联邦学习入门笔记(三)—— 基于差分隐私的FL
本文主要介绍了笔者对于将差分隐私与联邦学习相结合以保护客户端隐私这一类办法的理解。
本文首发于我的博客,
原文地址请点击这里!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
最近好久没更新博客了,主要是因为这一个多月研究生开学,事情比较多,再加上自己的电脑拆机的时候不小心把螺丝拧坏了一直没去处理(最近才弄好),所以导致将近2个月没更新文章。
笔者最近在研究将差分隐私与联邦学习相结合以保护客户端隐私的相关方向,大概看了有一个多月的文章,算是对这种保护方法有一个自己的理解吧,这里记录一下。
什么是差分隐私
这里可以参考这篇文章:
https://zhuanlan.zhihu.com/p/139114240
知乎这个专栏写的非常不错,引用他的话就是:
`差分隐私`顾名思义就是用来防范`差分攻击`的,我最早接触到`差分攻击`的概念是数据库课上老师介绍的。举个简单的例子,假设现在有一个婚恋数据库,2个单身8个已婚,只能查有多少人单身。刚开始的时候查询发现,2个人单身;现在张三跑去登记了自己婚姻状况,再一查,发现3个人单身。所以张三单身。
也就是说,对于任何一个所谓的”查询“任务,我们要防范出现上述这种情况,这里就用到了差分隐私研究领域涉及到的一些防范方法,即对于每次”查询“我们都加入一定的偶然性,也就是每次都添加一定量的噪音,引用那个专栏的例子:
比如刚才的例子,本来两次查询结构是确定的2和3,现在加入随机噪声后,变成了两个随机变量,画出它们概率分布图。
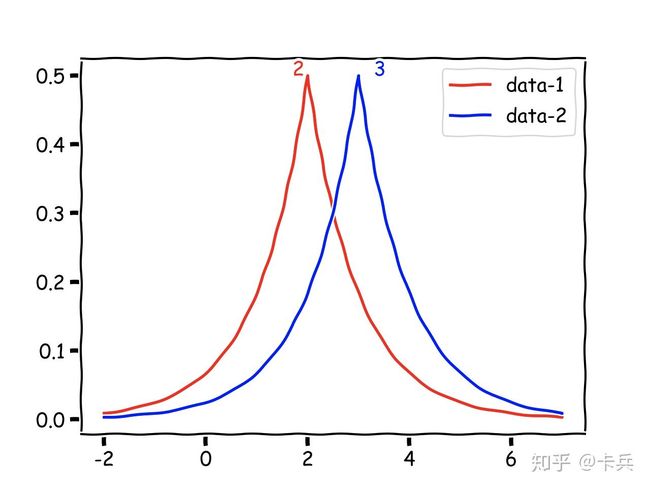
这里注意,由于2和3是真实结果,加上一个随机变量(也就是噪音,它可能呈拉普拉斯分布或者其他分布)的概率密度分布就可以得到如上图所示。
这样做也就是说,我一次查询,对于2来说,有较大的概率输出2,也有其他概率输出其他结果,这个概率是由噪音的概率密度函数所决定的。其实这就是所谓的差分隐私,加上的噪音有很多种方案,很多文章都是变换了加噪音的分布函数,然后检测它是否满足差分隐私定义的一些要求,然后告诉大家我们的这个可以用,效果怎么样等等。
关于差分隐私具体是什么,可以参考我上面发那片文章,具体这里不再赘述,本文主要关注的是差分隐私在联邦学习中是具体如何使用的。
联邦学习中的差分隐私
所谓在联邦学习中使用差分隐私,主要流程如下所示:
-
本地计算
客户端 i i i 根据本地数据库 D i \mathcal{D}_i Di 和接受的服务器的全局模型 w G t w_G^t wGt作为本地的参数,即 w i t = w G t w_i^t = w_G^t wit=wGt,进行梯度下降策略进行本地模型训练得到 w i t + 1 w_i^{t+1} wit+1 ( t t t 表示当前round)。
-
模型扰动
每个客户端产生一个随机噪音 n n n, n n n 是符合高斯分布的,使用 w i ‾ t + 1 = w i t + 1 + n \overline{w_i}^{t+1} = w_i^{t+1} + n wit+1=wit+1+n 扰动本地模型(这里注意 w w w是一个矩阵,那么 n n n就对矩阵的每一个元素产生噪音)。
-
模型聚合
服务器使用FedAVG算法聚合从客户端收到的 w i ‾ t + 1 \overline{w_i}^{t+1} wit+1得到新的全局模型参数 w G t + 1 w_G^{t+1} wGt+1,也就是扰动过的模型参数。
-
模型广播
服务器将新的模型参数广播给每个客户端。
-
本地模型更新
每个客户端接受新的模型参数,重新进行本地计算。
以上是利用差分隐私进行联邦学习梯度参数隐私保护的典型过程。当然也有一些变体,但是大体上都是这个思路。
为什么联邦学习需要差分隐私?
直观上可能会觉得仅仅使用联邦学习就已经能够保护隐私了(因为联邦学习并不直接传输数据,而是传输梯度信息)。
实际上,梯度信息已经被证明可以隐私,这两篇文章已经证明:
[1].Melis etal. Exploiting Unintended Feature Leakage in Collaborative Learning. In lEEE Symposium on Security & Privacy,2019.
[2].Hitaj et al. Deep models under theGAN: information leakage from collaborative deep learning.In ACM SIGSAC Conference on
防止梯度信息被泄露的方法有很多,目前主要有两种:
1.基于安全多方计算的
这个里面包含的方法很多,包括对梯度进行安全聚合算法进行聚合,或者进行同态加密运算,等等,文章以及方法很多。
2.基于差分隐私的
这个里面主要就是对梯度信息添加噪音,添加的噪音种类可能不同,但是目前主要就是拉普拉斯噪声和高斯噪声这两种。
现在回到标题问题,为什么要用差分隐私?
因为基于安全多方计算的通信代价或者计算代价非常大,这个方法主要是通过C/S双方复杂的通信协议或者复杂的加密机制来实现的,所以通信、计算、延迟都会较高,但是模型较为准确。
而基于差分隐私的联邦学习主要是对梯度信息添加噪声,不会有很高的通信或者计算代价,但是由于我们对于梯度进行进行了加噪,所以会影响模型收敛的速度,可能会需要更多的round才能达到我们想要的精度。
所以如果不想要很大的通信或者计算代价,那就可以采取差分隐私的方法。
如果想看具体的,可以看一下这个专栏:
https://zhuanlan.zhihu.com/p/266134450
FL中的差分隐私噪声是如何产生的?
- 首先每个client根据自己的隐私保护要求程度,产生一个差分隐私的 ϵ \epsilon ϵ值, ϵ \epsilon ϵ越大隐私保护程度越弱
- 每个client是需要裁剪(Clip)梯度,要把梯度bound在 C C C和 − C -C −C之间的话,那么差分隐私的 Δ f = 2 C n \Delta f = \frac{2C}{n} Δf=n2C,n为本地sample的数量
- 根据 Δ f \Delta f Δf 和 ϵ \epsilon ϵ的值就可以求出拉普拉斯分布或者高斯分布的参数了(高斯分布可能还需要 δ \delta δ,这个也是client自己规定的)
- 然后从高斯分布或者拉普拉斯分布中sample出一个值加上模型参数值就可以了。
Δ f = 2 C n \Delta f = \frac{2C}{n} Δf=n2C的推导可以看这两篇论文:
1.Federated Learning with Differential Privacy:Algorithms and Performance Analysis
2.The Value of Collaboration in Convex Machine Learning with Differential Privacy
我觉得 Δ f = 2 C \Delta f = 2C Δf=2C其实也可以,只不过 Δ f = 2 C n \Delta f = \frac{2C}{n} Δf=n2C可能更严谨一些,这个敏感度要根据算法所使用的梯度下降的方式来确定,如果是BGD就是 Δ f = 2 C n \Delta f = \frac{2C}{n} Δf=n2C,如果是SGD就是 Δ f = 2 C \Delta f = 2C Δf=2C,如果是miniBGD就是 Δ f = 2 C ∣ B a t c h S i z e ∣ \Delta f = \frac{2C}{|Batch Size|} Δf=∣BatchSize∣2C。
需要注意的点是:
- 每个client可能要求的 ϵ \epsilon ϵ是不一样的。
- 每个client添加的噪音是独立的,但是不一定同分布( ϵ , Δ f \epsilon,\Delta f ϵ,Δf不一样)。
为什么可以添加噪声?
从本质上来讲,联邦学习加差分隐私是向权重添加了噪声,而本身向权重添加噪声是防止模型过拟合的一种常用方法(相当于加了一个正则化项),可以参考:
1.http://www.huaxiaozhuan.com/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/chapters/3_regularization.html
2.https://www.bookstack.cn/read/huaxiaozhuan-ai/spilt.4.d07cc9a8a1364f3d.md
1中4.2节的描述特别清晰。
所以添加噪声既可以保护隐私,又可以防止模型过拟合,但是降低了模型的精度。
参考文献
1.https://www.zhihu.com/column/c_1293586488769040384
2.http://www.huaxiaozhuan.com/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0/chapters/3_regularization.html
3.https://www.bookstack.cn/read/huaxiaozhuan-ai/spilt.4.d07cc9a8a1364f3d.md
4.http://yongxintong.group/static/talks/2019/federated-DP.pdf
顺便提一下,youtube上wang shuseng老师的分布式机器学习讲解特别棒,简单易懂,适合入门。
链接:https://www.youtube.com/user/wsszju