疑难杂症:内存明明很富裕,却还是申请不到?
本次我们继续生产问题的疑难杂症排查系统的文章,在开始我们下一次集中讨论Redis的问题之前,本文与《疑难杂症:系统雪崩到底是为什么》和《疑难杂症: 遇到一个杀不掉,追不到,找不着的进程怎么破?》共同作为下次博客的前序铺垫,经大家普及一下基础知识。
当然这个情况我们还是以一个案例,引入今天的话题。最近Redis通过其极佳的性能而火爆全球,作为内存缓存数据库方面Redis几乎没有任何对手,因此Redis的问题往往是比较经典需要我们仔细推敲的。一般来讲我们都比较推荐在使用Redis时将其默认的MaxMemory配置为系统同存总量的90%左右,并且关掉Linux的OOM以保证Redis进程不会被操作系统的内存释放机制所杀掉。但是我们在生产上还是遇到了由于内存问题造成Redis无法正常启动的问题。具体的现象如下:
- Redis在运行一段时间之后就会崩溃。
- 如果关闭Linux操作系统的OOM,则操作系统有可能出现问题。
- 如果打开OOM则Redis会被杀掉
- Redis的最大内存占用项目(MAXMEMORY)配置为60G,实际物理内存大小为64G,经查询日志未发现Redis内存使用超过60G限度的问题。
数据局部性原理产生的循环
我在《疑难杂症:系统雪崩到底是为什么》曾经介绍过,数据的访问往往都有局部性,比如内存单元A被访问了,那么他的邻居A’和A’’被访问到的可能性也会极大的增加,因此CPU的高速缓存、硬盘的缓存都会将这些集中数据访问进行优化,这种优化机制也强化了连续数据的访问性能。比如读取连续的磁盘空间通常性能能比随机读高三、四个数量级;内存也是同样,读取连续空间比读取非连续空间要快得多,其机制就是硬盘及CPU缓存一般会将要缓存单元的邻居也一并调用到缓存当中。
而要搞清我们刚刚所说的Redis问题成因,还要把内存管理的模型以及物理内存分配的算法讲清楚。如果把计算机比成一个酒店,那内存就是客房,进程就是住户而CPU就是酒店的管家,从这个角度上理解逻辑地址、线性地址以及物理地址是最为简单的。
逻辑地址:应用进程直接用指令给出的地址其实就是逻辑地址,逻辑地址的引入其实就是让进程之间彼此相互不会影响,都以为自己独享整个客房,而屏蔽了底层物理地址的硬件细节 。
线性地址(Linear Address)也叫虚拟地址(virtual address):这层的引入其实基本上是由于英特尔对于x86向前兼容的需要,按照原有的英特尔规划,线性地址是暴露给操作系统管理的,也就是应用所在的逻辑地址空间会映射到一个大的线性空间,方便操作系统统一调用管理。而像Linux等目前主流的操作系统内核,全部启用分页机制进行进程之间的内存隔离与保护,线性地址其实就是逻辑地址。
物理地址:这就是真正的CPU地址总线访问内存使用的址了,由硬件电路控制(现在这些硬件是可编程的了)其具体含义。物理地址中很大一部分是留给内存条中的内存的,但也常被映射到其他存储器上(如显存、BIOS等)。
在实际地址映射时,CPU要利用其段式内存管理单元,先将为个逻辑地址转换成一个线性地址,再利用其分页功能,转换为最终物理地址。也就是进程访问的逻辑地址可能是相同的,但是最终他们访问到的物理地址完全不同。当然这个转换其实一次就够了。之所以这样冗余,正如前文所说完全是为了X86的向前兼容。
而物理内存是要尽量保证内存分配的连续性,虽然在各用户进程的看到的连续逻辑地址也完全可以映射为不连续的物理内存上,但是这样做的代价就是大幅牺牲执行效率,因为CPU缓存只会针对物理内存做局部性优化,逻辑地址是CPU看不到也不关心的。这样才能有效提速,因此一般操作系统都会保证将用户进程申请的内存区域,映射到连续的物理内存上去。
最直接的方案就是将个内存区域多个固定大小的分区,每个分区容纳一个进程,当一个分区空闲时,可以将内存调入内存,等待执行,这是最简单的内存分配方案,但是这种方案存在很多问题,我们并不知道每个进程需要多大的空间,如果空间过小,那么我们的进程就存不下,如果进程都很小,但是我们分区很大的话,那么会造成很大程度的浪费,这些在每个分区未被利用的空间,我们称之为碎片。
伙伴算法出场
为了尽可能的减少碎片,伙伴算法正式出场。伙伴算法,简而言之,就是将内存分成若干块,然后动态管理他们。Linux 便是采用这著名的伙伴系统算法来解决外部碎片的问题,同linux将所有的空闲页框分组为 11 块链表,每一块链表分别包含大小为1,2,4,8,16,32,64,128,256,512 和 1024 个连续的页框。对1024 个页框的最大请求对应着 4MB 大小的连续RAM 块。
满足以下条件的两个块称为伙伴:
- 两个块具有相同的大小,记作 b
- 它们的物理地址是连续的
该算法是迭代的,如果它成功合并所释放的块,它会试图合并 2b 的块,以再次试图形成更大的块。
下面通过一个例子,来深入地理解一下伙伴算法的真正内涵(下面这个例子并不严格表示Linux 内核中的实现,是阐述伙伴算法的实现思想):
假设系统中有 1MB 大小的内存需要动态管理,按照伙伴算法的要求:需要将这1M大小的内存进行划分。这里,我们将这1M的内存分为 64K、64K、128K、256K、和512K 共五个部分,如下图:
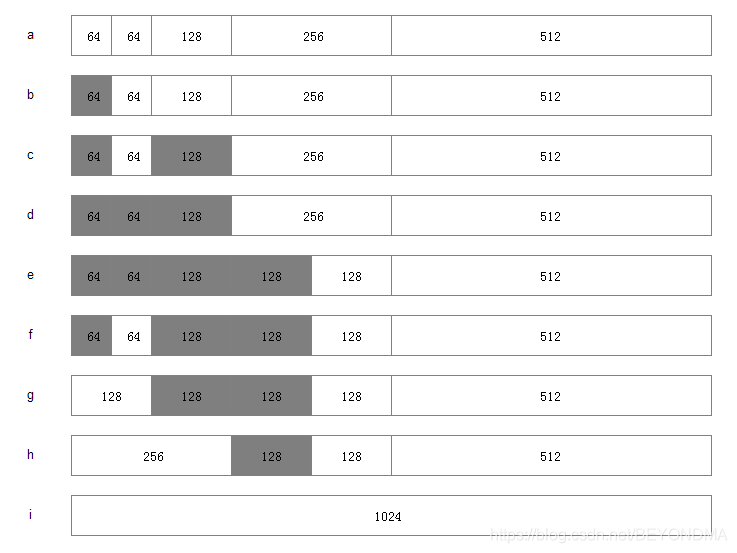
分配内存步骤:
1.寻找大小合适的内存块(大于等于所需大小并且最接近2的幂,比如需要27,实际分配32)
1.如果找到了,分配给应用程序。
2.如果没找到,分出合适的内存块。
1.对半分离出高于所需大小的空闲内存块
2.如果分到最低限度,分配这个大小。
3.回溯到步骤1(寻找合适大小的块)
4.重复该步骤直到一个合适的块
释放内存:
1.释放该内存块
1.寻找相邻的块,看其是否释放了。
2.如果相邻块也释放了,合并这两个块,重复上述步骤直到遇上未释放的相邻块,或者达到最高上限(即所有内存都释放了)。
理解不了伙伴算法也没关系,只要了解下面几个结论就好。
1操作系统会在进程申请或者释放内存的同时进行内存碎片的整理。
2在内存使用率比较高的情况下去申请或者释放内存都可能造成操作系统频繁进行内存页的合并或者切割,而这样的操作都是加锁保护的,一般会使系统整体的运行效率大幅下降。
3在内存还有足够空闲的情况下也有可能申请不到内存块。
回到Redis的内存问题
有了上述背景知识我们再来看刚刚提到的redis问题。
我们知道redis有最大内存占用也就是maxmemory的配置,一旦达到或者超过最大内存有以下几种策略可选择
noeviction: 不进行置换,表示即使内存达到上限也不进行置换,所有能引起内存增加的命令都会返回error
allkeys-lru: 优先删除掉最近最不经常使用的key,用以保存新数据
volatile-lru: 只从设置失效(expire set)的key中选择最近最不经常使用的key进行删除,用以保存新数据
allkeys-random: 随机从all-keys中选择一些key进行删除,用以保存新数据
volatile-random: 只从设置失效(expire set)的key中,选择一些key进行删除,用以保存新数据
volatile-ttl: 只从设置失效(expire set)的key中,选出存活时间(TTL)最短的key进行删除,用以保存新数据
我们当时选择的是lru策略,当然有关redis的问题排查我计划专题介绍,他的lru实现其实是分组策略,而不是全面的大排行,这明显是参考了缓存中组连接策略的精髓,当然这里不加赘述了。
而当时的情况下,redis在系统内存使用本身就比较高的情况下,还在频繁进行内存的释放与申请操作,这种情况下如果系统开了oom killer那么redis会被杀掉,如果没开那么系统会由于过大的内存整理损耗而崩溃。
两点启示
1如果想保证redis服务的平安,选择noeviction也就是不替换原有key的策略是最稳的。
2 如果无法选择noeviction策略,那么尽量打开系统的oom策略,这样更有利于问题的排查,以免错误的把原因归结为操作系统问题。