是直接用Alexnet的网络,然后连参数也是直接采用它的参数,作为初始的参数值,然后再fine-tuning训练。
②Domain-specific fine-tuning. 使用与检测任务相关的较小的数据集对CNN进行微调。
为什么要进行微调呢?
首先,反正CNN都是用于提取特征,那么我直接用Alexnet做特征提取,省去fine-tuning阶段可以吗?这个是可以的,你可以不需重新训练CNN,直接采用Alexnet模型,提取出p5、或者f6、f7的特征,作为特征向量,然后进行训练svm,只不过这样精度会比较低。那么问题又来了,没有fine-tuning的时候,要选择哪一层的特征作为cnn提取到的特征呢?我们有可以选择p5、f6、f7,这三层的神经元个数分别是9216、4096、4096。从p5到p6这层的参数个数是:4096*9216 ,从f6到f7的参数是4096*4096。那么具体是选择p5、还是f6,又或者是f7呢?
文献paper给我们证明了一个理论,如果你不进行fine-tuning,也就是你直接把Alexnet模型当做万金油使用,类似于HOG、SIFT一样做特征提取,不针对特定的任务。然后把提取的特征用于分类,结果发现p5的精度竟然跟f6、f7差不多,而且f6提取到的特征还比f7的精度略高;如果你进行fine-tuning了,那么f7、f6的提取到的特征最会训练的svm分类器的精度就会飙涨。
据此我们明白了一个道理,如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了。
疑问:CNN训练的时候,本来就是对bounding box的物体进行识别分类训练,是一个端到端的任务,在训练的时候最后一层softmax就是分类层,那么为什么作者闲着没事干要先用CNN做特征提取(提取fc7层数据),然后再把提取的特征用于训练svm分类器?这个是因为svm训练和cnn训练过程的正负样本定义方式各有不同,导致最后采用CNNsoftmax输出比采用svm精度还低。
事情是这样的,cnn在训练的时候,对训练数据做了比较宽松的标注,比如一个bounding box可能只包含物体的一部分,那么我也把它标注为正样本,用于训练cnn;采用这个方法的主要原因在于因为CNN容易过拟合,所以需要大量的训练数据,所以在CNN训练阶段我们是对Boundingbox的位置限制条件限制的比较松(IOU只要大于0.5都被标注为正样本了);
然而svm训练的时候,因为svm适用于少样本训练,所以对于训练样本数据的IOU要求比较严格,我们只有当bounding box把整个物体都包含进去了,我们才把它标注为物体类别,然后训练svm.
二:SPP-net(Spatial Pyramid Pooling in Deep Convolutional Networks forVisual Recognition.pdf)

与经典的R-CNN相比,在目标检测方面,SPP-Net主要解决了几个存在的问题:
1:不需要对每一个Region(candidatewindow)进行单独训练
2:不需要重复训练CNN网络多次
3:解决了corp/wrap过程中造成的图像失真或者剪切不完全的问题
解决方案:
1:将经过SS处理后(含有2k个region proposal)的整幅图像输入CNNs,不需要对图像中的每一个proposal进行训练,然后得到整个featuremap,大大减少了计算proposal的特征时候的运算开销。然后Mapping aWindow to Feature Maps.具体做法:
In ourimplementation, we project the corner point of a window onto a pixel inthefeature maps, such that this corner point in the image domain isclosest tothe center of the receptive field of that featuremap pixel。
不太理解,目前理解是:想要得到feature map path,要确定角点(论文中用的左上角点和右下角点),用已知的imageregion的window(ROI)的角点来确定特征图上的角点。步骤:
具体过程:
前提:我们已经知道了ROI位置,我们的目的是要在卷积层上得到对应的候选窗口。
① 取得ROI中心点位置(x,y)
② 则对应的feature map path的左上角点为![]()
右下角点为
![]()
补充:

看上图在conv5的时候提取的特征已经具有较好的响应能力了,这些filter的位置已经确定,这里感觉就是中心点了,只是要确定其大小,那么我们就可以知道其中心点(x’,y’),则根据论文说的公式相对应ROI的中心点就为![]()
,这里是不是就对应了这句话such that this corner point in the imagedomain is closest tothe center of
the receptive field of that featuremap pixel。互相来确认?论文也没说,不是很确定。
论文中也用了多尺寸的图像也即将一副图像resize为多个尺寸(480, 576, 688,864, 1200)进行训练,这就增加了特征提取的准确性,在微调过程中也只需要微调FC层即可,提高训练效率。
2:由于第一步的功劳,对于每一副图像不需要训练CNN网络多次。只需要训练一次CNN,从特征图中得到候选窗口。
3:通过SS等方法得到的Region proposal(candidate windows)不需要进行crop/wrap了,因为convolution layer和Pooling layer并没有对图像尺寸大小的约束,而是在FC层有要求,因此论文在FC层之前在最后的卷积层之后pool5层采用SSP,替代常规的Pooling,这也是其核心之处。如下图:
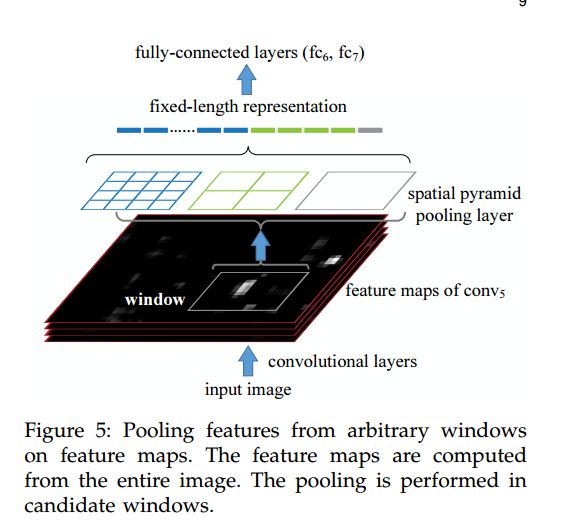
具体做法:将得到的region proposal,进行SSP算法,通过pyramid -level n*n bins,一般取(1*1,2*2,3*3,4*4,6*6),bin代表分割后的小方格,看下图:

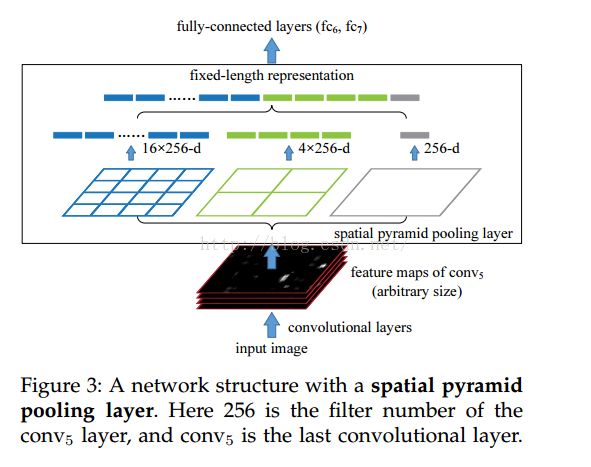
上图采用的比例是(1*1;2*2;4*4),level=3的金字塔。到FC层时feature vector长度为(16+1+4)*256。
三:Fast R-CNN
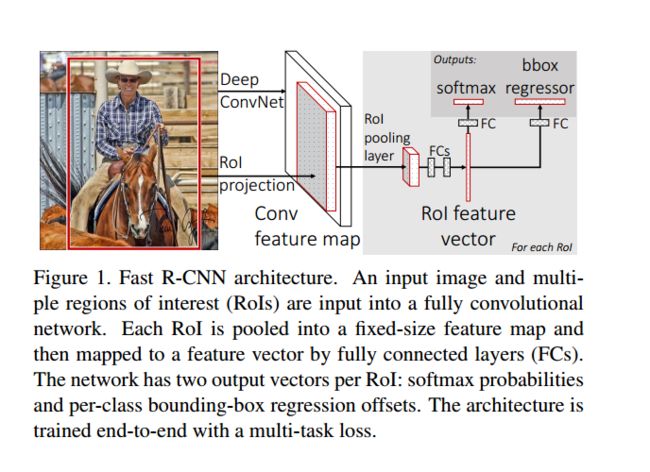
从图中可以看出与SPP-net的区别主要有以下三点:
1:输入数据由单输入改为双输入,分别是a list of images and a list of RoIs in those images.
2:引入了ROI Pooling层,将最后一层Pooling层替换为ROI Pooling层,这次相当于SPP-Net中的single-scale模式,从feature map上提取一个固定的特征向量到FC层。
3:输出包含了2层分支输出,一层分支为classification层,用来估计K类object与一类背景的概率(softmax);另一层为Regression层(为每一类输出一个4实值,其实也是bounding box的位置,通常用(x,y,w,h)表示,x,y代表中心点位置,w,h代表长宽)
其他改变:
1. 1:fine turning过程。SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层。
2. SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor
四:faster R-CNN(Faster R-CNN Towards Real-Time ObjectDetection with Region Proposal Networks v3.pdf)
相比于 fastR-CNN , FasterR-CNN 可以看做是对 Fast R-CNN 的进一步加速,最主要解决的如何快速获得 proposal ,一般的做法都是利用显著性目标检测(如 Selectivesearch )过一遍待检测图,得到 proposal 。基于区域的深度卷积网络虽然使用了 GPU 进行加速,但是 theregion proposal methods 确却都是在 CPU 上实现的,这就大大地拖慢了整个系统的速度。然后作者提出,卷积后的特征图同样也是可以用来生成 region proposals 的。通过增加两个卷积层来实现 Region Proposal Networks (RPNs) , 一个用来将每个特征图 的位置编码成一个向量,另一个则是对每一个位置输出一个 objectness score 和 regressed bounds for k region proposals 。如图: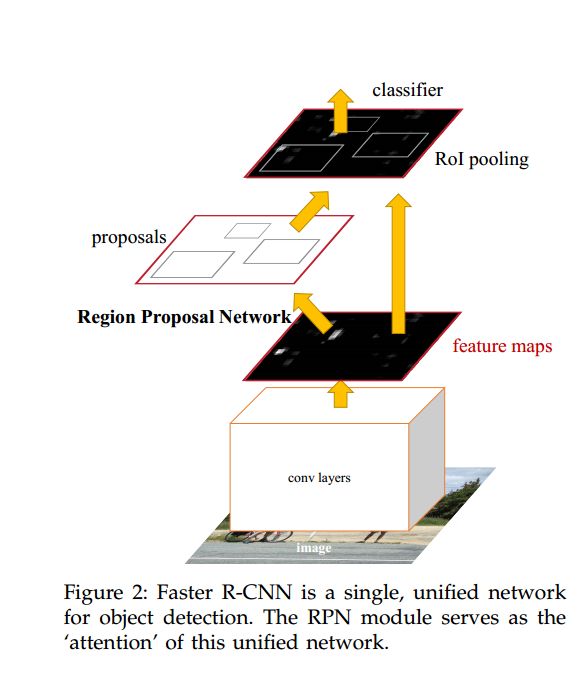
RPNs 是一种 fully-convolutional network (FCN),为了与 Fast R-CNN相结合,作者给出了一种简单的训练方法:固定 proposal,为生成 proposal和目标检测这两个task交替微调网络。
RPN网络是怎样训练的呢?
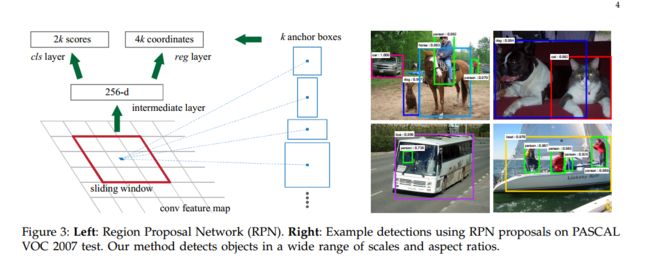
区域建议网络(RPN)将一个图像(任意大小)作为输入,输出矩形目标建议框的集合,每个框有一个objectness得分。我们用全卷积网络[14]对这个过程构建模型。因为我们的最终目标是和Fast R-CNN目标检测网络[15]共享计算,所以假设这两个网络共享一系列卷积层。在实验中,详细研究Zeiler和Fergus的模型[23](ZF),它有5个可共享的卷积层,以及Simonyan和Zisserman的模型[19](VGG),它有13个可共享的卷积层。
为了生成区域建议框,我们在最后一个共享的卷积层输出的卷积特征映射上滑动小网络,这个网络全连接到输入卷积特征映射的nxn的空间窗口上。每个滑动窗口映射到一个低维向量上(对于ZF是256-d,对于VGG是512-d,每个特征映射的一个滑动窗口对应一个数值)。这个向量输出给两个同级的全连接的层——Bounding Box Regression Layer(reg)和softmaxLayer(cls)。本文中n=3,注意图像的有效感受野很大(ZF是171像素,VGG是228像素)。图1(左)以这个小网络在某个位置的情况举了个例子。注意,由于小网络是滑动窗口的形式,所以全连接的层(nxn的)被所有空间位置共享(指所有位置用来计算内积的nxn的层参数相同)。这种结构实现为nxn的卷积层,后接两个同级的1x1的卷积层(分别对应reg和cls),ReLU[15]应用于nxn卷积层的输出。
相关链接:http://blog.csdn.net/liumaolincycle/article/details/48804687
http://www.myexception.cn/mobile/2085948.html
http://www.cnblogs.com/rocbomb/p/4428946.html
http://www.360doc.com/content/16/0313/16/1317564_541854712.shtml
http://blog.csdn.net/u011534057/article/details/51235964