redis主从切换会堵塞进程吗_Redis集群&哨兵机制

Redis主从复制
什么是主从复制
持久化保证了即使 Redis 服务重启也不会丢失数据,因为 Redis 服务重启后会将硬盘上持久化的数据恢复到内存中,但是当 Redis 服务器的硬盘损坏了可能会导致数据丢失,不过通过 Redis 的主从复制机制就可以避免这种单点故障。
实现原理
- Redis 的主从同步,分为全量同步和增量同步。
- 只要从机第一次连接上主机是全量同步。
- 断线重连有可能触发全量同步也有可能是增量同步( master 判断 runid 是否一致)。
- 除此之外的情况都是增量同步。
全量同步
Redis 的全量同步过程主要分三个阶段:
- 从服务器连接主服务器,发送同步命令。
- 主服务器接收到同步命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令。
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令。
- 从服务器收到快照文件后,载入解析快照,完成数据同步。

增量同步
- Redis 增量同步主要指 Slave 完成初始化后开始正常工作时, Master 发生的写操作同步到Slave 的过程。
- 通常情况下, Master 每执行一个写命令就会向 Slave 发送相同的写命令,然后 Slave 接收并执行。
``` # replicaof # 表示当前【从服务器】对应的【主服务器】的IP是192.168.10.135,端口是6379。 #4.0之前只能slaveof 4.0之后默认replicaof,slaveof都起作用
slaveof 192.168.133.154 6379
replicaof 192.168.133.154 6379 ```
Redis 哨兵机制
什么是哨兵
Redis Sentinel是一个分布式系统,为Redis提供高可用性解决方案。可以在一个架构中运行多个 Sentinel 进程(progress), 这些进程使用流言协议(gossip protocols)来 接收关于主服务器是否下线的信息, 并使用投票协议(agreement protocols)来决定是否执行自动故 障迁移, 以及选择哪个从服务器作为新的主服务器。
Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance) 该系统执行以下三个任务:
- 监控(Monitoring): Sentinel 会不断地定期检查你的主服务器和从服务器是否运作正常。
- 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过 API 向管理员或者其他应用程序发送通知。
- 自动故障迁移(Automaticfailover): 当一个主服务器不能正常工作时, Sentinel 会开始一次自动故障迁移操作, 它会将失效主服务器的其中 一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客 户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主 服务器代替失效服务器。
哨兵配置
sentinel.conf
# 设置端口
port 26379
# 是否守护进程启动
daemonize yes
# 守护进程运行的时候需要保留pidfile
pidfile /var/run/redis-sentinel.pid
# 日志文件
logfile "/root/log/sentinel.log"
## sentinel monitor master-group-name hostname port quorum
## quorum的解释如下:
##(1)至少多少个哨兵要一致同意,master进程挂掉了,或者slave进程挂掉了,或者要启动一个
#故障转移操作
##(2)quorum是用来识别故障的,真正执行故障转移的时候,还是要在哨兵集群执行选举,选举一 个哨兵进程出来执行故障转移操作
##(3)假设有5个哨兵,quorum设置了2,那么如果5个哨兵中的2个都认为master挂掉了; 2个哨 兵中的一个就会做一个选举,选举一个哨兵出来,执行故障转移; 如果5个哨兵中有3个哨兵都是运行 的,那么故障转移才会被允许执行。
# 原文是:Note that whatever is the ODOWN quorum, a Sentinel will require to
# be selected by the majority of the known Sentinels in order to
# start a failover, so no failover can be performed in minority.
sentinel monitor mymaster 127.0.0.1 6379 3
# down-after-milliseconds,超过多少毫秒跟一个redis实例断了连接(ping不通),哨兵就可 能认为这个redis实例挂了
sentinel down-after-milliseconds mymaster 30000
# parallel-syncs,新的master别切换之后,同时有多少个slave被切换到去连接新master,重 新做同步,数字越低,花费的时间越多
# 比如:master宕机了,4个slave中有1个切换成了master,剩下3个slave就要挂到新的master 上面去
# 这个时候,如果parallel-syncs是1,那么3个slave,一个一个地挂接到新的master上面去,1 个挂接完,而且从新的master sync完数据之后,再挂接下一个。
# 如果parallel-syncs是3,那么一次性就会把所有slave挂接到新的master上去
sentinel parallel-syncs mymaster 1
#failover-timeout,执行故障转移的timeout超时时长,Default is 3 minutes.
sentinel failover-timeout mymaster 180000
#如果主节点设置了密码,则需要这个配置,否则哨兵无法对主节点进行监控。
sentinel auth-pass mymaster password为什么要用到哨兵
哨兵(Sentinel)主要是为了解决在主从复制架构中出现宕机的情况,主要分为两种情况:
- 从Redis宕机
在Redis中从库重新启动后会自动加入到主从架构中,自动完成同步数据。在Redis2.8版本后,主从断线后恢复的情况下实现增量复制。
- 主Redis宕机
需要以下2步才能完成: a. 在从数据库中执行SLAVEOF NO ONE命令,断开主从关系并且提升为主库继续服务。 b. 将主库重新启动后,执行SLAVEOF命令,将其设置为其他库的从库,这时数据就能更新回来。
由于这个手动完成恢复的过程其实是比较麻烦的并且容易出错,所以Redis提供的哨兵(sentinel)的功能来解决
- 哨兵机制的高可用
Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
如图

在Server1 掉线后:

升级Server2 为新的主服务器:

哨兵的定时监控
任务1:每个哨兵节点每10秒会向主节点和从节点发送info命令获取最拓扑结构图,哨兵配置时只要配置对主节点的监控即可,通过 向主节点发送info,获取从节点的信息,并当有新的从节点加入时可以马上感知到。

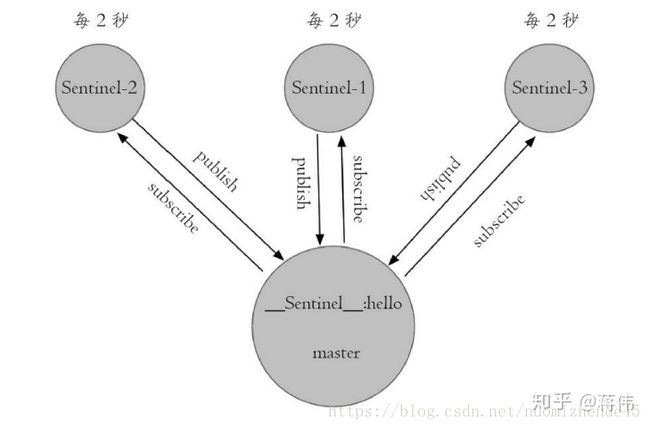
任务2:每个哨兵节点每隔2秒会向redis数据节点的指定频道上发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个 哨兵节点也会订阅该频道,来了解其它哨兵节点的信息及对主节点的判断,其实就是通过消息publish和subscribe来完成的。
任务3:每隔1秒每个哨兵会向主节点、从节点及其余哨兵节点发送一次ping命令做一次心跳检测,这个也是哨兵用来判断节点是否正常 的重要依据。

主观下线
所谓主观下线,就是单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。
sentinel会以每秒一次的频率向所有与其建立了命令连接的实例(master,从服务,其他sentinel)发ping命令,通过判断ping回复是有效回复,还是无效回复来判断实例时候在线(对该sentinel来说是“主观在线”)。
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度,如果实例在down-after-milliseconds毫秒内,返回的都是无效回复,那么sentinel回认为该实例已(主观)下线,修改其flags状态为SRI_S_DOWN。如果多个sentinel监视一个服务,有可能存在多个sentinel的down-after-milliseconds配置不同,这个在实际生产中要注意。
客观下线
当主观下线的节点是主节点时,此时该哨兵3节点会通过指令sentinel is-masterdown-by-addr寻求其它哨兵节点对主节点的判断,如果其他的哨兵也认为主节点主观线下了,则当认为主观下线的票数超过了quorum(选举)个数,此时哨兵节点则认为该主节点确实有问题,这样就客观下线了,大部分哨兵节点都同意下线操作,也就说是客观下线

哨兵lerder选举流程
如果主节点被判定为客观下线之后,就要选取一个哨兵节点来完成后面的故障转移工作,选举出一个leader的流程如下:
a)每个在线的哨兵节点都可以成为领导者,当它确认(比如哨兵3)主节点下线时,会向其它哨兵发is-master-down-by-addr命令,征 求判断并要求将自己设置为领导者,由领导者处理故障转移。 b)当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者。 c)如果哨兵3发现自己在选举的票数大于等于num(sentinels)/2+1时,将成为领导者,如果没有超过,继续选举…………

自动故障转移机制
在从节点下选择新的节点
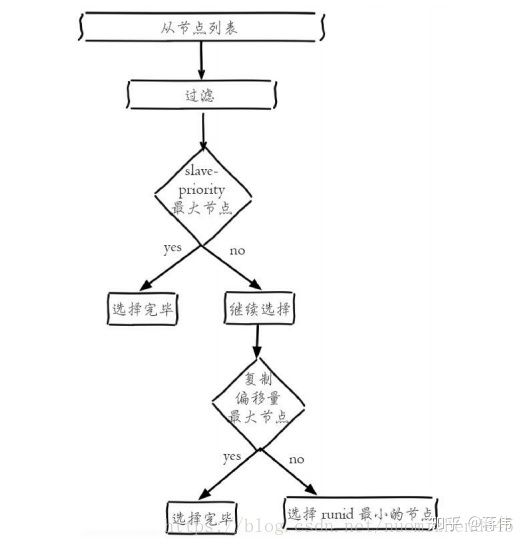
sentinel状态数据结构中保存了主服务的所有从服务信息,领头sentinel按照如下的规则从从服务列表中挑选出新的主服务
- 过滤掉主观下线的节点。
- 选择slave-priority(优先级)最高的节点,如果由则返回没有就继续选择。
- 选择出复制偏移量最大的系节点,因为复制便宜量越大则数据复制的越完整,如果由就返回了,没有就继续。
- 选择run_id最小的节点
更新主从状态
通过slaveof no one命令,让选出来的从节点成为主节点;并通过slaveof命令让其他节点成为其从节点。
将已下线的主节点设置成新的主节点的从节点,当其回复正常时,复制新的主节点,变成新的主节点的从节点
同理,当已下线的服务重新上线时,sentinel会向其发送slaveof命令,让其成为新主的从。
Sentinel的工作原理总结
- 每个Sentinel以每秒钟一次的频率向它所知的Master,Slave以及其他 Sentinel 实例发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel 标记为主观下线。
- 如果一个Master被标记为主观下线,则正在监视这个Master的所有 Sentinel 要以每秒一次的频率确认Master的确进入了主观下线状态。
- 当有足够数量的 Sentinel(大于等于配置文件指定的值)在指定的时间范围内确认Master的确进入了主观下线状态, 则Master会被标记为客观下线 。
- 在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有Master,Slave发送 INFO 命令 。
- 当Master被 Sentinel 标记为客观下线时,Sentinel 向下线的 Master 的所有 Slave 发送 INFO 命令的频率会从 10 秒一次改为每秒一次 。
- 若没有足够数量的 Sentinel 同意 Master 已经下线, Master 的客观下线状态就会被移除。 Redis集群&哨兵机制Redis集群&哨兵机制