上节课使用query从数据库中查询到了结果,但是query返回的对象是直接可用的吗?
query:
from connect import session
from user_module import User
result = session.query(User)
print(result,type(result)) #返回是一个query对象,打印出来可以看到转化过后的SQL
根据以上返回是一个query对象,打印出来可以看到转化过后的SQL。
filter:
from connect import session
from user_module import User
result = session.query(User).filter(User.username=='cainiao')
print(result,type(result)) #返回是一个query对象,打印出来可以看到转化过后的SQL

根据以上返回是一个query对象,打印出来可以看到转化过后的SQL。
all:
all 是返回所有符合条件的数据。
result = session.query(User).filter(User.username=='cainiao').all()
print(result,type(result)) ##返回的是一个list,列表里面是一个类
根据以上返回的是一个list,列表里面是一个类。
first:
first 是返回所有符合条件数据的第一条数据。
result = session.query(User).filter(User.username=='cainiao').first()
print(result,type(result)) #返回类的实例化
根据以上返回的是类的实例化
索引
result1 = session.query(User)
print(result1,type(result1)) #返回是一个query对象,打印出来可以看到转化过后的SQL
result2 = session.query(User)[0]
print(result2,type(result2)) #返回类的实例化
result3 = session.query(User).all()[0]
print(result3,type(result3)) #返回类的实例化
result4= session.query(User).first()
print(result4,type(result4)) #返回类的实例化

索引为0的值,类似于first,但是不等同于,空列表用这个会报错!!
取值
对于类的实例化可以用.和getattr来获取字段值
#对于类的实例化可以用.来获取字段值
print(result2.username)
print(result3.username)
print(result4.username)
#也可以用getattr方法
print(getattr(result2,'username'))
print(getattr(result2,'username'))
print(getattr(result2,'username'))
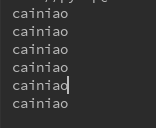
在query里面指定了某个属性值,返回是直接查询User.username的值,所以就返回了包括元组的列表
result = session.query(User.username).all()
print(result,type(result)) #在query里面指定了某个属性值,返回是直接查询User.username的值,所以就返回了包括元组的列表
print(session.query(User.username).first()) #返回元祖

过滤函数
filter是一个过滤函数,过滤条件都可以书写在次函数中,不同的条件之间用逗号隔开。filter_by 也是一个过滤函数,但是功能要弱一些。
result1 = session.query(User).filter(User.username=='cainiao',User.password=='1').all()
print(result1)
result2 = session.query(User).filter_by(username='cainiao').all()
print(result2)
区别:
二者都是 过滤函数,但是使用有如下差别:
- filter 中需要添加 类对象,filter_by不需要。
- filter_by 中只能添加等于的条件,不能添加 不等于、大于小于等条件,filter没有这个限制。
模糊查询
like和notlike
like 是模糊查询,和数据库中的 like 用法一样,notlike 和 like 作用相反。
#like 是模糊查询,和数据库中的 like 用法一样,notlike 和 like 作用相反。
result1 = session.query(User.id).filter(User.username.like('cainiao%')).all()
result2 = session.query(User.id).filter(User.username.notlike('cainiao%')).all()
print(result1,result2)
in_和notin_
in_ 和 notin_ 是范围查找
result1 = session.query(User.id).filter(User.username.in_(['cainiao', 'cainiao1'])).all()
result2 = session.query(User.id).filter(User.username.notin_(['cainiao2', 'cainiao3'])).all()
print(result1,result2)
is_和isnot
is_ 和 isnot精确查找
#is_ 和 isnot精确查找
result1 = session.query(User.id).filter(User.username.is_(None)).all()
result2 = session.query(User.id).filter(User.username.isnot(None)).all()
print(result1,result2)
#判断为空还可以使用:
result3 = session.query(User.id).filter(User.username==None).all()
print(result3)
查询结果
#先用 all 查看所有的数据
result1 = session.query(User.username).filter(User.username!='cainiao%').all()
#查看前2条数据
result2 = session.query(User.username).filter(User.username!='cainiao').limit(2).all()
#偏移一条记录,偏移1个,前面1个数据不看,从第2个数据开始查询
result3 = session.query(User.username).filter(User.username!='cainiao').offset(1).all()
#slice 对查询出来的数据进行切片取值,#切片,索引0到1的数据
result4 = session.query(User.username).filter(User.username!='cainiao').slice(0,2).all()
#one 查询一条数据,如果存在多条则报错,可以用来测试是否只有一条
result5 = session.query(User.username).filter(User.username!='cainiao').one()
排序
#导入模块
from sqlalchemy import desc,asc
#默认正序,asc也是正序
result1 = session.query(User.id).filter(User.username=='cainiao').order_by(User.id).all()
result2 = session.query(User.id).filter(User.username=='cainiao').order_by(asc(User.id)).all()
#desc 是倒序排序
result3 = session.query(User.id).filter(User.username=='cainiao').order_by(desc(User.id)).all()
#order_by 和 limit 一起使用的时候
result4 = session.query(User.id).filter(User.username=='cainiao').order_by(User.id).limit(2).all()
print(result1,type(result1))
print(result2,type(result2))
print(result3,type(result3))
print(result4,type(result4))
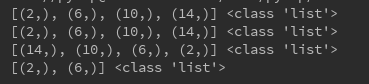
默认为正序,asc。desc为倒序。
函数
#导入
from sqlalchemy import func,extract
result1 = session.query(func.count(User.id)).all() #select count(id) from users
#用到group_by ,查询的列是分组的列,或者某个列的聚合函数
result2 = session.query(User.username).group_by(User.username).all() #select username from users group by username
result3 = session.query(User.username,func.count(User.id)).group_by(User.username).all() #select username,count(id) from users group by username
result4 = session.query(User.username).group_by(User.username).having(func.count(User.id)<4).all()
#group_by 和 order_by 一样,是可以直接使用的,不需要导入,having 也可以直接使用,使用方法也和 SQL 中使用类似。
print(result1,type(result1))
print(result2,type(result2))
print(result3,type(result3))
print(result4,type(result4))

用到group_by ,查询的列是分组的列,或者某个列的聚合函数。
聚合函数
#sum 求和
result1 = session.query(func.sum(User.id)).filter(User.username=='cainiao').all()
#max 求最大值
result2 = session.query(func.max(User.id)).filter(User.username=='cainiao').all()
#min 求最小值
result3 = session.query(func.min(User.id)).filter(User.username=='cainiao').all()
print(result1)
print(result2)
print(result3)
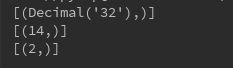
常用聚合函数:count 、 sum avg 、 max 、 min
extract
#extract 提取对象中的数据,这里提取分钟,并把提取出来的结果用 label 命名别名,之后就可以使用 group_by 来分组
session.query(extract('minute',User.creatime).label('minute'), func.count(User.id)).group_by('minute').all()
选择条件
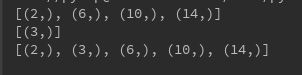
from sqlalchemy import or_
result1 = session.query(User.id).filter(User.username=='cainiao').all()
result2 = session.query(User.id).filter(User.id==3).all()
result3 = session.query(User.id).filter(or_(User.username=='cainiao',User.id==3)).all()
print(result1)
print(result2)
print(result3)
多表查询
新建module
class UserDetails(Base):
__tablename__ = 'user_details'
id = Column(Integer,primary_key=True,autoincrement=True)
id_card = Column(Integer,nullable=True,unique=True)
last_login =Column(DateTime)
login_num = Column(Integer,default=0)
user_id = Column(Integer,ForeignKey('users.id'))
def __repr__(self):
return ''%(self.id,self.id_card,self.last_login,self.login_num,
self.user_id)
cross join笛卡尔积
cross join交叉连接。交叉连接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉连接也称作笛卡尔积。
from user_module import UserDetails
result1 = session.query(UserDetails,User) #cross join 第一张表每一项与第二张表交叉连接
print(result1,type(result1))

inner join内连接
内连接inner join,内连接,只查匹配行。
result2 = session.query(User.username, UserDetails.last_login).join(UserDetails,UserDetails.id==User.id) #内连接
print(result2)
外连接
外连接,至少有一方保留全集,没有匹配行用NULL代替。外连接分为三种:左外连接,右外连接,全外连接。对应SQL:LEFT/RIGHT/FULL OUTER JOIN。通常我们省略outer 这个关键字。写成:LEFT/RIGHT/FULL JOIN。
- 左外连接:左表不加限制,保留左表的数据,匹配右表,右表没有匹配2到的行中的列显示为null。
- 右外连接:右表不加限制,保留右表的数据。匹配左表,左表没有匹配到的行中列显示为null。
- 完全外连接:左右表都不加限制。即右外连接的结果为:左右表匹配的数据+左表没有匹配到的数据+右表没有匹配到的数据。
#左连接 left join结果集保留左表的所有行,但只包含第二个表与第一表匹配的行。第二个表相应的空行被放入NULL值。
result3 = session.query(User.username, UserDetails.last_login).outerjoin(UserDetails,UserDetails.id==User.id) #左连接
print(result3,type(result3))
#sqlalchemy没有right join,右连接将表反过来写即可。
result4 = session.query(UserDetails.last_login,User.username).outerjoin(User,User.id==UserDetails.id)
print(result4,type(result4))

union
union 是联合查询,有自动去重的功能,对应的还有 union_all,UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
#union 是联合查询,有自动去重的功能,对应的还有 union_all,UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
q1 = session.query(User.id)
q2 = session.query(UserDetails.id)
result1 = q1.union(q2)
result2 = q1.union_all(q2)
print(q1.all())
print(q2.all())
print(result1.all(),type(result1))
print(result2.all(),type(result2))

union:联合的意思,即把两次或多次查询结果合并起来。
要求:两次查询的列数必须一致
推荐:列的类型可以不一样,但推荐查询的每一列,想对应的类型以一样
可以来自多张表的数据:多次sql语句取出的列名可以不一致,此时以第一个sql语句的列名为准。
如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。
如果不想去掉重复的行,可以使用union all。
子表查询
是指出现在其他SQL语句内的SELECT字句。嵌套在查询内部,且必须始终出现在圆括号内。子查询里面只能查询一个东西,不能查询多个,因为外面接收的只能接收一个。
#子表查询
#subquery声明子表
sql_0 =session.query(UserDetails.last_login).subquery()
#使用
result2 = session.query(User,sql_0.c.last_login)
print(result2)

原生sql查询
sql = "select * from users"
row = session.execute(sql)
print(row.fetchall()) #注意类似游标指针一次查询指针会指到本次查询的末尾处
print(row.fetchone())
print(row.fetchmany())
#循环获取
for i in row:
print(i)

pycharm快速添加数据
点击右边Database:

点击添加:

设置配置信息:
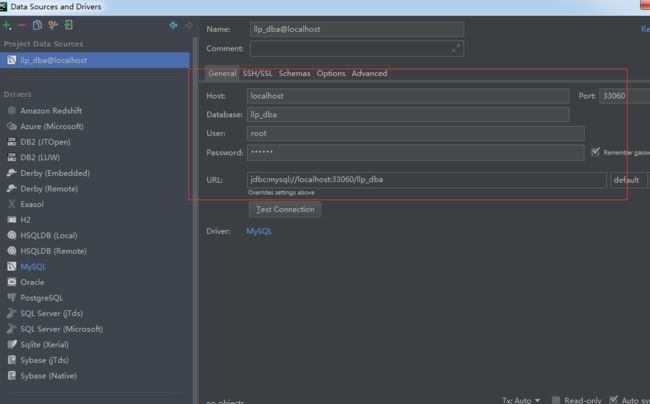
测试连接成功,点击保存:

点击右边就可以在左边进行相关操作了
