2021-04-22
本文主要详细讲解JDK7中HashMap的实现,后续文章将会介绍JDK7CurrentHashMap和JDK8中对应的HashMap。
在此之前先给大家补充一下基础知识,当然也可以跳过。
1.hashCode以及equals的区别与联系。
这两个方法都是Object这个顶层父类的方法。且hashCode方法是一个native方法,即一个本地方法,用于计算 得到一个对象的hash散列值的。而equals这个方法则是一个普通的公共方法,在Object类中,equals方法如下:
public boolean equals(Object obj) {
return (this == obj);
}
这意味着,如果一个类没有重写其equals方法,默认情况下,如果这个类的对象a.equals(b)返回true的话,那么意味着a和b对象一定是同一个对象。
2.关于==号在引用类型和基本数据类型中的不同。
在java中,有八种基本数据类型。分别是byte(1 byte),short(2 byte),char(2 byte),int(4 byte),float(4 byte),double(8 byte),long(8 byte),boolean(JVM规范并没有明确指出其说占空间大小)。对于这八个基本数据类型,==比较的就是其内容值本身,肉眼看上去的相等那么就相等。浮点数和整形都是有符号类型(在二进制表示中最高位为符号位,不参与计算)。而char无符号位的,这点在JVM规范中可以查看。且本人在IDEA中实验了下,发现定义超过65535(2个字节无符号最大65535)和小于0的整形都不能赋值给一个字符型,也可佐证这一点|01.jpg。且char在java中是以unicode存储的。
而引用数据类型则不一样了,引用类型存储的并不是其内容本身,而是与其关联的d对象的内存地址。比如下面一行代码。02.jpg。在这里,会在java堆中创建一个Object对象,那么这个o就是其引用,在这里这个引用是存放在Java栈对应栈帧里面的局部变量表中(不理解也没关系,不影响后面理解)。这里这个o指向的就是这个堆中Object对象地址。这点c/c++中的指针很相似。
因此,对于==号。
1)在基本数据类型中,是用于判断==两边的值是相等。
2)在引用数据类型中,用于判断所指对象地址值是否相等,若相等。则代表必定是同一个对象。
3.在来理解equals方法。
这个时候就很好理解了。equals方法在Object中就是一个==号。用于判断地址是否相等的。但是因为String重写了其equals方法。还有其他的Integer,Double的包装类也实现了,所以他们的equals都是用于比较值的。
4.再来理解hashCode。
在 Java 中,由 Object 类定义的 hashCode 方法会针对不同的对象返回不同的整数。(这是通过将该对象的内部地址转换成一个整数来实现的,但是 JavaTM 编程语言不需要这种实现技巧)。
如果根据 equals(Object) 方法,两个对象是相等的,那么对这两个对象中的每个对象调用 hashCode 方法都必须生成相同的整数结果。
如果根据 equals(java.lang.Object) 方法,两个对象不相等,那么对这两个对象中的任一对象上调用 hashCode 方法 不要求 一定生成不同的整数结果。但是,程序员应该意识到,为不相等的对象生成不同整数结果可以提高哈希表的性能。
一般HashCode多用于HashSet,HashMap,HashTable等容器中。
关于HashCode和equals的一些总结:
如果 x.equals(y) 返回 “true”,那么 x 和 y 的 hashCode() 必须相等。
如果 x.equals(y) 返回 “false”,那么 x 和 y 的 hashCode() 有可能相等,也有可能不等。
如果 x 和 y 的 hashCode() 不相等,那么 x.equals(y) 一定返回 “false”。
5.接下来在详细讲解JDK7中的HashMap底层原理。
1)我们先来看看JDK7中HashMap的一些基本属性。

看完了各个大致的属性结构之后,我们总结一下:
1)一个默认初始容量值16。
2)一个默认初始加载因子0.75。
3)还有一个默认的阈值,这个阈值是加载因子和容量一起算出的。当然默认也就是12。这是在
代码中显示计算的。
4)还有一个就是存储真实数据的table。
在这里我们看到了table其实是一个Entry数组,所以我有必要也给大家剖析一下这个Entry和我们传进去的键值对有什么关系。
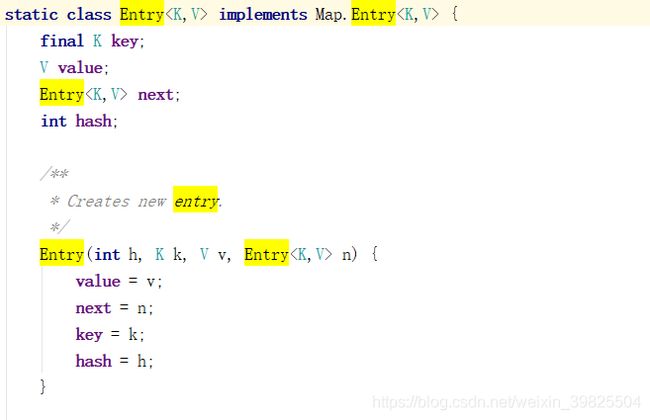
我们容易看到Entry是HashMap的一个静态内部类,其中我们传进去的键和值最后封装到这个Entry对象去。且键和值都是使用泛型,说明键和值都可以传任意类型,包括null。这里还有一个属性next,可以猜测,在底层使用了链表。hash就是这个key的hash。这个Entry使用起来比较方便,提供了很多方法使用起来很方便,这也是为什么封装成一个Entry的原因。关于这一点大家也可也去看源码。
2)在了解了以上内容之后,再来看看HashMap中的无参构造函数。
3)接下来我们来进去put(key,value)方法看看。

上面是put方法的全景了,本来不想画这么图,显得太low,但是还是怕有些小伙伴看不懂。接下来看我如何秀操作帮大家一步步拆分HashMap。
首先,首当其冲的是inflateTable。
在调用上面的put的时候,可以看出,if是会执行的。所以接下来会调用inflateTable方法。 在这里调用了inflateTable(threshold)函数,我刚在上面让大家记住一下在默认无参构造函数中,threshold是被赋值成了16,所以这里传进去的是16。接下来我们在进入这个inflateTable方法。

我们可以知道,这个toSize在一开始就是传进来的16。当然,传进来的也可也是10,11,12等。我们可以看到这里面有一个roundUpToPowerOf2()方法,这个方法从名字也可也看出,返回一个大于等于传进去的toSize的2的整数幂。那么这个方法怎么实现这一功能,让我们进去看一下。以下便是roundUpToPowerOf2()方法的实现。

我们可以知道,我们传进去的number初始是一个16。并且一般情况下这个number >= MAXIMUM_CAPACITY是不成立的,因为这个MAXIMUM_CAPACITY在上面定义的是一个1 << 30,这是个非常大的数了,所以我们可以只看那个(number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;就行了。当然我们传进去的是16,所以直接Integer.highestOneBit((number - 1) << 1) : 1;就可以了。好,这个Integer.highestOneBit(args)是个关键。
我们在追进去看看Integer.highestOneBit(args)的源码,可能有些小伙伴已经晕了,大家别急,在这里先有个概念,稍后我会给大家梳理的。

哇,这是一堆的右移和那个不知道的 |= 符号,其实这个|=本人也是从来没看过,经过测试之后发现这个|=的功能,在这里是将i和 |= 后面的数进行或
运算然后再重新赋值给i。什么意思呢?举个例子。
i = 0000 0001,j = 0000 0110,那么i |= j就会先将i和j进行或操作,这里什么是或操作大家不明白可以上网搜,其实也很简单,也就是这里的二进制进行
按位进行比对,只要两个比对的位有一个为1那么结果对于的位就是1。这里按位或之后就是0000 0111,之后再赋值给i,所以i最后的值就是7。这下各位
小伙伴明白了吧。让我们再来看看这个highestOneBit(int i)为什么要这么设计?
我在讲解之前先问大家几个问题。
请分别回答出0001 0000,0000 1000,0000 0100,0000 0010,0000 0001 这几个二进对应的十进制?
很简单,就是代码里面的16,8,4,2,1。很巧吧,别急,下面阿波来一一讲解。
我们先不管那么多,先假设一个二进制为i = 000001****...,咱先不管他有多少位,也不管那个*代表什么,我们就看那个1。请先进行下面操作。
1)i >> 1,右移动一位,i >> 1 = 0000001****...,很简单吧。
在进行 i |= (i >> 1)。我们由上面讲解可知,先将i与i >> i进行或。结果就是0000011***...。怎么样,原来的i的那个第一个1后面就多了个1,咱不管
他原来是0还是1,反正最后会变成1。
2)在进行i |= (i >> 2);
此时i = 0000011***...,先右移两位,000000011***...,在进行按位或并赋值给i,可以得到i = 000001111*...,我们可以看到,又多出了两个1。在这里我怕有些
人看不明白,就画了张过程图如下。附上14.jpg。
接下来,大家应该都明白了。
3)进行i |= (i >> 4),同理,先右移4位,在按位或,这里大家自己演算下,就会得到i = 0000011111111*...,多出了四个1。
后面我就不演示了,已经很清楚了。就是不断的将后面的位变位1。有些人可能会疑惑如果传进来的数转成二进制就是....0000100这样的,那移动那么多,还移动
16岂不是很没必要。是的,在你的数是这样的情况的确是没必要。其实先进行i |= (i >> 1)在进行i |= (i >> 2)之后这个i就已经是....0000111了,后面在怎么
操作都不会对i有任何改变。但是你要知道,这个传进来的i是个int类型,32位,如果很大呢,1在很高位呢,那就是吧。所以我们也很容易知道,仔细看看就知道。
1 + 2 + 4 + 8 + 16 = 31,这保证了如果你最高位在第32位,我照样能将后面的31位变为1。
好,那么我们就很清楚了。
之后再进行return i - (i >>> 1)这个操作。
将i先右移一位,我们假设传进来的i就是10(十进制),对应的二进制为....0000 1010(前面省略24个0),那么经过上面的一系列又是右移又是或的操作之后
i=....0000 1111(前面省略24个0),(i >>> 1) == ....0000 0111,然后i - (i >>> 1) 等于什么呢?很简单,那就是....0000 1000。再看看他和10是什么关系。
这是个8,有些人肯定说,不对啊,不是求大于等于i的最小2次幂数吗,哈哈,其实在这个方法里,他是计算出小于等于这个i的最大二次幂数。其实,阿波直接
跟大家说了,求大于等于的是roundUpToPowerOf2,而Integer.highestOneBit(int i)大家没记错应该是这个roundUpToPowerOf2里面调用的,这是个求小于等于...的。
我们再来看,那么我们假设我们传进去的是16和10,那么经过这个Integer.highestOneBit(int i),就会分别返回,16和8。别急。关键的地方来了。
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;就是这句,传入的是16和10,我们知道应该计算出来的是16和16(大于等于16和10的最
小二次幂数都是16)。我们来仔细看看这句Integer.highestOneBit((number - 1) << 1)。很迷惑,他并没有直接将16和19传进去。而是先减一再左移动,这又是
什么魔鬼操作,其实左移一位想告诉大家的就是,左移一位可以理解为乘以2。当然可能会益处,但是在这里一般都不会溢出,那就先这样理解就是乘以2。所以传进去的是
16和10,那么减一乘以2就是30和18。
这里为什么要减一呢?
如果不减一,那么传进去是16,16 * 2 = 32,按照我们上面的分析,他经过Integer.highestOneBit(int i)就会返回一个32,很显然不正确。所以减一就是防止这种边界错误的
发生。所以30和18传进去之后返回的就是16和16。这里我们就已经搞清楚了这个roundUpToPowerOf2(int number)函数了。
我们再回过头来看这个inflateTable函数。

所以,如果传进去的是16和10,那么capacity最后就等于16和16。
阈值在这里,我也让大家记了下,他在这里已经是容量乘以加载因子了。我们看到这里就创建了一个大小为capacity的Entry数组。下面的initHashSeedAsNeeded(capacity);我们
就先不探究了,到了这一步已经可以了。
我们再来回顾put方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);//已经初始化好了那个Entry数组
}
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
我们先来看看这个key为null的情况,这个时候会执行到putForNullKey(value)函数。我们追进去看一下。

在这里我们看到了,那个for循环以及for循环里面的Entry
信息,我key为null的永远放在table数组的第一个位置。因为这个第一位置可能也不只是只有key为null的键值对,可能
也有其他的,这个key为null可能在这个链表的某一个位置。

可以知道key,value最后被封装到Entry里面了,当然里面还有key的hash,以及下一个Entry指针。所以在底层存的也是一个链表。
我们在来看看这个for循环,就是遍历这数组上下标为0的对应的那个位置,如果有链表就遍历链表,直到找到了一个key也为null
的数据,然后使用e.value = value;进行新值替换。最后return oldValue;返回旧值。但是如果没有找到,这就说明还没有key为
null的数据。这个时候就会调用addEntry(0, null, value, 0);方法进行添加。在addEntry方法中,有一个resize()函数是关于扩容
的,我们待会再来讲解。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
我们在回到最初的那个调用putForNullKey(value)函数的地方。回到了put函数。我们上面走到了key为null的逻辑里面。
可以知道,无非就是遍历下标为0的地方是不是已经有key为null的元素,有就替换旧值,并返回旧值。没有就代表首次
添加,于是调用addEntry(int hash, K key, V value, int bucketIndex)函数进行添加,这个函数我们后面讲。
我们知道,如果没有执行putForNullKey(value)函数,就说明传进来的key不为null。就会调用key的hash方法int hash = hash(key);
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
hash函数为什么又是右移又是抑或的进行操作,这里我们不需要知道那么多,面试的时候直接说返回的hash不是key原本的hash就行了,当然
后面我也会进行解释为什么要这样操作。总之,大伙记住,返回一个hash。
hash(key)方法之后得到了key的hash值。就接着调用int i = indexFor(hash, table.length);函数。得到hash是为了什么?就是为了得到一个
唯一的下标值,而这个indexFor函数正是求得下标i的函数。
static int indexFor(int h, int length) {
return h & (length-1);
}
我们很容易就能看到,这个传进来的hash和底层数组的长度减一进行与运算。
为什么要这么操作?
大家想想,一个这个indexFor(int h, int length)是不是要至少满足两个条件,一个是能够返回0~table.lengt - 1的所有可能值。二是能够随机的
返回其中一个值,这样才能代表下标。
好,那么hash是一个32位整型值,假如length为16。那么减一之后的二进制就是00000001111。这个值与hash进行与运算。
如果hash为 0011011010,那么。
00000001111
(与)
10101011010
(result)
00000001010
这个结果就是和那个hash值的低四位相同。至于为什么用与,因为与操作非常快。而且低四位是什么,产生的下标i就会是多少。这里i的返回值可能是
0~15之间,刚好如果数组table的长度为16,那么其下标就是0~15。看到这里大家就清楚了吧。这也说明了为什么在inflateTable里面这个table数组的
容量会被初始化成一个2的幂次方?在这里与之呼应。2的幂次方-1得到的低位就全是1,与hash的低位进行与运算就能刚好返回 0~table.length-1中间
的下标值,而且由于hash是随机的,那这个下标也会是随机的。
上面我们说了为什么一个hash要进行那么多操作之后才返回。大家看看下面的解释。
如果是直接使用key的hash的话,会遇到一个问题。那就是在indexFor里面计算下标的时候使用到低位,不同的hash的高位差异不会对结果造成影响。同样
以数组长度为16。
hash 0011011011 0011 和 hash 001001100010 0011 得到的下标结果是一样的,这样hash就很容易冲突。所以我们需要让高位也能全部影响到最终结果。
于是就进行了右移和抑或操作。
看完了indexFor(hash, table.length),下面我们就得到了下标i,也知道了这个key,value要存在数组的哪个位置了。但是这个位置可能对应的又是一个链表。
于是又是进行for循环查找相同并替换,然后返回旧值。
for (Entry
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
我们可以看到e.hash == hash && ((k = e.key) == key || key.equals(k))这一句,这一句代码说明了什么情况下算作两个key是同一个key。
我来详细说说。
1)首先if要返回true。必须e.hash == hash为true和((k = e.key) == key || key.equals(k))为true。
在一般情况下,同一个对象比如:User user = new User("zhangsan",12),他的hashCode一直是不变的。
如果执行下面代码:
①map.put(user,"nihaoa"); ②map.put(user,"hello")
那么①中的user先存到一个下标为i的位置,②这里的user的hash肯定和他一样,然后操作之后hash也和他一样,然后得到的下标i也和他一样,最后
的结果在执行②的时候就会一路执行到这个if判断。此时当②加入user的时候会遍历①中加入的user所在的那个链表。假如已经遍历到了①中加入的user。
此时e.hash == hash肯定为true。然后k = e.key) == key || key.equals(k)也会为true(因为为同一个对象)。于是新值替换旧值e.value = value。
2)我们此时是同一个对象user,那我们此时加入的对象如果不是同一对象会怎么办,就比如下面。
User user1 = new User("lisi",12);
User user2 = new User("lisi",12);
map.put(user1,"aaaa");map.put(user2,"bbbbbbb");
在不重写User对象的hashCode()方法的时候,这两个对象返回的hashCode在大概率情况下是不同的,虽然有可能相同,但是一般是不同的,因为不是同一个
对象(==判断返回false)。
而且如果不重写equals的时候,使用的是Object的equals那么判断就是使用==比较地址,那更不可能相等。 而在我们的印象里,这种情况下user1和user2虽然
不是同一个对象,但是在添加的时候应该视为同一个对象。
我们在走走1)中的逻辑。e.hash == hash会返回false,(k = e.key) == key 返回flase, key.equals(k)其实和哪个==判断一样,也返回false,整体返回flase,
结果就是if里面不执行,不会进行替换,这是不符合我们逻辑的,这两个人本来名字和年龄都一样,应该是同一个人,结果却添加了两次。
所以这也说明了我们在编写User的时候应该重写其hashCode和equals方法。这也当所有属性相同的时候,hash值是一样的,equals返回的也是true。所以if判断
就会返回true,重而同一个人不能重复添加。
说了这么多,到了最后的一个方法了,addEntry(hash, key, value, i)。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
在addEntry里面传进来key的hash,key,value,还有下标bucketIndex。
走到这一步说明了下标i处不是一个链表或者下标i处是一个链表,但是没有找到相同的key。
if ((size >= threshold) && (null != table[bucketIndex])):这句是扩容的条件。这个size是已经添加到HashMap中的元素的个数。
我们很容易可以看到,当然HashMap中的元素个数大于等于阈值并且下标i处是一个链表才会进行扩容。这样做也是怕链表过长而影响
查找时的效率。很多网上说等于等于阈值就扩容,在这里可以看到,还要添加的那个i位置是一个链表才行。
接下来,深究这个扩容核心代码resize(2 * table.length);我会画图给大家展示。
首先,记住一点,扩容时传进去的是数组大小的两倍,假如数组长度4,那么传进去就是8。(太长了图不好画)
void resize(int newCapacity) {
Entry[] oldTable = table; ①
int oldCapacity = oldTable.length; ②
if (oldCapacity == MAXIMUM_CAPACITY) { ③
threshold = Integer.MAX_VALUE; ④
return;
}
Entry[] newTable = new Entry[newCapacity]; ⑤
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1); ⑥
}
这个resize方法很巧妙,因为他实现了链表减短的操作,让我们看看如何实现的。
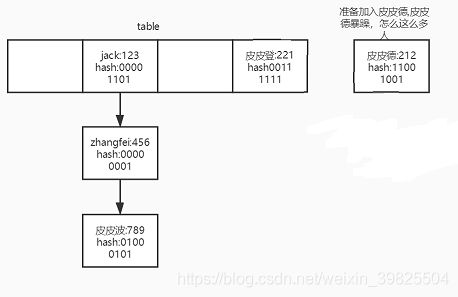
从图中可以看出,阈值为0.75 * 4 = 3。未加入皮皮德之前,size = 3。
开始准备加入皮皮德。加入皮皮德也要加入到jack在的那个位置。
addEntry中的if ((size >= threshold) && (null != table[bucketIndex]))得以满足,所以进行扩容。当然如果是加在皮皮登的前面就
不要扩容了。
假如一直执行到了⑤,然后下面的transfer是进行旧数组元素向新数组元素的迁移。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry
while(null != e) {
Entry
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
在这个transfer,先是一个for遍历所有的下标位置,然后一个while遍历某个下标位置的链表。我们来一步步看图。一般情况下那个rehash是
不会执行的,我们就认为不会执行。直接走indexFor(e.hash,newCapacity);这里的旧数组元素转移到新数组上,如果存在链表,则链表采用的
是头插法。这里面在单线程下是没有问题,单在多线程下会出现循环链表,而且可能还会丢失数据,问题很大。
下面我给大家附上transfer模拟图,在这里有两点需要说明,一点是大家要记住数组中存的并不是真正的堆中对象,而是对象的引用就行了,其实
也不妨碍看图,只是大家有这个概念就行。
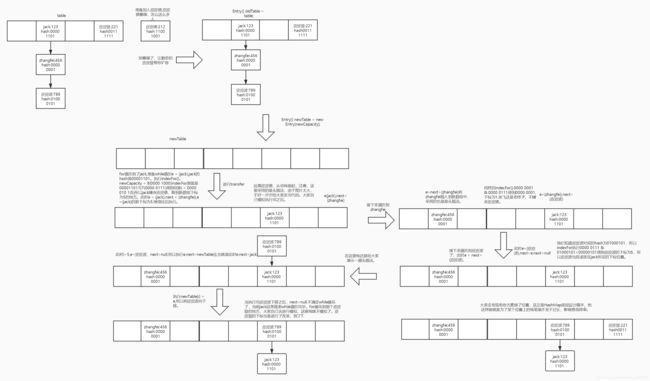
当这个transfer执行完之后,我们又拉回到resize函数,之后执行table = newTable;threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
就是将HashMap中的table数组重新指向那个新创建的数组,此时数组中已经有了元素了,然后在重新计算阈值。resize执行完毕,我们再回到addEntry。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
我们假设addEntry里面加入的就是皮皮德,一切状态都跟我们上面画的图那样。
从代码中可以看出,此时已经扩容完成了,这个扩容我还要说一句,注意他的条件并不是HashMap的元素(包括链表)个数达到阈值就扩容,还有后面的条件。
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
这两句代码会算出皮皮德在新数组中的下标,很简单为1100 1001 & 0000 0111 = 0000 0001,可以看到zhangfei的那个位置。
之后执行createEntry(hash, key, value, bucketIndex);
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
这里面的table[bucketIndex] = new Entry<>(hash, key, value, e);也就是头插法,大家自己模拟吧。然后添加成功,size++;
在回到put方法的时候,return null,一个元素就添加完毕。
总结:
1)执行map.put(key,value)
2)判断底层table是否为空,数组如果还为空,则执行inflateTable初始化,初始化的时候会执行roundUpToPowerOf2,roundUpToPowerOf2里面会执行
Integer.highestOneBit进行初始化,这个Integer.highestOneBit是返回一个小于等于。总之最后返回的是大于等于容量的2的幂次方,这个容量可能
是默认的16,也可能是用户传进来的。
3)如果不为空,或者初始化数组已经执行完,执行hash获得key的非真实hashCode,然后执行执行indexFor得到添加元素的下标。然后再遍历这个下标所在
位置的链表(如果存在),看是否待添加元素已存在于链表中,存在则覆盖且返回旧的值,这个存不存在是根据key来判断的,所以说key不能重复,返回
的值是旧key对应的value。
4)如果不存在于链表中,则执行addEntry进行添加,addEntry里面可能视情况而调用resize进行扩容。
5)如果扩容执行resize,那么扩容完之后就会执行transfer进行旧数组元素向新数组元素的转移。之后在回到addEntry重新计算key的hash并调用createEntry
(hash, key, value, bucketIndex);函数进行元素的添加,添加的时候都是采用的头插法。不管在扩容转移的时候还是真正添加的时候都是采用头插法。
6)如果不扩容则直接调用createEntry函数进行元素的添加。在具体添加元素的时候都是封装成一个Entry对象。