此文是关于elasticsearch in action书部分重点读书笔记。
Chapter 2 Diving into elasticsearch
- 逻辑布局:用来索引和搜索的是一个Document,可以认为是一个行在关系数据库。Documents分组成类型,包含Documents的方式类似表格包含行。一个或多个types在一个index,类似数据库在SQL。
- 物理布局:es划分每个index成为shards,可以在服务器间migrate组成一个cluster。

2.1 理解逻辑布局:documents,types,indices
当你index一个文档在es,你把它放在一个type在一个index里。
- ID 实际上是string
- index-type-ID独特地鉴别一个document在es设置。
- types是documents的逻辑容器,类似表格是行的容器。你会把不同结构的documents放在不同types。
- fields的定义在每个type是一个mapping。
- Indices是mapping types的容器。一个es index是documents的独立chunk。每个索引存储在磁盘上在文件的相同集合中。
每个index存储在文件的相同集合在磁盘上。存储所有域从所有映射类型,每个有自己的设置。
可以搜索跨types,也可以搜索跨indices。
2.2 理解物理布局:nodes和shards

- 一个节点是一个es的instance。可以有多个节点在相同服务器上通过起多个es进程。
多个节点可以加入相同cluster。有一个cluster有多个节点,相同数据可以被扩展在多个服务器上。
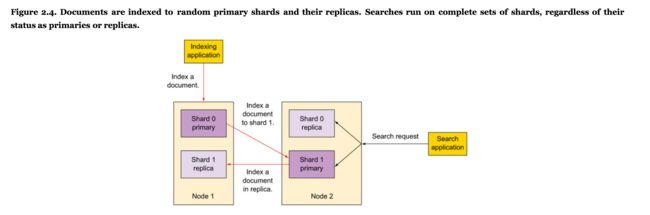
- 理解primary 和 replica shards
一个shard是一个lucene index:一个文件目录包含一个inverted index。an inverted index是一个结构允许es告诉你那个文档包含哪个term(一个单词)不用查找所有单词。
elasticsearch index vs. lucene index
一个es index被分解成chunks:shards。一个shard是一个lucene index,因此一个elasticsearch index由多个lucene indices组成。
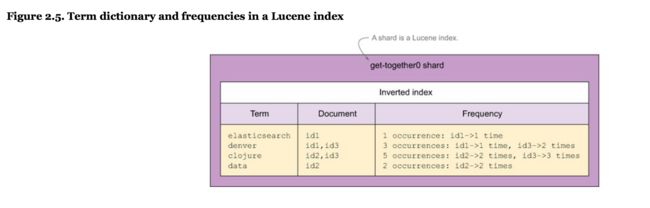

2.2.3 分布shards在一个cluster
最简单的es cluster只有一个节点。
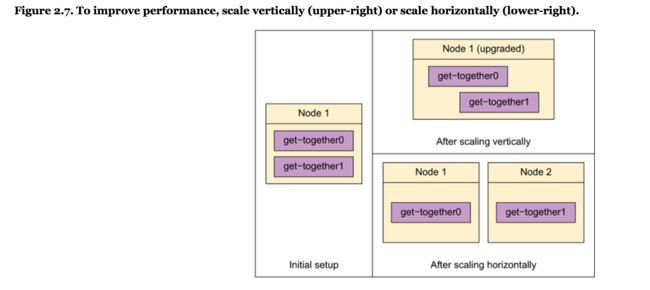


默认,primary 和 replica shards击中用round-robin算法。也可以组织数据或配置shards来组织更慢的节点变成一个瓶颈。
2.3 indexing new data

man curl 来看关于curl的帮助信息
- -X PUT 和-XPUT都可以,有没有空格的区别
- uri,我们跳过额协议,默认是http
- around uri放置了单引号划分参数用&
- 数据通过http传输典型是JSON,包围它用但幸好因为JSON本身包含双引号。
如果你喜欢图形界面,可以用几个工具
- elasticsearch head:可以发送http 请求,head最有用是监管工具,展示shards如何在cluster分布
- Elasticsearch kopf
- Marvel
2.3.2 创建index和mapping type
- 手动创建一个index
% curl -XPUT 'localhost:9200/new-index' - 查看当前所有mapping
http://localhost:9200/singulariti/_mapping/?pretty - 查看某个type的mapping
% curl 'localhost:9200/get-together/_mapping/group?pretty'
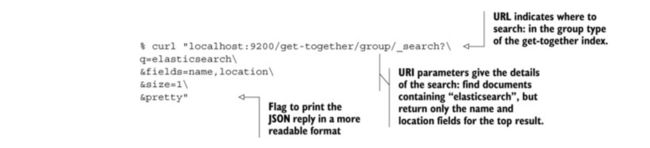
如果想要在特定field运行,比如q=name:elasticsearch。
实际上,es默认用field:_all,所有field的内容都被index。
一个搜索的三个重要方面:
- 在哪里搜索:
搜索在多个types:
% curl "localhost:9200/get-together/group,event/_search\ ?q=elasticsearch
中间用,分开 - 如果你指定在某个index搜索,但是该index不存在,会报错。可以增加ignore_unavaliable flag。
- 要在所有indices搜索,可以直接不用index的flag:
curl 'localhost:9200/_search?q=elasticsearch&pretty' - 如果你需要搜索所有indices的某个type,可以指定indices是_all
- 需要回复的内容
- what & how to search
2.4.2 回复的content

默认搜索timeout时间是永久不timeout,但可以指定timeout时间
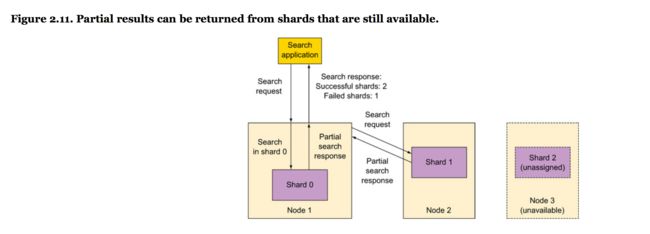
document的score默认用TF-IDF (term frequency-inverse document frequency)算法。
默认,es限制返回的数目是10,用size参数改变返回结果的数目。
每个匹配文档有它的index和type,ID,分数。
如果你不想指定显示什么域,_source域被用。
也可以用source filtering.
setting query string options
- 默认es用_all field。如果你想看group name,可以用"default_field":"name"
- 默认操作子是OR
"default_operator":"AND"
修改的query看上去如下:
% curl 'localhost:9200/get-together/group/_search?pretty' -d '{
"query": {
"query_string": {
"query": "elasticsearch san francisco",
"default_field": "name",
"default_operator": "AND"
}
}
}'
另一种方式是指定field和操作子在query string本身:
"query": "name:elasticsearch AND name:san AND name:francisco"
- 为了返回所有活动组织者,可以用term aggregation
"aggregations" : {
"organizers" : {
"terms" : { "field" : "organizer" }
}
}
}'
2.4.4 getting documents by ID
要获取某个特定document,必须知道它属于的index,type,ID。
% curl 'localhost:9200/get-together/group/1?pretty'
{
"_index" : "get-together",
"_type" : "group",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"name": "Denver Clojure",
"organizer": ["Daniel", "Lee"]
….
2.5 配置es
- 指定cluster name in elasticsearch.yml
这是es-specific选项的主要配置文件。 - 编辑logging options 在logging.yml
- 调整memory settings 在环境变量在elasticsearch.in.sh
默认,新的节点发现存在的clusters通过多播——发送ping到所有的主机监听特定multicast address。如果一个cluster被发现,新的节点加入它如果它有相同的cluster名字。你需要自定义cluster名字放置默认配置的实例加入到cluster。改变cluster name:
cluster.name:elasticsearch-in-action
改变cluster名字后,重启es。
如果改变cluster ,原来索引数据不存在。
2.5.2 指定verbose logging通过logging.yml
elasticsearch log 入口是三种类型的文件:
- main log:(clustername.log):可以找到es运行的一般信息;一个query是否失败或者一个新的节点加入cluster
- slow-search log(cluster-name_index_search_slowlog.log)
如果一个查询超过半秒,在这里记录 - index-slow log(cluster-name_index_indexing_slowlog.log)
2.5.3 调整JVM设置
es用的绝大多数内存叫做heap。如果你的操作超过了1GB,这些操作会失败你会看到内存不足的信息。
2.6 增加节点到cluster
在增加节点前,需要检查cluster状态来可视化当前分配数据。
如果没有plugin装,可以用
% curl 'localhost:9200/_cat/shards?v'
Chapter 3. Indexing, updating, and deleting data
Chapter 3. Indexing, updating, and deleting data
3.1. Using mappings to define kinds of documents
3.1.1. Retrieving and defining mappings
curl 'localhost:9200/get-together/group/_mapping?pretty'
3.1.2. Extending an existing mapping
3.2. Core types for defining your own fields in documents
3.2.1. String
3.2.2. Numeric
3.2.3. Date
3.2.4. Boolean
3.3. Arrays and multi-fields
3.3.1. Arrays
3.3.2. Multi-fields
3.4. Using predefined fields
3.4.1. Controlling how to store and search your documents
3.4.2. Identifying your documents
3.5. Updating existing documents
3.5.1. Using the update API
3.5.2. Implementing concurrency control through versioning
3.6. Deleting data
3.6.1. Deleting documents
3.6.2. Deleting indices
3.6.3. Closing indices
3.6.4. Re-indexing sample documents
3.7. Summary
Chapter 4. Searching your data
4.1. Structure of a search request
4.1.1. Specifying a search scope
4.1.2. Basic components of a search request
4.1.3. Request body–based search request
4.1.4. Understanding the structure of a response
4.2. Introducing the query and filter DSL
4.2.1. Match query and term filter
4.2.2. Most used basic queries and filters
4.2.3. Match query and term filter
4.2.4. Phrase_prefix query
4.3. Combining queries or compound queries
4.3.1. bool query
4.3.2. bool filter
4.4. Beyond match and filter queries
4.4.1. Range query and filter
4.4.2. Prefix query and filter
4.4.3. Wildcard query
4.5. Querying for field existence with filters
4.5.1. Exists filter
4.5.2. Missing filter
4.5.3. Transforming any query into a filter
4.6. Choosing the best query for the job
4.7. Summary
Chapter 5. Analyzing your data
5.1. What is analysis?
5.1.1. Character filtering
5.1.2. Breaking into tokens
5.1.3. Token filtering
5.1.4. Token indexing
5.2. Using analyzers for your documents
5.2.1. Adding analyzers when an index is created
5.2.2. Adding analyzers to the Elasticsearch configuration
5.2.3. Specifying the analyzer for a field in the mapping
5.3. Analyzing text with the analyze API
5.3.1. Selecting an analyzer
5.3.2. Combining parts to create an impromptu analyzer
5.3.3. Analyzing based on a field’s mapping
5.3.4. Learning about indexed terms using the terms vectors API
5.4. Analyzers, tokenizers, and token filters, oh my!
5.4.1. Built-in analyzers
5.4.2. Tokenization
5.4.3. Token filters
5.5. Ngrams, edge ngrams, and shingles
5.5.1. 1-grams
5.5.2. Bigrams
5.5.3. Trigrams
5.5.4. Setting min_gram and max_gram
5.5.5. Edge ngrams
5.5.6. Ngram settings
5.5.7. Shingles
5.6. Stemming
5.6.1. Algorithmic stemming
5.6.2. Stemming with dictionaries
5.6.3. Overriding the stemming from a token filter
5.7. Summary
Chapter 6. Searching with relevancy
6.1. How scoring works in Elasticsearch
6.1.1. How scoring documents works
6.1.2. Term frequency
6.1.3. Inverse document frequency
6.1.4. Lucene’s scoring formula
6.2. Other scoring methods
6.2.1. Okapi BM25
6.3. Boosting
6.3.1. Boosting at index time
6.3.2. Boosting at query time
6.3.3. Queries spanning multiple fields
6.4. Understanding how a document was scored with explain
6.4.1. Explaining why a document did not match
6.5. Reducing scoring impact with query rescoring
6.6. Custom scoring with function_score
6.6.1. weight
6.6.2. Combining scores
6.6.3. field_value_factor
6.6.4. Script
6.6.5. random
6.6.6. Decay functions
6.6.7. Configuration options
6.7. Tying it back together
6.8. Sorting with scripts
6.9. Field data detour
6.9.1. The field data cache
6.9.2. What field data is used for
6.9.3. Managing field data
6.10. Summary
Chapter 7. Exploring your data with aggregations
7.1. Understanding the anatomy of an aggregation
7.1.1. Structure of an aggregation request
7.1.2. Aggregations run on query results
7.1.3. Filters and aggregations
7.2. Metrics aggregations
7.2.1. Statistics
7.2.2. Advanced statistics
7.2.3. Approximate statistics
7.3. Multi-bucket aggregations
7.3.1. Terms aggregations
7.3.2. Range aggregations
7.3.3. Histogram aggregations
7.4. Nesting aggregations
7.4.1. Nesting multi-bucket aggregations
7.4.2. Nesting aggregations to get result grouping
7.4.3. Using single-bucket aggregations
7.5. Summary
Chapter 8. Relations among documents
8.1. Overview of options for defining relationships among documents
8.1.1. Object type
8.1.2. Nested type
8.1.3. Parent-child relationships
8.1.4. Denormalizing
8.2. Having objects as field values
8.2.1. Mapping and indexing objects
8.2.2. Searching in objects
8.3. Nested type: connecting nested documents
8.3.1. Mapping and indexing nested documents
8.3.2. Searches and aggregations on nested documents
8.4. Parent-child relationships: connecting separate documents
8.4.1. Indexing, updating, and deleting child documents
8.4.2. Searching in parent and child documents
8.5. Denormalizing: using redundant data connections
8.5.1. Use cases for denormalizing
8.5.2. Indexing, updating, and deleting denormalized data
8.5.3. Querying denormalized data
8.6. Application-side joins
8.7. Summary
Chapter 9. Scaling out
9.1. Adding nodes to your Elasticsearch cluster
9.1.1. Adding nodes to your cluster
9.2. Discovering other Elasticsearch nodes
9.2.1. Multicast discovery
9.2.2. Unicast discovery
9.2.3. Electing a master node and detecting faults
9.2.4. Fault detection
9.3. Removing nodes from a cluster
9.3.1. Decommissioning nodes
9.4. Upgrading Elasticsearch nodes
9.4.1. Performing a rolling restart
9.4.2. Minimizing recovery time for a restart
9.5. Using the _cat API
9.6. Scaling strategies
9.6.1. Over-sharding
9.6.2. Splitting data into indices and shards
9.6.3. Maximizing throughput
9.7. Aliases
9.7.1. What is an alias, really?
9.7.2. Alias creation
9.8. Routing
9.8.1. Why use routing?
9.8.2. Routing strategies
9.8.3. Using the _search_shards API to determine where a search is performed
9.8.4. Configuring routing
9.8.5. Combining routing with aliases
9.9. Summary
Chapter 10. Improving performance
10.1. Grouping requests
这部分介绍是读第一遍时候阅读。
- 搜索引擎的综述,可以用来解决什么问题。
- 关于主要功能介绍:索引文档,搜索,分析数据通过聚集,缩放到多个节点。
- 索引时的选项,更新,和删除数据。你可以学习到什么类型数据你可以有在你的Documents中,什么发生当你写它们。
- 深入到全文本搜索。你会发现查询的重要类型,filters,它们如何工作和何时用它们。
- 如何分些文本从查询和文本中用来搜索。你会学习如何用不同类型的analyser-你如何建立你自己的analyser-为了完全实现es的全文本搜索能力。
- 帮助你完成全文本搜索能力聚焦在相关性上。你会学习因子影响文档的分数如何操作他们用不同得分算法,boosting一个特别的查询或域,或用文档值本身——比如喜欢或转发的树木——来加速得分。
- 展示如何用聚集来完成实时分析。你会学习如何去耦合聚集在查询中,如何嵌套它们为了在haystack找到needle。
- 处理关系型数据,比如bands和albums。会学习如何用es特征-比如嵌套文档和父子关系-和一般的nosql技术(比如去正交化和应用层连接)来索引和搜索数据不稳的。
第二部分帮助你理解核心功能到声场。需要学习每个特征如何使用,和在性能和缩放性上的影响。
- 处理缩放到多个节点上。如何shard或者复制索引——oversharding或者基于时间索引。
- 挤压cluster更多性能。es如何用缓存写数据到磁盘。
- 如何监管数据在production中。
Chapter 1.Introducing elastic search
- 理解搜索引擎和遇到的问题
- es如何适应到搜索引擎的上下文
- es的典型场景
- es提供的特征
- 装es
1.2 确保相关性结果
相关性得分,简单就直接排序。默认用来计算文档相关性的算法叫做TF-IDF。代表术语frequency-inverse document frequency,两个因子影响相关性得分
- term frequency
- inverse document frequency-每个单词的权重更高如果这个单词在其它文档不常见
1.2.1 用es作为主要的后端
传统上来说,搜索引擎建立在很好建立的数据仓库中来提供快速的和相关的搜索能力。因为历史搜索没有提供可持续存储或者其它需要特征,比如统计学。
es是可以提供可持续存储的一个现代例子。推荐用es作为唯一的数据仓库。
和其它nosql数据仓库类似,es不支持交易。在第三章,会找到如何用版本来控制并发,但是如果需要transaction,考虑用另一个数据库作为真实源。
1.2.4 主要es特征
es允许你方便获取lucene的功能用来索引和搜索数据。在索引段,有很多选择如何处理文本和如何存储处理后的文本。当搜索时候,有很多查询和filters来选择。es暴露了很多这样的功能通过rest api,允许你结构化查询在json,调整绝大部分配置通过相同的api。
在lucene之上,es提供它高层功能,从缓存到实时分析。在第七章,你会学习如何做这些分析通过聚集,给你结果比如最受欢迎blog tags,特定组的post的平均受欢迎程度,无穷尽的结合比如post对于每个标签的受欢迎程度。
另一个层次的抽象是你可以组织文档的方式:多个索引可以分开或一起搜索,你能放置多个类型的文档在一个索引中。
最后,es是弹性的。它是clustered的,你能叫他一个cluster即使你允许在一个单独的server上—你可以增加更多的服务器来增加capacity或者容错率。
1.2.5 扩展lucene能力
es一个显著特征是它是很好结构化的rest api。你也可以看到用filters来包括或者排除结果在一个便宜的和可缓存的方式。json搜索可以包括查询和filter,和聚集,产生统计学从匹配文档中。
通过相同rest api你能读取和改变很多设置,和文档索引的方式。
apache solr
是一个开源的,分布式搜索引擎基于lucene。
1.2.6 在es中结构化数据
Chapter 2. 深入了解功能
- 定义文档、类型和索引
- 理解es节点,primary和replica shards
- 索引文档用cURL和一个数据集合
- 搜索和获取数据
- 设置es配置选项
- 和多个节点同时工作
所有操作都会用cURL完成,一个简单命令行工具对于http请求。通过这一章,你可以做一些配置改变和开启es的新实例,可以体验多个节点的cluster。
开始描述数据组织。为了理解数据如何在es组织,看如下两个方面:
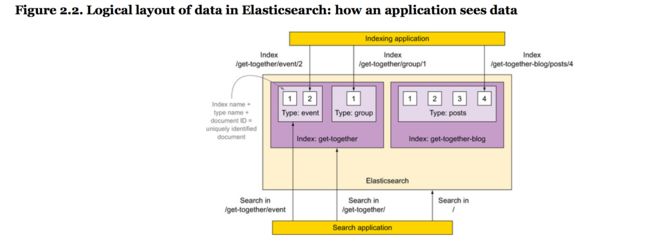
- logical layout-你的搜索应用需要意识到什么。用于索引和搜索的单元是文档,你可以认为他是关系数据库的一行。文档分组成类型,包含文档在一个方式类似表格包含行。最后,一个或多个类型在一个index下,最大的容齐,类似于sql的数据库。
- 物理布局
es如何在后台处理数据。es划分数据成shards,可以在服务器间迁移来做成一个cluster。通常来说,应用不关心这因为他们和es工作在相同方式,不管他是一个还是多个服务器。但当你管理集群,你关心因为你配置物理布局的方式关系到性能、可缩放性和可提供性。
2.1 理解逻辑布局:文档、类型和索引
当你在es索引一个文件,你放置一个类型在一个index中。types包含documents。index-type-ID 结合独特性鉴定一个文档在es设置中。当你搜索,当你搜索时,你能查看documents在那个特点类型中,或者跨越多个type,甚至多个indices。
2.1.1 Documents
es是面向文档的,索引数据的最小单元是documents。一个文档有若干重要属性:
- 自包含的:包含fields(name)和values.
- 可以是多层次的:documents within documents。
- 是弹性化的结构
一个document经常是数据的json代表。json通过http是最常用的方式来和es交互。document在es是schema-free,每个域的类型还是重要的,es保持一个映射你所有的域和他们类型和其它设置。这个映射是特定的对于每个索引的每个类型。这是类型有时叫做mapping types的原因在es术语中。
2.1.2 Types
类型是文档的逻辑包含器,类似于表格是行的容器。
当你搜索域不是在json document的root上,必须指定路径。
新域的自动检测有负面影响因为es可能猜错了。安全的方式是定义映射在索引数据前。
映射类型只在逻辑上划分文档。物理上,文档从相同索引写到disk不管他们属于什么映射类型。
2.1.3 indices
indices是映射类型的容器。es映射是文档的独立块,很像关系数据库:每个索引存储在disk,在相同文件集合中。存储所有域从所有映射类型在那里,有自己的设置。举例,每个缩影由一个设置叫做refresh_interval,定义了索引文档更新间隔。
index-specific设置包括了shards的数目。一个index可以有一个或多个chunk叫做shard组成。这对scalability很好,可以运行es在多台服务器上,相同索引的shard在他们上都有。看如何es的shard工作。
2.2理解物理布局:nodes和shards
2.3索引新数据
- 用cURL插入数据
- es如何自动创建索引和类型你的文档属于如果他们不存在
2.3.1 索引一个文档用cURL
对于这本书大多数片段,用cURL snippets.cURL是一个命令号工具用于传输数据基于http。用curl命令来做出http请求,成为一个惯例用cURL对于es代码片段。
有很多方式用curl发出请求,允许man curl来查看。curl使用惯例:
- method,经常是get,put,或者post是-x 参数的值。可以加空格,但是一般不加。我们用-XPUT而不是-X PUT,默认方法是GET,当用get时候,就省略了get参数。
- 在url中,跳过指定协议,我们经常有http,curl默认用http当没有协议指定。
- 用单引号,因为多个参数需要用&分开这些参数
- 数据通过http发送经常是json,用单引号包围它因为json本身包含双引号。
- 加上pretty参数让son返回值看上去更可读,不然会在一行返回
2.3.2 创建索引和映射类型
- 索引原来不在那里,没有发送任何命令创建索引叫做get-together
- 映射原来并不存在。
cur命令工作因为es自动增加get-together索引给你,也创建了一个新的映射对于类型组。这个映射包含了你的域作为字符串的定义。es可以默认帮你处理它。让你开始索引不需要任何配置,你也可以改变默认行为。
2.5 配置es
- 指定cluster名字在elastic search.yml
- 允许logging选项在logging.yml
- 调整内存设置在环境变量或者elasticsearch.in.sh
- 调整JVM设置:最重要的是多少内存允许它用。选择正确的内存设置对于es的表现和稳定性是很重要的。
绝大部分内存被es用叫做heap。默认设置对于heap是256M,可以增加到1G。
Chapter 3. 索引,更新和删除数据
- 用映射类型来定义文档的多个类型在相同索引下
- 在映射中可用的域的类型
- 用预先定义的域和它们的选项
- 所有以上可以在索引中其帮助,包括更新和删除数据
这章节主要包括让数据进出es。
看域的三种类型:
- Core:这些域包括字符串和数字
- 数组和多域:这些域帮你存储相同ocre类型的值在同一个域
- 预先定义:包括ttl(time to live) 和时间戳
认为这些数据是元数据可以自动被es管理给你额外的功能。一旦你知道域类型可以在你文档如何索引他们,来看如何更新已经在那里的文档。由于它存储文档的方式,当es更新存在的文档,它获取它应用改变根据你的specificatio。然后索引结果文档删除老的。这可能导致一致性问题,可以看这如何在文档版本中自动解决。耶可以看到删除文档的多种方式,一些比另一些更快。这是由于Apache lucene,主要的库es用来索引,存储数据在磁盘上。
开始索引看如何管理域从你的文档中。fields在映射中被定义,你如何和域的美中类型一起工作,如何一般化和域一起工作。
3.1 用映射来定义文档的类型
每个document属于一个类型,反过来属于一个index。作为数据的逻辑划分,你可以认为indices是数据库,类型是表格。
types包含每个域的定义,映射包含所有域可能出现在文档中,告诉es如何索引改域在文档中。距离,如果包含日期,可以告诉何种格式是可接受的。
types只提供逻辑划分。
所有文档在一个es索引中,不管类型,归结到相同文件集合属于相同shards。在一个shard里,是一个lucene索引,type的名字是一个域,所有映射的所有域一起作为fields在lucene索引中。
type的概念是层抽象特定对于es但不是对于lucene,让你很方便又不同类型documents在相同index中。es负责分开这些文档,距离,通过过滤文档属于一个类型你可以只在那个类型中搜索。
这个方法创建一个问题当相同域名字在多个类型中出现。
3.1.1 获取和定义映射
Chapter 4.搜索数据
- es搜索请求和返回的结构
- es filters和他们如何和查询不同
- 过滤bitsets和缓存
- 用es支持的查询或过滤条件
chapter 5.分析数据
- 分析文档的文本用es
- 用分析api
- 符号化
- 字符过滤
- token 过滤
- stemming
- 在es中的解释器
5.1 什么是分析
分析是es处理文档的主体在文档被发送去inverted index 处理
- 字符过滤
- 划分文本成tokens
- token过滤
- token索引
5.2 在文档上用你的分析器
有两种方式指定解释器被你的fields所有
- 当索引建立,设置对于那个特定的索引
- 全局解释器在配置文件中对于es
不管你指定你自定义解释器的方式,你需要指定哪个域用那个解释器在你索引映射中,或者通过指定映射当索引创建或者用put mapping api来指定在随后时机中。
5.2.1增加解释器当一个索引被创建
5.3 分析文本用分析API
用分析API来测试分析过程可能很有用当追踪信息如何在es索引中存储。这api允许你发送任意文本到es,指定何种解释器,符号化,token filter要用,得到分析的tokens。
5.3.3 分析基于一个域的映射
es允许你分析基于域映射已经被建立。
5.3.4学习索引属于用术语向量API
5.5 ngrams,dege ngrams, and shingles
Chapter 6.和相关度一起搜索
- 计算得分如何在lucene和es中工作
- boosting一个分数对于一个特定查询或者域
- 理解术语相关性,逆转文档频率,相关性得分用解释api
- 规约得分的影响通过重新计算文档得分子集
- 获取最终能力在得分上用函数_score查询
- 域数据缓存,它如何影响es实例
Chapter 7.探索数据用聚集
- 聚集的机制
- 单筒和多筒聚集
- 嵌套聚集
- 查询的关系,filters,和聚集
Chapter 8.文档间的关系
- 对象和对象数组
- 嵌套映射,查询和过滤
- 父亲映射,has_parent,和has_child查询和过滤
- 去正交化技术
一些数据本质上是关联的。
8.1 选项的综述对于定义文档间的关系
来快速定义这些方法:
- Object type:允许你有一个对象(有它自己的域和值)作为域的值在文档中。举例,一个时间的地址域
用object定义Document关系:pros和cons
- 他们很方便使用。es默认检测他们,不需要定义任何事来索引物体。
- 可以运行查询和aggregation在物体上
Chapter 9.Scaling out
- 增加节点到每个es cluster
- 管理election在es cluster
- 移除和decommission 节点
- 用_API来理解cluster
- 计划和scale strategies
- 别名和自定义转发
Chapter 10.Improving performance
- bulk,multisite和multisearch API
- 更新,flush,merge和存储
- 过滤缓存和tuning filters
- 调节脚本
- 查询warmers
- 平衡JVM堆大小和OS缓存