Hadoop3.3.0完全分布式部署
一、配置hadoop
1.1 总纲
- 采用1+1+3的集群配置(一台主服务器,一台备主服务器,3台从服务器)
- 这些配置都只是先在master1作,然后用命SCP拷贝复制到其它服务器
- 下载最新hadoop镜像:hadoop-3.3.0
- 解压到相应目录
- 配置环境变量在/etc/hosts, /etc/profile,hadoop-en.sh, yarn-en.sh, mapreduce-env.sh
- 修改文件目录权限
- 设置免密登录
- 配置相应文件:workers, core-site.xmlhdfs-site.xmlmapred-site.xmlyarn-site.xml
1.2 修改/etc/hosts,配置服务器名
ip1.226 master1
ip2.229 master2
ip3.227 worker1
ip4.228 worker2
ip5.232 worker3
- 将master1上的/etc/hosts传到其他服务器上,并且执行source /etc/profile,使其生效:
scp /etc/hosts root@master2:/etc/
scp /etc/hosts root@worker1:/etc/
scp /etc/hosts root@worker2:/etc/
scp /etc/hosts root@worker3:/etc/
1.3 修改/etc/profile,添加环境变量
# for hadoop
export MYSQL_HOVE=/usr/local/mysql
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64
#export JAVA_HOME=/usr/lib/jvm/jre
export HADOOP_HOME=/opt/hadoop3/hadoop-3.3.0
export HIVE_HOME=/opt/hive/apache-hive-3.1.2-bin
export PATH=.:$HADOOP_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$MYSQL_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/tools.jar:$HIVE_HOME/bin
source /etc/profile
- 将master1上的/etc/profile传到其他服务器上, 并且执行source /etc/profile,使其生效:
scp /etc/profile root@master2:/etc/
scp /etc/profile root@worker1:/etc/
scp /etc/profile root@worker2:/etc/
scp /etc/profile root@worker3:/etc/
hadoop是守护线程 读取不到 /etc/profile 里面配置的JAVA_HOME路径 ,
所以在 hadoop-env.sh yarn-env.sh mapreduce-env.sh配置 JAVA_HOME, 这样才能读取到JAVA_HOME
- 再登录到每个服务器上去:source /etc/profile, ./hadoop-env.sh, ./yarn-env.sh, ./mapreduce-env.sh
1.4 修改workers文件,配置从节点名
# 路径:hadoop-3.3.0\hadoop-3.3.0\hadoop-3.3.0\etc\hadoop\
worker1
worker2
worker3
1.5 设置集群服务器之间的免密登录
ssh master2 # 第一次需要输入yes,进行确认。如果登录到master2,表示已经可以免密登录了,然后exit退出。
ssh worker1
ssh worker2
ssh worker3
如果不用密码就可以登录,则不用设置免密登录,如果不可以,则需要进行免密设置步骤
ssh生成相应密钥对:id_rsa私钥和id_rsa.pub公钥。
ssh-keygen -t rsa -P ''
默认是存在/当前user/.ssh(/root/.ssh或者/home/user/.ssh)下的!
有了密钥对:将id_rsa.pub加到授权中
# cat id_rsa.pub >> authorized_keys
试一下是否本地免密登陆设置成功:
ssh localhost #第一次登陆需要确定,输入yes
ok!没有问题,那么配置其他服务器,其实只需要把本机master1的id_rsa.pub复制到其他服务器上就可以了!这里就选择ssh-copy-id命令传送到其他服务器上
# ssh-copy-id root@master2
# ssh-copy-id root@worker1
# ssh-copy-id root@worker2
# ssh-copy-id root@worker3
- master1主节点配置,先在主节点配置,然后在用scp传到其它服务器上
1.6 配置hadoop环境, 主要是修改4个配置文件:
-
core-site.xml
-
hdfs-site.xml
-
mapred-site.xml
-
yarn-site.xml
-
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://master1:9000value>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/hadoop3/tmpvalue>
property>
configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///${hadoop.tmp.dir}/dfs/nnvalue>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master2:50000value>
property>
<property>
<name>dfs.blocksizename>
<value>268435456value>
property>
<property>
<name>dfs.namenode.handler.countname>
<value>100value>
property>
<property>
<name>dfs.replicationname>
<value>2value>
property>
configuration>
- mapred-site.xml
mapreduce.framework.name
yarn
- yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enablename>
<value>truevalue>
property>
<property>
<name>yarn.admin.aclname>
<value>Admin ACLvalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>falsevalue>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
然后把主节点的所有配置文件,以及hadoop都复制到其它服务器上:
scp -r /opt/hadoop3/ root@master2:/opt/
scp -r /opt/hadoop3/ root@worker1:/opt/
scp -r /opt/hadoop3/ root@worker2:/opt/
scp -r /opt/hadoop3/ root@worker3:/opt/
1.7 格式化主节点
hadoop namenode -format
1.8 启动hadoop
start-all.sh
root启动报错:
Starting namenodes on [master1]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [master2]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
解决办法:在start-yarn.sh、stop-yarn.sh、 start-all.sh、start-dfs.sh、stop-dfs.sh文件顶部添加以下参数
[root@master1 hadoop]# cat ../../sbin/start-all.sh
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
#HADOOP_SECURE_DN_USER=hdfs
HDFS_DATANODE_SECURE_USER=root
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
添加完成后,再将这些配置文件复制到其它服务器上
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh start-all.sh root@master2:/opt/hadoop3/hadoop-3.3.0/sbin/
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh start-all.sh root@worker1:/opt/hadoop3/hadoop-3.3.0/sbin/
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh start-all.sh root@worker2:/opt/hadoop3/hadoop-3.3.0/sbin/
scp start-dfs.sh stop-dfs.sh start-yarn.sh stop-yarn.sh start-all.sh root@worker3:/opt/hadoop3/hadoop-3.3.0/sbin/
再次运行start-all.sh文件,错误:
− b a s h : / o p t / h a d o o p 3 / h a d o o p − 3.3.0 / b i n / h a d o o p : P e r m i s s i o n d e n i e d -bash: /opt/hadoop3/hadoop-3.3.0/bin/hadoop: Permission denied −bash:/opt/hadoop3/hadoop−3.3.0/bin/hadoop:Permissiondenied
[hadoop@master1 sbin]$ ./start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [master1]
master1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting datanodes
worker3: Warning: Permanently added 'worker3,ip5.232' (ECDSA) to the list of known hosts.
worker2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
worker1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
worker3: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting secondary namenodes [master2]
master2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting resourcemanager
resourcemanager is running as process 34085. Stop it first.
Starting nodemanagers
worker2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
worker1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
worker3: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
解决办法:
chown -R root:root /opt
chmod -R a+x /opt/*
再运行命令start-all.sh,没有报错,启动成功。
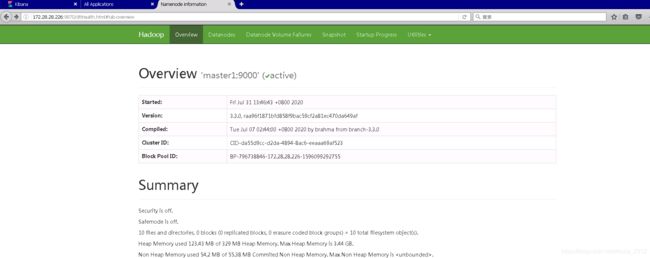
用jps命令查询进程信息,如果提示没有jps命令,则再配置一下jps命令。还可以登录浏览器查看。
# 主节点:
jps 30996 Jps 30645 NameNode 30917 ResourceManager
# 2主节点:
jps 33571 Jps 33533 SecondaryNameNode
# 从节点:
jps 33720 Jps 33691 NodeManager 33630 DataNode
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Wn5MXXqv-1596618990177)(media/image-20200803084739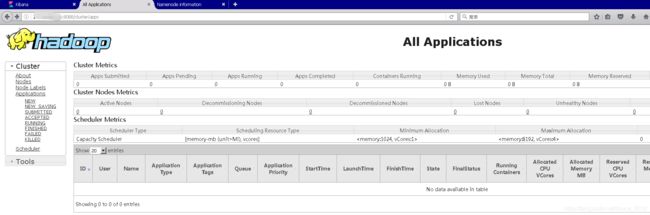
284.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l9lhJpwT-1596618990178)(media/image-20200803084825457.png)]
1.9 停止hadoop集群
-
在master节点上运行stop-all.sh
-
然后在worker节点上再jps检查一下,看看worker节点是否成功的被停止了。
-
在worker上运行:stop-all.sh,出现如下错误:
service: ssh: Could not resolve hostname service: Name or service not known
worker2: Warning: Permanently added 'worker2' (ECDSA) to the list of known hosts.
worker1: Warning: Permanently added 'worker1' (ECDSA) to the list of known hosts.
worker2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
worker1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
- 解决办法
chown -R hadoop:hadoop /opt/hadoop3/
2.0 添加hadoop用户,非root用户启动和运行hadoop
上面都是使用的root用户运行hadoop,但是其实hadoop一般不用root用户,建议用其它用户,因此下面讲添加和配置hadoop用户该如何操作。
- 所有机器添加用户hadoop和用户组hadoop
# 新建用户
adduser hadoop
# 新建用户组
groupadd hadoop
# 添加密码
passwd hadoop
# 将hadoop用户添加到hadoop用户组。前面一个hadoop是组名,后面一个hadoop是用户名
usermod -a -G hadoop hadoop
# 或者添加用户和用户组用以合成命令
groupadd hadoop &&useradd -d /home/hadoop -g hadoop -m hadoop
# 修改文件及文件夹的用户和用户组:
chown -R hadoop:hadoop /opt/*
- 节点可以互相免密登录的本质是,需要在作为服务器的节点要保存来访节点(客户端)的公钥在鉴权文件(authorized_keys)中,这样才保证是经过授权的
- 免密登录是有方向的,可以是单向也可以是双向的免密登录。服务器到客户端,客户端到服务器
- 比如226的节点可以访问227,则226是客户端,227是服务器。那么就需要将226的公钥以需要免密登录的用户角色拷贝到227上,并且将其追加到227的authorized_keys文件中。最后还要保证227的文件以及目录都有免密用户权限。
- 反之227要免密登录到226,则则227是客户端,226是服务器。那么就需要将227的公钥以需要免密登录的用户角色拷贝到226上,并且将其追加到226的authorized_keys文件中。最后还要保证226的文件以及目录都有免密用户权限。
# 以下操作都需要在所有需要免密登录的机器上操作, 但可以在master1上操作再拷贝到其它机器
# 确认ssh服务已经安装并打开;
# 打开文件/etc/ssh/sshd_config,确保以下配置已经添加(如果被"#“注释了就把”#"删除):
AuthorizedKeysFile .ssh/authorized_keys
PubkeyAuthentication yes
#在master机器上输入ssh hadoop@master2,尝试ssh登录master2,此时由于未配置免密码登录,所以控制台要求输入master2的密码,如下:
[hadoop@master1 ~]$ ssh hadoop@master2
# 以hadoop账号登录,输入ssh-keygen -t rsa,然后一路回车,顺利生成秘钥文件,如下:
[hadoop@master1 ~]$ ssh-keygen -t rsa
# 配置秘钥授权文件,以hadoop账号登录master1机器,生成一个空白文件:
[hadoop@master1 ~]$touch ~/.ssh/authorized_keys
# 将master1自己的公钥放入文件authorized_keys中:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 以hadoop账号登录master2机器,执行以下命令,即可将master2的公钥传输到master1机器,文件名为master2.id_rsa.pub:
[hadoop@master1 ~]scp ~/.ssh/id_rsa.pub hadoop@master1:~/.ssh/master2.id_rsa.pub
# 期间会要求输入master1的hadoop账号的密码,输入后传输完成,在master1的/home/hadoop/.ssh目录下,多了个名为master2.id_rsa.pub的文件;
# 在master1机器执行以下命令,即可将master2.id_rsa.pub的内容写入authorized_keys文件:
[hadoop@master1 ~]cat ~/.ssh/master2.id_rsa.pub >> ~/.ssh/authorized_keys
# 此时authorized_keys文件中已经有了master1和master2的公钥;
# 以hadoop账号登录worker1机器,执行以下命令,即可将worker1的公钥传输到master1机器,文件名为worker1.id_rsa.pub:
[hadoop@master1 ~]scp ~/.ssh/id_rsa.pub hadoop@master1:~/.ssh/worker1.id_rsa.pub
# 期间会要求输入master1的hadoop账号的密码,输入后传输完成,在master1的/home/hadoop/.ssh目录下,多了个名为worker1.id_rsa.pub的文件;
# 在master1机器执行以下命令,即可将worker1.id_rsa.pub的内容写入authorized_keys文件:
[hadoop@master1 ~]cat ~/.ssh/worker1.id_rsa.pub >> ~/.ssh/authorized_keys
# 此时authorized_keys文件中已经有了master1、master2、worker1的公钥;
# 以同样的方式,将worker2,worker3的公钥保存在master1的authorized_keys文件
-------------------------------------------------------------------------------------
# 同步秘钥授权文件
# 以hadoop账号登录master1机器,执行以下命令将秘钥授权文件同步到master2机器:
[hadoop@master1 ~]scp ~/.ssh/authorized_keys hadoop@master2:~/.ssh/
# 以hadoop账号登录master1机器,执行以下命令将秘钥授权文件同步到worker1机器:
[hadoop@master1 ~]scp ~/.ssh/authorized_keys hadoop@worker1:~/.ssh/
# 至此,秘钥授权文件已经同步到所有机器,如果前面的所有操作用的是root账号,此时已经可以免密码登录成功了,但是今天我们用的不是root账号,此时在master1输入命令ssh hadoop@master2,却发现依然要求输入master2的hadoop账号的密码,这是因为文件和文件夹权限的问题导致的,接下来解决权限问题;
# 调整文件夹和文件的权限(三台机器都要执行)
# 先调整文件夹~/.ssh的权限:
chmod 700 ~/.ssh
# 再调整文件~/.ssh/authorized_keys的权限:
chmod 600 ~/.ssh/authorized_keys
# 至此,非root账号的SSH免密码登录配置已经完成,在master2输入命令ssh hadoop@master1试试,如下,顺利登录,不需要输入密码:
[hadoop@master2 ~]$ ssh hadoop@master1
Last login: Fri Feb 8 00:36:57 2019 from 192.168.119.1
# 重要重要重要!!!,将上面配置授权文件,同步授权文件的过程再反过来执行一遍,比如master2的公钥存在master1上,这样就可以实现以hadoop用户在master1上免密登录master2。
# 同理其它的也是一样的。
- 修改/opt/hadoop目录和文件的所有者权限, 每一台服务器都需要执行,且chown的命令需要在root用户下执行
chown -R hadoop:hadoop /opt/hadoop3
- 不要忘记注释掉之前添加的root用户角色,在这几个文件中都需要注释掉:stop-yarn.sh start-yarn.sh start-all.sh stop-all.sh start-dfs.sh stop-dfs.sh
[root@master1 hadoop]# cat ../../sbin/start-all.sh
#!/usr/bin/env bash
#HDFS_DATANODE_USER=root
#HADOOP_SECURE_DN_USER=hdfs
#HDFS_DATANODE_SECURE_USER=root
#HDFS_NAMENODE_USER=root
#HDFS_SECONDARYNAMENODE_USER=root
#YARN_RESOURCEMANAGER_USER=root
#YARN_NODEMANAGER_USER=root
- 然后将master1修改的全部复制到其它几台服务器上
scp stop-yarn.sh start-yarn.sh start-all.sh stop-all.sh start-dfs.sh stop-dfs.sh hadoop@master2:/opt/hadoop3/hadoop-3.3.0/sbin/
scp stop-yarn.sh start-yarn.sh start-all.sh stop-all.sh start-dfs.sh stop-dfs.sh hadoop@worker1:/opt/hadoop3/hadoop-3.3.0/sbin/
scp stop-yarn.sh start-yarn.sh start-all.sh stop-all.sh start-dfs.sh stop-dfs.sh hadoop@worker2:/opt/hadoop3/hadoop-3.3.0/sbin/
scp stop-yarn.sh start-yarn.sh start-all.sh stop-all.sh start-dfs.sh stop-dfs.sh hadoop@worker3:/opt/hadoop3/hadoop-3.3.0/sbin/
-
记得一定要重新运行命令:hadoop namenode -format, 进行节点格式化
-
start-all.sh启动所有服务
二、centos7上配置hive:apache-hive-3.1.2-bin
在配置和运行hive之前,需要先配置好hive的元数据库。虽然有默认的Derby数据库,但是不熟悉其操作和使用。因此还是改用习惯的mysql。centos7上已经默认用mariadb替换mysql,但是不熟悉mariadb库的任何配置以及使用,所以还是避免不了mysql,老老实实安装mysql吧。
CentOS7默认数据库是mariadb,配置等用着不习惯,因此决定改成mysql,但是CentOS7的yum源中默认好像是没有mysql的。为了解决这个问题,第一次我也是按照网上的下载repo源,但是在安装的过程中还是需要联网,所以尝试第二次,下载离线的mysql二进制包:mysql-8.0.21-linux-glibc2.12-x86_64。下载地址
2.1. 先在centos7上配置mysql
https://dev.mysql.com/downloads/mysql/
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z4VADImS-1596618990180)(media/image-20200731144514908.png)]
下载好后,上传到master服务器,解压到目录:/usr/local/mysql
在配置mysql之前,先用命令查一下是不是以及有mysql了,如果有的话,可以利用就利用,不用新装。如果没有则需要重新安装。
# 查询命令
$ rpm -qa|grep mysql
配置环境变量:
vi /etc/profile
在文件底部添加:
export PATH=/usr/local/mysql/bin:$PATH
保存退出,运行命令,改变的变量生效:
source /etc/profile
初始化命名:
bin/mysqld --initialize --user=mysql //该步骤执行完毕,会产生一个临时密码,复制粘贴到其他地方保存,后续登录mysql需要使用
bin/mysql_ssl_rsa_setup
bin/mysqld_safe --user=mysql &
cp support-files/mysql.server /etc/init.d/mysql.server
在bin目录下运行命令,第一次登陆:
$ mysql -uroot -p'xxxxxx' //xxxx是之前记录的临时密码
mysql > use mysql;
mysql > update user set password=password('hive') where user='root'; //修改密码
mysql > exit;
重启mysql服务
chkconfig mysql on //开机自动启动
$ service mysql restart
再次在bin目录下进入mysql命令行,创建一个 hive 数据库用来存储 Hive 元数据,且数据库访问的用户名和密码都为 hive。
m y s q l − u r o o t − p h i v e mysql -uroot -phive mysql−uroot−phive
mysql> CREATE DATABASE hive;
mysql> USE hive;
mysql> CREATE USER 'hive'@'localhost' IDENTIFIED BY 'hive';
mysql> grant all on *.* to 'hive'@'%';
mysql> exit;
配置jdbc连接器:
MySQL Java 连接器添加到 $HIVE_HOME/lib 目录下。我安装时使用的是 mysql-connector-java-8.0.16.jar。
2.2. 配置hive
解压到指定目录,然后配置环境变量
export HIVE_HOME=/opt/hive/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin
修改hive-env.sh
因为 Hive 使用了 Hadoop, 需要在 hive-env.sh 文件中指定 Hadoop 安装路径:
export JAVA_HOME=/usr/lib/jvm/jre ##Java路径
export HADOOP_HOME=/opt/hadoop3/hadoop-3.3.0 ##Hadoop安装路径
export HIVE_HOME=/opt/hive/apache-hive-3.1.2-bin ##Hive安装路径
export HIVE_CONF_DIR=$HIVE_HOME/conf ##Hive配置文件路径
在运行hive之前,必须创建两个路径/tmp和/user/hive/warehouse后,这样才能在hive中创建库和表
$HADOOP_HOME/bin/hadoop fs -mkdir /tmp
$HADOOP_HOME/bin/hadoop fs -mkdir -p /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse
修改hive-site.xml, 注意ConnectionURL每一个关键字之前有分号。
javax.jdo.option.ConnectionURL
jdbc:mysql://localhost:3306/hive?allowMultiQueries=true&useSSL=false&verifyServerCertificate=false&allowPublicKeyRetrieval=true
javax.jdo.option.ConnectionDriverName
com.mysql.cj.jdbc.Driver
javax.jdo.option.ConnectionUserName
hive
javax.jdo.option.ConnectionPassword
hive
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.exec.scratchdir
/tmp
datanucleus.readOnlyDatastore
false
datanucleus.fixedDatastore
false
datanucleus.autoCreateSchema
true
datanucleus.autoCreateTables
true
datanucleus.autoCreateColumns
true
2.3. 运行hive以及错误解决
运行 schematool 命令来执行初始化操作,此命令也在hive的bin目录下
schematool -dbType mysql -initSchema
启动hadoop,hdfs, 然后用jps查看进程。
./start-all.sh
jps
这时启动hive,用beeline命令:
$HIVE_HOME/bin/beeline -u jdbc:hive2://
如果出现如下错误:
java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument](https://www.cnblogs.com/syq816/p/12632028.html)
错误原因:系统找不到这个类所在的jar包或者jar包的版本不一样,系统不知道使用哪个。这里是因为hive中的jar包和hadoop中的jar包版本不一致导致的。
解决办法:
1、com.google.common.base.Preconditions.checkArgument这个类所在的jar包为:guava.jar
2、hadoop-3.2.1(路径:hadoop\share\hadoop\common\lib)中该jar包为 guava-27.0-jre.jar;而hive-3.1.2(路径:hive/lib)中该jar包为guava-19.0.1.jar
3、将jar包变成一致的版本:删除hive中低版本jar包,将hadoop中高版本的复制到hive的lib中。
启动错误:
Underlying cause: java.sql.SQLNonTransientConnectionException : Public Key Retrieval is not allowed
SQL Error code: 0
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
解决办法:
# 添加--verbose选项,查看详细信息
./schematool schematool -dbType mysql -initSchema --verbose
# 在ConnectionURL中添加allowPublicKeyRetrieval=true, 见hive-site.html文件中的配置
启动错误:
Error applying authorization policy on hive configuration: The dir: /tmp on HDFS should be writable. Current permissions are: rwxrwxr-x
解决办法:
$HADOOP_HOME/bin/hadoop fs -chmod a+w /tmp
制到hive的lib中。
启动错误:
Underlying cause: java.sql.SQLNonTransientConnectionException : Public Key Retrieval is not allowed
SQL Error code: 0
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
解决办法:
# 添加--verbose选项,查看详细信息
./schematool schematool -dbType mysql -initSchema --verbose
# 在ConnectionURL中添加allowPublicKeyRetrieval=true, 见hive-site.html文件中的配置
启动错误:
Error applying authorization policy on hive configuration: The dir: /tmp on HDFS should be writable. Current permissions are: rwxrwxr-x
解决办法:
$HADOOP_HOME/bin/hadoop fs -chmod a+w /tmp