python 判断数据类型_Python数据分析实战(一)——Python基础
概要
本章主要总结了Python的数据类型与数据结构、生成器与迭代器的关系等Python基础知识,为后边的数据分析实例实战做好准备。
目录
- 数据分析环境配置
- Python基本数据类型与数据结构
- 条件控制与循环
- 函数
- 容器、迭代器和生成器
1. 数据分析环境配置
工欲善其事,必先利其器。
在正式学习使用Python进行数据分析之前,我们需要安装相应的软件。主流的工具包括:
- 包管理器和环境管理器:Anaconda
- 交互式笔记本:Jupyter Notebook
安装和配置教程如下:
初学 Python 者自学 Anaconda 的正确姿势是什么?www.zhihu.com
此外,在这里还要推荐Jupyter Notebook扩展插件,极大地提高了搬砖的效率和幸福感,用过的人都说好:
https://mp.weixin.qq.com/s?__biz=MzI3ODkxODU3Mg%3D%3D&mid=2247485697&idx=2&sn=cfd494920bc59c62e192ee475bc01b9d&chksm=eb4eedc2dc3964d40a6df962cde5fdfc6ccd2cbb88c423b24d479754b992e5430cdeebea9da4mp.weixin.qq.com环境配置的过程比较耗费时间,需要多点耐心。
温馨提示:本系列基于Python3版本编写。
2. Python基本数据类型与数据结构
在Python中,每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
# 变量赋值
a = 10 # 整形变量
b = "hello python!" # 字符串变量本身是没有类型的,这里的“数据类型”,是变量所指的内存中对象的类型。
Python3中共有7个标准的数据类型:
- Number(数字)
- String(字符串)
- None(空值)
- Tuple(元组)
- List(列表)
- Dictionary(字典)
- Set(集合)
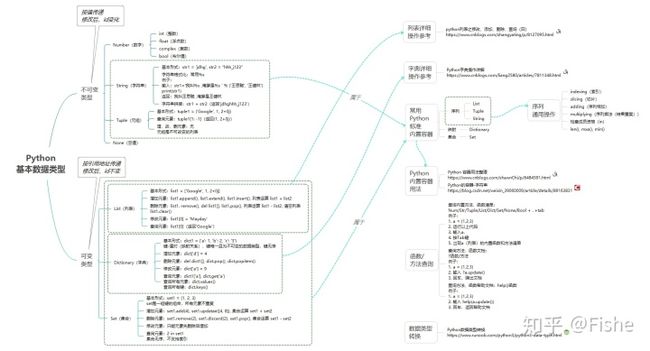
2.1 Python基本数据类型
依据是否为可变对象,以上7种数据类型可划分为可变类型和不可变类型——除了列表、字典和集合是可变类型外,其他数据类型都是不可变类型。
判断一个实例的数据类型可变还是不可变类型的依据在于,该实例在被修改后的内存地址是否变化(采用id() 函数)。如果id不变,则为可变类型数据;id改变则为不可变类型数据。
为了方便记忆,Python的基本数据类型分类及其操作总结如下图:
2.2 Python数据结构
数据结构 [1]是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成。简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中。
数据结构按照其逻辑结构可分为线性结构、树结构、图结构:
1) 线性结构:数据结构中的元素存在一对一的相互关系,e.g.列表
2) 树结构:数据结构中的元素存在一对多的相互关系
3) 图结构:数据结构中的元素存在多对多的相互关系
在数据分析中,我们常用线性结构,包括列表、栈、队列、链表、哈希表(如:字典)。针对不同的数据操作需求采用不同的数据结构,有利于提高内存使用率和计算速率。
collections是Python内建的一个集合模块,collections为Python提供了一些拓展性的数据结构,可输入以下代码查询Python的collections模块提供的数据结构:
import collections
collections.__all__除了基础的数据结构,如集合、列表、字典和元组外,常用的扩展性数据结构包括:栈、队列、有序字典、计数器,相关概念和操作总结如下:

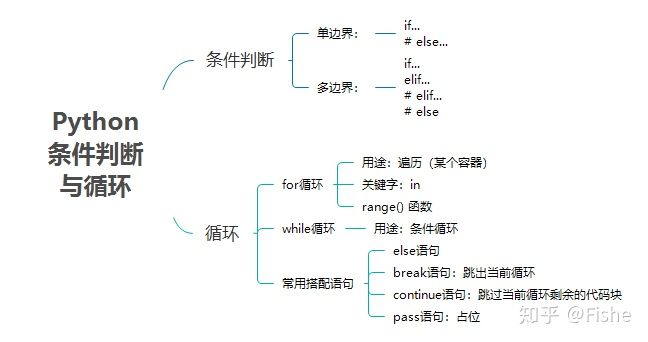
3. 条件控制与循环
Python 条件控制是通过一条或多条语句的执行结果(True 或者 False)来决定执行代码块的。简单来说,整个条件控制的流程就是:
if 满足 A条件,则执行A1代码;不满足A条件,则不执行或者,满足下个条件就执行下个条件相应的代码。
在Python中,条件语句是通过if实现的。
而Python的循环语句是通过for语句和while语句实现的,这两个语句分别用于遍历和条件循环。
Python的条件控制与循环关键点总结如下:
4. 函数
函数是一种抽象,可以理解为是对某类具有共同特点的对象的操作套路。
Python中有许多实用的内置函数,可以通过help()函数查询其帮助文档。
此外,我们也可以通过def语句定义函数。Python自定义函数的要点总结如下:

通常在查询python内置函数帮助文档的时候,常常看到这样两个参数:*args和**kw。对应上图中参数板块的内容,我们可以知道:
- *args是可变参数,args接收的是一个tuple
- **kw是关键字参数,kw接收的是一个dict
而调用函数时传入可变参数和关键字参数的语法[2]为:
- 可变参数既可以直接传入:func(1, 2, 3),又可以先组装list或tuple,再通过*args传入:func(*(1, 2, 3))
- 关键字参数既可以直接传入:func(a=1, b=2),又可以先组装dict,再通过**kw传入:func(**{'a': 1, 'b': 2})
5. 容器、迭代器和生成器
5.1 容器 container
首先,容器是一种数据结构,顾名思义,这是一种可以把多个对象/元素组织在一起的数据结构。容器中的元素可以通过for循环逐个地迭代获取,也可以通过in关键字来判断元素是否在容器中。[3]
在Python中,常见的容器对象包括:
- list、dequeue...
- set、frozenset...
- dict、defaultdict、OrderDict...
- tuple、namedtuple...
- str
- file
5.2 迭代 iteration
如果给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为 迭代(Iteration) [4]。
在这个过程中,list或tuple等可直接使用for循环来遍历的对象统称为可迭代对象(Iterable)。判断一个对象是否为可迭代对象,可以通过isinstance()函数和collections模块中的Iterable类型来实现:
list1 = [1,2,3]
tuple1 = (1,2,3)
dict1 = {'a':1,'b':2,'c':3}
set1 = {1,2,3}
str1 = 'abc'
no = None
bl = False
num1 = 32
ass_iter = [
[1,2,3],
(1,2,3),
{'a':1,'b':2,'c':3},
{1,2,3},
'abc',
None,
False,
32
]
for i in ass_iter:
if isinstance(i, Iterable):
print(type(i), " is an iterble.n")
else:
print(type(i), " is not an iterble.n")以上代码的执行结果为:

虽然list、dict、tuple是可以迭代的对象,但不是迭代器。
但是可迭代对象实现了__iter__方法,该方法返回一个迭代器对象 [4]。
迭代器是什么呢?
迭代器指的是可以被next()函数调用并不断返回下一个值的对象。可通过调用iter()方法,创建一个迭代器:
list1 = [1,2,3]
print(type(list1))
it = iter(list1)
print(type(it))运行结果为:
5.3 生成器 generator
不同于一个函数只返回一次,生成器是一种一边循环一边计算的机制,只有用next()调用了才执行,不调用则不执行。这种机制节省了大量的内存空间和计算时间。
创建生成器的方法有两种,包括:
- 生成器表达式(区别于列表表达式)
- yield关键字
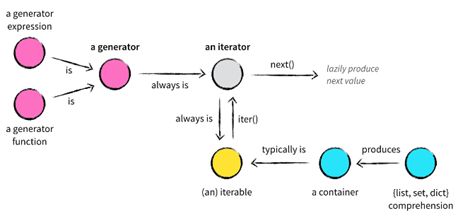
5.4 容器、迭代器和生成器的关系
简单来说,容器、迭代器和生成器的关系可用下图来说明:

- 生成器表达式和生成器函数(含yield关键字)是一个生成器;
- 生成器通常是一个迭代器;
- 生成器/迭代器可调用next()方法
- 通过列表、集合、字典等容器对象可产生一个容器;
- 容器通常是可迭代对象;
- 可迭代对象通过iter()函数可创建一个迭代器。
以上,是Python的基础姿势,总结完毕~
参考
- ^数据结构 https://www.cnblogs.com/xiugeng/p/9685762.html
- ^函数的参数 https://www.liaoxuefeng.com/wiki/1016959663602400/1017261630425888
- ^python:容器、迭代器、生成器 简单介绍 https://segmentfault.com/a/1190000016127764
- ^ab迭代 https://www.liaoxuefeng.com/wiki/1016959663602400/1017316949097888