你是什么鬼?
leveldb : 老子是一个单机的KV数据库,适合写多读少,支持持久化,支持故障恢复,咋样,牛逼吧?
我:听不懂!
leveldb : 老子就是一个main函数,管理一堆文件,给你存数据读数据!
我:哦!
开篇来个简单傻逼的对话,不过却道出数据库的本质。数据库就是以格式化数据存储起来然后提供增删改查功能而已,只不过数据量大了之后事情变得有点复杂。那么leveldb也是这样一个东西。leveldb提供的是KV格式的存储,支持二进制数据,那么leveldb是如何实现的这个的呢?
让我们从上层开始讲起!
数据之旅
既然是KV数据库,那么开始我们肯定会有个叫DB的对象。这个叫DB的对象提供啥?简化可以理解三个接口:
1. DB.Put(key, value)
2. DB.Get(key)
3. DB.Del(key)
简单吧!这让你想起啥?HashMap!对,一样的功能,却复杂了千百倍。要实现一个完善的数据库系统,还需要考虑很多东西,例如数据格式,例如持久化,例如高性能。当然,这些接下来慢慢聊,我们可以暂且忘记这么多烦恼,先记得这个HashMap的简单玩具雏形。
这三个简单的接口下面有啥啥东西?这时候应该用一张图说明:
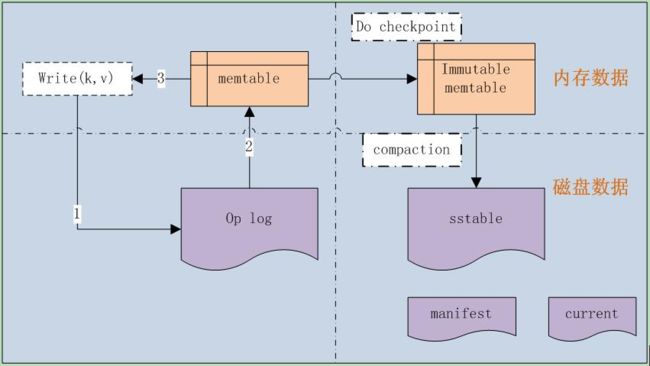
当我们写入一个KV数据的时候,KV会经过三个
table和一个log。
写入数据的流程是
- KV写操作会写到
log文件中,顺序写,做持久化(系统崩溃会从log文件中恢复,log文件也是按照一定格式的二进制数据)- 写到log文件中后会写入
memtable(一个叫跳跃表的数据结构)- 之后write操作就返回成功了。
经过上面几步我们可以保证数据一定不会丢失了,内存memtable丢失的数据会读取log的操作记录重跑一遍,数据就恢复了。但是接下来数据还会被持久到磁盘中。
- 当memtable的大小达到一个上限,那么memtable会变成
Immutale memtable。这两个table的数据结构是一样的,都是跳跃表,只不过后者是只读的。- 这时候会产生一个新的memtable来支持新的写操作
- Imutable memtable的内容会定期刷到磁盘,然后清楚对应的log文件,生成新的log文件。
- 磁盘中数据的存储格式叫sstable。
由上面七步我们知道数据经历了memtable, imutable memtable, sstable三个table。数据的存储格式几乎说明了整个数据库的精髓,所以这三个数据结构后面都会详细讲解!现在我们先感性认识一下数据流程以及leveldb如何保证数据持久化的。
leveldb: 那么现在可以回答数据持久化是如何实现的吗?
我:嗯,好像跟一个log文件有关!
leveldb: 对头,一次写KV操作需要一次磁盘的顺序写(log文件)和一次内存写(写入metable),所以写效率是非常高的。如果内存中数据丢失,我们会读取log文件的操作指令重跑一遍,数据就可以恢复了。当KV数据到达sstable之后,旧的log文件会被删除并且产生新的log文件。所以我们可以保证数据不丢失!
为啥叫leveldb?
还记得我们上面讲那三个table吗?
1. memtable
2. Imuable memtable
3. sstable( Sorted String Table)
其中1和2都是跳跃表,然而我们还没讲到3sstable是什么数据结构?sstable什么鬼?就是传说中google三大论文之一的Bigtable中的那个sstable。这个东西大概长这样:
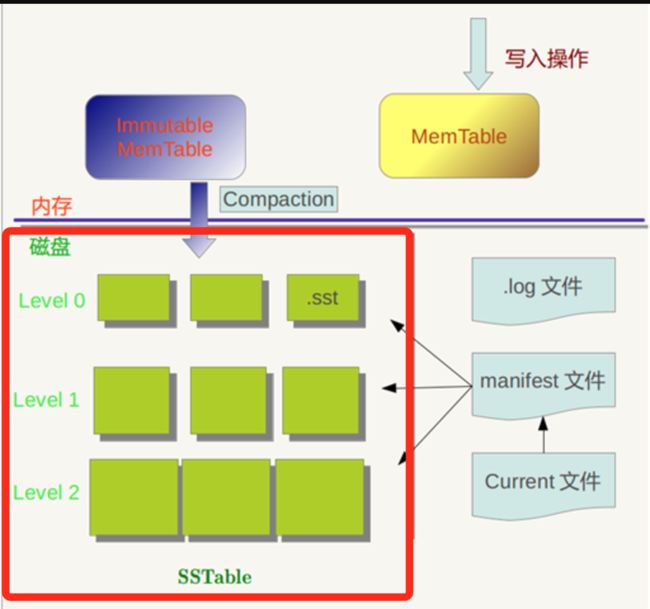
图中红色框部分就是他的样子。
level0是由Imuabletable memtable直接dump到磁盘中的,level1是由level0经过compaction获得,level2是由level1经过compaction获得,以此类推。其中每个文件后缀为.sst, 每个level中的文件数都是有限制的,超过了限制则会被compaction到更高level的层次上去,所以这个东西叫leveldb。其中每一个level符合以下规则:
1. level0中的单个文件(sst)是有序的,但是文件与文件之间是无序的并且有可能有重合的key
2. level 1 ~ level n 每一个level中在自己level中都是全局有序的
3. mainifest文件中包含了每一个sst文件的最小key和最大key,方便查找
上面只是简单讲解以下整体结构,后面会深入其细节。但是在那之前,先建立一个宏观感受是非常重要的。
读
前面我们讲解了数据的存储整体结构,那么理解数据是怎么被查找的就非常简单了。查找依次经过:
1. memtable
2. Imuable memtable
3. level 0
4. level 1
......
上面步骤非常清晰。首先查找会先经过memtable查找,找不到就依次按顺序往下找,一直找不到就返回empty了。当然,中间有很多细节优化,这里先不深入去理解,例如会通过布隆算法过滤掉不存在的key。后面讲到filter的时候会深入讲解。
删除
数据库的数据当以一种格式化存储在一起,要删掉某部分就要移动剩下部分往前移动,这是代价很大的。所以:
leveldb没有实际的删除操作,就是write一个删除标记和key进去
啥意思?我们都知道所有key的插入都是时间有序的,从memtable到level n一路飞奔,从不回头。
所以我们假如我们添加了key为name, value 为戈风的数据进去之后,我们要删除key为name的记录,我们只需要再插入一条 name del(标志),这样我们查找的时候就会先遇到name del表示key已经被删除,返回empty。
除了这个时间有序之外,在level n compaction到level n + 1的时候如果发现有删除的key,这时候就会真正删除它。
尾记
从前面的讲述,我相信我们应该心中对leveldb有了一个大概的印象,下面我们会慢慢把印象具体起来,把细节丰富出来,构造一个3d立体的理解结构。那么,前面涉及到了几个leveldb的模块呢?
1. memtable
2. Imuable memtable(其实我跟1是亲兄弟啦)
3. sstable
4. log
5. filter
这几个模块就是leveldb的重中之重了。在有了一个大框架之后,我们需要进入一点细节了。好了,本章到此为止!